摘要
随着高清与超高清视频需求的激增,高效视频编码(HEVC)标准被广泛应用,但其带来的块效应、振铃效应等压缩失真(Artifacts)仍是影响视觉质量的关键问题。现有的基于卷积神经网络(CNN) 的后处理方法通常仅将解码帧作为输入,忽略了编码过程中产生的关键先验信息。我们提出了一种创新框架,巧妙地将编码过程中的分区信息(Partition Information) 作为关键先验,通过生成的掩膜(Mask)引导后处理过程。此外,针对帧内不同区域的失真差异,我们还提出了一种自适应切换神经网络(ASN) 方案,通过迭代训练多个独立CNN来处理具有不同特征的图像块。实验表明,该方案在亮度通道上实现了最高 10.97% 的BD-rate节省,性能显著优于现有最先进的方法。
背景与动机
HEVC通过基于块的混合编码框架实现了比H.264/AVC高50%的压缩效率,但也无可避免地引入了明显的压缩失真。虽然已有VRCNN、ARCNN等基于深度学习的后处理方法,但它们普遍存在两个主要局限性:
- 忽略先验信息:大多数方法仅利用解码后的像素信息,未能利用编码器生成的CU划分信息。这些划分信息直接反映了编码决策,与失真的空间分布密切相关。
- 忽略局部差异:通常使用单一的、通用的模型处理整帧甚至所有视频帧,忽略了帧内不同图像块(Patch)在内容纹理和失真程度上的巨大差异性。
为了解决上述问题,本文旨在结合编码端提供的分区信息先验,并通过多模型自适应切换机制,实现更精细、更高效的视频后处理。
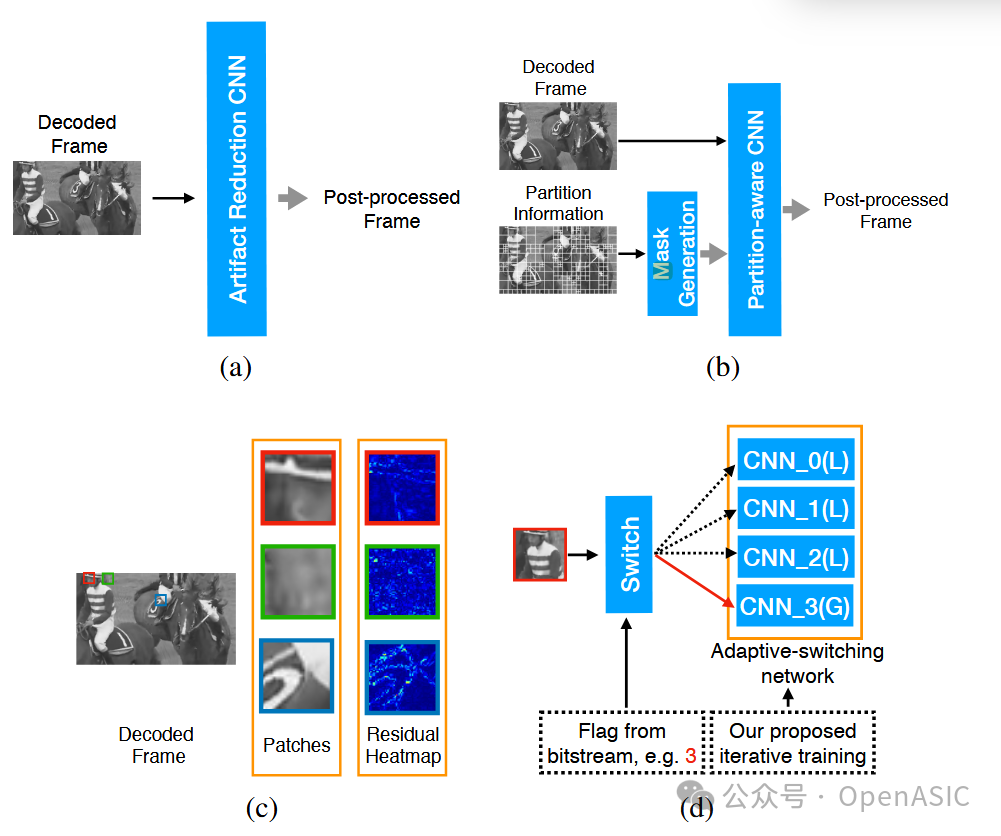
图1:展示了(a)传统单输入CNN后处理方法;(b)本文提出的分区感知CNN双路输入;(c)残差热力图显示的局部失真差异;(d)本文的自适应切换网络工作流程。
提出的设计方案
A. 总体架构
本文的核心创新在于两个相互关联的组件:分区感知CNN(Partition-aware CNN) 和自适应切换神经网络(Adaptive-switching Neural Network, ASN)。
- 分区感知CNN:其输入不仅包括解码帧,还增加了从HEVC分区信息派生出的掩膜。通过双路特征提取与融合,该网络能够更有针对性地减少特定区域的伪影。
- ASN方案:在解码端,系统会根据从比特流中解析出的标志位(Flag),动态地为每个图像块选择最适合的CNN模型进行处理,从而实现对帧内多样性的自适应处理。
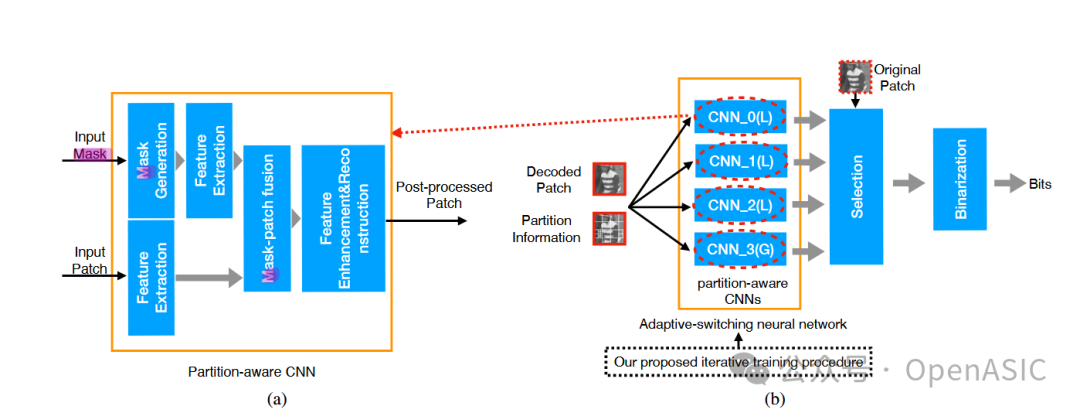
图2:详细展示了(a)分区感知CNN的具体流程,包括掩膜生成、特征融合与重建;(b)自适应切换方案的编码端选择与解码端切换流程。
B. 掩膜生成与融合策略
为了有效利用HEVC的CU划分信息(如 64x64, 32x32, 16x16, 8x8 等),我们设计了专门的掩膜生成与融合策略:
-
掩膜生成 (Mask Generation):
- 局部均值掩膜 (Local Mean-based Mask, MM):用每个编码分区内解码像素的均值来填充该分区对应的块。这种方法能有效区分不同的分区模式,实验证明其性能最优。
- 边界掩膜 (Boundary-based Mask, BM):仅标记编码分区的边界像素,信息较为稀疏。
-
掩膜-帧融合 (Mask-frame Fusion):
- 加法融合 (Add-based Fusion, AF):分别通过卷积层提取掩膜和原始解码帧的特征图,然后进行元素级相加。这是本文采用的最佳策略,实现了特征的有效互补。
- 拼接融合 (Concatenation-based Fusion):包括早期拼接(CEF)和晚期拼接(CLF),将特征在通道维度上进行合并。

图3:三种不同的掩膜生成效果对比:(a)原始帧与分区叠加;(b)基于局部均值的掩膜;(c)基于边界的掩膜。

图4:三种不同的特征融合方法示意图:基于连接的晚期融合、基于加法的融合和基于连接的早期融合。
C. 分区感知CNN网络结构
网络主体采用了经典的残差结构,以利于梯度流动和模型训练。具体设计如下:
- 双流特征提取:一个分支处理解码帧,另一个分支处理生成的掩膜(Mask)。
- 特征融合:采用前述的加法融合(AF)策略,将两路提取的特征进行合并。
- 重建层:融合后的特征经过一系列包含残差块的卷积层进行深度特征增强和细节重建,最终输出修复后的高质量帧。
- 损失函数:使用均方误差(MSE)作为损失函数来指导网络训练。
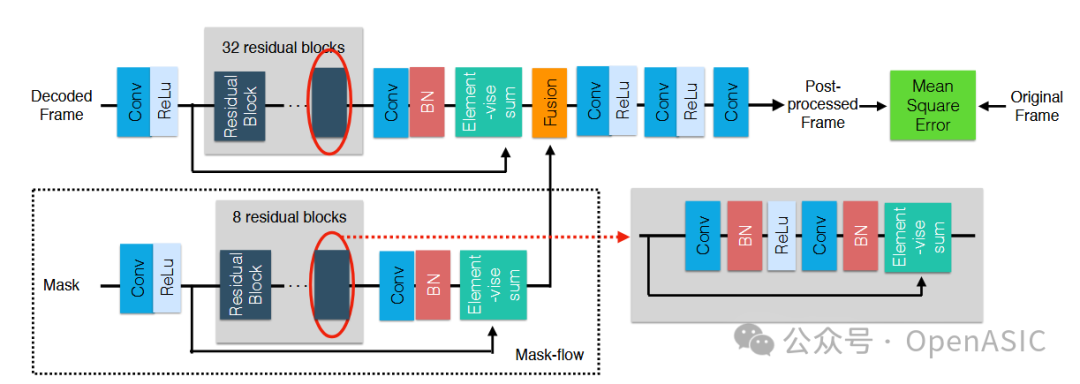
图5:分区感知CNN的详细网络结构图,包含双流输入、加法融合、多个残差块以及最终的重建输出层。
D. 自适应切换方案 (ASN)
为了应对帧内不同区域(如平滑区域、纹理区域、边缘区域)的失真差异,我们设计了一个包含多个CNN的切换方案,其中包括一个全局CNN和多个专门化的局部CNN。
-
工作机制:
- 编码端:每个图像块会分别通过所有候选CNN进行处理,系统选择输出结果与原始块PSNR最高(即质量最好)的CNN,并将其索引(Flag)写入码流。这个过程虽然增加编码复杂度,但只在编码端进行一次。
- 解码端:解码时解析Flag,即可将每个图像块直接送入对应的、最优的CNN进行后处理,解码复杂度可控。
-
迭代训练 (Iterative Training): 由于没有现成的标签指明每个块应由哪个模型处理,我们提出了一种创新的迭代训练算法:
- 初始化:使用基于聚类的分析方法,为训练数据中的图像块分配初始的模型标签。
- 迭代更新:首先,用当前标签训练各个CNN模型;然后,使用训练好的模型重新对所有块进行测试,根据性能为它们分配新的(可能更优的)模型标签;最后,用新标签微调模型。这个过程循环进行,直至模型性能收敛。
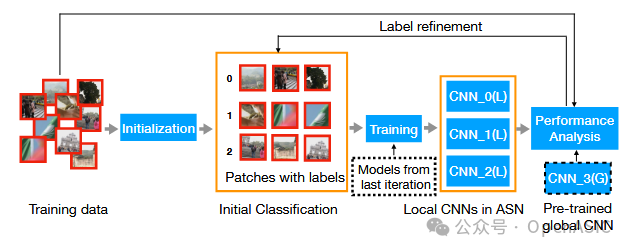
图6:自适应切换网络的迭代训练流程,展示了从数据初始化、模型训练、标签精炼到性能评估的闭环过程。
实验结果
A. 数据集与设置
为了充分验证方法的有效性,我们建立了一个大规模数据集,包含 202,251 个训练样本,涵盖了多种分辨率视频在不同QP值(22, 27, 32, 37)下的编码情况。所有实验均在HEVC参考软件HM-16.0的Low-delay P (LP)配置下进行。
B. 不同策略的性能对比
- 掩膜策略:局部均值掩膜(MM)在几乎所有测试场景下均稳定优于边界掩膜(BM)。
- 融合策略:加法融合(AF)在性能上超越了各种拼接融合策略,且网络结构更简洁。
- 综合性能:采用MM+AF策略的分区感知CNN(记为 D*)在QP=37时,其PSNR比仅使用解码帧的单输入基线模型提高了 0.15dB 以上。
C. 自适应切换与SOTA对比
我们将本文提出的完整方案与VRCNN、QECNN-P、DRN、DCAD等当前先进方法进行了全面对比,评价指标为BD-rate(负值表示码率节省,越低越好):
| 方法 |
说明 |
BD-rate节省 (LP配置, Y通道) |
| VRCNN |
浅层网络基线 |
-3.57% |
| QECNN-P |
针对P帧优化 |
-4.95% |
| **Our D*** |
分区感知深层网络 |
-9.76% |
| **Our ASN@4D*** |
完整自适应切换方案 |
-10.97% |
实验结果表明,**ASN@4D*** (集成了4个深度分区感知模型的自适应网络)取得了最佳性能。即使是一个混合了深浅模型的轻量化版本,也能在保持较低计算复杂度的同时,超越大多数现有方法。

图7:主观视觉质量对比。可以看到,本文方法(最右侧)能更有效地去除篮球场地板上的带状纹路失真,并清晰地恢复赛马图像中马腿的边缘细节,显著优于其他对比方法。
结论
本文提出了一种创新的HEVC后处理方案,该方案深度融合了编码分区先验信息与自适应模型切换机制。通过引入分区感知模块,我们充分利用了编码端的决策信息来引导后处理;通过设计自适应切换网络及配套的迭代训练策略,我们有效应对了视频帧内局部纹理和失真的多样性。充分的实验证明,该方案在客观指标(PSNR/BD-rate)和主观视觉质量上均显著优于现有的先进算法,为下一代视频编码的智能后处理提供了新的思路。
对深度学习和视频编码前沿技术感兴趣的开发者,欢迎在 云栈社区 交流探讨。
 发表于 2025-12-31 04:27:54
|
查看: 301|
回复: 0
发表于 2025-12-31 04:27:54
|
查看: 301|
回复: 0
