最近在负责的一个基础模块中,我们发现了一个性能问题:在某硬件平台上,系统开机阶段有一个线程的CPU占用率异常偏高。经过排查,最终定位到问题的根源在于系统中使用的 libuv 版本较旧。在特定场景下,其内部函数 uv__async_spin 会发生长时间的空转,从而消耗大量CPU资源。而新版本的libuv对此进行了优化,在相同场景下,CPU占用时长可降低50%以上。
该问题在libuv v1.40.0版本中引入,并在v1.45.0版本中得到修复。
1. 背景
1.1 libuv async基本用法
libuv的async机制允许其他线程唤醒运行在event loop上的主线程,并触发预设的回调函数执行。一个典型的使用示例如下:
event loop运行在main主线程中。- 子线程
triggerThread每隔一秒调用一次uv_async_send,唤醒主线程的event loop,从而在主线程中执行回调函数callback。
#include <unistd.h>
#include <uv.h>
#include <thread>
void callback(uv_async_t* async) {
printf("I‘m called\n");
}
int main() {
uv_async_t async;
uv_loop_t* loop = uv_default_loop();
uv_async_init(loop, &async, callback);
std::thread triggerThread([&]() {
while (true) {
sleep(1);
uv_async_send(&async);
}
});
return uv_run(loop, UV_RUN_DEFAULT);
}
上述代码执行后,会每隔1秒调用一次callback函数,输出结果如下:
I'm called
I'm called
...
1.2 libuv async工作原理
libuv的async工作机制可以概括为以下流程:
- 用户在其他线程中调用
uv_async_send,唤醒event loop线程。
event loop线程执行与uv_async_t绑定的回调函数。
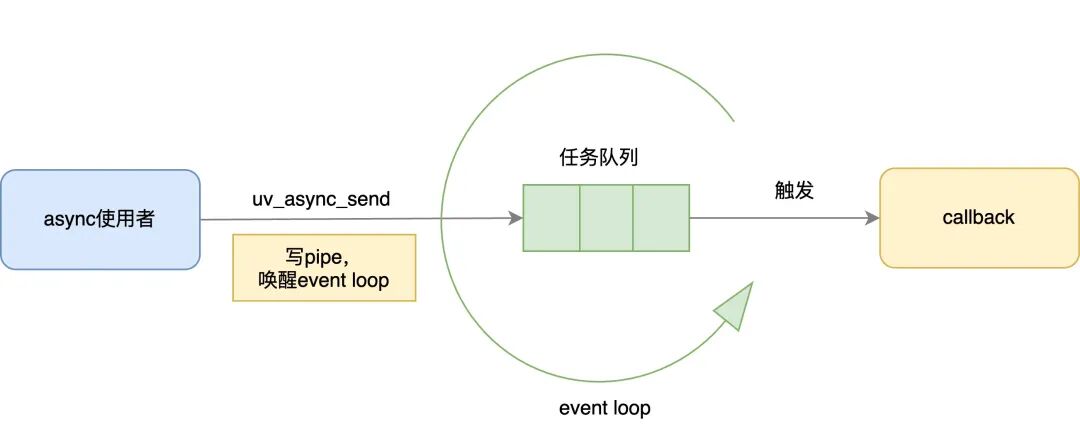
结合代码来分析异步唤醒的流程,可以更清晰地理解其机制。
uv_async_send的实现逻辑如下(以libuv v1.40.0为例):
- 尝试标记待处理:首先尝试将当前
uv_async_t的pending标记从0原子地修改为1,表明有唤醒事件待处理。如果pending状态已不为0,则本次uv_async_send直接返回。这体现了uv_async_send的折叠效应:libuv保证调用uv_async_send必定会触发一次回调,但不保证每次调用都会触发。例如,连续调用5次,可能只触发1次回调,但绝不会多于5次。
- 唤醒event loop:调用内部函数
uv__async_send,通过向pipe写入数据来唤醒event loop。
- 标记处理结束:将
pending标记从1原子地修改为2,表明本次唤醒流程已结束。
// libuv v1.40.0 src/unix/async.c
int uv_async_send(uv_async_t* handle) {
/* Do a cheap read first. */
if (ACCESS_ONCE(int, handle->pending) != 0)
return 0;
/* Tell the other thread we're busy with the handle. */
if (cmpxchgi(&handle->pending, 0, 1) != 0)
return 0;
/* Wake up the other thread's event loop. */
uv__async_send(handle->loop);
/* Tell the other thread we're done. */
if (cmpxchgi(&handle->pending, 1, 2) != 1)
abort();
return 0;
}
在event loop线程中,uv_run函数会调用uv__async_io来处理唤醒事件。该函数会读取pipe中的数据(内容不重要),并遍历所有async_handles,调用uv__async_spin来判断是否需要执行回调。
// libuv v1.40.0 src/unix/async.c
static void uv__async_io(uv_loop_t* loop, uv__io_t* w, unsigned int events) {
char buf[1024];
ssize_t r;
QUEUE queue;
QUEUE* q;
uv_async_t* h;
assert(w == &loop->async_io_watcher);
// 读取pipe内容,直到无数据可读(配合折叠效应理解)
for (;;) {
r = read(w->fd, buf, sizeof(buf));
if (r == sizeof(buf))
continue;
if (r != -1)
break;
if (errno == EAGAIN || errno == EWOULDBLOCK)
break;
if (errno == EINTR)
continue;
abort();
}
// 检查哪些uv_async_t被触发,并调用对应回调
QUEUE_MOVE(&loop->async_handles, &queue);
while (!QUEUE_EMPTY(&queue)) {
q = QUEUE_HEAD(&queue);
h = QUEUE_DATA(q, uv_async_t, queue);
QUEUE_REMOVE(q);
QUEUE_INSERT_TAIL(&loop->async_handles, q);
// 关键函数:通过spin处理pending状态
if (0 == uv__async_spin(h))
continue; /* Not pending. */
if (h->async_cb == NULL)
continue;
h->async_cb(h);
}
}
uv__async_spin是实现的核心,也是问题的所在。其逻辑如下:
// libuv v1.40.0 src/unix/async.c
static int uv__async_spin(uv_async_t* handle) {
int i;
int rc;
for (;;) {
/* 循环997次(一个质数,旨在减少共振影响) */
for (i = 0; i < 997; i++) {
/* rc的可能返回值:
* rc=0 -- handle未处于待处理状态。
* rc=1 -- handle待处理,但其他线程仍在操作它(关键点)。
* rc=2 -- handle待处理,且其他线程操作已完成。
*/
rc = cmpxchgi(&handle->pending, 2, 0);
if (rc != 1)
return rc;
/* 其他线程正忙于此handle,自旋等待其完成。 */
cpu_relax();
}
/* 让出CPU,避免长时间占用。 */
sched_yield();
}
}
重点关注 cmpxchgi(&handle->pending, 2, 0) 这一行。它的语义是:
- 如果
handle->pending当前值为2,则将其原子地设置为0,并返回2(表示唤醒已完成,但回调未执行)。
- 如果当前值为0,则什么也不做,返回0(表示未被唤醒)。
- 如果当前值为1,则什么也不做,返回1(表示
uv_async_send正在执行中)。此时,uv__async_spin会进入自旋等待状态,直到handle->pending变为2。这正是导致本文所述Bug的根源。
2. 问题场景
结合问题复现时抓取的调用栈和代码进行分析,问题发生序列如下:
- 发送线程被抢占:主线程在
uv__async_send中调用write系统调用写pipe时,CPU时间片被抢占。
- Event Loop线程空转等待:
event loop线程(例如线程21757)在事件循环中检测到handle->pending状态为1,意味着uv_async_send尚未完成。于是,它在uv__async_spin中进入自旋等待状态。
- 结果:
uv__async_spin的总耗时达到313ms,其中CPU空转时间高达183ms。
libuv spin空转trace图

这个问题在I/O性能较差的硬件平台上更容易出现,因为write系统调用耗时更长。在I/O性能良好的平台上可能不易观察到。
进一步思考,这个问题在单CPU核心场景,或者进程的线程被绑定到同一个CPU核心的场景下更容易触发。如下图所示,只要event loop线程在uv__async_send的执行区间(绿色区域)内被唤醒,都会陷入无效的空转等待,这对于 高并发编程 场景是严重的性能损耗。

3. 修复方案
我们来看看libuv在最新版本(如v1.51.0)中是如何解决这个问题的。
首先,pending状态被简化了,只保留0和1两个值。uv_async_send的逻辑变得非常简洁:
- 原子地将
pending从0交换为1(如果原本不是0则直接返回)。
- 调用
uv__async_send写pipe唤醒event loop。
// libuv v1.51.0 src/unix/async.c
// 删除了无关的busy状态以便理解
int uv_async_send(uv_async_t* handle) {
_Atomic int* pending;
pending = (_Atomic int*) &handle->pending;
/* Do a cheap read first. */
if (atomic_load_explicit(pending, memory_order_relaxed) != 0)
return 0;
/* Wake up the other thread's event loop. */
if (atomic_exchange(pending, 1) == 0)
uv__async_send(handle->loop);
return 0;
}
uv__async_io函数的变化更大,它直接移除了uv__async_spin:
- 原子地获取
pending值并清零。
- 如果获取到的原值是1,则执行回调;如果是0,则跳过。
// libuv v1.51.0 src/unix/async.c
static void uv__async_io(uv_loop_t* loop, uv__io_t* w, unsigned int events) {
// 读取pipe部分略...
uv__queue_move(&loop->async_handles, &queue);
while (!uv__queue_empty(&queue)) {
q = uv__queue_head(&queue);
h = uv__queue_data(q, uv_async_t, queue);
uv__queue_remove(q);
uv__queue_insert_tail(&loop->async_handles, q);
/* 关键变化:直接原子交换,不再spin */
pending = (_Atomic int*) &h->pending;
if (atomic_exchange(pending, 0) == 0)
continue;
if (h->async_cb == NULL)
continue;
h->async_cb(h);
}
}
现在,回顾第2部分的问题场景,新版本libuv的行为是:
uv__async_io检测到pending为1,直接执行回调,并将pending清零。- 随后,
uv__async_send中的write完成,导致event loop在下一次循环中再次被唤醒。
- 但此次
uv__async_io检测到pending已为0,因此不做任何操作(产生了一次“多余的”唤醒)。
这种“多余唤醒”的代价,远低于旧版本中长时间CPU空转的代价,因此是正确的优化方向。
4. 实践建议
在实际项目中,解决此问题通常有两种方案:
- 方案一:升级libuv到v1.45.0或更高版本。
- 方案二:在旧版本libuv上应用针对此问题的补丁。
如何选择?
- 对于新项目:建议直接升级libuv到较新版本,通常新版本包含更多Bug修复和性能改进。
- 对于稳定运行的老项目:如果升级基础库风险较大,可以采用打补丁的方式,影响范围更可控,回退也更方便。
在我们的实践中,基础库团队经过评估,最终选择了为旧版本打补丁的方案。实施后,在相同的问题场景下,CPU占用时长下降了50%以上,取得了显著的性能提升。
 发表于 2025-12-10 18:04:59
|
查看: 208|
回复: 0
发表于 2025-12-10 18:04:59
|
查看: 208|
回复: 0
