在掌握了卷积神经网络(CNN)的基础层之后,我们如何构建更强大、更高效的网络?又该如何稳定、高效地训练它们?本篇将深入探讨CNN的架构演进与核心训练技巧,涵盖从归一化、Dropout等关键组件,到VGG、ResNet等经典设计,再到权重初始化、数据增强、迁移学习等实战策略。
一、归一化层:稳定深度网络训练的基石
归一化层的核心思想是两段式操作:先计算输入数据的统计量(均值与标准差)进行标准化,将其转化为均值为0、方差为1的分布;随后引入可学习的缩放(scale)与平移(shift)参数进行重新调整。这样既能稳定训练过程,又能保留模型的表达能力。
所有归一化方法都遵循“先归一化、再仿射变换”的流程,差异主要在于统计量的计算维度不同。
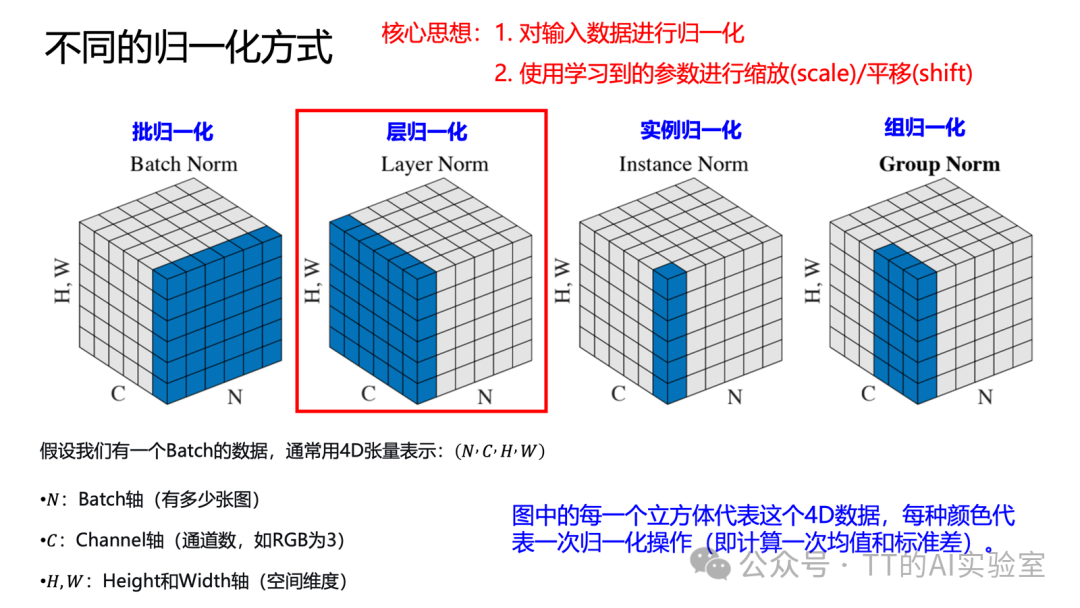
- 层归一化(Layer Normalization):目前在 Transformer 架构中最常用。它对每个样本独立计算其所有通道、高度和宽度的统计特性,不依赖Batch维度,因此在小批量或单样本场景下表现稳定。
- 批归一化(Batch Normalization):在mini-batch维度上为每个通道计算统计量,效果依赖于batch size,在卷积网络中应用广泛。
- 实例归一化(Instance Normalization):对每个样本的每个通道分别进行归一化,常见于风格迁移等任务。
- 组归一化(Group Normalization):将通道分组,在组内计算统计量,在不同batch size下能保持更稳定的表现。

归一化的本质并非简单压缩数值范围,而是通过重塑特征分布来改善梯度传播条件,让更深、更复杂的网络得以稳定训练。
二、正则化利器:Dropout(随机失活)
Dropout是一种在训练阶段引入随机性的正则化技术,旨在抑制过拟合、提升模型泛化能力。其核心操作是:在每次前向传播时,以固定概率(如0.5)随机将当前层的部分神经元输出置零,使其暂时“失活”。
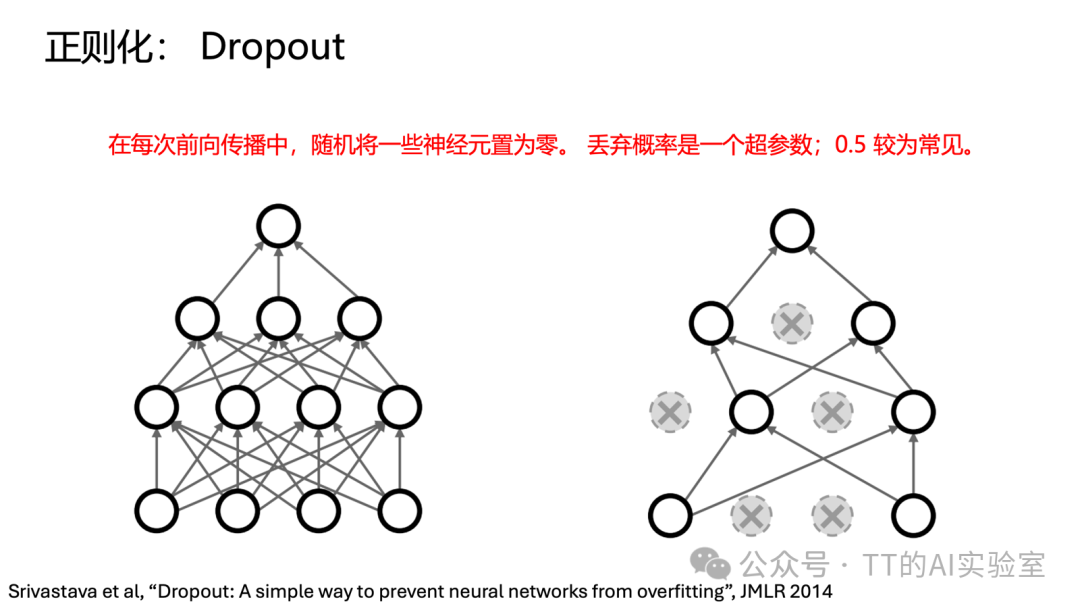
这种机制迫使网络不能过度依赖少数特定神经元或特征,必须学习更分散、冗余且鲁棒的表示。在训练阶段,Dropout通过随机屏蔽神经元增加了拟合难度。
# Dropout训练阶段示例代码(简化版)
p = 0.5 # 神经元保留概率
def train_step(X):
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # 生成Dropout掩码
H1 *= U1 # 应用Dropout,丢弃部分神经元
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p
H2 *= U2
out = np.dot(W3, H2) + b3
# ... 后续反向传播与参数更新

而在测试阶段,所有神经元都保持激活。为了保持与训练阶段期望输出的一致性,需要对激活值进行缩放(乘以保留概率 p)。
# Dropout测试阶段示例代码
def predict(X):
# 注意:对激活值进行缩放
H1 = np.maximum(0, np.dot(W1, X) + b1) * p
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p
out = np.dot(W3, H2) + b3

Dropout的本质是在结构层面引入随机扰动,通过训练时使用不同的“动态子网络”,最终在测试时集成为一个更强大的模型,有效提升泛化能力。
三、经典CNN架构的演进之路
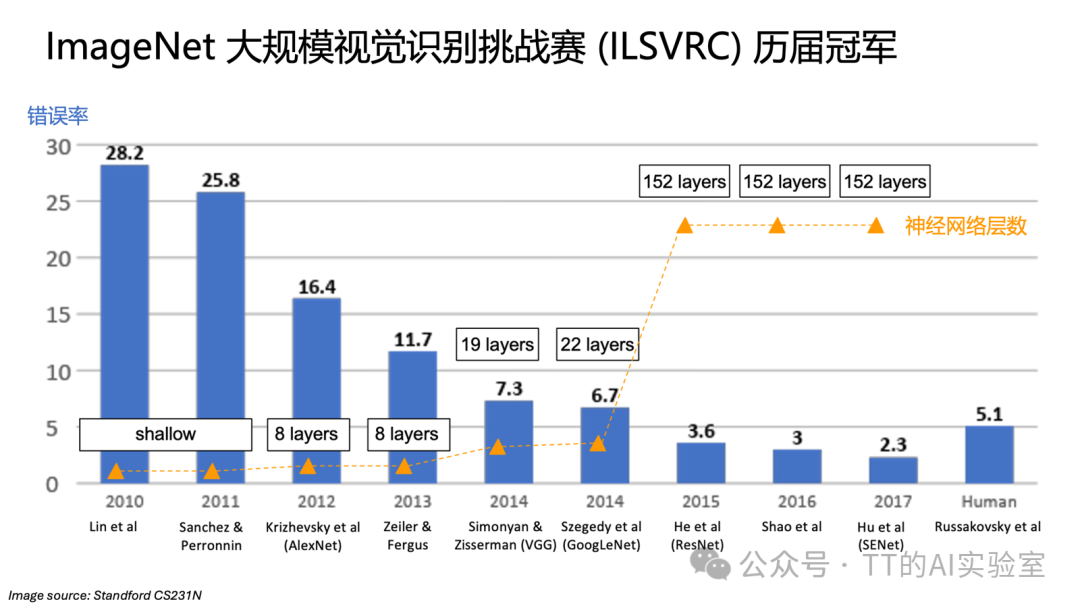
回顾历史,一个清晰趋势是:随着网络层数大幅增加,图像识别错误率持续下降,甚至超越人类水平。更深网络带来更强表达能力,也引发了新的结构与优化挑战。
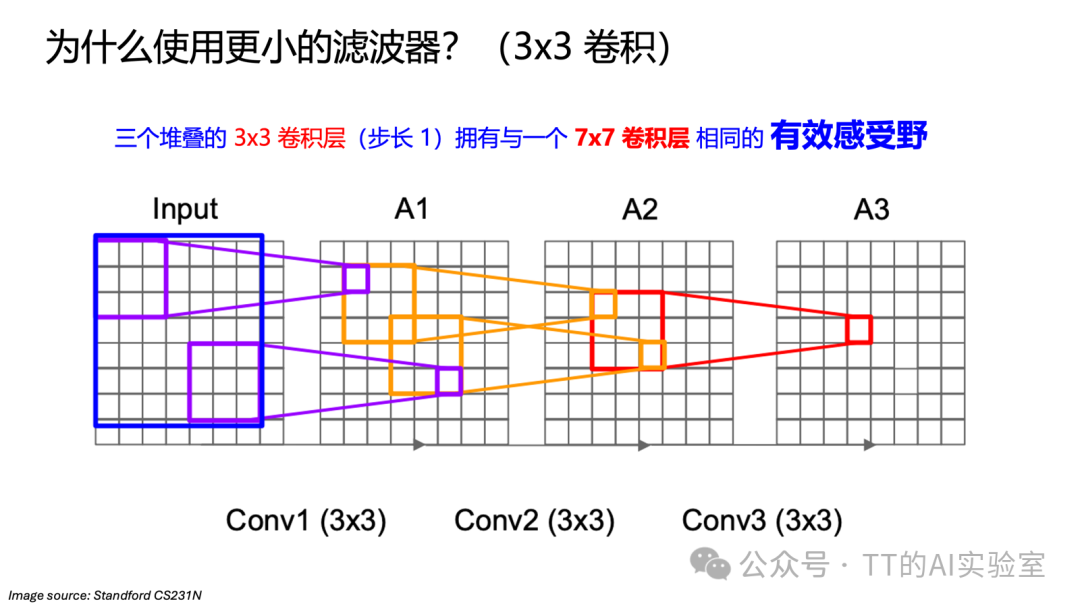
1. VGG的设计智慧:为何执着于3×3卷积?
从AlexNet到VGG,一个关键变化是卷积核尺寸的选择。VGG的核心思想是堆叠多个较小的3×3卷积层,而非使用单个大卷积核(如7×7)。这样做优势显著:
- 相同的有效感受野:三个堆叠的3×3卷积(步长1)拥有与一个7×7卷积相同的有效感受野。
- 更高的参数效率:假设输入输出通道数均为C,三个3×3卷积参数量为3×(3×3×C×C)=27C²,远少于一个7×7卷积的49C²。
- 更强的非线性能力:多层小卷积之间可以插入更多激活函数,引入更多非线性变换,学习更复杂的特征表达。

这种“深而小”的设计,为后续更深的网络奠定了坚实的结构基础。
2. ResNet:破解深度网络的退化难题
然而,当网络层数继续增加,一个反直觉的现象出现了:在普通CNN中,56层网络的训练误差竟高于20层网络。
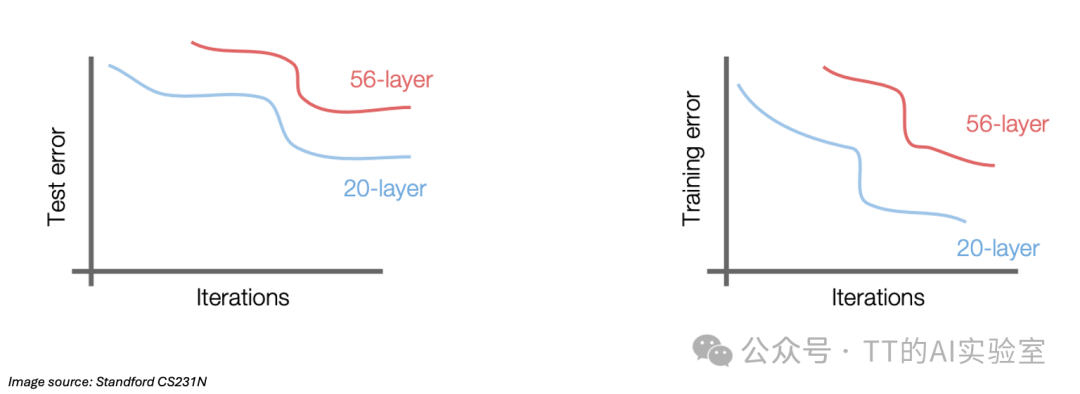
这并非过拟合,而是优化困难导致的“退化问题”。理论上,深层网络至少应能通过恒等映射模拟浅层网络,但实际训练中难以实现。
ResNet的突破性解决方案是引入残差连接(Residual Connection)。它通过捷径连接(Skip Connection)将输入 x 直接加到卷积层的输出 F(x) 上,使网络不再直接学习目标映射 H(x),而是学习残差映射 F(x) = H(x) - x,最终输出为 F(x) + x。
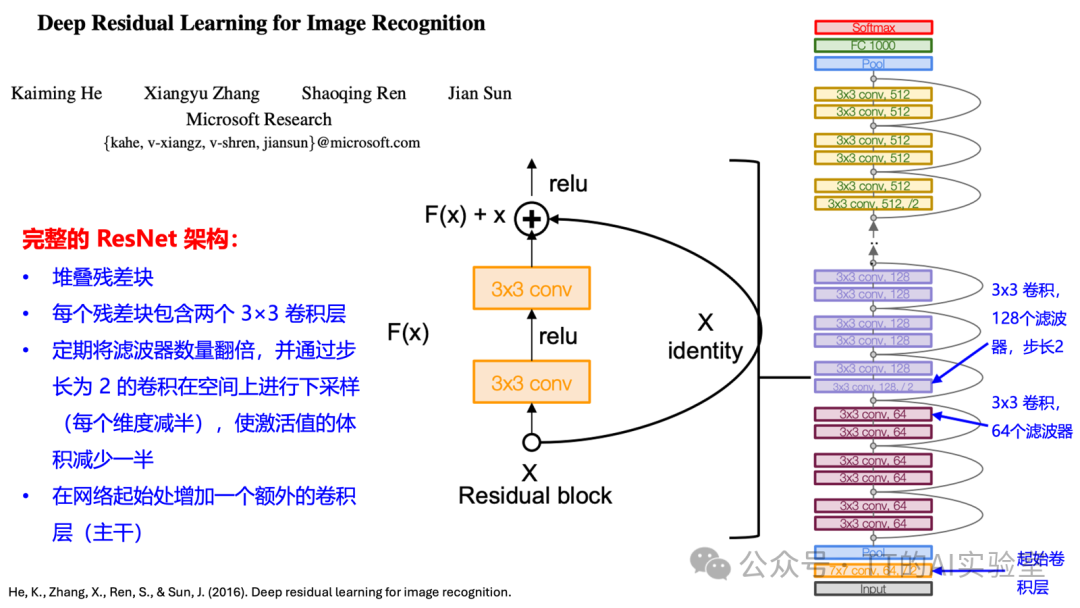
这种设计妙在:当某些层“无用”时,模型只需将残差 F(x) 学习为接近0,即可自然退化为恒等映射(F(x)+x ≈ x),极大降低了优化难度。ResNet由堆叠的残差块构成,每个块通常包含两个3×3卷积层,通过跳跃连接实现特征相加,确保了训练上百层深度网络成为可能。
四、训练CNN的五大实用技巧
优秀的架构需要配以精良的训练策略。以下是决定模型最终表现的几个关键环节。
1. 权重初始化:寻找传播的平衡点
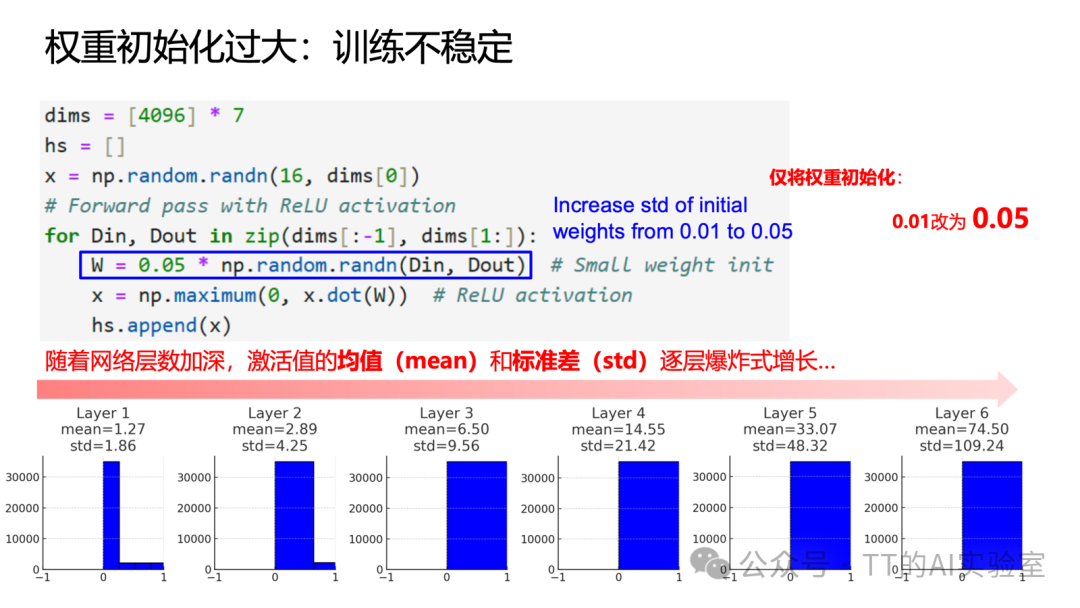
权重初始化的目标是保持信号在前向传播中的稳定性。初始化不当会导致两种问题:
- 权重过小:激活值逐层衰减至接近零,梯度消失。
- 权重过大:激活值逐层爆炸,梯度不稳定。

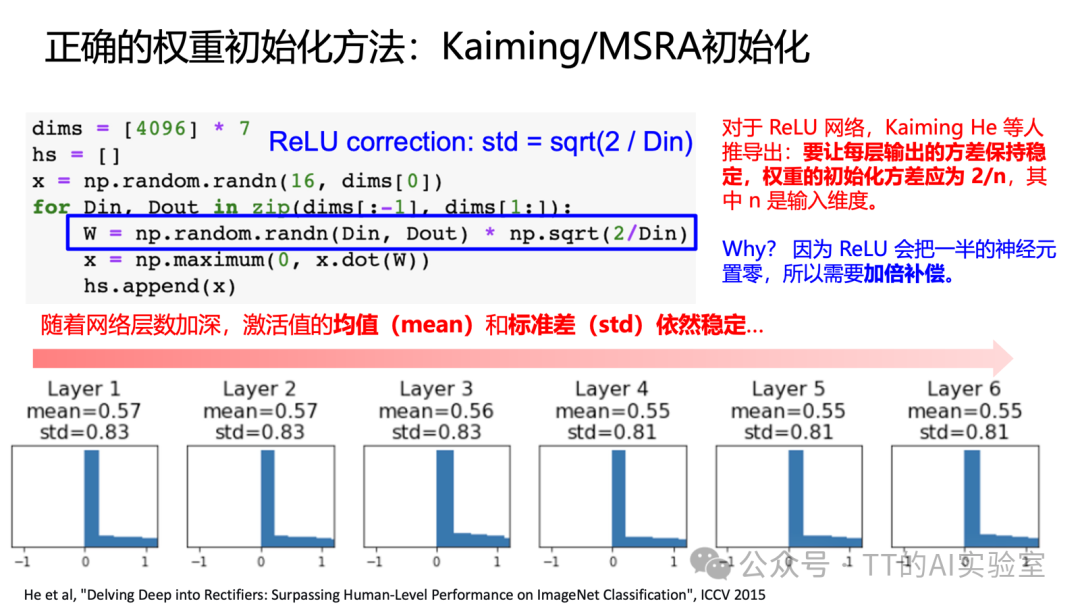
对于使用ReLU激活函数的网络,Kaiming初始化(He初始化) 是标准方案。其原理是将权重初始化为均值为0、方差为 2 / n 的分布,其中 n 是权重张量的输入维度(对于卷积层,n = kernel_size * kernel_size * in_channels)。这样可以补偿ReLU将一半神经元置零的影响,维持前向传播中激活值方差的稳定。
2. 数据预处理与增强:从源头提升模型鲁棒性
- 数据预处理:通常对每个颜色通道(R, G, B)计算整个数据集的均值和标准差,然后对输入图像进行减均值、除标准差的标准化。这能稳定输入分布,加速收敛。实践中常直接使用ImageNet的统计量以与预训练模型保持一致。
- 数据增强:通过对训练图像施加随机变换来增加数据多样性,是防止过拟合、提升泛化能力的低成本高效方法。
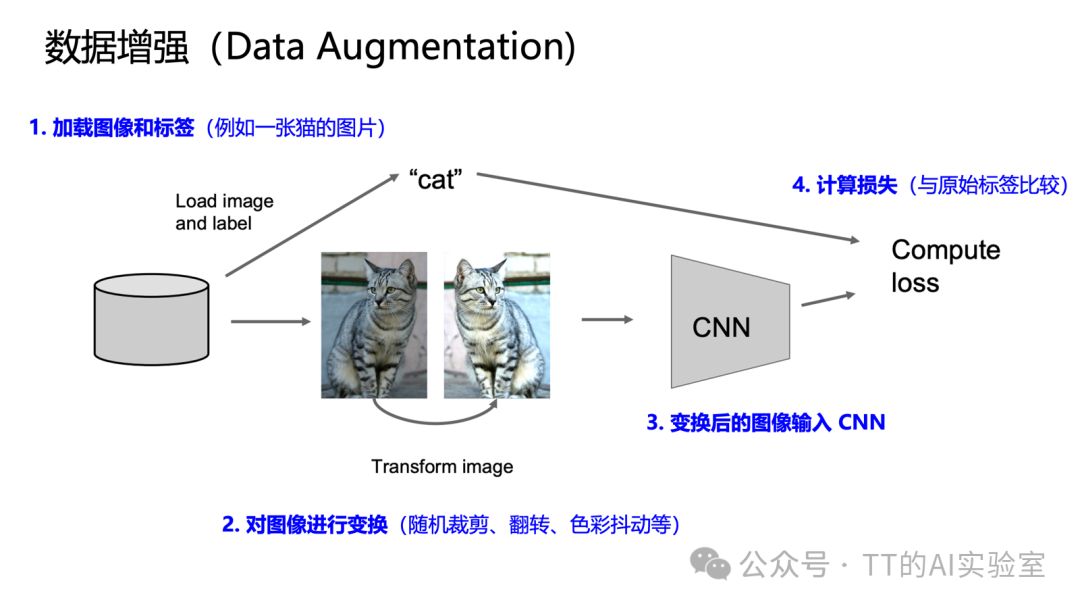
常见增强方法包括:
- 水平翻转:适用于具有对称性的物体。
- 随机裁剪与缩放:最常用的策略,如先将短边缩放到一定尺寸,再随机裁剪出固定区域。
- 色彩抖动:随机调整亮度、对比度、饱和度等。
- 随机遮挡:随机用灰色块遮盖图像部分区域,强迫模型关注整体而非局部。

此外,测试时增强(对同一张图做多种变换并平均预测结果)也能带来小幅性能提升。
3. 迁移学习:小数据场景下的“作弊器”
当自有数据规模有限时,迁移学习是首选策略。其核心是利用在大规模数据集(如ImageNet)上预训练好的模型,将其学到的通用视觉特征迁移到新任务上。
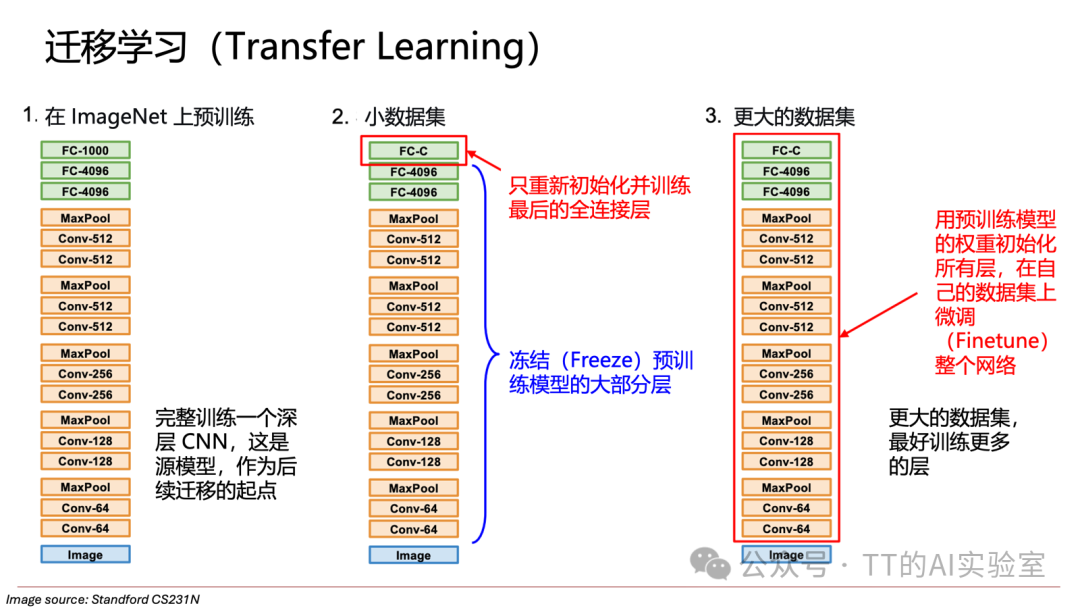
具体策略取决于新数据集的规模及其与预训练数据任务的相似性:
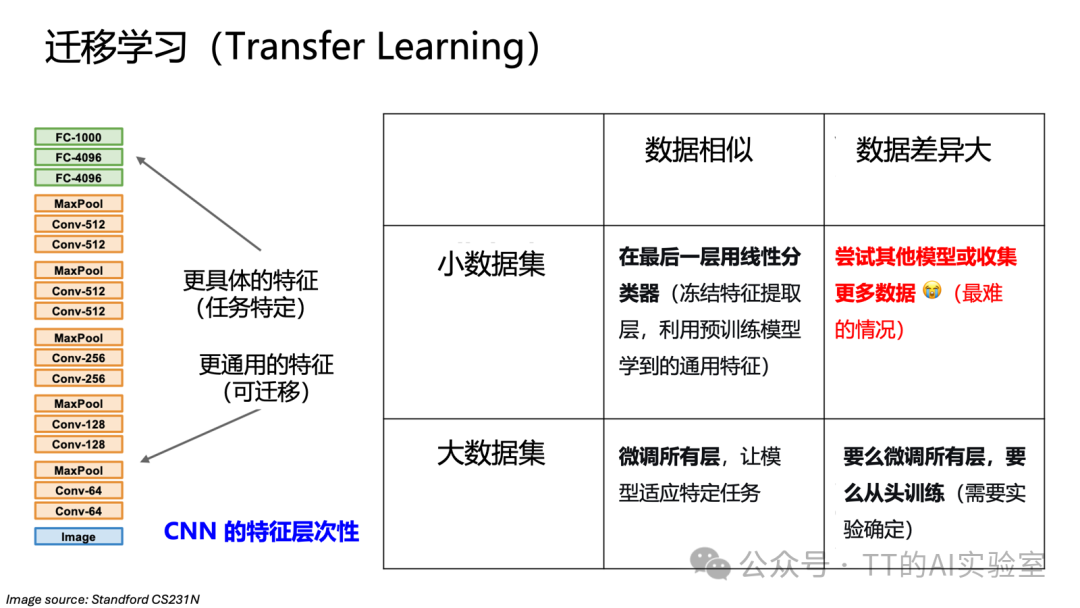
- 数据量小,任务相似:冻结预训练模型的大部分层,仅重新训练最后的分类层。
- 数据量大,任务相似:用预训练权重初始化整个网络,然后在新数据上进行微调(Fine-tuning),通常效果最佳。
- 数据量大,任务差异大:可尝试微调或从头训练。
- 数据量小,任务差异大:最困难的情况,需寻找更相近的预训练模型或结合领域自适应方法。
一个通用建议是:如果数据规模远小于百万级别,应优先考虑利用大规模数据集进行预训练再迁移。
4. 超参数选择与调试:系统化逼近最优解
高效的调参需要系统化步骤:
- 过拟合一个小样本:用极少量数据(如一个batch)训练,确保模型能将训练损失降至接近0。若不能,则可能是代码或架构问题。
- 粗略搜索学习率范围:通过短期训练观察损失下降速度,确定合适的学习率区间。
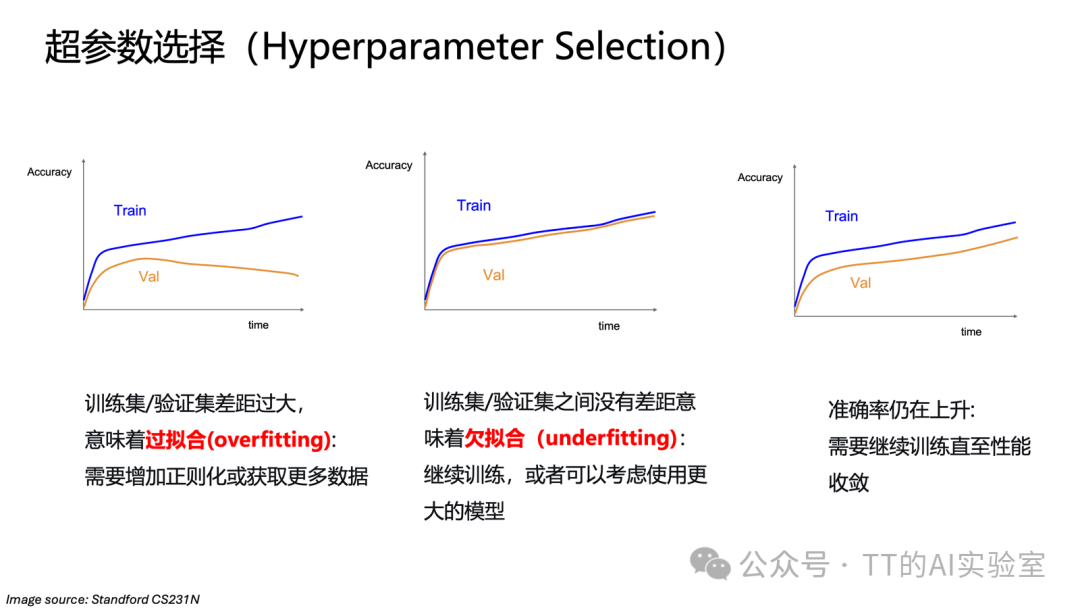
在正式训练中,需持续监控训练集和验证集的性能曲线:
- 训练准确率高,验证准确率低:可能过拟合,需加强正则化(如加大Dropout率、权重衰减)或增加数据。
- 训练和验证准确率都低:可能欠拟合,需继续训练、增大模型容量或调高学习率。
- 两者同步稳健上升:状态良好,可继续训练直至收敛。
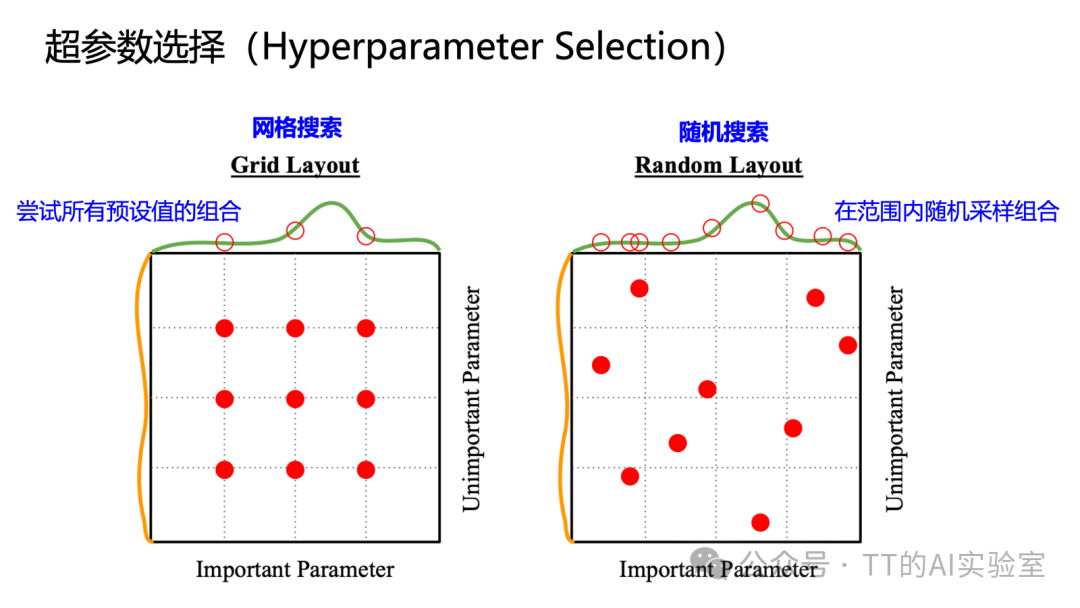
对于多超参数优化,随机搜索通常比网格搜索更高效,因为它能在有限尝试次数内,更大概率探索到对性能影响大的关键参数维度。
小结与预告
本篇深入探讨了构建与训练高效CNN的两大核心。在结构上,归一化层和Dropout作为关键组件,分别从稳定梯度传播和抑制过拟合两方面保障了深度网络的训练。在架构演进上,从VGG的小卷积堆叠到ResNet的残差连接,其核心都是在解决“网络加深”带来的优化难题。
在训练策略上,正确的权重初始化是训练稳定的起点,数据预处理与增强是提升模型质量的基础,迁移学习是小数据场景的利器,而系统化的超参数调试则是逼近模型性能上限的最后一步。可以说,结构决定了模型能力的上限,而训练技巧决定了我们能多大程度接近这个上限。
掌握这些计算机基础层面的原理与工程实践,是构建强大计算机视觉系统的关键。CNN为我们处理图像这类网格化数据奠定了基础。但面对文本、语音、视频等序列数据,顺序至关重要。在后续内容中,我们将转向循环神经网络(RNN),探索网络如何通过“记忆”来捕捉序列中的时间依赖关系。欢迎在云栈社区继续交流与探索更多深度学习相关知识。
 发表于 2026-2-24 03:39:52
|
查看: 302|
回复: 0
发表于 2026-2-24 03:39:52
|
查看: 302|
回复: 0
