本文介绍了AI大语言模型的完整工作流程,从文本输入的预处理到最终输出的生成过程。文章系统性地介绍了分词与嵌入、Transformer架构、自注意力机制、位置编码、长文本外推等核心技术概念,并结合DeepSeek V3等实际案例进行详细说明。同时,本文还提供了丰富的工程实践指导,包括上下文优化、耗时控制、多Agent协同等实用策略。
在AI时代,了解大模型如何工作以及其能力边界,能帮助我们更好地利用它。本文将以通俗易懂的方式,解释大语言模型的核心工作原理及其在工程实践中的应用。
输入:从用户提问到模型“看得懂”的矩阵
1. 输入实质是组合文本
首先需要明确,输入给大语言模型的是一个被称为“上下文”的组合文本,通常包括:
- 系统提示词(例如:“你是个智能助手,回答时要可爱些”)
- 可用工具列表描述(对应Function Call能力)
- 历史对话记录
- 用户的最新提问
以下是一个遵循主流API协议(如OpenAI)的输入示例(工具描述已简化):
messages = [
{"role": "system", "content": "你是个智能助手,回答时要可爱些"}, // 系统提示词
{"role": "user", "content": "你好"}, // 历史提问
{"role": "assistant", "content": "你好,有什么能帮到你呀"}, // 历史回答
{"role": "user", "content": "查询下今日天气"}, // 最新提问
]
tools = [{"type": "function", "function": {"name": "get_weather", "description": "Get current weather information"}}]
核心要点:输入本质上是文本。每次模型调用都是独立的,能够进行多轮对话是因为在工程实现上,每次调用都会将历史对话内容拼接到输入中。这导致在一轮对话中,每次调用的上下文文本会越来越长。
2. 文本如何变成数字:分词与嵌入
模型核心进行的是数学运算(主要是矩阵乘法),因此需要将文本转换为数值矩阵。这个过程主要分为两步:分词(Tokenization)和嵌入(Embedding)。
分词
分词是将文本“切碎”成更小的单元,称为Token。例如:
- 中文里,“北京”可能是一个Token,“的”也是一个Token。
- 英文单词“unhappy”可能被拆分为“un”和“happy”两个Token。
- 每个标点符号、数字通常也会被单独处理。
不同模型的分词规则不同。分词完成后,每个Token会通过一个预训练的词汇表映射为一个唯一的数字ID(可理解为Token在词表中的位置)。大模型的词表规模通常在数万到数十万之间。
嵌入
嵌入过程通过一个可学习的嵌入矩阵,将每个Token的数字ID转换为一个固定维度(如512维)的向量,例如 [0.1, -0.3, ..., 0.8]。这些向量不仅编码了词汇的语义,还能在数学空间中表达词与词之间的关系(如“猫”和“狗”的向量更接近)。
最终,输入文本被转换为n个Token,再经过嵌入变为n个512维的向量,共同组成一个n×512的输入矩阵。
核心要点:文本在计算前被转换为Token序列。序列长度n就是上下文的Token数量,也是模型处理的基本长度单位。
3. 上下文长度的限制
所有大模型都对上下文长度有严格限制。当输入的上下文超过限制时,通常会直接报错。在工程实践中,常见的处理方式是在累计内容超过上下文窗口时,自动丢弃最早的历史数据,保留最新的内容,以确保总长度不超过模型处理能力。
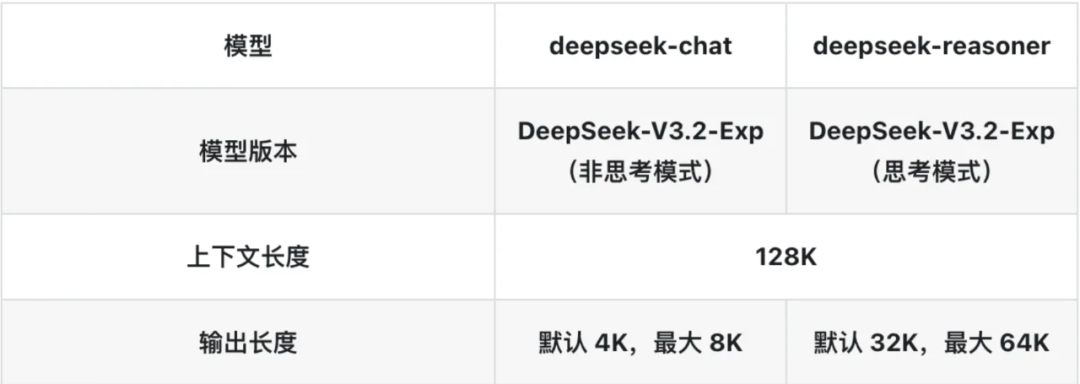
核心要点:上下文长度有限制,且此限制是包含输出长度的。例如,对于一个最大上下文长度为128K、输出令牌预留为4K的模型,理论最大输入长度为124K。
得到输入矩阵后,便进入核心计算环节——Transformer架构。其精髓在于自注意力机制,它让模型能够理解文本中词语间的复杂关系。
1. 自注意力:模型如何“聚焦”重要信息
自注意力机制模拟了人类阅读时关注相关信息的过程。每个自注意力模块包含三个通过训练得到的权重矩阵:Wq、Wk、Wv。
Q、K、V矩阵
每个输入Token的向量与上述三个矩阵相乘,分别生成三个矩阵:
- Query (Q):代表“我想获取什么信息”,主动发起询问。
- Key (K):代表“我拥有什么信息”,用于回应询问。
- Value (V):代表“我包含的实际内容信息”。
计算过程
- 计算注意力分数:用当前Token的Q向量与序列中所有Token的K向量进行内积计算,得到一组注意力分数,分数越高表示关联性越强。
- 生成加权输出:将上一步得到的注意力分数(经Softmax归一化为权重)与所有Token的V向量相乘并求和,得到融合了上下文信息的新向量。
这个过程确保模型生成的回复是基于整个上下文的,而不仅仅是孤立的最新问题。
核心要点:自注意力机制让每个Token都能获取到与之前所有Token相关的信息。特别地,序列中最后一个Token的注意力信息包含了整个上下文的所有信息。
2. 多头注意力:多角度理解文本
单一注意力可能不够全面,因此Transformer采用了多头注意力设计。这相当于多个结构相同但权重不同的自注意力模块并行工作,每个“头”关注文本的不同方面,最终将各头的计算结果拼接并融合。这增强了模型从多角度理解文本的能力。
3. 前馈网络层
一个完整的Transformer层主要由多头自注意力层和前馈网络层构成(还有层归一化等模块,此处不展开)。
- 自注意力层:负责“聚合信息”,将序列中所有位置的信息通过注意力权重整合。
- 前馈网络层:负责“加工和提炼信息”,对聚合后的信息进行非线性变换和特征提取,形成更深层次的理解。
一个简化的Transformer层结构如下图所示:
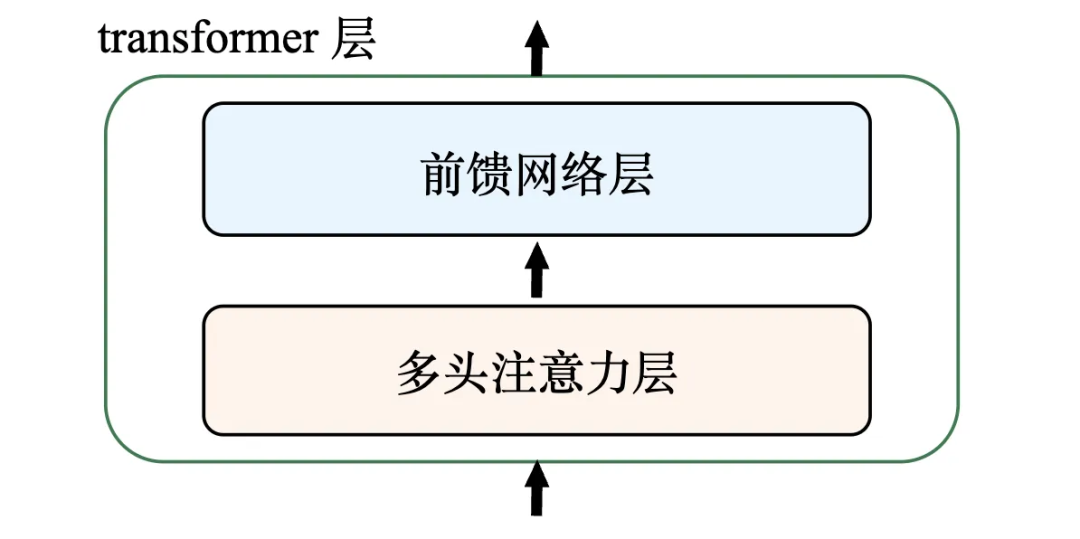
核心要点:自注意力机制关联上下文信息,前馈网络层则负责特征的深层提炼与转换。
4. 大模型之“大”
参数量
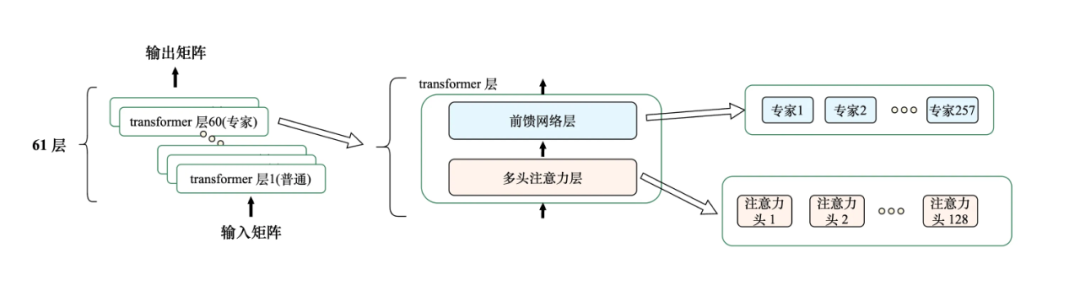
参数量是衡量模型复杂度的核心。以DeepSeek V3为例,它采用MLA(潜在多头注意力)等优化结构,共有61层Transformer层。其庞大参数量主要来自前馈网络层中的大量“专家”(共14906个)。不过,由于每次前向传播只动态激活少量专家(如8个),实际参与计算的参数量约为370亿,总参数量达6710亿。
训练量
庞大的参数需要通过海量数据训练来调整。DeepSeek V3在预训练阶段就使用了14.8万亿Token的数据集,且数据会被重复使用多次进行训练。
输出:从logits到人类语言的“翻译”
经过多层Transformer处理后,我们得到了一个包含丰富语义的“隐藏状态矩阵”。接下来需要将其转换回人类语言。
1. 线性层:从隐藏状态到词汇表映射
线性层充当“翻译官”,将每个Token对应的高维隐藏状态向量,映射为一个长度等于词汇表大小(如5万)的向量。该向量的每个维度对应词汇表中一个词的原始得分(logits)。
2. Softmax:将得分转换为概率分布
线性层输出的logits是原始得分,范围不确定。Softmax函数将其转换为一个概率分布:
- 所有值被映射到(0,1)区间。
- 所有概率之和为1。
- 保持得分的相对大小关系。
例如,logits [2.1, -0.3, 1.8] 经Softmax后可能变为 [0.65, 0.05, 0.30],分别代表三个词被选中的概率。
3. 自回归生成:逐词构建完整回答
模型并非一次性生成整个回答,而是以自回归方式逐词生成:
- 基于完整输入上下文,预测第一个词的概率分布。
- 根据策略(如采样)从分布中选择一个词。
- 将已生成的词追加到输入中,预测下一个词。
- 重复步骤2-3,直至生成结束标志或达到长度限制。
核心要点:模型每次只预测下一个Token,并通过循环迭代生成完整回复。这也是为什么上下文长度限制必须包含输出长度的原因。
4. 生成策略:如何从概率中选择词汇
为了平衡“创造性”和“可靠性”,通常可调节以下参数:
- Temperature(温度):调整概率分布的“尖锐”程度。温度越低(<1),分布越尖锐,模型输出越确定、保守;温度越高,分布越平滑,输出越随机、有创意。温度为0时,则总是选择概率最高的词(贪婪解码)。
- Top-p(核采样):设定一个概率累积阈值p,仅从概率最高的、累积概率刚超过p的最小候选词集合中采样。这能动态限制候选池,避免选择概率极低的生僻词。
在实际的Python工程应用中,可根据场景组合使用这些参数。值得注意的是,DeepSeek V3的代码中目前主要支持temperature参数。
位置编码和长文本外推
1. 位置编码
自注意力机制本身是位置无关的,它无法区分“我咬狗”和“狗咬我”。因此,需要向模型注入位置信息。
- 绝对位置编码:为每个位置分配一个固定的编码向量。缺点是当输入长度超过训练长度时,模型会遇见未见过的位置编码,性能下降。
- 相对位置编码:关注Token之间的相对距离。目前主流方案是RoPE(旋转位置编码)。其核心思想是将位置信息转化为高维空间的旋转角度,在计算Q和K的点积时融入相对位置信息。通过巧妙设计,RoPE天然具有远程衰减特性,即相对距离越远,注意力分数倾向于越低。
核心要点:RoPE等相对位置编码让模型学会了相对位置关系,使其在某种程度上能泛化到比训练时更长的序列。
2. 长文本外推
即使使用相对位置编码,当输入长度远超训练长度时,模型性能仍会下降。为此,研究者提出了多种外推策略:
- 插值法:如将推理时的长位置索引压缩到模型训练时所熟悉的位置索引范围内。
- 选择策略法:如滑动窗口注意力,每个Token只关注其附近固定窗口内的Token,或通过策略从全局挑选部分区间进行计算,以节省计算开销。这类方案通常是有损的。
3. 长文本训练范式:短文本预训练 + 长文本微调
直接用长文本从头训练成本极高(计算复杂度与序列长度平方成正比),且高质量长文本数据稀缺。因此主流做法是:
- 阶段一(基础预训练):在海量高质量短文本(如2K/4K/8K长度)上训练,让模型掌握核心语言能力和推理逻辑。
- 阶段二(长度扩展微调):使用外推技术,在相对较少的长文本数据上对模型进行微调,教会它在更长上下文中运用已学到的能力。
核心要点:尽管通过外推和微调能支持长上下文,但由于训练数据的分布差异和外推方法的有损性,模型在超长文本下的表现通常仍会劣于其在标准训练长度下的表现。
实践与思考
了解原理后,这对我们的工程实践有何指导意义?
1. 多模态输入的实现原理
以DeepSeek V3为例,其输入主要为文本。对于图像理解,一种可能的工程实现是:先用专门的视觉模型(如OCR、目标检测)对图片进行分析,将分析结果(如识别出的文字、物体列表)以文本形式描述出来,再将此描述文本与用户问题一同输入大模型。这解释了为什么纯文本模型有时也能处理图像问题,但其准确度受限于前端视觉模型的能力和文本描述的完整性。
2. 通过控制上下文提高系统稳定性
模型在短文本(如4K)上训练最充分,效果最稳定。因此,在构建应用(如Agent)时,应尽量精简系统提示词(Prompt)和工具描述,避免不必要的规则堆砌。过长的上下文和复杂的指令容易导致模型输出混乱,例如输出格式不符合解析要求,甚至陷入循环输出。
3. 耗时分析与优化
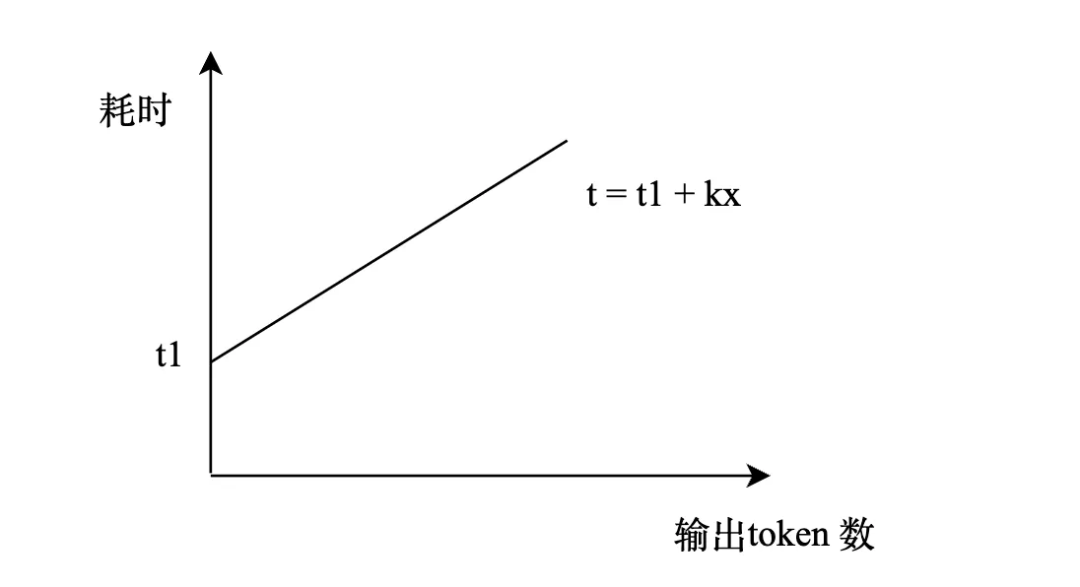
一次模型调用的耗时主要取决于:
- 首Token耗时:与输入上下文长度的平方成正比,因为需要为所有输入Token计算注意力。
- 后续Token生成耗时:每个新Token的生成耗时与当前上下文长度(包含已生成的输出)大致成正比。
- 总生成耗时:与生成的Token数量线性相关。
优化实践:
- 减少输入上下文长度:这是最有效的优化手段,因为首Token耗时与长度平方相关。
- 限制最大输出长度:通过接口参数或Prompt约束,避免模型生成冗余内容。
4. 如何有效管理复杂上下文:多Agent协同
当业务规则复杂必然导致Prompt很长时,可以考虑采用多Agent协同架构:
- 设计一个轻量级的主Agent,负责理解用户意图和任务规划,其Prompt只需包含各子Agent的能力描述,而非具体规则。
- 将不同功能拆分为多个子Agent,每个子Agent专注于一个简单、明确的任务,拥有自己精简的Prompt。
- 主Agent将复杂任务拆解后,调度相应的子Agent执行。
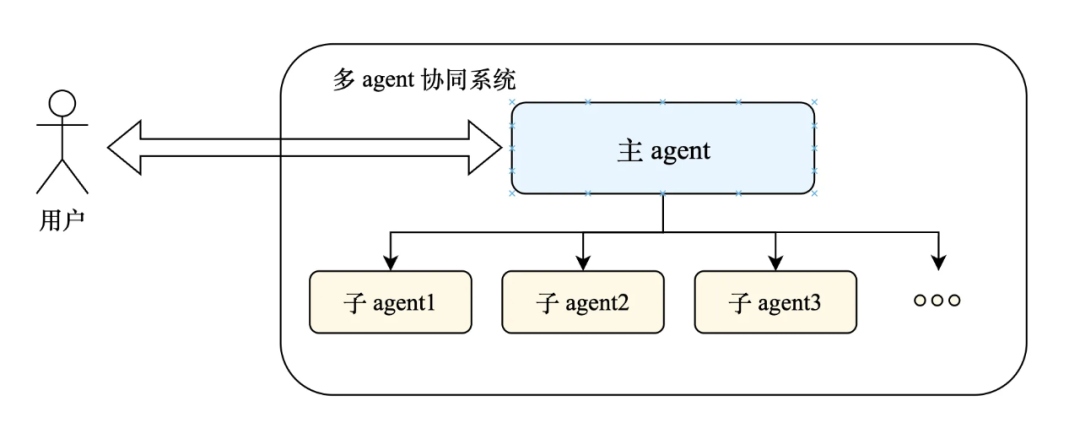
优势:虽然调用次数可能增加,但每次调用的上下文长度大幅缩短。由于耗时与长度平方成正比,将一次12K的调用拆分为4次3K的调用,理论计算开销从144单位降至36单位,整体耗时可能反而降低。
5. 历史对话管理
历史对话积累会导致上下文膨胀。工程上可采用更智能的策略,例如:
- 将历史对话向量化存储。
- 当用户发起新提问时,先从其历史中检索最相关的片段,仅将这些相关片段作为历史上下文输入模型,而非全部历史。
写在最后
以上内容基于个人对人工智能大模型原理的理解及工程实践的总结,希望能为大家提供有价值的参考。
参考
- 位置编码详解:Transformer模型理解语序的核心机制与长文本外推技术. https://yunpan.plus/t/2293-1-1
- 大模型RoPE位置编码与外推性:Sinusoidal、PI与NTK全解析. https://yunpan.plus/t/2297-1-1
- Transformer旋转位置编码RoPE原理与实战:从数学推导到LLaMA源码解析. https://yunpan.plus/t/2299-1-1
- Transformer词嵌入与位置编码详解:从原理到PyTorch实战. https://yunpan.plus/t/2300-1-1
- Transformer架构深度解析:自注意力机制原理与模型演进. https://yunpan.plus/t/2298-1-1
- Transformer架构深度解析:自注意力机制与编码器-解码器实现原理. https://yunpan.plus/t/2301-1-1
- DeepSeek-R1模型架构深度解析:MLA与MoE技术详解. https://yunpan.plus/t/2302-1-1
- Transformer模型详解:Attention is All You Need论文逐行代码实现. Harvard NLP. https://yunpan.plus/t/2303-1-1
 发表于 2025-12-10 18:20:04
|
查看: 189|
回复: 0
发表于 2025-12-10 18:20:04
|
查看: 189|
回复: 0
