当你构建一个多Agent系统或复杂的RAG应用时,后台的处理链可能会相当耗时。如果不给用户任何反馈,在前端看起来程序就像卡住了一样,体验非常糟糕。而用户并不知道,背后的Agent正在辛勤工作,力求给出一个完美的答案。
一个比较直观的解决方案,就是将后台的“思考”和处理过程实时地展示给前端用户。很多AI产品也正是这么做的,让用户看到一个清晰的进度,知道AI“正在思考问题”、“正在搜索资料”。
本文将以一个简单的教育性示例,手把手带您实现这一功能。为了聚焦核心逻辑,我们将用一个基于LlamaIndex的RAG系统作为后端,并用React构建前端,来模拟和展示AI的“思考”过程。
完整的项目代码可以在Github查看:https://github.com/ayuLiao/show_llm_thinking_example
最终实现的效果如下图所示:
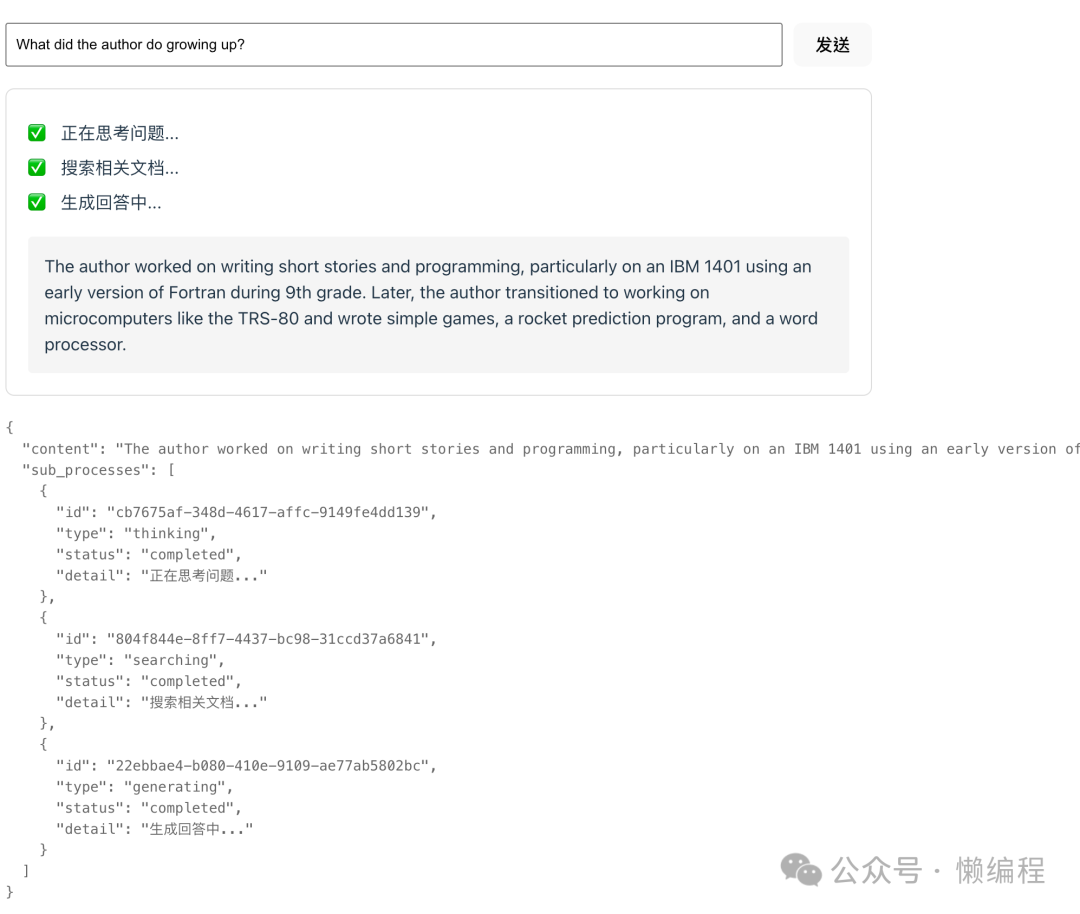
后端技术细节
核心思路是定义好数据模型,并在处理的每个关键节点,更新状态并推送给前端。
首先,我们定义Message对象。它不仅是最终答案的载体,还包含了一个sub_processes列表,用于记录所有的子处理过程状态。
class ProcessType(str, Enum):
THINKING = "thinking"
SEARCHING = "searching"
ANALYZING = "analyzing"
GENERATING = "generating"
class SubProcess(BaseModel):
id: str
type: ProcessType
status: str
detail: str
class Message(BaseModel):
content: str
sub_processes: List[SubProcess]
当用户发起提问时,我们先创建一个初始的、内容为空的Message对象。然后,我们按照处理流程,逐步创建并更新sub_process,并通过一个异步队列(示例中使用send_chan)将状态变更实时推送给前端API,再由API通过Server-Sent Events(SSE)推给浏览器。
1. 思考阶段
在此阶段,我们添加一个“正在思考”的子过程。
content = ""
message = Message(content=content, sub_processes=[])
# 思考阶段
thinking_process = SubProcess(
id=str(uuid.uuid4()),
type=ProcessType.THINKING,
status="running",
detail="正在思考问题...",
)
message.sub_processes.append(thinking_process)
await send_chan.put({"data": json.dumps(message.model_dump())})
await asyncio.sleep(0.5)
thinking_process.status = "completed"
await send_chan.put({"data": json.dumps(message.model_dump())})
2. 搜索阶段
接下来,模拟文档检索过程。
# 搜索阶段
search_process = SubProcess(
id=str(uuid.uuid4()),
type=ProcessType.SEARCHING,
status="running",
detail="搜索相关文档...",
)
message.sub_processes.append(search_process)
await send_chan.put({"data": json.dumps(message.model_dump())})
# 实际调用 LlamaIndex 查询
response = query_engine.query(question)
search_process.status = "completed"
await send_chan.put({"data": json.dumps(message.model_dump())})
3. 生成回答阶段
最后,流式生成最终答案,并逐字添加到message.content中。
# 生成回答阶段
generating_process = SubProcess(
id=str(uuid.uuid4()),
type=ProcessType.GENERATING,
status="running",
detail="生成回答中...",
)
message.sub_processes.append(generating_process)
await send_chan.put({"data": json.dumps(message.model_dump())})
# 逐字输出回答
for word in str(response).split():
content += word + " "
message.content = content
await send_chan.put({"data": json.dumps(message.model_dump())})
await asyncio.sleep(0.1)
generating_process.status = "completed"
await send_chan.put({"data": json.dumps(message.model_dump())})
await send_chan.put(None)
整个流程非常清晰。如果你正在构建多Agent系统,原理也完全一样:初始化一个Message,然后随着每个Agent的处理完成,不断更新其sub_processes并推送,前端便能实时渲染出整个协同思考的链路。
前端技术细节
前端的工作相对直接。在React项目中,当用户提交问题后,我们通过EventSource连接到后端SSE接口,并监听onmessage事件来接收实时状态更新。
关键代码如下:
const handleSubmit = async (e: React.FormEvent) => {
e.preventDefault();
if (!question.trim() || isLoading) return;
setIsLoading(true);
setMessage({ content: "", sub_processes: [] });
const eventSource = new EventSource(
`http://localhost:8000/chat?question=${encodeURIComponent(question)}`
);
eventSource.onmessage = (event) => {
console.log("Received event:", event.data); // 调试日志
try {
const newMessage = JSON.parse(event.data);
setMessage(newMessage);
} catch (error) {
console.error("Error parsing message:", error);
}
};
eventSource.onerror = (error) => {
console.error("EventSource error:", error); // 调试日志
eventSource.close();
setIsLoading(false);
};
// 添加onopen处理
eventSource.onopen = () => {
console.log("EventSource connected"); // 调试日志
};
// 清理函数
return () => {
eventSource.close();
setIsLoading(false);
};
};
在页面渲染部分,我们只需要遍历message.sub_processes数组,根据每个子过程的status和detail来展示进度条或状态图标,同时渲染message.content作为流式输出的答案。
<div className="message-container">
<div className="process-list">
{message.sub_processes.map((proc) => (
<div key={proc.id} className="process-item">
<span className={`status ${proc.status}`}>
{proc.status === "running" ? "⏳" : "✅"}
</span>
<span>{proc.detail}</span>
</div>
))}
</div>
<div className="content">{message.content || "等待回答..."}</div>
</div>
这样一来,一个能够实时展示AI“思考过程”的前端交互就完成了。通过这个例子,我们可以看到,将后端处理状态结构化和实时推送,是提升AI应用用户体验的关键。希望这个简单的示例能为你实现更复杂的多Agent或工作流系统提供启发。想了解更多关于Python和AI结合的实战技巧,欢迎来云栈社区交流讨论。
 发表于 2026-4-8 09:17:10
|
查看: 198|
回复: 0
发表于 2026-4-8 09:17:10
|
查看: 198|
回复: 0
