做一个小夜灯有很多方法,但能否让它“听懂你说话”?这次,我利用MAX78000芯片内置的CNN加速器,从头训练了一个定制化的语音唤醒模型,打造了一个真正由AI芯片驱动的离线声控小夜灯。从模型训练、功耗优化到最终硬件落地,本文将完整呈现开发流程与实战经验,希望能为你的边缘AI项目带来启发。

项目介绍
本项目是基于MAX78000微控制器实现的一款具备离线语音识别功能的小夜灯。核心是利用MAX78000的神经网络加速器,实时识别特定的语音控制命令,并通过PWM(脉宽调制)技术对USB供电的LED光源进行开关及亮度调节。
项目设计思路
MAX78000的最大特点在于能够以超低功耗运行神经网络,其定位与边缘计算、功耗敏感型应用场景高度契合。你是否遇到过以下情形?
- 上床睡觉时才发现灯还没关。
- 晚上回家或起夜时在黑暗中摸索开关。
- 宿舍熄灯后,没人愿意下床关灯。
正是这些生活中的小痛点,促使我萌生了制作一个语音控制小夜灯的想法。MAX78000的低功耗AI特性,使其成为实现这一想法的理想平台。
首先需要解决硬件载体。我找到了两个备选光源:一个磁吸式LED照明灯和一个USB小氛围灯。


确定硬件后,剩下的核心任务有三个:
- 设计语音指令并完成识别网络的训练与量化。
- 设计小夜灯控制系统的硬件电路。
- 完成识别工程的部署与系统集成。
根据开关和亮度调节这两大核心需求,我设定了以下语音指令词条:
- 开灯指令:“开灯”
- 关灯指令:“关灯”
- 调节指令:“亮一点”、“暗一点”
- 定时指令:“定时”(功能预留)
语音识别网络的训练与量化主要遵循官方流程:基于 ai8x-training 仓库进行模型训练,再通过 ai8x-synthesis 仓库进行量化,并使用工具将训练好的模型转换为C代码。
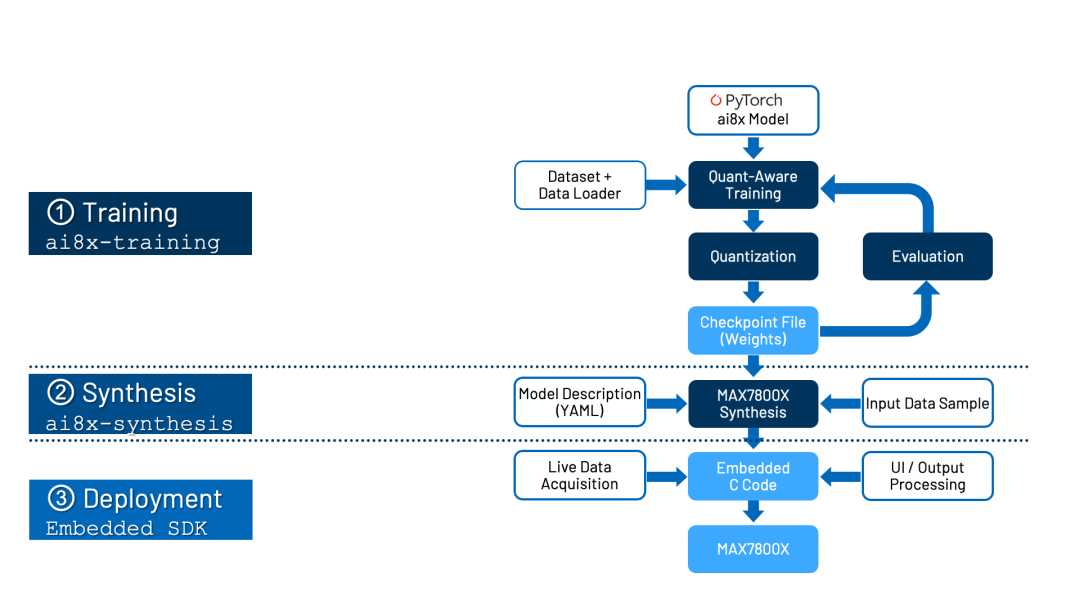
硬件方面,除了主控MAX78000评估板和麦克风,额外增加了一个支持PWM控制的MOS管驱动模块来驱动小夜灯。系统通过板载麦克风采集语音,经MAX78000的CNN加速器识别出关键词后,由芯片内部的TMR外设生成PWM信号,进而控制小夜灯。
整体系统设计框图如下:


素材收集思路
本项目为定制化开发,无法使用公开语音数据集,因此需要自行收集关键词语音数据。我采用了录音采集和语音合成两种方式。
录音采集有两种思路:一是连续录制长音频后分割;二是直接按需录制单条音频。我选择第二种,但官方提供的 VoiceRecorder.py 脚本无法直观评估录音质量。受 Edge Impulse 平台数据采集界面的启发,我决定用Python自行实现一个带波形实时显示的录音脚本,确保每次录音清晰完整。
语音数据质量直接决定最终识别效果。前期我曾因录音音量过小,导致模型几乎无法识别任何词条。因此,必须严格按照模型输入要求(1秒时长、16kHz采样率、单声道WAV格式)进行录制,并保证音量适中。
以下为改进后的录音脚本 record.py,它使用 pyaudio 录音,并通过 numpy 和 matplotlib 实时显示波形,便于质检。脚本还加入了400ms的起始偏移,以规避按键到开始说话之间的人为反应延迟。
import wave
import pyaudio
import os
import shutil
import time
import numpy
import matplotlib.pyplot as plt
# 定义数据流块
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
# 录音时间
RECORD_SECONDS = 1
# 要写入的文件名
WAVE_OUTPUT_FILENAME = "output.wav"
# 创建PyAudio对象
p = pyaudio.PyAudio()
# 打开数据流
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
OFF_TIME = int(RATE / CHUNK * 0.4)
# 开始录音
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)+OFF_TIME):
data = stream.read(CHUNK)
if i >= OFF_TIME:
frames.append(data)
else:
continue
print("* done recording")
# 停止数据流
stream.stop_stream()
stream.close()
# 关闭PyAudio
p.terminate()
# 写入录音文件
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
# 只读方式打开WAV文件
wf = wave.open('./output.wav', 'rb')
p = pyaudio.PyAudio()
stream = p.open(format = p.get_format_from_width(wf.getsampwidth()),
channels = wf.getnchannels(),
rate = wf.getframerate(),
output = True)
nframes = wf.getnframes()
framerate = wf.getframerate()
# 读取完整的帧数据到str_data中,这是一个string类型的数据
str_data = wf.readframes(nframes)
wf.close()
# 将波形数据转换成数组
wave_data = numpy.fromstring(str_data, dtype=numpy.short)
# 将wave_data数组改为2列,行数自动匹配
wave_data.shape = -1,CHANNELS
# 将数组转置
wave_data = wave_data.T
def time_plt():
# time也是一个数组,与wave_data[0]或wave_data[1]配对形成系列点坐标
time = numpy.arange(0, nframes)*(1.0/framerate)
# 绘制波形图
plt.subplot(211)
plt.plot(time, wave_data[0], c='r')
if CHANNELS == 2:
plt.subplot(212)
plt.plot(time, wave_data[1], c='g')
plt.xlabel('time (seconds)')
plt.show()
def freq():
# 采样点数,修改采样点数和起始位置进行不同位置和长度的音频波形分析
N=44100
start=0 # 开始采样位置
df=framerate/(N-1) # 分辨率
freq=[df*n for n in range(0,N)] # N个元素
wave_data2=wave_data[0][start:start+N]
c=numpy.fft.fft(wave_data2)*2/N
# 常规显示采样频率一半的频谱
d=int(len(c)/2)
# 仅显示频率在4000以下的频谱
while freq[d] > 4000:
d-=10
plt.plot(freq[:d-1], abs(c[:d-1]), 'r')
plt.show()
def main_plot():
time_plt()
# freq()
def mkdir(path):
folder = os.path.exists(path)
if not folder: #判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(path) #makedirs 创建文件时如果路径不存在会创建这个路径
if __name__ == '__main__':
main_plot()
laber = "kaideng"
mkdir(laber)
str_time = str(int(time.mktime(time.localtime())))
cp_name = './'+str(laber)+'/'+str(laber)+'_'+str_time+'.wav'
print("file:", cp_name)
shutil.copy('./output.wav', cp_name)
语音合成部分,则使用 pyttsx3 库开发脚本 tts_gen.py,通过 pypinyin 库将中文关键词转换为拼音标签,并生成语音文件。
from ast import keyword
import pyttsx3
import os , shutil, time
from pypinyin import lazy_pinyin
def mkdir(path):
folder = os.path.exists(path)
if not folder: #判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(path) #makedirs 创建文件时如果路径不存在会创建这个路径
if __name__ == '__main__':
# main_plot()
key_word = "开灯"
pinyin_list = lazy_pinyin(key_word)
laber = ''.join(x for x in pinyin_list)
laber = laber +'_tts'
print(laber)
mkdir(laber)
str_time = str(int(time.mktime(time.localtime())))
cp_name = './'+str(laber)+'/'+str(laber)+'_'+str_time+'.mp3'
print("file:", cp_name)
engine = pyttsx3.init() # object creation5117
engine.save_to_file(key_word,cp_name)
engine.runAndWait()
engine.stop()
由于 pyttsx3 输出为MP3格式,还需使用 audio_transfor.py 脚本(依赖 ffmpy 库)将其转换为WAV格式。
from ffmpy import FFmpeg
import os
# MP3转wav
def audio_transfor(audio_path: str, output_dir: str):
ext = os.path.basename(audio_path).strip().split('.')[-1]
if ext != 'mp3':
raise Exception('format is not mp3')
result = os.path.join(output_dir, '{}.{}'.format(os.path.basename(audio_path).strip().split('.')[0], 'wav'))
filter_cmd = '-f wav -ac 1 -ar 16000'
ff = FFmpeg(
inputs={
audio_path: None}, outputs={
result: filter_cmd})
print(ff.cmd)
ff.run()
return result
def handle(audio_dir: str, output_dir: str):
for x in os.listdir(audio_dir):
audio_transfor(os.path.join(audio_dir, x), output_dir)
if __name__ == '__main__':
handle('ttsmp3', 'ttswav')
训练实现过程
在确保语音数据质量后,即可开始模型训练流程,主要包括:添加数据、调整数据加载器、修改模型参数、训练、量化、评估与综合。
1. 添加自定义命令词数据
在 ai8x-training/data/KWS/raw/ 目录下为每个新关键词创建文件夹(如 kaideng),并放入对应的WAV文件。若 processed 文件夹已存在,需删除它以强制数据加载器重新生成包含新标签的数据集。
2. 数据加载器调整
修改 ai8x-training/datasets/kws20.py 文件。首先,在 class_dict 字典中按字母顺序添加新标签并赋予唯一整数值。
class_dict = {'backward': 0, 'bed': 1, 'bird': 2, 'cat': 3, 'dingshi': 4, 'dog': 5, 'down': 6,
'eight': 7, 'five': 8, 'follow': 9, 'forward': 10, 'four': 11, 'go': 12,'guandeng': 13,
'happy': 14, 'house': 15, 'kaideng': 16, 'learn': 17, 'left': 18, 'marvin': 19, 'nine': 20,
'no': 21, 'off': 22 ,'on': 23, 'one': 24, 'right': 25, 'seven': 26,
'sheila': 27, 'six': 28, 'stop': 29, 'three': 30,'tiaoanyidian': 31, 'tiaoliangyidian': 32,'tree': 33, 'two': 34,
'up': 35, 'visual': 36, 'wow': 37, 'yes': 38, 'zero': 39}
然后,定义新的数据集 KWS_25(25个关键词+1个未知类),并设置各类别的权重(与样本数成反比)。
{
'name': 'KWS_25', # 25 keywords
'input': (128, 128),
'output': ('up', 'down', 'left', 'right', 'stop', 'go', 'yes', 'no', 'on', 'off', 'one',
'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'zero','dingshi', 'guandeng', 'kaideng', 'tiaoliangyidian','tiaoanyidian',
'UNKNOWN'),
'weight': (1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 28, 28, 28, 28, 28,0.14),
'loader': KWS_25_get_datasets,
}
最后,创建对应的数据加载函数。
def KWS_25_get_datasets(data, load_train=True, load_test=True):
return KWS_get_datasets(data, load_train, load_test, num_classes=25)
3. 修改网络模型参数
更新 ai8x-training/models/ai85net-kws20.py 中模型初始化部分的 num_classes 参数,使其等于关键词数量+1(未知类)。
# num_classes = n keywords + 1 unknown
def __init__(
self,
num_classes=26, # was 21
num_channels=128,
dimensions=(128, 1),
fc_inputs=7,
bias=False,
**kwargs
):
4. 训练
在Ubuntu环境下,激活训练环境后,执行训练命令。首次训练会花较长时间处理数据。
python train.py --epochs 100 --optimizer Adam --lr 0.001 --wd 0 --deterministic --compress policies/schedule_kws20.yaml --model ai85kws20net --dataset KWS_25 --confusion --device MAX78000 "$@"
训练日志和结果会保存在 ai8x-training/logs/ 目录下。

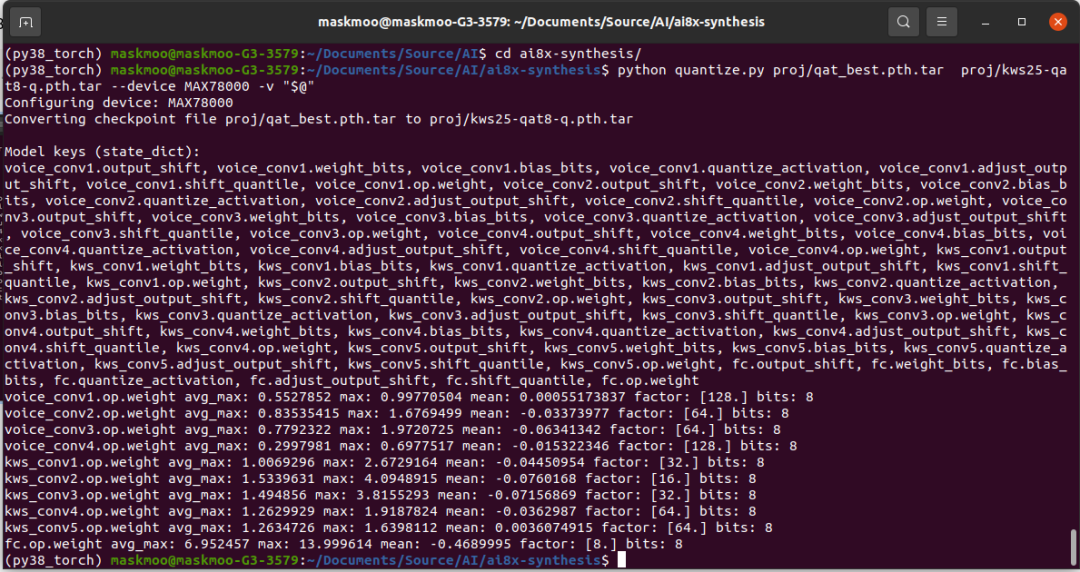
5. 量化
将训练好的模型文件 (qat_best.pth.tar) 拷贝至 ai8x-synthesis/proj/ 目录,执行量化命令,生成适用于MAX78000的8位量化模型。
python quantize.py proj/qat_best.pth.tar proj/kws25-qat8-q.pth.tar --device MAX78000 -v "$@"
6. 评估和综合
量化后,可对模型进行评估。评估完成后,使用 ai8xize.py 脚本将量化模型转换为可在MAX78000上运行的C代码。
python ai8xize.py --test-dir demo --prefix kws25_v1 --checkpoint-file proj/kws25-qat8-q.pth.tar --config-file networks/kws20-hwc.yaml --softmax --device MAX78000 --timer 0 --display-checkpoint --verbose "$@"
7. 更新Demo应用程序
将上一步生成的 cnn.c, cnn.h, weights.h, sampledata.h 四个文件替换到 kws20_demo 工程中。更新 main.c 中的关键词数组以匹配你的词表。
const char keywords[NUM_OUTPUTS][20] = {"up", "down", "left", "right", "stop", "go", "yes", "no", "on", "off", "one","two", "three", "four", "five", "six", "seven", "eight", "nine", "zero","dingshi", "guandeng", "kaideng", "tiaoliangyidian","tiaoanyidian","UNKNOWN"};
最后,在语音识别回调函数中添加PWM控制逻辑,实现关键词到具体动作的映射。
/* find detected class with max probability */
ret = check_inference(ml_softmax, ml_data, &out_class, &probability);
PR_DEBUG("----------------------------------------- \n");
if (!ret) {
PR_DEBUG("LOW CONFIDENCE!: ");
}
else{
if(out_class == 21){// guangdeng
if(PWM_CTRL_STATE != 21)
{
SetPWMDuty(1);
PWM_CTRL_Disable();
// MXC_GPIO_OutClr(MXC_GPIO2, MXC_GPIO_PIN_4);
PWM_CTRL_STATE = 21;
PR_DEBUG("guandeng \r\n");
}
}
else if(out_class == 22){//kaideng
if(PWM_CTRL_STATE != 22)
{
PWMTimer_Setup();
PWM_CTRL_STATE = 22;
PWM_CTRL_DUTY = 100;
PR_DEBUG("kaideng \r\n");
}
}
else if(out_class == 20){//dingshi
}
else if(out_class == 23){//liangyidian
PWM_CTRL_DUTY = PWM_CTRL_DUTY + PWM_CTRL_DUTY_OFFSET;
if(PWM_CTRL_DUTY>80){
PWM_CTRL_DUTY = 80;
}
SetPWMDuty(PWM_CTRL_DUTY);
PR_DEBUG("liangyidian \r\n");
}
else if(out_class == 24){//anyidian
PWM_CTRL_DUTY = PWM_CTRL_DUTY - PWM_CTRL_DUTY_OFFSET;
if(PWM_CTRL_DUTY<=20){
PWM_CTRL_DUTY = 20;
}
SetPWMDuty(PWM_CTRL_DUTY);
PR_DEBUG("anyidian \r\n");
}
}
PR_DEBUG("Detected word:(%d) %s (%0.1f%%)",out_class, keywords[out_class], probability);
PR_DEBUG("\n----------------------------------------- \n");
实现结果展示
最终实现的声控小夜灯识别效果良好,能准确响应“开灯”、“关灯”、“亮一点”、“暗一点”等指令。硬件上采用USB接口输出控制,方便连接各类USB供电的小灯。具体效果可观看演示视频。


项目总结与踩坑记录
- Ubuntu环境问题:系统自动更新内核可能导致NVIDIA显卡驱动失效。解决办法是禁止系统自动更新内核,或在更新后重装驱动。
- 语音数据收集:这是决定模型效果的关键,也耗时最长。主要遇到三个问题:
- 数据可视化:自行编写带波形显示的录音脚本,便于质量控制。
- 录音音量:初期使用耳机麦克风导致音量过小,模型无法识别。需保证录音音量适中。
- 录音延迟:Python
pyaudio 库存在约200ms的初始延迟,通过在脚本中加入偏移截断处理来规避。
- 工程部署问题:
- 电平匹配:MAX78000的IO口支持3.3V和1.8V,需在GPIO初始化时正确配置。
- PWM控制:需要仔细查阅数据手册和例程,正确配置TMR外设以生成稳定的PWM信号。
后续计划
目前模型主要基于我个人的语音数据训练,对于其他人的语音识别效果可能有所下降。未来的改进方向是收集更多样化的语音数据,重新训练以提升模型的泛化能力。对于想自行移植的朋友,也需要按照上述流程收集自己的语音数据进行训练,才能获得最佳识别效果。
本项目完整展示了从 人工智能 模型训练到嵌入式端侧部署的全流程,体现了MAX78000在超低功耗边缘AI应用中的强大潜力。
 发表于 2025-12-11 03:02:20
|
查看: 245|
回复: 0
发表于 2025-12-11 03:02:20
|
查看: 245|
回复: 0
