Deep Research(深度研究)功能火了之后,一个现实问题摆在我们面前:市面上这么多宣称能进行深度研究的AI系统,到底谁的“研究”能力更强?
这不再是一个简单比拼“报告文笔是否通顺”的问题,而是需要真刀真枪地检验:它检索的信息是否全面?推理链条是否扎实?最终生成的报告中,是否存在事实性“幻觉”或逻辑漏洞?
为此,MiroMind团队推出了一套名为MiroEval的基准测试,将13个主流的Deep Research系统拉到了同一赛道上。参评选手包括了OpenAI Deep Research、Gemini、Claude、Kimi、Manus、Grok等几乎市面上所有知名产品。
测试结果颇有看点:OpenAI在事实准确性上得分最高,但综合排名却并非榜首。
现有评测框架的短板在哪?
以往对Deep Research系统的评测,大多停留在“评估最终报告质量”的层面。给定一套固定的评分标准(rubric),然后对生成的报告进行打分,流程就算结束了。
这种方式存在几个明显的短板。首先,一个系统可能搜索过程一团糟,东拼西凑,但最终凭借优秀的文本生成能力,产出了一份看起来逻辑清晰、文笔流畅的报告。如果只看最终输出,根本无法发现其研究过程的敷衍。反之,一个系统可能进行了扎实的搜索和推理,但报告组织和表达欠佳,在旧有标准下反而会得到低分。
其次,现有基准测试中的任务大多是人工合成的、偏向学术的问题,与真实用户的多元化、动态化的研究需求存在差距。此外,对多模态场景的评测几乎是空白:用户丢给系统一张图表、一份PDF或一份电子表格让其分析,绝大多数现有基准都无法覆盖这类场景。
MiroEval的三层立体评测法
MiroEval的核心思路是:不仅要看你交上来的“作业”(结果),还要审视你完成作业的“过程”。其评估框架主要包含以下三个维度:
- 自适应合成质量评估:针对每个具体任务,动态生成专属的评分维度和权重。例如,一个金融分析任务和一个代码生成任务的评估侧重点理应不同,而不是用一套僵化的通用标准去衡量所有任务。
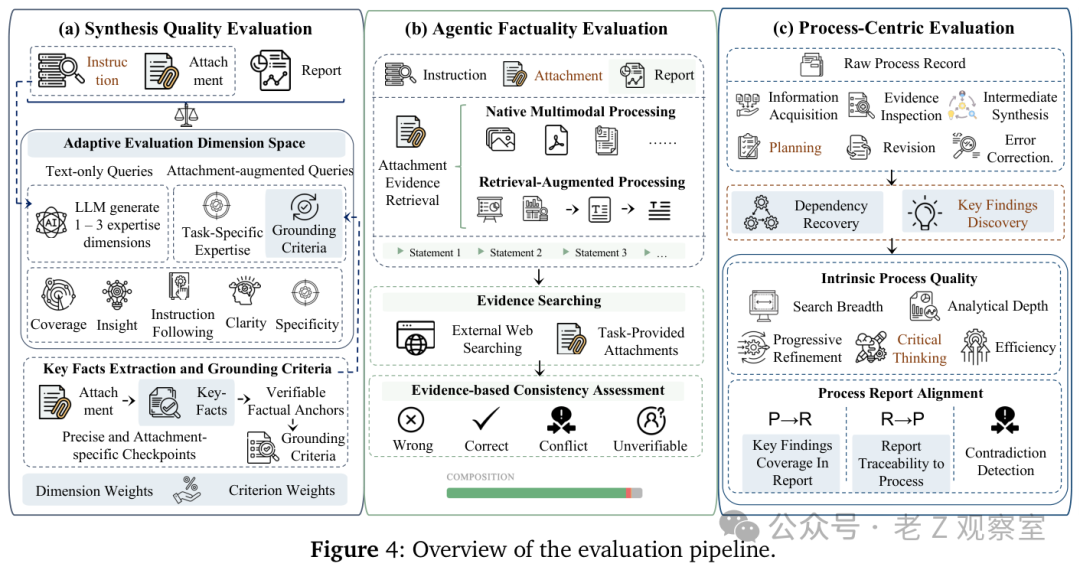
- 主动事实验证:将评估做到了原子级别。系统会将生成的报告拆解成一条条独立的声明(statements),然后派出一个专门的“核查智能体”去互联网上逐条核实证据,最终将每条声明判定为“正确”、“错误”、“矛盾”或“无法验证”四类,精确到每一句话。
- 以过程为中心的审计:这是最具创新性的部分。MiroEval从五个维度审计系统的整个研究过程:信息获取的广度、分析的深度、渐进式优化的能力、批判性思维的体现以及整体效率。此外,它还会检查“过程”与“最终报告”之间的双向对齐:报告里得出的结论,在研究过程中是否找到了依据?研究过程中发现的关键信息,在最终报告中是否被遗漏或错误表述?
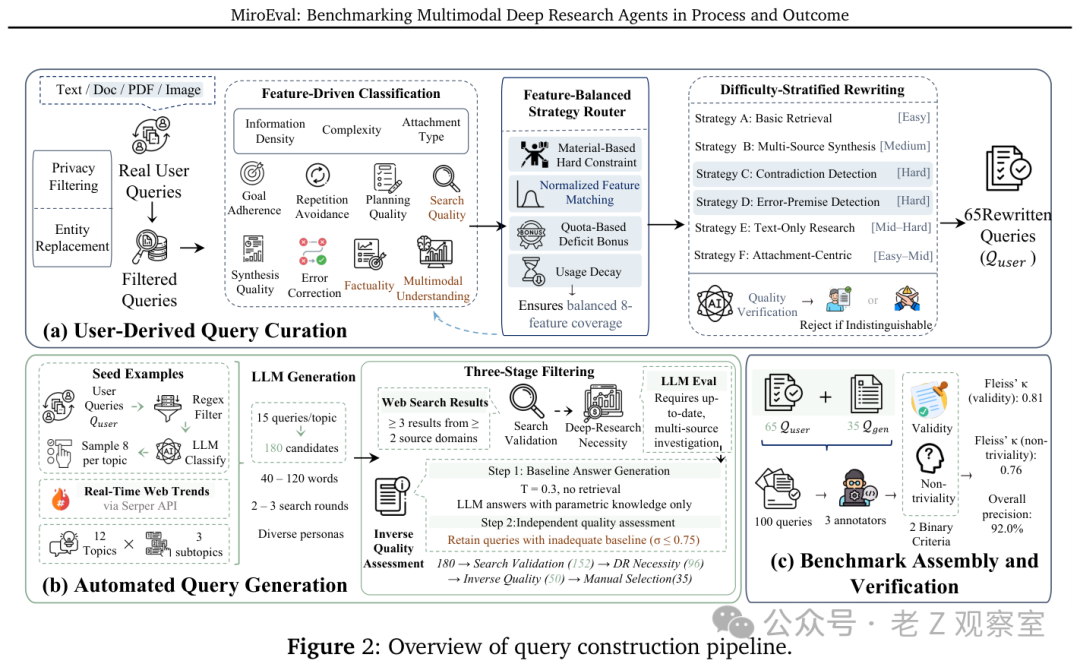
在任务构建上,MiroEval包含了100道题目,来源有二:65道来自对真实用户查询的脱敏与改写(其中包含30道多模态任务),35道基于实时网络趋势自动生成。这些题目覆盖了科技、金融、科学、医疗等12个不同领域。
13个系统的成绩单与排名分析

本次评测最值得关注的发现之一是:三个评估维度的排名差异显著,这说明不同的系统在不同方面各有所长。
- 合成质量:MiroThinker-H1以76.7分位列第一,Kimi以75.7分紧随其后,OpenAI Deep Research以73.8分排在第三。
- 事实准确性:OpenAI以83.3的高分遥遥领先,MiroThinker-H1(81.1)和MiroThinker-1.7(79.4)分列二、三位。这表明OpenAI在查证事实、避免幻觉方面确实做得最为扎实。
- 过程质量:MiroThinker-H1拿到了74.7的最高分,OpenAI以73.1分紧随其后。
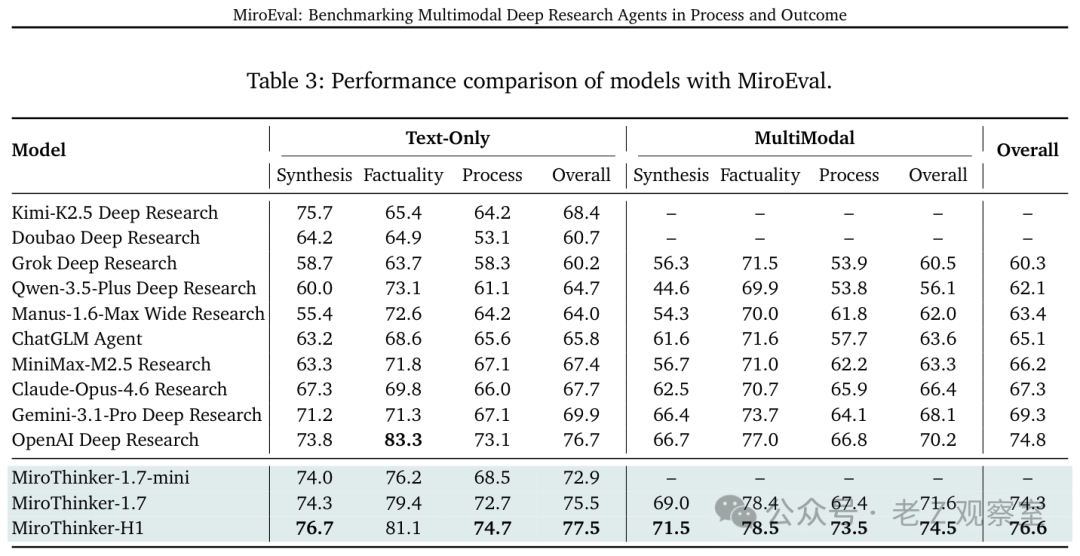
综合三个维度的表现来看,MiroThinker-H1是表现最为均衡的选手。OpenAI在事实性上展现出碾压级的优势,但在合成质量和过程质量上并非最强。Gemini表现中规中矩,三项均处于中上游。Claude的过程质量位于中游,但事实性表现尚可。
Manus的得分分布则比较有意思:它的合成质量得分最低(55.4),但事实准确性反而不差(72.6),这说明其研究(搜索与验证)能力尚可,但最终的报告组织和表达环节相对薄弱。Grok在三个维度上的表现均靠后。
多模态任务:当前系统的共同“短板”
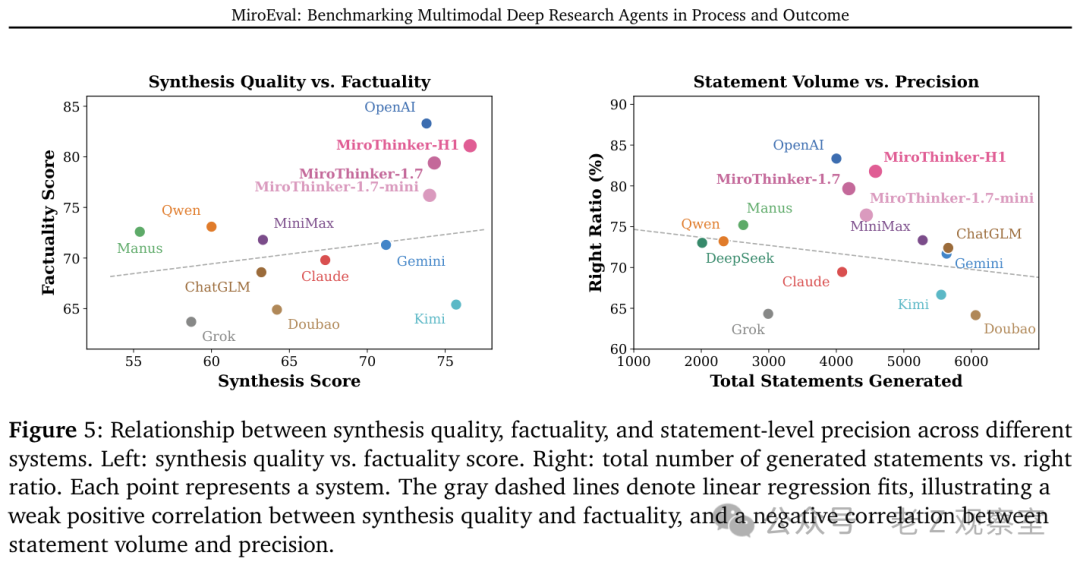
当评测加入多模态题目后,几乎所有系统的得分都出现了3到10分的下降。
这清晰地表明,目前这些Deep Research系统处理图像、PDF、电子表格等非纯文本信息的能力还远未成熟。在纯文本任务上打得有来有回的对手,一遇到需要结合图文进行分析的多模态场景,差距就被拉开了。
另一个重要发现是:过程质量高的系统,其最终报告质量普遍也更好。但过程审计的价值在于,它能暴露出仅看最终报告所无法发现的问题,例如分析深度不足、搜索策略低效、以及过程记录与最终报告结论之间的脱节等。
MiroEval还进行了人类排名验证,三位专家标注员给出的排名与自动评测排名之间的相关性(Kendall's τ)达到了0.91,这为自动评测结果的可靠性提供了一定支持。
如何客观看待这份评测报告?
首先必须承认一个事实:MiroEval基准由MiroMind团队创建,而排名靠前的MiroThinker系列也是该团队的产品。“裁判兼选手”的身份带来了显而易见的利益冲突,尽管报告通过人类验证和鲁棒性实验试图增加可信度,但这层关系仍需读者在解读排名时保持审慎。
撇开具体的排名争议,MiroEval所提出的“合成质量+事实验证+过程审计”的三层立体评测思路,无疑具有重要的参考价值。特别是将“过程质量”纳入核心评估维度,确实击中了当前Deep Research系统评测的盲区。只评估最终报告,就像只凭期末考试分数评价学生,而不管他平时是否认真研究、方法是否科学。过程质量既能预测结果质量,也能暴露结果层面无法察觉的深层问题,这个方向值得后续研究和产品开发重点关注。
当然,仅有100道题的基准规模仍然偏小,其覆盖的领域和难度分布可能无法完全代表真实世界中复杂多变的研究场景。但作为一个方向性的探索工作,它至少将“如何科学评测Deep Research系统”这件事,向前推进到了更系统化、更贴近真实需求的阶段。
关于深度研究系统的技术演进与评测方法,你可以在云栈社区的AI技术板块找到更多相关的深度讨论与资源分享。
 发表于 2026-4-6 12:38:22
|
查看: 267|
回复: 0
发表于 2026-4-6 12:38:22
|
查看: 267|
回复: 0
