写在前面:为什么是 Karpathy,为什么是 Agent
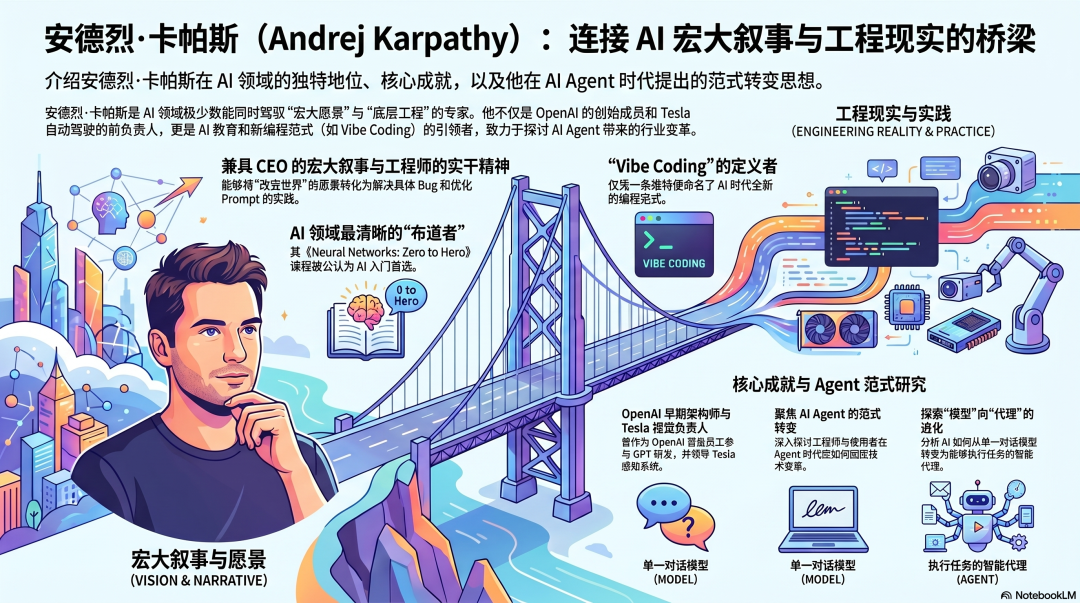
2026年,AI Agent早已不是一个空泛的概念。
它正在真实的生产环境中运行着真实的任务——编写代码、分析研究、处理邮件、管理日程、通宵执行实验。大量工程师的日常工作重心,已然从“亲手写代码”转变为“监督Agent写代码”。
然而,多数人对Agent的理解仍停留在“更强大的ChatGPT”这个层面。他们用着Agent,却不明白为什么它在某些任务上智慧得惊人,而在另一些任务上又愚蠢得离谱。他们调整着Prompt,却无法解释为什么同一段Prompt时而奏效,时而完全失控。
在这个领域,Andrej Karpathy是为数不多把问题本质彻底想清楚的人。
作为OpenAI的早期核心成员、GPT系列架构的参与者、特斯拉Autopilot感知系统的负责人,以及广受好评的《Neural Networks: Zero to Hero》课程的作者,他同样是那个发明了“Vibe Coding”一词的人。2025年初一条随手的推文,精准地定义了一整代工程师的编程范式。
但更重要的是:他是一位真正在依靠Agent工作,而非仅仅空谈Agent的实践者。
在Eureka Labs,他用Agent进行机器学习研究,通宵跑实验,处理那些他曾经必须亲自编写代码才能完成的事务。他的判断,源于扎实的工程实践,而非单纯的理论推演。
本系列旨在系统梳理Karpathy的Agent思想体系。
本篇作为开篇,我们将从2017年的一个关键论断讲起——正是这个论断,在今天直接推导出了Agent出现的必然性。
一、那篇博客,和它被低估的含义
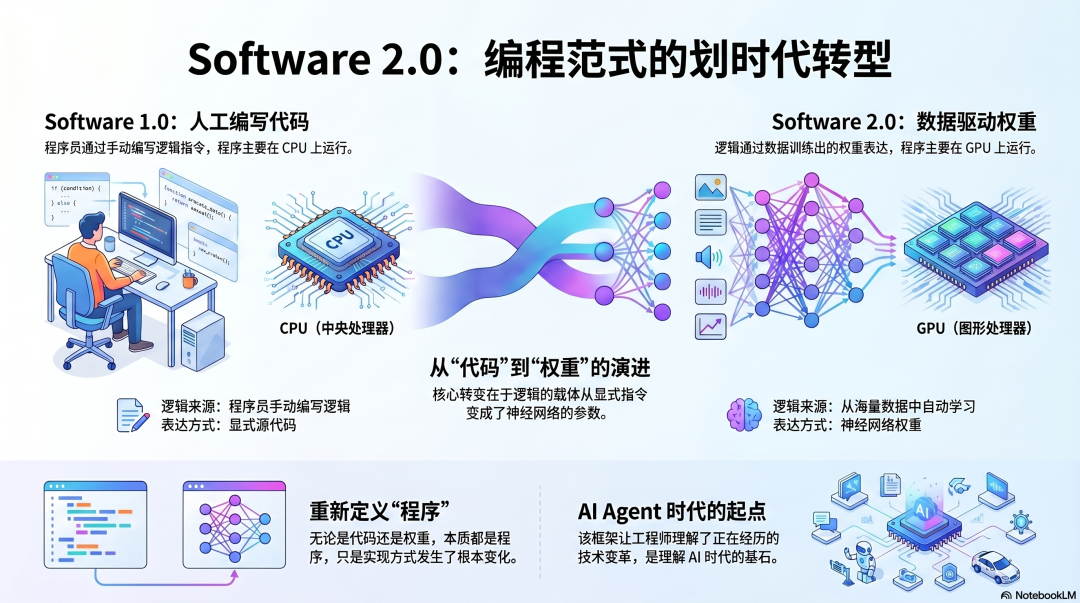
2017年,Karpathy在Medium上发表了一篇题为《Software 2.0》的文章。
这并非学术论文,也不是什么演讲,就是一篇普通的博客。但在随后的几年里,它的引用频率却超过了绝大多数的正式学术文献。
文章的核心论断振聋发聩:
我们正从“用代码表达逻辑”的时代,步入“用权重表达逻辑”的时代。
Software 1.0:程序员撰写代码,代码是显式指令,由CPU执行。
Software 2.0:程序员定义目标与数据,逻辑被“学习”到权重中,由GPU执行。
这个论断在2017年听起来像是对机器学习趋势的一种描述。但当我们回首审视,它其实是一个精准的预言——一个关于Agent行将登场的预言。
逻辑推演如下:
如果权重能够表达逻辑,甚至能表达人类难以编写的复杂逻辑(比如识别行人、理解自然语言、生成代码),那么当这种“学出来的逻辑”足够强大时,它就不再仅仅是一个函数,它可以成为一个 决策者。
一个能够理解任务、分解步骤、调用工具、处理结果并持续执行的决策者。
这个决策者,就是Agent。
Software 2.0并非Agent时代的背景板,它恰恰是Agent时代的逻辑起点。
二、特斯拉给了他什么工程直觉
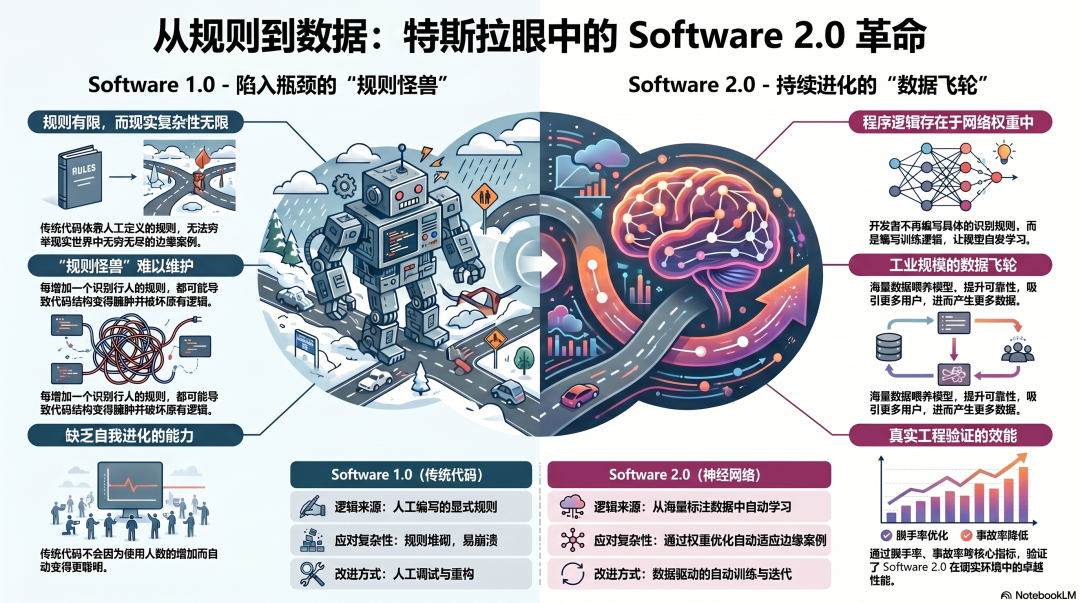
这个论断并非凭空而来,Karpathy在特斯拉的经历是其真正的源头。
2017年,他加入特斯拉,负责Autopilot的感知系统。他的使命是:将AI塞进真实的汽车,并让它行驶在真实的道路上。
雨天、雪天、强烈的逆光、施工区、突然变道的卡车、路面上飘过的塑料袋——每一种场景都必须得到可靠的处理。
若沿用传统代码(Software 1.0)来完成这件事,无异于一条死胡同。你需要为无穷无尽的边缘情况编写规则,而规则只会越积越多,系统越来越脆弱,最终没人能完整地维护它。
而神经网络的方式则截然不同:喂给它海量数据,让模型自己去学。
更为关键的是,他在特斯拉目睹了一种重塑他工程直觉的现象:数据飞轮。
特斯拉的车队在路上奔驰,每天产生着海量的真实路况数据。这些数据投喂回去,模型就变得更好;模型越好,功能就越可靠;功能越可靠,用户就更愿意开启Autopilot;更多的使用又会催生更多的数据——一个完美的飞轮就此转动起来。
这个飞轮,只有在Software 2.0的框架下才能运转。代码不会因为被更多人使用就自我优化,但权重可以。
Karpathy将这份宝贵的工程直觉带出了特斯拉,并融入了后来他对大语言模型(LLM)与Agent的一切判断里。在云栈社区上,我们经常探讨这种从自动驾驶领域迁移到通用AI的思维模式,它对理解AI Agent的工程化落地至关重要。
三、从特斯拉到 LLM:他看到的那条线
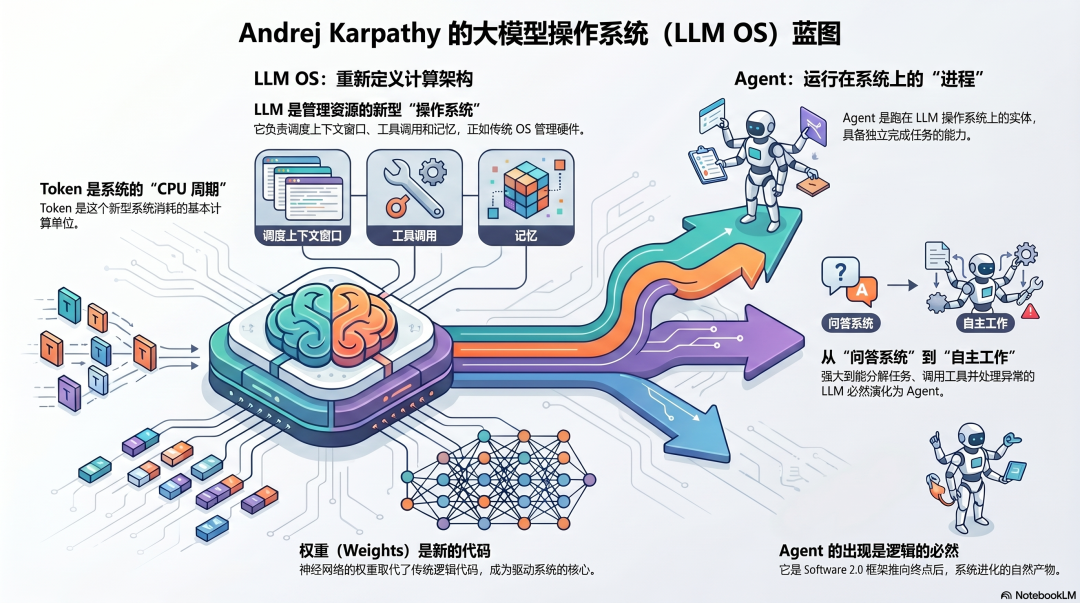
2022年,Karpathy离开特斯拉,重返OpenAI。
那时,GPT-4的训练尚未完成,ChatGPT也还未向世人发布。但他已经能比公众提早近一年,洞察到正在发生的巨变。
在这段时期,他将Software 2.0的框架推演到了一个必然的逻辑终点:
如果权重是新的代码,那么大语言模型(LLM)就是新的操作系统。
这并非一个虚幻的比喻。在2023年的一次演讲中,他清晰地阐述了这个框架:
- LLM是操作系统,负责管理资源(如上下文窗口、工具调用、记忆)
- Token是CPU周期,是这个系统消耗的基本计算单位
- Agent是跑在这个操作系统上的进程,独立执行任务
在此框架下,Agent并非一个新鲜的功能,更不是ChatGPT的加强版——它是Software 2.0框架走向逻辑终点后,必然出现的产物。
当一个LLM强大到足以理解复杂指令、分解多步骤任务、调用外部工具、处理异常状况并持续执行时,它便不再是一个被动的问答系统,而蜕变为一个能够自主工作的Agent。
四、他自己的转变:停止写代码的那一天
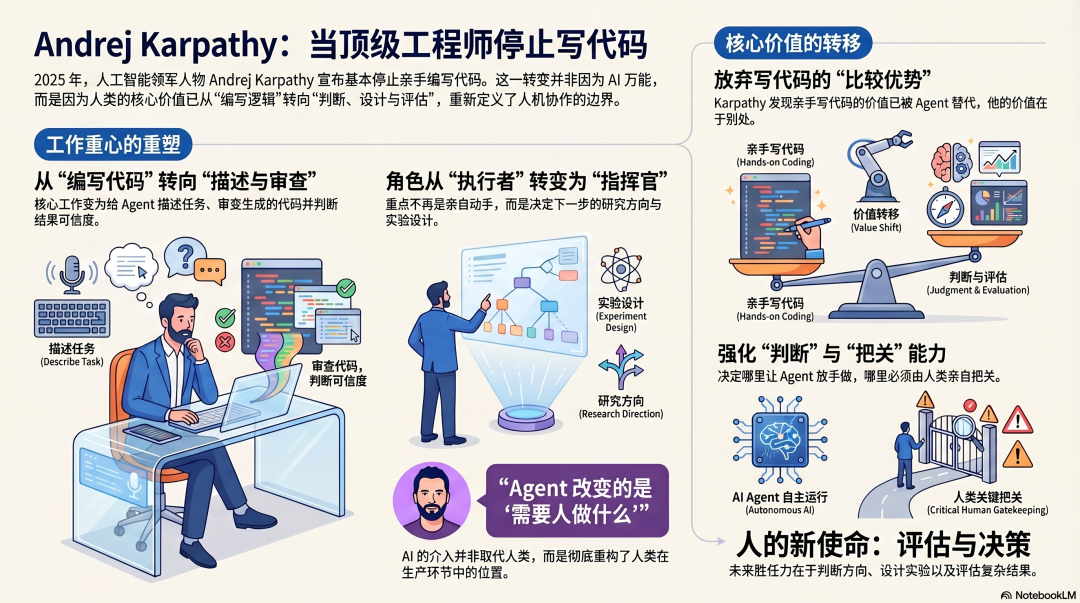
要理解Karpathy关于Agent的判断,我们不能只听其言,更要观其行。
2025年,他在社交媒体上描述了自己的工作状态:他仍在从事机器学习研究,但亲手编写代码的比例越来越低。大量工作变成了:向Agent描述任务、审查Agent生成的代码、判断结果的可信度、决定下一步的研究方向。
至2025年底,他的一条推文在工程师圈内引发了轩然大波:
他基本上停止亲手写代码了。
这条推文,后来成为了本系列第十六篇的核心,届时我们会详细拆解他停止写代码后,时间花在了哪里,哪些技能变得更为关键。
这里先点出最关键的一点:
他停止写代码,不是因为Agent已经无所不能,而是因为他发现自己的比较优势已然不在此处。
在Karpathy能贡献价值的众多事务中,亲手写代码这件事的价值,已经被Agent有效地替代了。他的价值转移到了别处:判断方向、设计实验、评估结果、以及在何处让Agent放手去做,在何处又必须由自己亲自把关。
这个转变,是他对Agent最深层次判断的直接体现:
Agent改变的并非“需不需要人”,而是“需要人做什么”。
五、“代码已死”——这句话的完整含义
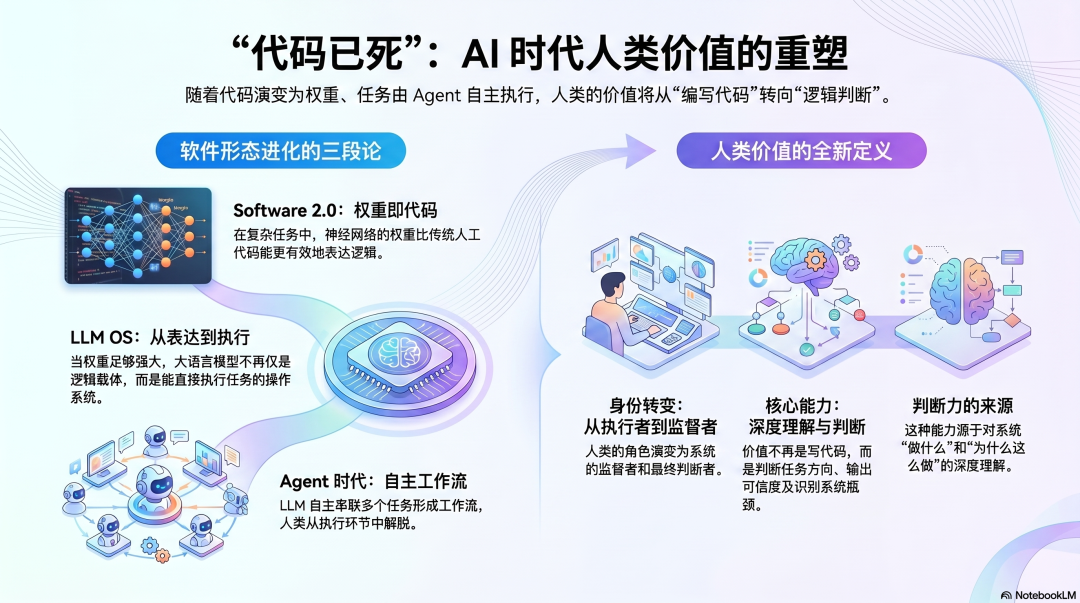
至此,我们可以完整地回答那个初始问题了。
当Karpathy说“代码已死,权重是新的代码”时,他实质上在阐述一个三段论:
第一段:在越来越多的任务领域中,用权重来表达逻辑比用代码更高效——这是Software 2.0的核心论断。
第二段:当权重强大到某个程度时,它不仅能“表达逻辑”,更能“执行任务”——这是把LLM视作操作系统的论断。
第三段:当LLM能够自主执行任务,并能将多个任务串联成工作流,人类的角色便从“执行者”转变为“监督者与判断者”——这正是Agent时代的论断。
这三段论述一脉相承。“代码已死”作为第一段,必然推导出Agent的出现,也必然推导出人类工作方式的彻底转变。
但这引出了一个Karpathy从不回避的根本问题:
如果代码可以被生成,如果Agent可以执行任务,那人类的价值何在?
他的答案贯穿了整个系列的后29篇文章。简洁的版本是:
人类的核心价值,在于判断。
不是判断代码该怎么写,而是判断:任务方向是否正确、Agent的输出是否可信、何时必须亲自介入、什么才是真正的问题而非问题表象。
这种判断能力,并非单纯从写代码中习得——它来自于对“这个系统在做什么、为什么这样做、会在哪里出错”的深度理解。
Software 2.0改变的不是需不需要人,而是需要人做什么。而“做什么”这个问题的最终答案,正是整个系列试图拼凑出的地图。
六、2026年:这个判断已经验证到什么程度
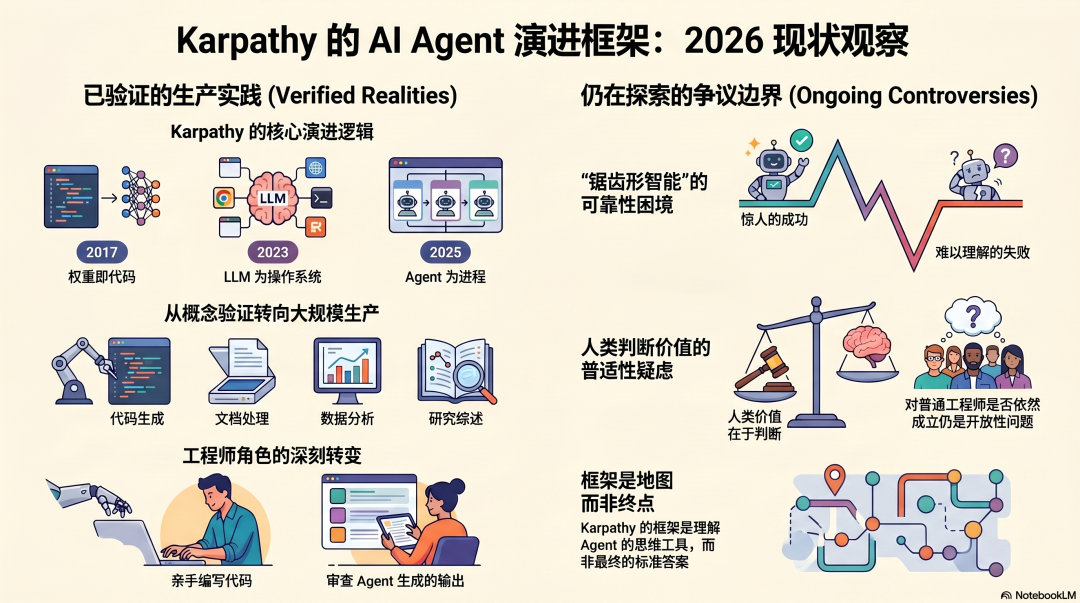
回到当下。
Karpathy在2017年说“权重是新的代码”,在2023年说“LLM是操作系统”,在2025年说“Agent是跑在上面的进程”——时至2026年,这套框架到底得到了多大程度的验证?
已被验证的部分:
Agent确实在真实场景中完成了真实的工作。代码生成、文档处理、数据分析、研究综述——这些任务的Agent化早已不再是概念验证,而是大规模的生产实践。
工程师的工作方式,也确实在朝着Karpathy所描述的方向转变:越来越多人将更多时间花在“审查Agent的输出”上,而非“亲手编写代码”上。
尚存争议的部分:
Agent可靠性的边界究竟在哪里——这个问题在2026年依然没有定论。Karpathy本人也承认,Agent在一些任务上展现出了惊人的能力,而在另一些任务上却会出现令人费解的失败。
“人类的价值在于判断”这个结论——在Karpathy这个级别的专家身上是成立的,但对于广大的普通工程师群体是否同样成立,仍是一个有待探讨的开放性问题。
这种不确定性,恰恰是本系列存在的理由。
Karpathy的框架,是目前理解Agent最为清晰的思维工具,但它并非最终的答案,而是一张高精度的地图。地图可以清晰标示地形,但脚下的路,最终还得靠我们自己走。
 发表于 5 天前
|
查看: 9|
回复: 0
发表于 5 天前
|
查看: 9|
回复: 0
