早在2018年,便有学者发现可以通过仅修改几个像素来干扰模型对输入的预测。
作为一篇云栈社区的博客,本文将谈论如何构造验证码,而不是如何解决验证码,以避免不必要的负面影响(构造验证码来保护在线业务几乎总是有利于保护网络安全环境的)。请勿恶意构造其他数据,或利用类似方法做对抗性滤波,避免对他人服务产生影响。
验证码识别器的原理
在开始谈论对抗性验证码构造前,我们必须了解验证码识别器的原理。
绝大多数的人工智能识别器,从ResNet到Yolo,都是基于卷积层的。卷积层是网络的核心,其运算并非数学严格定义上的卷积,而是互相关运算。给定一个二维输入张量X,其维度为高度H和宽度W,卷积核K为一个大小为kH乘以kW的张量。输出特征图矩阵中的每一个元素Y(i, j)是通过卷积核在输入图像上的滑动窗口内进行逐元素相乘并求和得到的。从数学角度看,这可以表示为在每一个空间位置上,输入局部区域向量与卷积核权值向量的内积再加上偏置项。
由于同一个卷积核在整个输入空间上滑动,这种权值共享极大减少了参数数量,并利用了图像统计属性的局部平稳性。在卷积操作之后,通常会施加一个非线性激活函数,最常用的是修正线性单元ReLU,即函数f(x)等于max(0, x)。
引入非线性的目的是为了使网络能够拟合复杂的非线性函数,否则多层线性卷积层在数学上等价于单层线性变换,将失去深层结构的表达能力。
这里,为了更有教育意义,我们先自己训练一个甚至有点过度简化(只有数字识别、没有位置检测和分割功能)的验证码识别器。在产业中,这一步可以直接替换为使用攻击者使用的模型进行防御。
我们先对mnist数据集进行一些简单的扰动,代码如下:
# img is 28x28 numpy array, uint8
# Random shift -2 to 2
shift_x, shift_y = random.randint(-2, 2), random.randint(-2, 2)
M1 = np.float32([[1, 0, shift_x], [0, 1, shift_y]])
img = cv2.warpAffine(img, M1, (28, 28), borderValue=0)
# Random scale -> resize and crop/pad to 28x28
# Target size within 26x30 to 30x26
t_width = random.randint(26, 30)
t_height = 56 - t_width # keeping sum around 56, matching 26x30 ~ 30x26 boundaries
if t_width == 28:
t_height = 28
else:
t_height = random.randint(26, 30)
img = cv2.resize(img, (t_width, t_height))
# Pad or crop to 28x28
canvas = np.zeros((28, 28), dtype=np.uint8)
start_y = max((t_height - 28) // 2, 0)
start_x = max((t_width - 28) // 2, 0)
c_start_y = max((28 - t_height) // 2, 0)
c_start_x = max((28 - t_width) // 2, 0)
copy_h = min(28, t_height)
copy_w = min(28, t_width)
canvas[c_start_y:c_start_y + copy_h, c_start_x:c_start_x + copy_w] = img[start_y:start_y + copy_h, start_x:start_x + copy_w]
img = canvas
angle = random.uniform(-20, 20)
M2 = cv2.getRotationMatrix2D((14, 14), angle, 1.0)
img = cv2.warpAffine(img, M2, (28, 28), borderValue=0)
# Add 10 random noise pixels
for _ in range(10):
nx, ny = random.randint(0, 27), random.randint(0, 27)
img[ny, nx] = random.choice([0, 255])
return img.astype(np.float32) / 255.0
效果如图所示:

很多传统的验证码生成器就到此为止了(生成随机干扰点和线)。必须指出,尽管在今天看来,这种扰动是毫无意义的(任何合理的OCR都能无视这种扰动),但是它可以避免我们接下来构建的识别器过度简单,从而不能正确地反应其他识别器的弱点。
验证码识别器的构建
我们可以随手(嗯,真的是随手,根本没怎么调优)设计一个CNN网络,比如说如图所示:
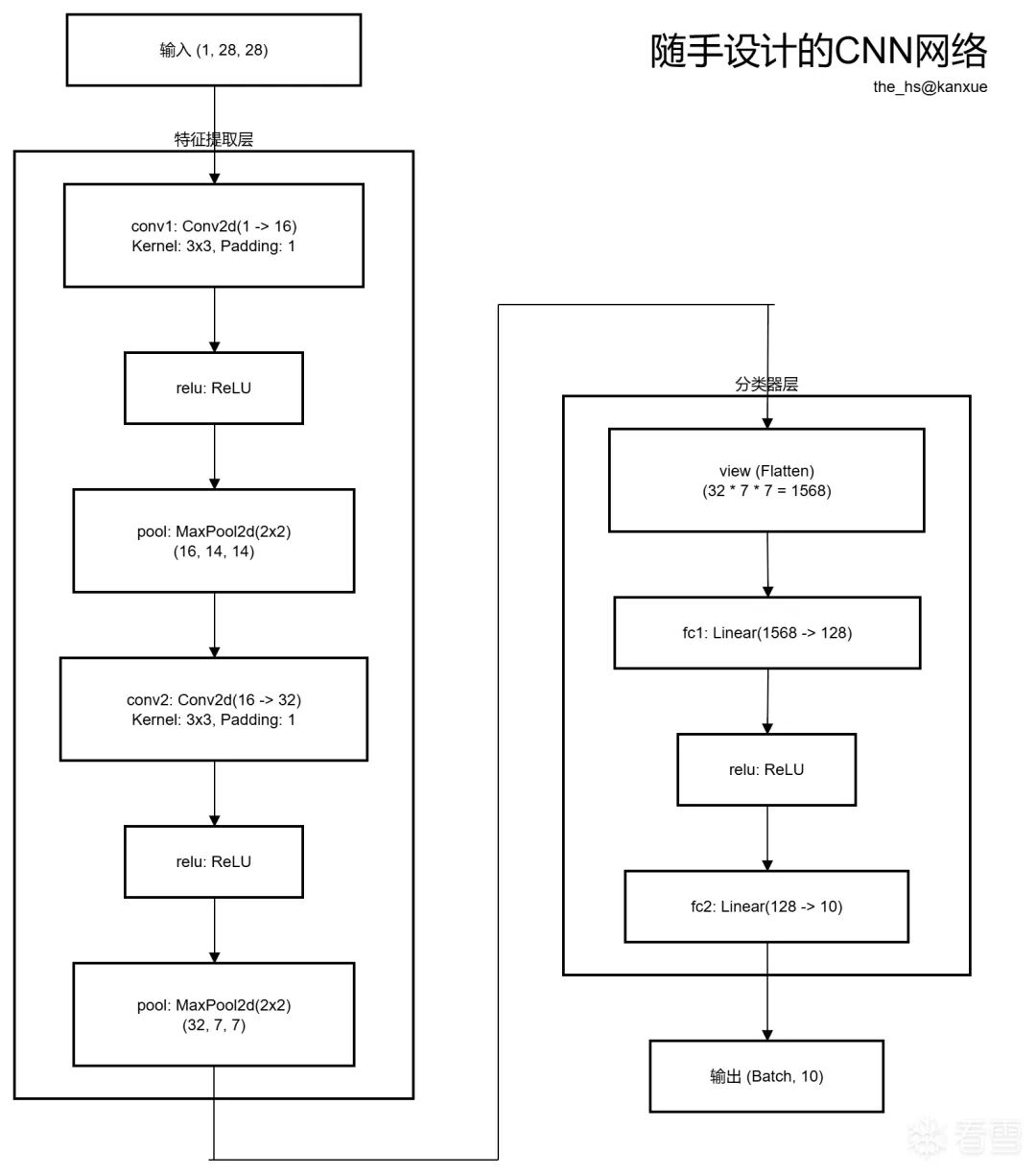
代码如下:
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(-1, 32 * 7 * 7)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
并画上那么几秒钟进行一个简单的训练。五秒钟后,尽管模型的准确率只有95%,并且没有分割等功能,但是已经足够我们下一步使用了。
Epoch 20/20, Loss: 0.0017
Time elapsed: 5.03 seconds
Test Accuracy: 95.10%
对抗性样本的构造
构造对抗性样本有很多种不同的方法,这里展示一种笔者前日设计的方法(FastJSMA: Accelerating Jacobian-based Saliency Map Attacks through Gradient Decoupling)的变种:取预测中高置信度的部分作为优化目标,进行逐点干扰。这里,为了确保不被滤波器滤除,同时没有benchmark需求,我们选择随机构造扰动幅度,代码如下:
img_adv = img_tensor.clone().detach().requires_grad_(True)
# A
T = set()
for step in range(50):
if img_adv.grad is not None:
img_adv.grad.zero_()
output = model(img_adv)
model.zero_grad()
output[0, target_class].backward(retain_graph=True)
grad_target = img_adv.grad.clone()
img_adv.grad.zero_()
output[0, source_class].backward()
grad_source = img_adv.grad.clone()
D = (0.5 * grad_target - grad_source).squeeze()
D_flat = D.view(-1)
for t_idx in T:
D_flat[t_idx] = -float('inf')
max_idx = torch.argmax(D_flat).item()
T.add(max_idx)
# B
magnitude = random.uniform(0.3, 0.6)
direction = torch.sign(D_flat[max_idx]).item()
if direction == 0:
direction = 1
with torch.no_grad():
flat_img = img_adv.view(-1)
flat_img[max_idx] += direction * magnitude
# C
flat_img.clamp_(0, 1)
img_adv.requires_grad_(True)
上述代码中A处是为了避免重复修改相同像素,B处是刚才提到的随机扰动,C处是为了避免生成的值不再是图像;这些点比较琐碎,但不正确的实现还是会导致效果不对。g+与g-的混合因子、试探方式与paper中存在微小出入,是为了更好地适配ddddocr进行的工程优化。那么就大功告成。
效果测试
4339

ddddocr-数字模式:识别失败
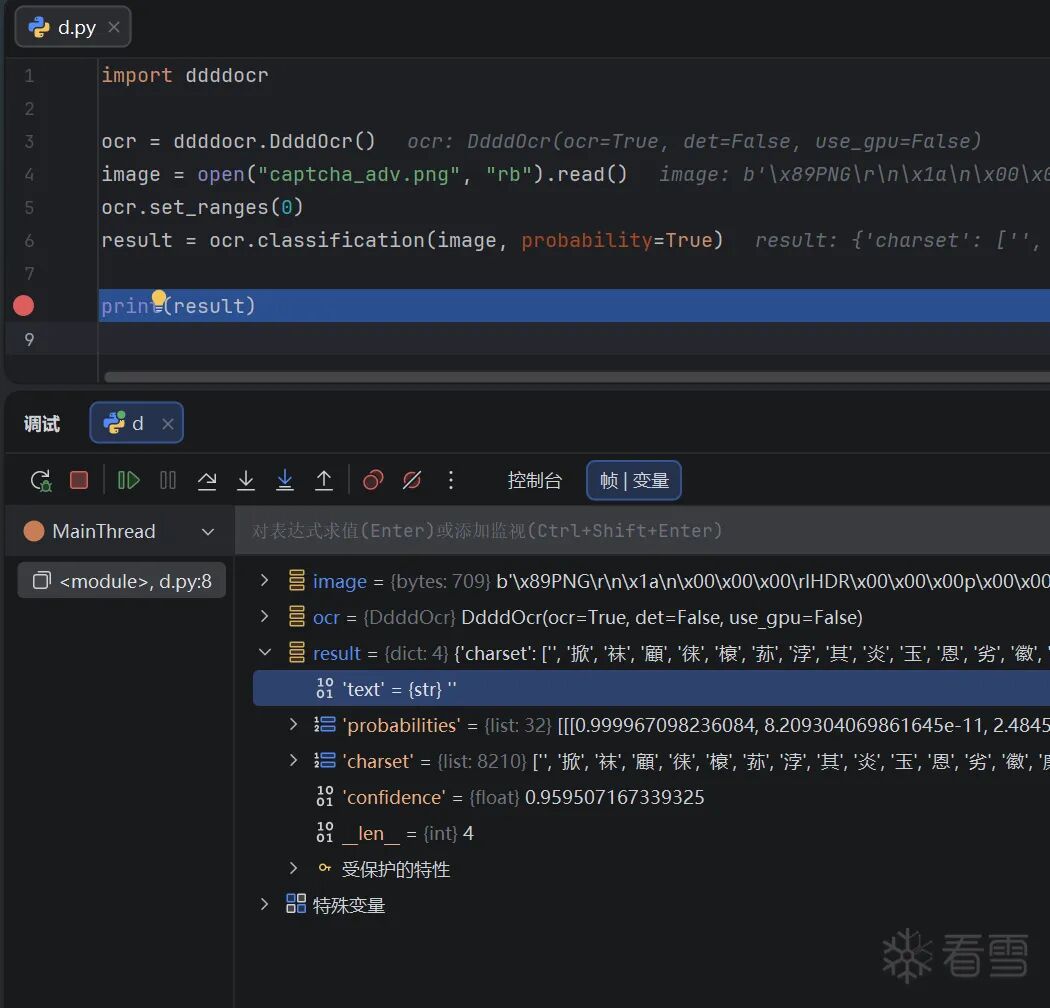
几个常见的vlm:7984 9339 4239
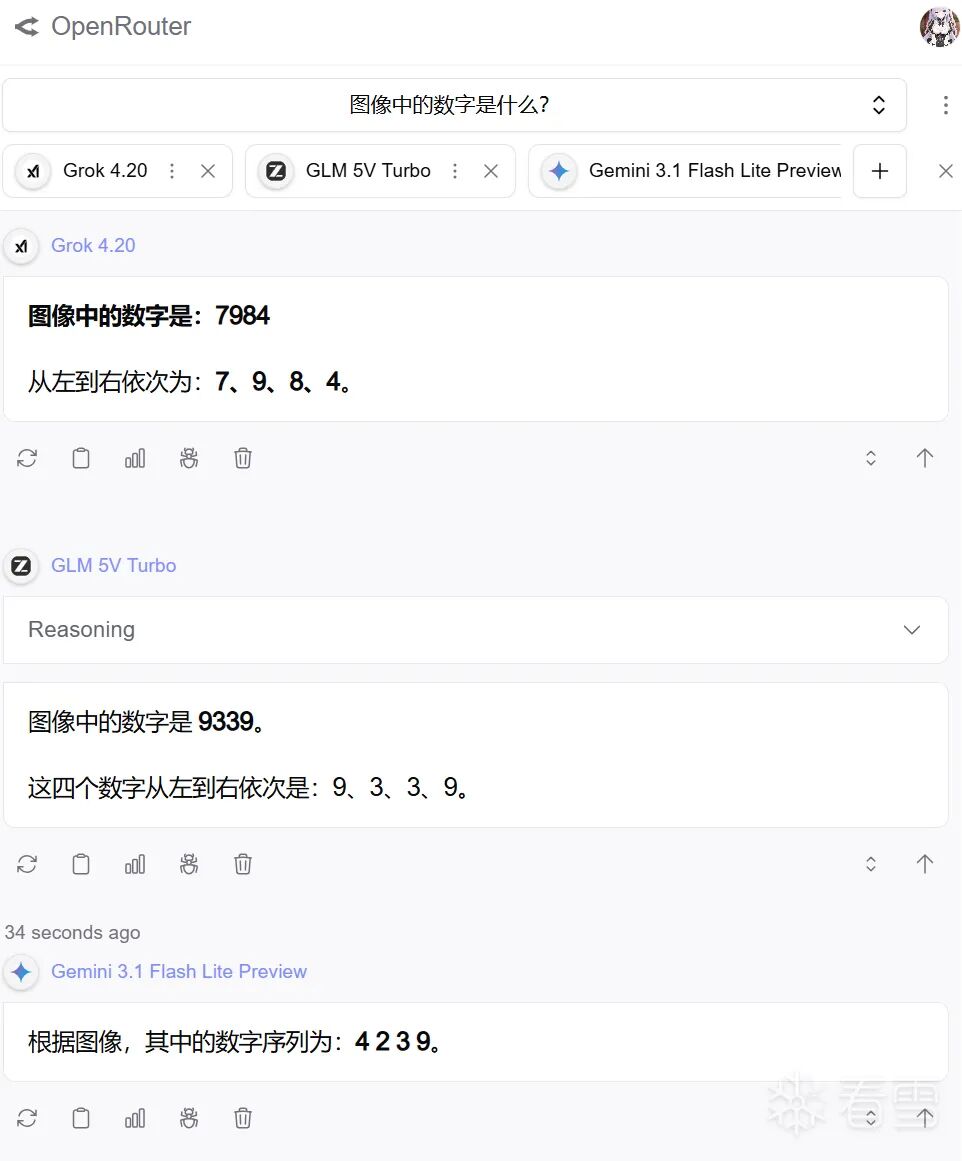
ddddocr-全量模式:y33g
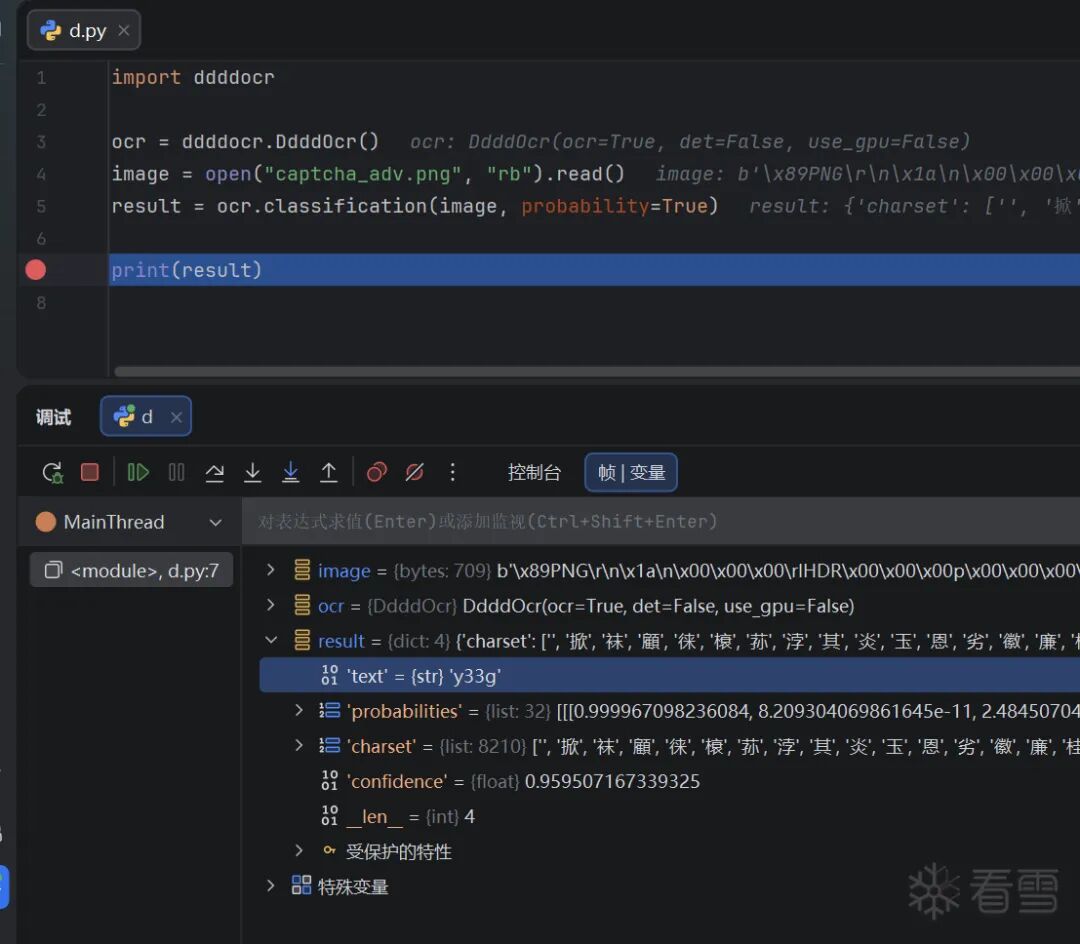
PaddleOCR-VL: 936.9

因此可以认为我们的验证码对于常见的机器学习方法拥有足够的抵抗力。
总结
本文所展示的对抗性样本构造方法,其唯一目的在于学术探讨及网络安全防御应用,旨在通过提升验证码的抗AI识别能力,帮助开发者更好地保护在线业务免受恶意自动化程序的攻击。
请勿将本文涉及的技术、代码或逻辑用于任何非法或违背道德的行为,包括但不限于样本投毒、恶意绕过他人的安全防御系统或干扰正常网络服务。在进行任何相关实验或应用时,请确保严格遵守《生成式人工智能服务管理暂行办法》及所在地区的相关法律法规。技术的使用应始终保持合法、合规且符合伦理的框架内。
 发表于 2026-4-27 18:12:54
|
查看: 160|
回复: 0
发表于 2026-4-27 18:12:54
|
查看: 160|
回复: 0
