Sora能生成逼真的物理世界视频,GPT-image-1能画出精美的插画。然而,当任务从“生成”转向“推理”——比如让它们解答一道物理题、规划一条迷宫路线,或者按步骤组装一个乐高模型时,会发生什么?
清华大学与美团M17团队联合进行的一项大规模基准测试给出了答案:大部分视觉生成模型在此类需要推理的任务上表现极差。
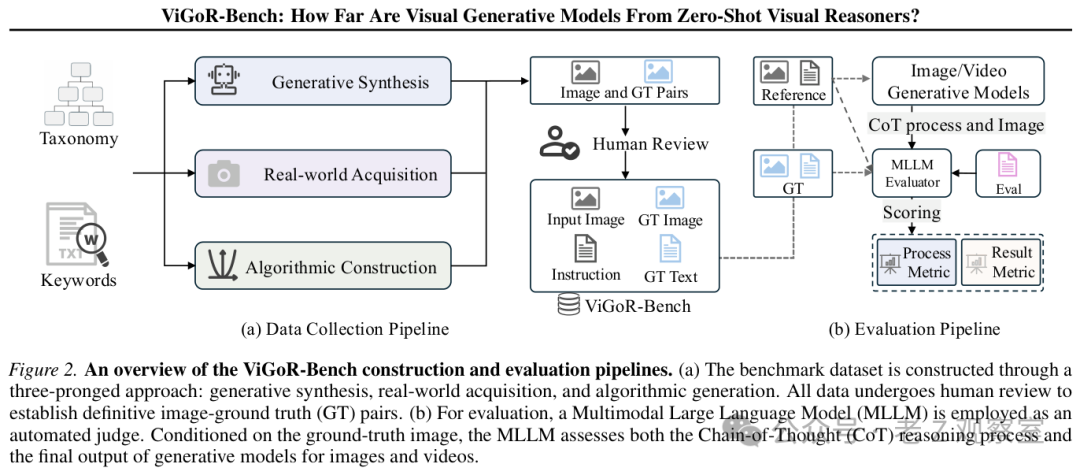
他们构建了一个名为 ViGoR-Bench 的评测基准,专门用于检验视觉生成模型的推理能力。测试覆盖了超过20个主流模型,横跨图像编辑、视频生成与统一生成模型三大类别。结果揭示了一个与画面逼真度背道而驰的残酷现实:在越来越真实的视觉表象之下,隐藏着一片广阔的“逻辑沙漠”。

CLIP-Score与FID指标无法捕捉的盲区
评价一个图像生成模型的好坏,业界通常依赖FID(Fréchet Inception Distance,衡量生成图像与真实图像的统计分布距离)和CLIP-Score(评估图像与文本描述的语义匹配度)。
然而,这两个主流指标存在一个共同的致命缺陷:它们完全不关心生成内容背后的推理是否正确。一张画面极其精美、且与文本提示高度匹配的图片,完全可能包含违背物理规律的荒谬错误。例如,水向上流动、影子方向矛盾、或者齿轮传动关系错误,这些逻辑谬误在FID和CLIP-Score的评分体系中不会被扣分。
此前也有一些基准测试尝试评估推理能力,但它们通常只聚焦于单一模态,例如仅测试图像编辑或仅测试视频生成,缺乏一个能将各种生成模态统一起来的评估框架。并且,多数测试只关注最终的生成结果,忽略了模型在生成过程中的推理链条是否合理。
ViGoR-Bench如何进行全面评测?
ViGoR-Bench基准涵盖了多达20个不同的推理维度,并将其归纳为三大核心类别:
- 物理推理:涉及力学、光学、流体、热力学等物理规律的认知与应用。
- 知识推理:需要社会常识、文化背景、生物知识等跨领域知识的理解。
- 符号推理:包括数学函数可视化、空间规划、逻辑谜题求解等抽象任务。
评测覆盖了三种主流的任务形态:单次图像编辑(I2I)、序列图像编辑(I2Is,需多步完成一个目标)和图像到视频生成(I2V)。这使得ViGoR-Bench成为首个将三种生成模态统一纳入评估的基准测试。
其评估体系采用双轨制:过程评测与结果评测。这意味着它不仅判断最终生成的图像或视频是否正确,还深入检查模型在生成过程中的每一步推理链是否合理。例如,在一个组装乐高的任务中,评估不仅要看最终模型是否拼装完成,还要审视其每一步放置积木的位置和顺序是否正确。

在自动化评判方面,研究团队采用Gemini-2.5-Pro作为“裁判”。为了确保评估的可靠性,他们进行了严格的验证:将AI评判结果与三位人类专家的评分进行对比,准确率达到了73%-78%,表明其稳定性和可靠性已与人类评审相当。测试还发现,是否为评判者提供标准答案作为参考,会显著影响评判质量。这种“有据可查”的评判方式,远比让模型“凭感觉打分”要可靠得多。
20余份成绩单:关键发现与短板

对超过20个模型的测试结果进行分析后,几个关键发现浮出水面:
-
闭源模型优势明显:Nano Banana Pro在多数评估指标上位列第一,Sora 2 Pro则在视频生成类任务中表现突出。一个明显的趋势是,在需要复杂推理的任务上,开源模型与闭源模型之间的性能差距,比在普通内容生成任务上更为显著。
-
有推理链不等于推理正确:团队专门测试了思维链对生成质量的影响。结果显示,CoT确实能让模型的生成过程变得更加可解释(用户能看到模型“思考”了什么),但这并不保证最终结果的正确性。部分模型在引入CoT后,其过程评分有所提升,但最终结果分数反而下降了。这说明,“能思考”和“能思考正确”是两回事。
-
物理与符号推理是最大短板:涉及物理规律(如力学平衡、光学反射)以及抽象符号推理(如数学函数绘图、迷宫求解)的任务,对绝大多数模型来说都是巨大挑战。仅有像Nano Banana Pro和Sora 2 Pro这样的顶级模型,才能在部分物理推理任务上给出正确答案。开源模型在处理复杂推理指令时,常常出现“幻觉”(生成无关或错误内容),或者直接忽略指令中的关键约束。例如,在一个迷宫任务中,规则明确要求路径不能穿墙,但模型生成的路线却径直穿墙而过。
生成模型的下一道关卡:从“像不像”到“对不对”
这份详尽的测试报告指出了一个清晰的发展方向:视觉生成领域正从追求“画得像不像”的阶段,迈入考验“画得对不对”的新纪元。
当前的生成模型在视觉逼真度上已经取得了长足进步,但其内在的推理能力仍存在巨大鸿沟。ViGoR-Bench的价值在于,它将这种差距进行了量化,并拆解到具体的认知维度,让开发者能够清晰地看到当前模型在哪些类型的推理上最为薄弱。
此外,关于“CoT并非万能药”的发现也颇具启发性。能够陈述推理过程与能够进行正确推理是两种不同的能力。生成模型若想真正具备可靠的推理能力,可能需要的不仅是简单地“附加一个思维链”,而是更底层、更根本的架构性变革。对这项研究感兴趣的朋友,欢迎到云栈社区的相应板块继续探讨。 |  发表于 2026-4-6 12:35:48
|
查看: 115|
回复: 0
发表于 2026-4-6 12:35:48
|
查看: 115|
回复: 0
