在大语言模型推理服务中,首 Token 延迟(TTFT,Time-To-First-Token) 是衡量服务响应速度的核心指标。从用户发起请求到看见第一个 Token 输出,这段时间越短,体验就越好。然而,在实际部署中,优化 TTFT 常常面临各种挑战。
LMCache 针对此问题,提出了一套 KV 缓存持久化与复用 的优化方案。该项目已开源,并与 vLLM 推理引擎进行了深度集成。

核心原理
传统大模型推理的一个特点是:每次处理输入文本时,都需要从头开始计算 KV 缓存(Key-Value Cache)。可以将 KV 缓存理解为模型在“阅读”文本时生成的中间状态,类似于做的“笔记”。
问题的关键在于,传统方案不会复用这些“笔记”。即使是完全相同的文本再次出现,整个 KV 缓存仍需要重新计算一遍。
LMCache 的核心思路是将计算好的 KV 缓存保存下来——不仅存储在 GPU 显存中,还可以保存到 CPU 内存甚至磁盘上。当后续遇到相同的文本时(注意:不只是前缀匹配,任意位置的文本片段都可复用),便可以直接读取缓存,从而省去大量重复计算。
根据实测,搭配 vLLM 使用时,在多轮对话、RAG 等场景下,响应速度可以提升 3 到 10 倍。
其工作流程的伪代码示意如下:
# 传统方式:速度较慢
def get_answer(prompt):
memory = build_memory_from_zero(prompt) # GPU 需要重新计算
return model.answer(memory)
# 使用 LMCache:快速且智能
import lmcache
def get_answer(prompt):
if lmcache.knows_this(prompt): # 是否见过此文本?
memory = lmcache.grab_memory(prompt) # 快速获取缓存
else:
memory = build_memory_from_zero(prompt)
lmcache.save_memory(prompt, memory) # 保存以备后用
return model.answer(memory)
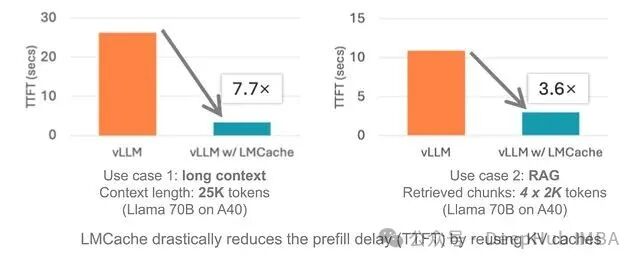
主要特性
- 高性能:缓存读取速度相比原生方案可提升约 7 倍,同时吞吐量也有所增加。
- 灵活匹配:文本无论出现在 Prompt 的哪个位置,只要重复出现就能命中缓存。
- 多级存储:支持 GPU 显存、CPU 内存、磁盘等多级存储,甚至可以接入 NIXL 等分布式存储系统,有效减轻 GPU 压力。
- 深度集成:与 vLLM v1 集成紧密,支持跨设备共享 KV 缓存、跨节点传递等高级特性,易于在生产环境中配合 llm-d、KServe 等工具使用。
对于构建聊天机器人或 RAG 应用,LMCache 能够在不升级硬件的情况下,有效降低响应延迟。
安装指南
LMCache 目前主要支持 Linux 环境,Windows 用户需要通过 WSL 或社区适配方案使用。
基础要求:
- Python 3.9+
- NVIDIA GPU(如 V100、H100 等)
- CUDA 12.8 或更高版本
- 安装后可离线运行
使用 pip 安装:
pip install lmcache
安装包已包含必要的 PyTorch 依赖。若遇到问题,建议尝试源码编译。
尝鲜预发布版(TestPyPI):
pip install --index-url https://pypi.org/simple --extra-index-url https://test.pypi.org/simple lmcache==0.3.4.dev61
安装后验证版本:
import lmcache
from importlib.metadata import version
print(version("lmcache")) # 应输出 0.3.4.dev61 或更新版本
具体最新版本号请查看项目 GitHub 主页。
源码编译
喜欢手动编译的用户可以按以下步骤操作:
git clone https://github.com/LMCache/LMCache.git
cd LMCache
pip install -r requirements/build.txt
# 选择一个选项:
# A: 选择你的 Torch 版本(推荐用于 vLLM 0.10.0)
pip install torch==2.7.1
# B: 安装包含 Torch 的 vLLM
pip install vllm==0.10.0
pip install -e . --no-build-isolation
编译完成后进行验证:
python3 -c "import lmcache.c_ops"
若无报错则说明编译成功。
使用 uv 工具可以加速此过程:
git clone https://github.com/LMCache/LMCache.git
cd LMCache
uv venv --python3.12
source .venv/bin/activate
uv pip install -r requirements/build.txt
# 同上选择 Torch 或 vLLM 安装方式
uv pip install -e . --no-build-isolation
Docker 部署
为简化部署,可以直接使用 Docker 镜像:
# 稳定版
docker pull lmcache/vllm-openai
# 每夜构建版
docker pull lmcache/vllm-openai:latest-nightly
对于 AMD GPU(如 MI300X)用户:需要从 vLLM 基础镜像开始,并设置特定的 ROCm 编译参数:
PYTORCH_ROCM_ARCH="gfx942" \
TORCH_DONT_CHECK_COMPILER_ABI=1 \
CXX=hipcc \
BUILD_WITH_HIP=1 \
python3 -m pip install --no-build-isolation -e .
总结
KV 缓存复用是优化 LLM 推理性能的基本思路之一,而 LMCache 将其实现得较为完善。其多级存储设计、任意位置文本匹配能力以及与 vLLM 的原生深度集成,组合起来能够有效解决实际生产中的性能瓶颈。对于多轮对话、RAG 等 Prompt 重复率较高的应用场景,实现 3-10 倍的 TTFT 优化 具有显著的实用价值。
目前,LMCache 主要围绕 vLLM 生态,以 Linux 支持为主,AMD GPU 的支持仍在持续完善中。作为一个开源解决方案,它值得关注和尝试。
项目地址:https://github.com/LMCache/LMCache
 发表于 2025-12-10 05:45:04
|
查看: 210|
回复: 0
发表于 2025-12-10 05:45:04
|
查看: 210|
回复: 0
