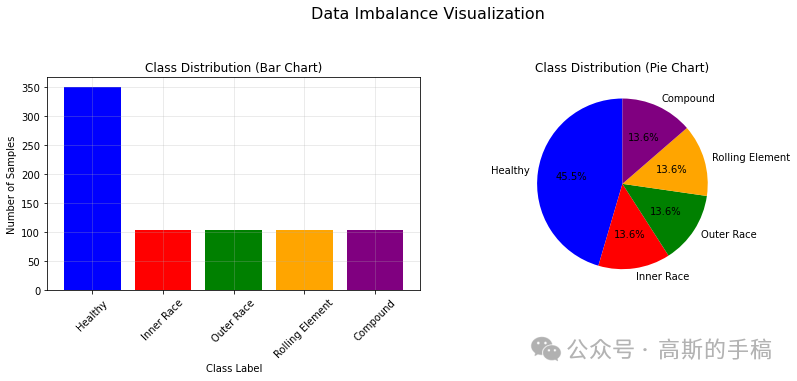
在实际工业故障诊断场景中,收集到的各类故障数据往往存在严重的类别不平衡问题,例如健康样本远多于故障样本,这极大影响了深度学习模型的训练效果与诊断精度。针对这一挑战,我们实现了一种结合谱图卷积(Spectral Graph Convolution)与混合注意力机制的改进型循环一致生成对抗网络,用于在数据不均衡条件下进行有效的故障数据增强。
方法概述
本方案的核心是利用生成对抗网络学习从多数类样本(如健康状态)到少数类样本(如各类故障)的映射关系,从而生成逼真、多样的故障数据,以平衡训练集。整个流程主要包含以下关键步骤:
- 数据准备与问题构建:首先,模拟轴承在不同状态下的振动信号,并通过时频分析(如短时傅里叶变换)将其转换为二维时频图像。人为构造一个类别不均衡的数据集,例如健康样本数量远多于内圈故障、外圈故障等少数类样本,以模拟真实工业数据分布。
- 网络架构设计:在经典的CycleGAN框架基础上进行增强。CycleGAN包含两个生成器(
G_A2B, G_B2A)和两个判别器(D_A, D_B),通过循环一致性损失实现无配对图像的风格迁移。我们在此框架中集成了两个核心模块:
- 谱图卷积模块:传统卷积操作局限于局部感受野。谱图卷积通过模拟图像像素间的图结构关系,实现特征间的全局交互与信息传递,能更好地捕捉故障特征在时频图中的整体模式。
- 混合注意力模块:该模块并行结合了通道注意力与空间注意力机制。通道注意力让网络关注重要的特征通道;空间注意力则聚焦于特征图中的关键区域(如故障特征明显的时频区域)。两者结合,使模型能自适应地强化对判别性特征的学习。
- 对抗训练与数据生成:使用构建好的不均衡数据集对网络进行训练。训练稳定后,即可利用生成器
G_A2B(假设A域为健康样本,B域为故障样本)输入健康样本,生成对应的、多样化的故障样本,从而有效扩充少数类样本库。
- 平衡训练与故障分类:将生成的故障样本与原始样本合并,形成一个类别平衡的新训练集。最后,使用这个平衡的数据集训练一个故障分类器(如卷积神经网络),从而显著提升模型在真实不均衡数据下的诊断准确率。
核心代码实现(PyTorch)
以下展示了网络核心模块的简化实现代码。
1. 谱图卷积模块
这是一个简化的谱图卷积实现,通过标准的卷积层配合残差连接来模拟图结构上的特征传播。
# ==================== 谱图卷积模块 ====================
class SpectralGraphConv(nn.Module):
"""谱图卷积模块(简化版)"""
def __init__(self, in_channels, out_channels):
super().__init__()
# 图卷积的简化实现
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.norm = nn.InstanceNorm2d(out_channels)
self.dropout = nn.Dropout2d(0.1)
def forward(self, x):
# 残差连接
identity = x
# 图卷积运算(简化)
x = self.conv(x)
x = self.norm(x)
x = F.relu(x, inplace=True)
# 残差连接
if identity.shape[1] == x.shape[1]:
x = x + identity
x = self.dropout(x)
return x
2. 混合注意力模块
该模块集成了通道注意力和空间注意力,是提升模型特征选择能力的有效手段,广泛应用于深度学习的视觉任务中。
# ==================== 混合注意力模块 ====================
class HybridAttentionModule(nn.Module):
"""混合注意力模块(通道注意力 + 空间注意力)"""
def __init__(self, in_channels, reduction_ratio=16):
super().__init__()
# 通道注意力
self.channel_attention = ChannelAttention(in_channels, reduction_ratio)
# 空间注意力
self.spatial_attention = SpatialAttention()
def forward(self, x):
# 通道注意力
x_channel = self.channel_attention(x)
# 空间注意力
x_spatial = self.spatial_attention(x_channel)
return x_spatial
class ChannelAttention(nn.Module):
"""通道注意力模块"""
def __init__(self, in_channels, reduction_ratio=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享的MLP
self.mlp = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction_ratio, in_channels)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
avg_out = self.avg_pool(x).view(b, c)
max_out = self.max_pool(x).view(b, c)
avg_out = self.mlp(avg_out)
max_out = self.mlp(max_out)
channel_weights = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)
return x * channel_weights
class SpatialAttention(nn.Module):
"""空间注意力模块"""
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size//2)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
concat = torch.cat([avg_out, max_out], dim=1)
spatial_weights = self.conv(concat)
spatial_weights = self.sigmoid(spatial_weights)
return x * spatial_weights
3. 生成器网络
生成器采用编码器-解码器结构,在下采样后,通过多个包含前述增强模块的残差块进行特征变换。
# ==================== 生成器网络 ====================
class Generator(nn.Module):
"""I-CycleGAN生成器"""
def __init__(self, in_channels=3, out_channels=3, base_channels=64):
super().__init__()
# 初始卷积层
self.initial_conv = nn.Sequential(
nn.Conv2d(in_channels, base_channels, kernel_size=7, stride=1, padding=3),
nn.InstanceNorm2d(base_channels),
nn.ReLU(inplace=True),
)
# 下采样
self.downsample = nn.Sequential(
nn.Conv2d(base_channels, base_channels*2, kernel_size=3, stride=2, padding=1),
nn.InstanceNorm2d(base_channels*2),
nn.ReLU(inplace=True),
nn.Conv2d(base_channels*2, base_channels*4, kernel_size=3, stride=2, padding=1),
nn.InstanceNorm2d(base_channels*4),
nn.ReLU(inplace=True),
)
# 残差块(包含谱图卷积和混合注意力)
self.residual_blocks = nn.ModuleList([
ResidualBlock(base_channels*4) for _ in range(6)
])
# 上采样
self.upsample = nn.Sequential(
nn.ConvTranspose2d(base_channels*4, base_channels*2,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(base_channels*2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(base_channels*2, base_channels,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(base_channels),
nn.ReLU(inplace=True),
)
# 最终卷积层
self.final_conv = nn.Sequential(
nn.Conv2d(base_channels, out_channels, kernel_size=7, stride=1, padding=3),
nn.Tanh()
)
def forward(self, x):
# 初始卷积
x = self.initial_conv(x)
# 下采样
x = self.downsample(x)
# 残差块
identity = x
for block in self.residual_blocks:
x = block(x)
# 残差连接
x = x + identity
# 上采样
x = self.upsample(x)
# 最终卷积
x = self.final_conv(x)
return x
(注:ResidualBlock 内部会调用 SpectralGraphConv 和 HybridAttentionModule)
网络架构与效果示意
下图展示了集成谱图卷积与混合注意力机制的CycleGAN框架示意图:
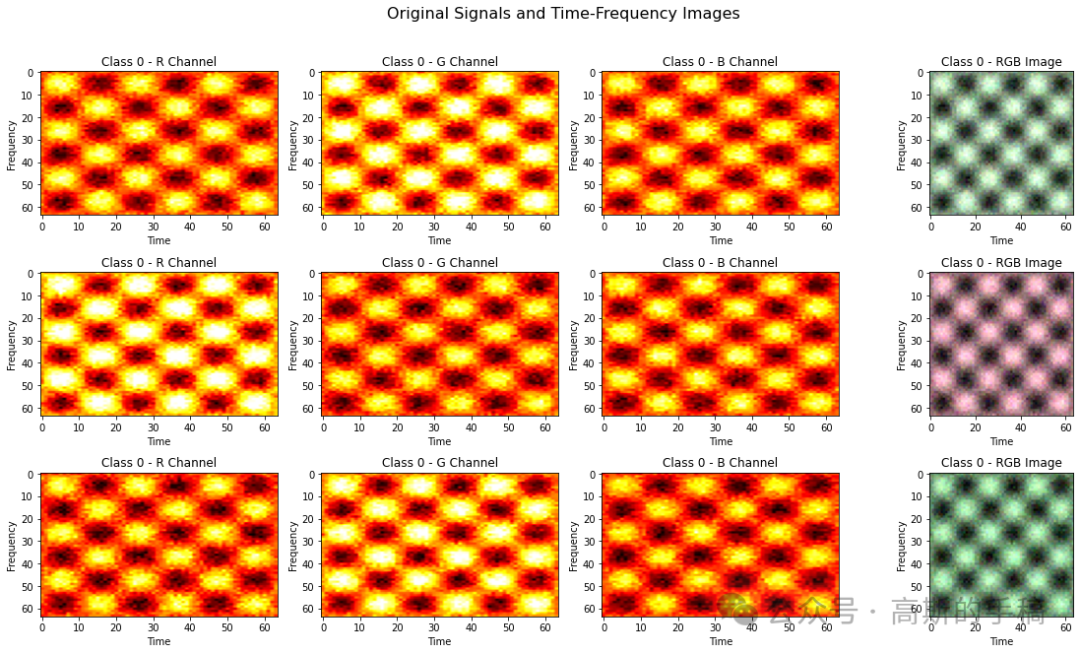
经过训练后,生成器能够将健康状态的时频图(输入)转化为逼真的故障时频图(输出),如下图所示:
总结
通过将谱图卷积的全局特征交互能力与混合注意力的自适应聚焦能力相结合,并嵌入到CycleGAN的循环一致框架中,本方法能够有效应对故障诊断中的数据不均衡问题。在PyTorch框架下实现的这一方案,为生成高质量、多样性的少数类样本提供了一种强有力的技术途径,最终能显著提升下游故障分类模型的泛化性能与鲁棒性。这种方法的思想也可迁移至其他存在数据不均衡问题的视觉或信号处理任务中。
 发表于 2025-12-11 04:35:43
|
查看: 213|
回复: 0
发表于 2025-12-11 04:35:43
|
查看: 213|
回复: 0
