MySQL 的 MyISAM 和 InnoDB 存储引擎虽然都使用 B+ 树作为索引结构,但在底层实现上存在根本性差异。本文将深入剖析两者在底层索引结构上的关键差异。
首先,我们创建一张表用于示例分析,SQL 如下:
CREATE TABLE `t_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(16) DEFAULT NULL,
`email` varchar(32) DEFAULT NULL,
`phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `k_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=latin1
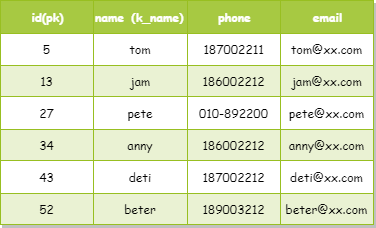
这张表除了主键 id,还在 name 字段上建立了一个普通索引。假设我们插入了 6 条数据,其内容如下:
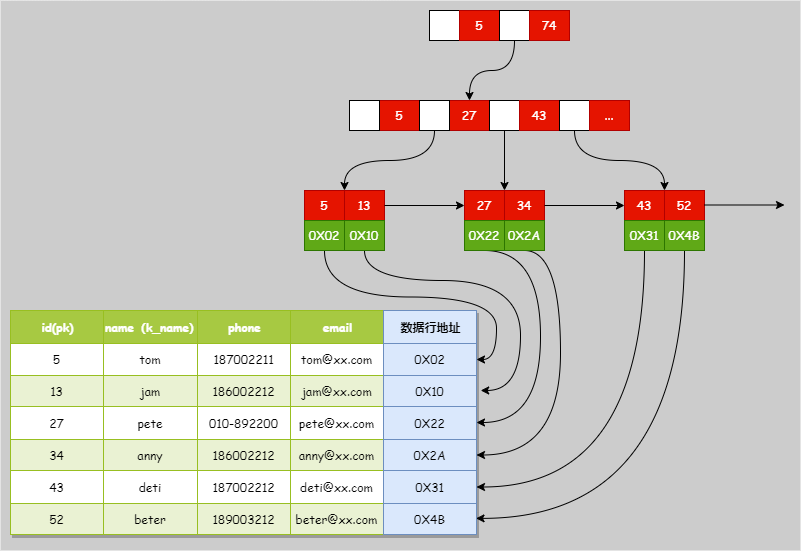
1. MyISAM 索引结构(非聚集索引)
MyISAM 存储引擎的一个重要特性是索引文件与数据文件分离。其索引文件(.MYI)仅保存数据记录的物理存储地址(如磁盘偏移量)。
1.1 主键索引
MyISAM 的主键索引同样是一棵 B+ 树。B+ 树的非叶子节点保存索引键值,而叶子节点保存的是主键值和对应的数据记录地址(指针)。由于叶子节点不直接保存完整的行数据,这种索引模式被称为非聚集索引。
其结构示意图如下:
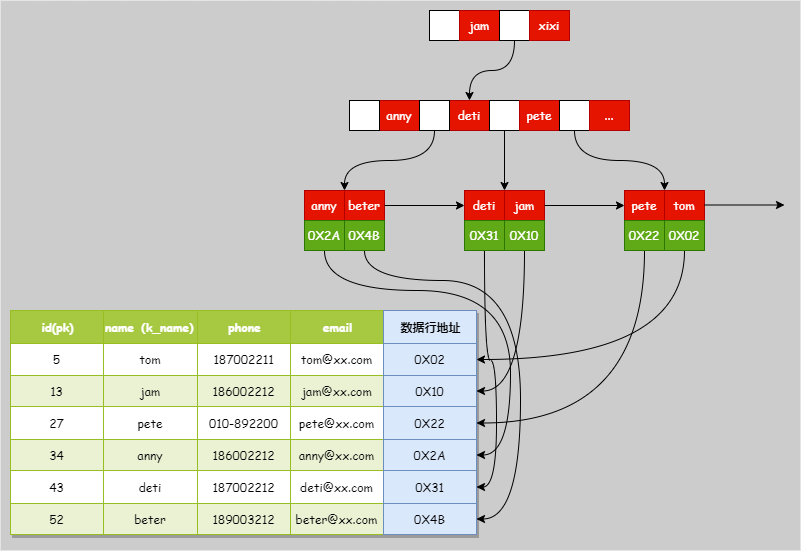
1.2 非主键索引(辅助索引)
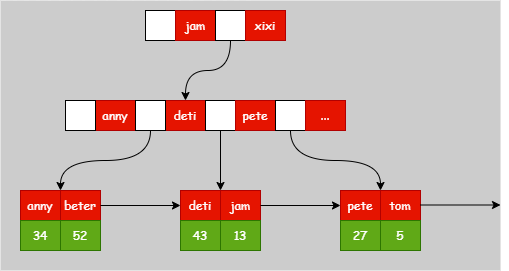
MyISAM 的非主键索引(如我们创建的 k_name 索引)在结构上与主键索引完全一致,唯一的区别在于索引键值可以重复。非主键索引的叶子节点同样存储的是索引值和对应的数据地址。
k_name 索引的结构示意:
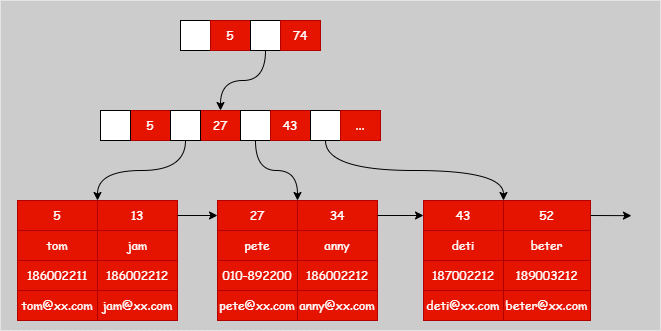
2. InnoDB 索引结构(聚集索引)
与 MyISAM 不同,InnoDB 的表数据文件本身就是按 B+ 树组织的聚集索引。这意味着主键索引的叶子节点不仅包含主键值,还保存了完整的行记录数据。因此,InnoDB 的数据文件(.ibd)就是主键索引文件。
2.1 主键索引(聚集索引)
InnoDB 主键索引的 B+ 树,其键(Key)是主键值,数据域(Data)则是该主键对应的完整行记录。通过主键进行查询时,可以直接在索引树中获取所有数据,效率非常高。
其结构示意图如下:
2.2 非主键索引(二级索引)
InnoDB 的普通索引(二级索引)也是 B+ 树结构,但其叶子节点存储的内容与主键索引不同。二级索引的叶子节点存储的是索引键值和对应的主键值,而非数据地址。当通过二级索引查询非索引列的数据时,需要先查找到主键,再利用主键回到主键索引树中查找完整数据,这个过程称为“回表查询”。
理解 数据库/中间件 如 MySQL 的索引机制,对于设计高效查询和优化系统性能至关重要。
其结构示意图如下:
3. 核心区别总结
| 特性 |
MyISAM |
InnoDB |
| 索引类型 |
非聚集索引 |
聚集索引 |
| 数据存储 |
索引文件与数据文件分离 |
数据文件即主键索引文件 |
| 主键索引叶子节点 |
存储主键值 + 数据记录的地址 |
存储主键值 + 完整的行记录 |
| 非主键索引叶子节点 |
存储索引值 + 数据记录的地址 |
存储索引值 + 对应记录的主键值 |
| 查询过程(普通索引) |
通过地址直接访问数据 |
需要回表到主键索引查询完整数据 |
尽管两者都基于 B+ 树,但 MyISAM 采用的是“索引-地址”的映射模式,而 InnoDB 采用的是“索引-数据(主键索引)”或“索引-主键(二级索引)”的映射模式。这种根本性的结构差异,深刻影响了查询性能、数据存储方式以及事务支持等特性。掌握聚集索引与非聚集索引的原理,是深入理解 数据库/中间件 性能调优的基础。 |  发表于 2025-12-11 03:50:17
|
查看: 192|
回复: 0
发表于 2025-12-11 03:50:17
|
查看: 192|
回复: 0
