在深入理解标准LSTM之后,下一步自然是探索其更强大的变体——双向LSTM。它的核心思想非常直观:同时利用过去和未来的上下文信息来理解当前时刻的内容。
试想一个填空题:“我今天吃了一个 ___,味道很甜。”如果仅看到前半句,空格里可能是苹果、橙子等任何东西。但结合后半句的“味道很甜”,答案就明确指向了某种水果。双向LSTM正是为了实现这种结合前后文的理解能力而设计的。
为什么需要双向结构?
标准的单向LSTM存在一个明显的局限:信息只能从序列的过去流向未来。在处理当前位置时,模型无法获知后续的信息。这在许多任务中会造成理解偏差。
以命名实体识别为例,对于句子“苹果公司发布了新产品”。当模型处理“苹果”这个词时,单向LSTM只能看到“苹果”本身,很可能将其误判为水果类别。而双向LSTM则能同时看到其后的“公司”一词,从而准确地将其识别为企业名称。这种对完整上下文的捕捉能力,是双向架构的核心价值所在。
结构剖析:前向与后向的并行世界
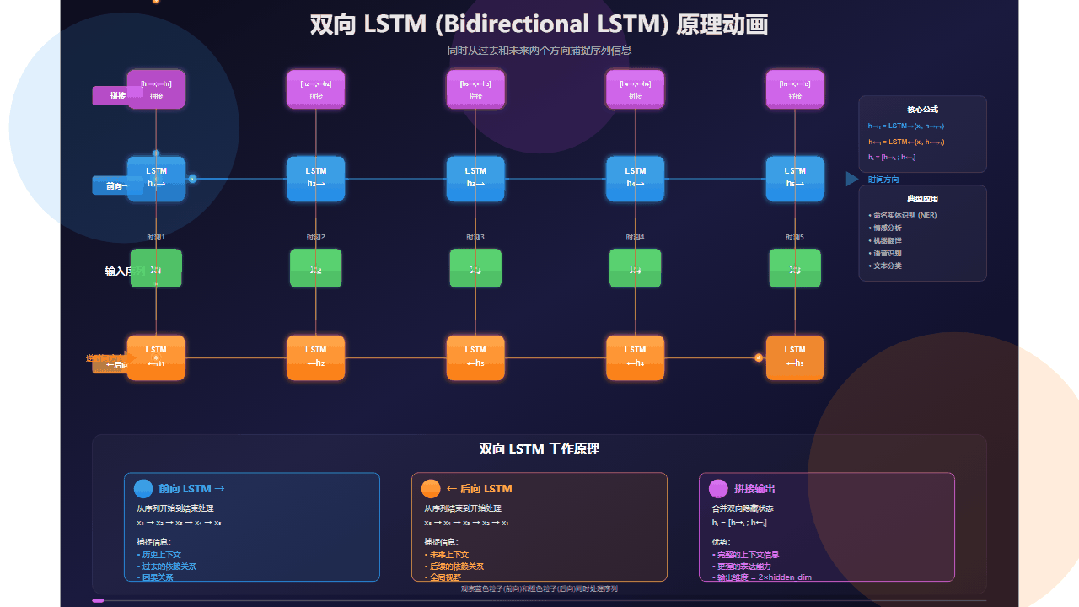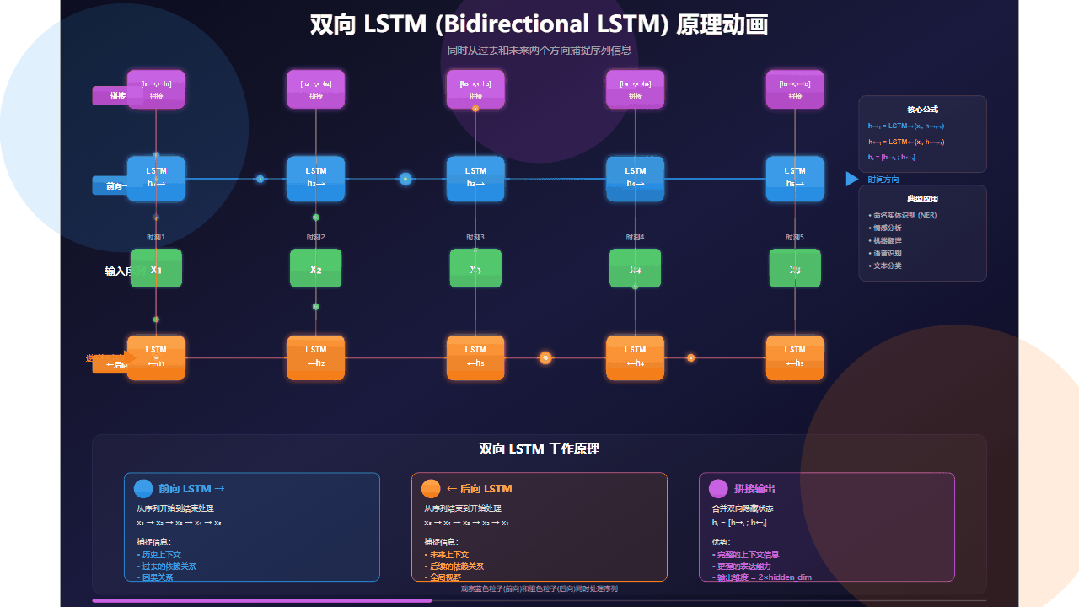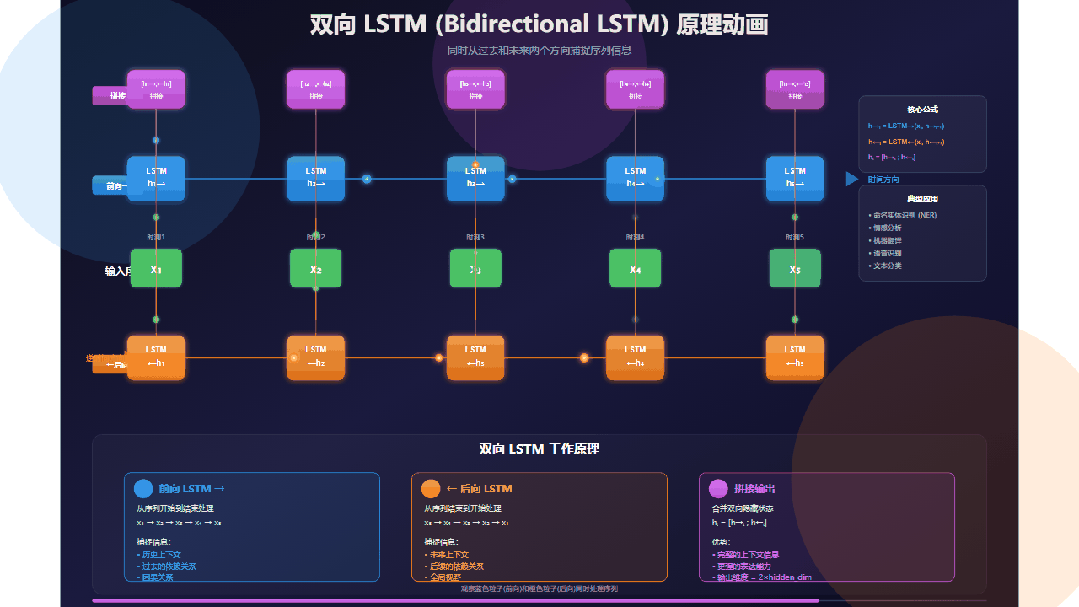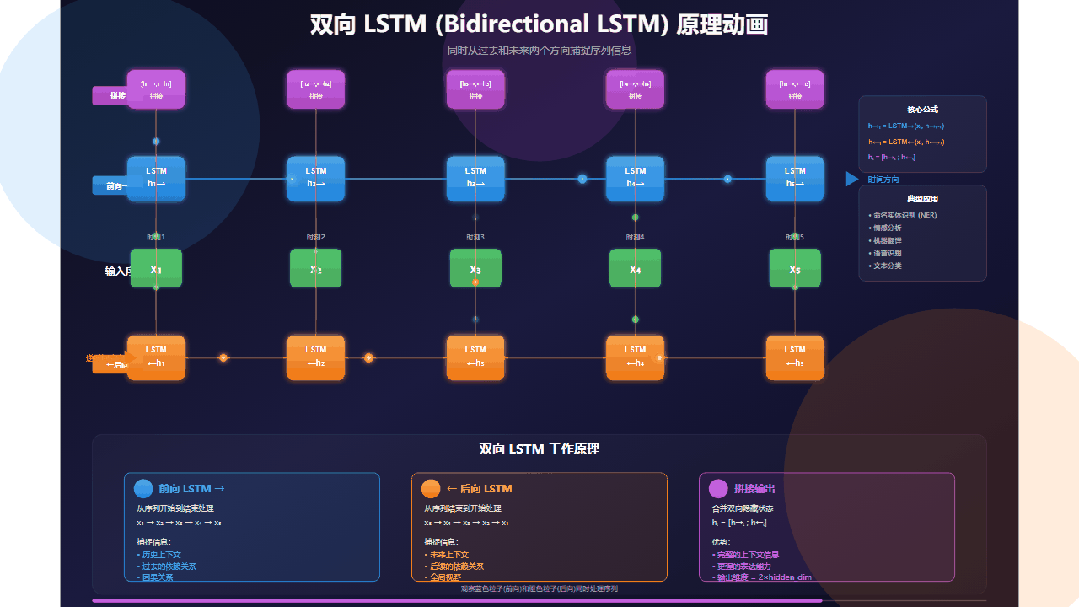
双向LSTM的结构可以清晰地分为三个部分:输入分发、双向并行处理与结果合并。
输入序列
观察位于中央的绿色输入序列:x₁ → x₂ → x₃ → x₄ → x₅。它代表了一个长度为5的序列,可以是句子中的词、语音帧或字符。关键在于,每个输入单元会同时向上和向下“发射”数据粒子,分别供给前向层和后向层处理。
前向LSTM层(蓝色)
这一层沿时间正向(从左到右)处理序列:
时间步: t=1 → t=2 → t=3 → t=4 → t=5
其隐藏状态 h→ₜ 的更新遵循 h→ₜ = LSTM→(xₜ, h→ₜ₋₁)。这意味着 h→ₜ 编码了从序列开头到当前位置 t 的所有历史信息。例如,h→₃ 包含了 x₁, x₂, x₃ 的信息。
后向LSTM层(橙色)
这一层沿时间反向(从右到左)处理序列:
时间步: t=5 → t=4 → t=3 → t=2 → t=1
其隐藏状态 h←ₜ 的更新遵循 h←ₜ = LSTM←(xₜ, h←ₜ₊₁)。因此,h←ₜ 编码了从序列末尾回溯到当前位置 t 的所有未来信息。例如,←h₃ 包含了 x₃, x₄, x₅ 的信息。
双向并行处理
动画中最精彩的部分在于蓝色粒子(前向)与橙色粒子(后向)同时、独立地流动。这两个方向的处理互不干扰,在GPU等硬件上可以高效并行计算,大大提升了效率。
信息融合:拼接操作
双向处理完成后,需要将两个方向的信息进行融合。这是通过向量拼接操作完成的。
对于每个时间步 t,其最终的输出隐藏状态 hₜ 是前向和后向状态的拼接:
hₜ = [h→ₜ ; h←ₜ]
假设每个单向LSTM的隐藏层维度为128,那么拼接后的 hₜ 维度就是256。这使得位置 t 的输出同时蕴含了其全部历史与未来上下文。例如,h₃ = [h→₃; ←h₃],既知道前面的 x₁, x₂,也知道后面的 x₄, x₅。
在PyTorch等深度学习框架中,可以非常方便地实现双向LSTM,其关键就在于输出维度的翻倍。
import torch.nn as nn
lstm = nn.LSTM(
input_size=300,
hidden_size=128, # 单向维度
bidirectional=True # 启用双向
)
# 输出形状: [seq_len, batch, 256] (即 128*2)
核心应用场景
双向LSTM的强大之处在其应用场景中体现得淋漓尽致。
- 命名实体识别:如前所述,判断“苹果”是企业还是水果,必须依赖其后的“公司”一词。双向结构在此类序列标注任务中表现优异。
- 情感分析:对于句子“这部电影虽然节奏慢,但是结局非常感人”。单向模型看到“节奏慢”可能倾向负面,而双向模型能同时看到转折后的“非常感人”,从而做出更准确的正面判断。
- 机器翻译:在编码源语言句子时,双向编码器能更好地理解每个词的上下文。例如,准确判断“bank”在“the bank of the river”中是“河岸”而非“银行”。
这些都属于需要对整个句子进行充分理解的自然语言处理任务。
双向与单向的对比
| 特性 |
单向 LSTM |
双向 LSTM |
| 信息流向 |
过去 → 现在 |
过去 ↔ 现在 ↔ 未来 |
| 上下文 |
只有历史信息 |
完整上下文信息 |
| 输出维度 |
hidden_dim |
hidden_dim × 2 |
| 计算量/参数量 |
1x |
约2x |
| 典型场景 |
文本生成、实时预测 |
文本分类、NER、情感分析 |
何时使用双向LSTM?
- 适合:所有允许在预测前看到完整输入序列的任务,如文本分类、命名实体识别、情感分析、机器翻译的编码器部分。
- 不适合:任何需要实时或逐项生成的任务,如实时语音识别、文本自动生成、时间序列的未来预测,因为这些任务在预测当前输出时无法“预知”未来输入。
总结与核心公式
双向LSTM通过并列一个反向处理的LSTM层,巧妙地让每个位置都能获取全局上下文信息。
核心公式
前向: h→ₜ = LSTM→(xₜ, h→ₜ₋₁)
后向: h←ₜ = LSTM←(xₜ, h←ₜ₊₁)
合并: hₜ = [h→ₜ ; h←ₜ]
一句话总结:双向LSTM通过并行处理序列的正向和反向信息,并将结果拼接,使模型具备更强大的序列上下文理解能力,特别适用于各类自然语言处理分析任务。
代码实现参考
import torch
import torch.nn as nn
class BiLSTMClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
# 定义双向LSTM
self.lstm = nn.LSTM(
input_size=embed_dim,
hidden_size=hidden_dim,
num_layers=2,
bidirectional=True, # 关键参数
batch_first=True,
dropout=0.5
)
# 注意:全连接层输入维度是 hidden_dim * 2
self.fc = nn.Linear(hidden_dim * 2, num_classes)
def forward(self, x):
# x: [batch, seq_len]
embedded = self.embedding(x) # [batch, seq_len, embed_dim]
output, (hidden, cell) = self.lstm(embedded)
# 拼接最后时刻前向和后向的隐藏状态
# hidden 形状: [num_layers*2, batch, hidden_dim]
forward_hidden = hidden[-2] # 前向最后一层
backward_hidden = hidden[-1] # 后向最后一层
final_hidden = torch.cat([forward_hidden, backward_hidden], dim=1)
logits = self.fc(final_hidden)
return logits
 发表于 2025-12-10 18:23:37
|
查看: 257|
回复: 0
发表于 2025-12-10 18:23:37
|
查看: 257|
回复: 0
