事情是这样的。
Google DeepMind 的两位工程师最近发了篇论文,读完后我盯着屏幕愣了半晌。
Xiaoyu Ma 在 DeepMind 做系统架构,David Patterson 在 UC Berkeley 教计算机体系结构,同时兼任 Google 杰出工程师,更在 2017 年拿到了图灵奖。
这俩人凑一块写的文章,不太可能是唬人的。
论文讨论的,是大模型推理的硬件——不是训练,而是推理。
你可能分不太清这两者。训练就像学生上课:把数据喂给模型,让它学习。推理则是让学好的模型回答问题,好比考试答题。
如今所有人都在聊大模型多厉害,却很少认真想过一个问题:推理太烧钱了。
烧到 OpenAI 一年亏损 50 亿美元,微软在 AI 上砸下的资金更让人倒吸凉气。问题不在于模型不够好,而是现有的硬件架构从根本上就不适合推理。
论文有句话非常直白:在 2025 年的顶级体系结构会议上,产业界的贡献占比已不到 4%。回看 1976 年,这个数字是 40%。
学术界与工业界几乎脱节了。
而他们恰恰认为,推理这个领域最需要产业界的真金白银与学术界的严密思考。
推理为什么这么费劲?
大模型推理有两个阶段:预填充(Prefill)与解码(Decode)。
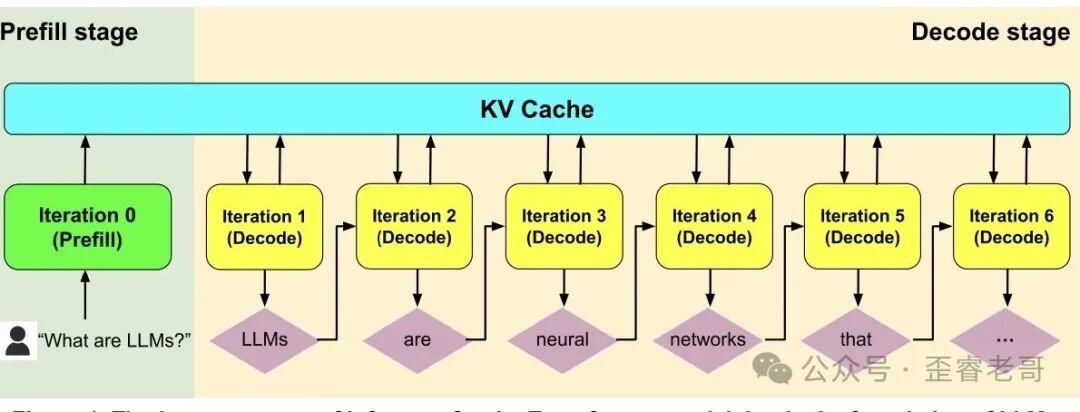
预填充相当于模型一次性读完你的问题,这是并行的,类似做阅读理解。解码才是真正开始输出答案,一字一字往外蹦,如同写作文。
预填充是计算密集型,解码则是内存密集型。
问题就卡在这里。现在数据中心里跑的 GPU 和 TPU,全都是为训练——或者说为预填充——设计的。它们算力很强,高带宽内存也够大,但这些对解码阶段几乎用错了地方。
解码的时候,模型每次只能吐出一个 token,得反复从内存中取权重和上下文。实际计算量很小,内存访问开销却大得惊人。这好比让一位短跑冠军去翻箱倒柜找东西,他的爆发力完全使不上劲。
更麻烦的是,近年的模型趋势还在不断加剧这组矛盾。
MoE 架构让模型参数膨胀了成百上千倍。DeepSeek v3 有 256 个专家,每次推理只激活一小部分,但权重总量却大得吓人。长上下文让 KV Cache 越来越大——一个 200K 上下文窗口所需内存是普通窗口的几十倍。推理模型还得先生成大量「思考」token 才能给出最终答案,直接把输出长度拉长了数倍。
模型越来越大,上下文越来越长,推理越来越慢。而硬件架构,十年没变过。
一个刺眼的数据
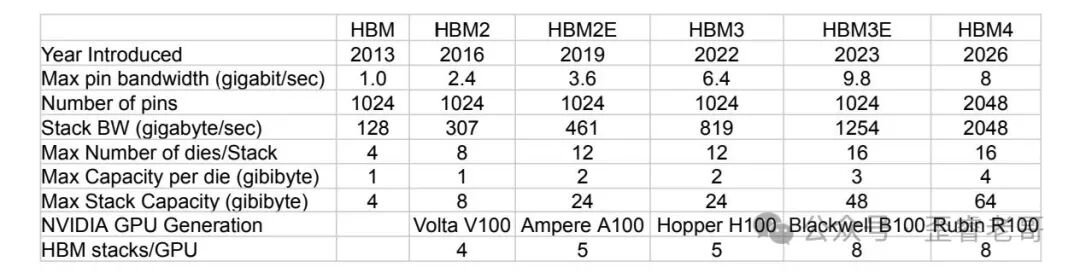
从 2012 到 2022 年,NVIDIA GPU 的浮点运算能力翻了 80 倍。但内存带宽,只涨了 17 倍。
算力在狂奔,内存在散步。
这两者的差距还会越拉越大,因为 HBM 越来越贵。
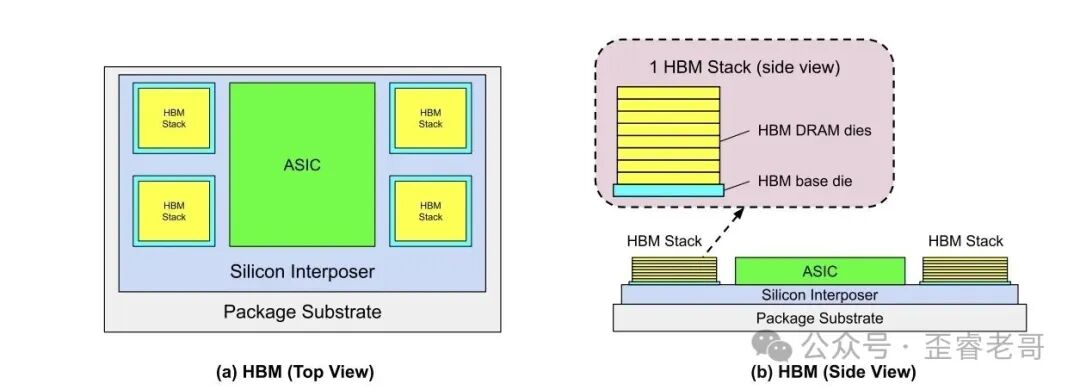
HBM,就是现在 GPU 配备的那种高带宽内存,像一摞饼干一样叠在 GPU 附近。
2023 到 2025 年间,每 GB 容量的成本和每 GBps 带宽的成本都涨了 1.35 倍。
反观普通 DDR 内存,成本却在持续下降。同一时间窗口,容量成本降到了原来的 0.54 倍,带宽成本降到了 0.45 倍。
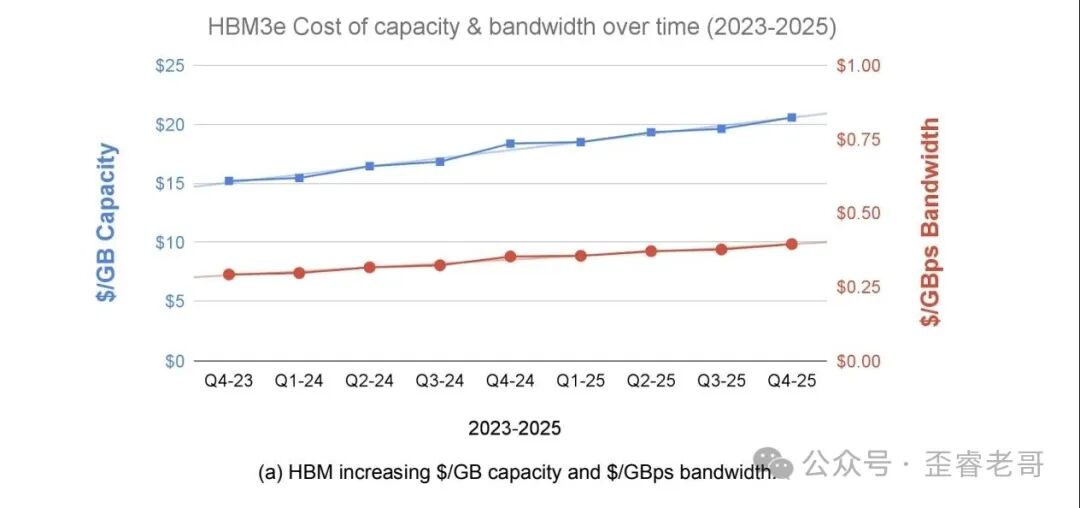
数据很说明问题。HBM 并非产能问题,而是物理堆叠难度在攀升。
每个 HBM 封装里 DRAM 芯片数量越来越密,单颗芯片密度也越来越高,良率和封装难度几乎呈指数级上升。而传统硅基内存技术仍沿着摩尔定律稳稳前进。
论文还触及了一个更底层的困境:DRAM 单芯片的密度增长正在减速。2014 年推出的 8-Gigabit DRAM 芯片,到 2026 年才实现四倍增长,这速度比过去每三到六年翻一番要慢得多。
全用 SRAM 替代 DRAM 的方案同样走不通。
Cerebras 和 Groq 都曾尝试用超大芯片塞满 SRAM 来绕开 DRAM 和 HBM。结果呢?大模型一上线,片上 SRAM 的容量根本不够用,两家最后都不得不 retrofit 外挂 DRAM。
硬件这条路,不是换条道就能抄近道的。
真正有价值的部分:四个破局方向
两位作者提出了四项有前景的研究方向,每一个都直指推理硬件的核心痛点。
1. 高带宽闪存(HBF)
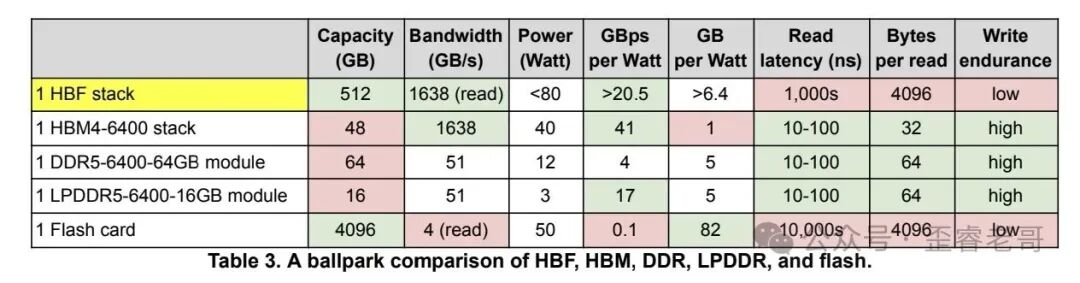
这个概念最早由 SanDisk 提出,SK 海力士随后加入。做法简单粗暴:把闪存芯片像 HBM 一样堆叠起来,获得接近 HBM 的带宽,而容量则是 HBM 的十倍以上。
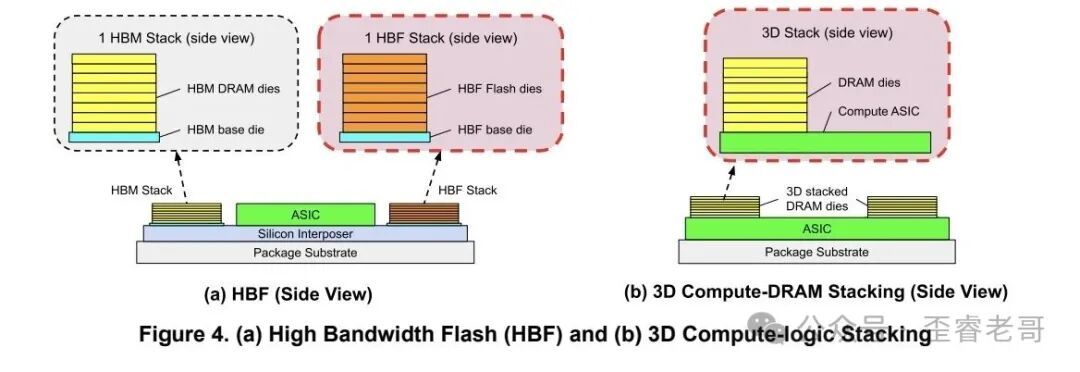
一块 HBF 封装有 512GB 容量,读取带宽可达 1638 GBps。对比之下,HBM4 的带宽同样是 1638 GBps,容量却只有 48GB。容量差出十倍以上,读取带宽却打平了。
功耗方面,一块 HBF 封装不超过 80 瓦,HBM4 是 40 瓦。单看 HBF 功耗更高,可一旦考虑容量差距,每 GB 的功耗 HBF 反而更低。
论文作者粗算了一笔账:用 HBF,推理系统的整体尺寸可以大幅缩小。模型权重能全部加载进一个更紧凑的系统,芯片数量减少,通信开销降低,可靠性提升,数据中心的空间和电力预算也能喘口气。
HBF 当然不是银弹。闪存写入寿命有限,每次读写粒度是页面级别而非字节级别,延迟比 DRAM 高好几个数量级。因此它只能存那些不常变动的数据:模型权重、知识库语料、代码仓库。而每次推理都要更新的 KV Cache,还得靠 DRAM。
但这恰恰显出 HBF 的精明之处——它不试图包办一切,而是找准自己最舒服的生态位。
一个网页搜索 AI 系统,背后可能存储了数十亿份网页文档,这些文档并不会每天刷新。一个代码辅助 AI,背后有数十亿行代码,也不会每天全量更新。一个科研辅导 AI,背后是数百万篇论文。这些全是「慢变上下文」。
HBF 可以把这些一次性加载、反复读取、几乎不改动的数据,用极低的空间成本塞进去。
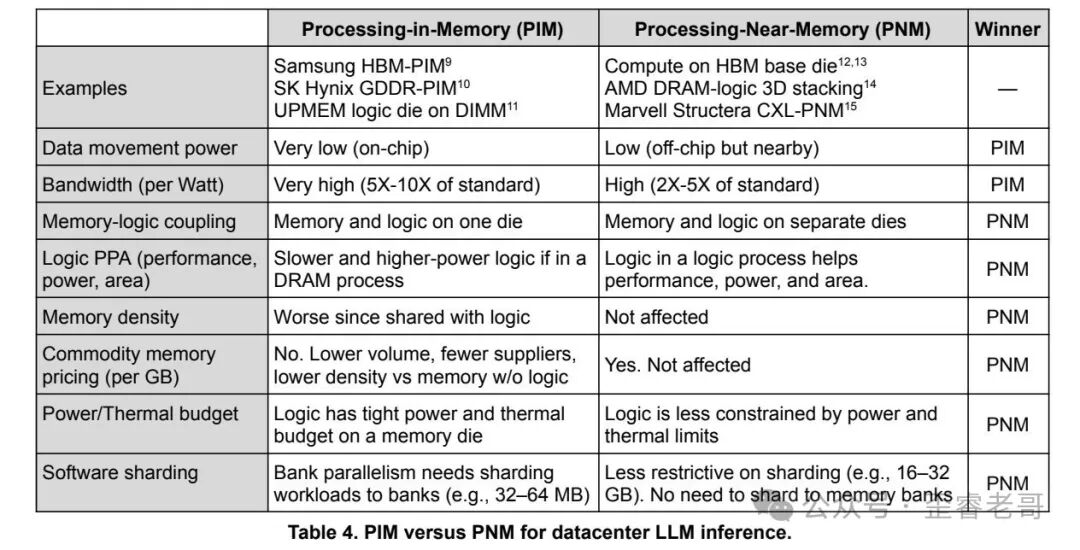
2. 近存计算(PNM)
这个词听起来绕口,说通俗点就是:在内存边上放一个小处理器,让数据不必跑远路去计算。
这里要分清两个概念:PIM 是把处理器和内存做在同一颗芯片里;而 PNM 则是把处理器和内存分居不同芯片,但挨得很近。
论文作者特意强调这层区别,因为二者差异巨大。PIM 将计算逻辑塞进 DRAM 工艺节点,功耗和面积效率都很差。PNM 用的是独立芯片,可以选择更成熟的逻辑工艺,散热也更容易控制。
PNM 不需要像 PIM 那样把 LLM 的结构切成 32 到 64MB 的小块。因为内存和逻辑不在同一个 die 上,数据能按更大粒度来划分。这对 LLM 推理来讲太关键了。
已经有公司开始往这个方向走了。AMD 提出了 DRAM 与逻辑芯片 3D 堆叠的方案,三星做了 AXDIMM 将计算逻辑集成进 DIMM 缓冲芯片,Marvell 的 Structera 则用 CXL 接口实现了 DDR 与处理器的连接。
3. 3D 内存逻辑堆叠
这个方向更激进——它不把处理器搁在内存边上,而是直接把处理器芯片垒在内存芯片头顶,用硅通孔 TSV 做垂直连接。带宽和密度都远超 2D 平面布局。
这条路有两种实现选择:一是复用 HBM 设计,把计算逻辑塞进 HBM 的基座芯片,好处是接口不用动,带宽与 HBM 相同,但数据路径变短,功耗降低两到三倍。另一种是定制化 3D 方案,用更宽的接口和更先进的封装技术,带宽和能效可以超越 HBM 本身。
挑战当然也很大。3D 堆叠的散热是硬骨头——计算芯片趴在上面,表面散热面积反倒更小。论文给出的解法是降低时钟频率和电压。反正 LLM 解码阶段的计算强度本来就不高,用低频换散热,是完全可接受的妥协。
4. 低延迟互连
前面三个方向都聚焦在单颗芯片或单个节点上。这个方向解决的是多芯片之间的通信问题。
训练阶段的超算追求的是带宽,得传输海量的梯度数据。但推理阶段完全是另一回事:每次推理请求的数据量很小,频率却极高,这时候延迟比带宽重要得多。
论文提出了几个有意思的思路。高连通性的拓扑结构——比如树形、dragonfly 和高维环形——可以减少通信跳数从而压住延迟。即便带宽因此有所损失,推理对延迟的敏感度也远高于带宽。
网络内计算也是个方向。LLM 使用的集合通信操作,如广播、all-reduce、MoE 的调度分发,在网络层直接进行聚合,可以大幅削减延迟与带宽开销。NVIDIA 的 NVLink 和 Infiniband 交换机已经支持 in-switch reduction。
甚至有个更反直觉的想法:如果 LLM 推理不需要完美通信呢?当消息超时,用近似结果或之前的缓存值来替代,而不是空等慢速消息抵达。论文认为这可以在不大牺牲质量的前提下,显著压缩延迟。
其实这想法背后的逻辑很值得琢磨:我们习惯了通信必须可靠完整,可大模型推理的特性恰恰是输出本身就有不确定性。假如消息延迟造成的精度损失,比模型自身的不确定性还小,那何乐而不为呢?
读到这里你可能发现了一个规律:这四个方向都不是要制造更彪悍的计算芯片。它们全都指向同一个思路——
别再堆算力了,去解决内存和通信的问题。
过去十年,AI 硬件的进化方向过于单一:更大的芯片、更多的核心、更高的 FLOPS。训练阶段确实需要这些,因为矩阵乘法是计算密集型的。但推理阶段,特别是解码阶段,核心瓶颈从来不是算力,而是内存带宽、内存容量和通信延迟。
继续用训练芯片做推理,就像开一辆 F1 赛车去送外卖。引擎确实猛,可载货空间不够,油耗太高,在城里同样跑不快。
论文作者最后提出了一个建议:整个计算机体系结构的研究社区,需要一套基于 roofline 模型的性能模拟器,专门用于评估推理场景下的内存与通信优化。这算不得全新想法,只是这些年来大家太容易被算力牵着走——缓存设计、分支预测这些传统体系结构问题,都是靠着真实模拟器才得以突破的。推理硬件领域不缺想法,缺的是系统化的评估手段。
这篇论文本身即是一次重新连接的努力:用产业界的真实数据、真实痛点去激发学术界的研究灵感,再用学术界的严谨方法,回应一线用户正面临的工程难题。
这可能正是 AI 硬件未来所需要的东西——不是某个人或某家公司单打独斗,而是把产业和学术重新捏合在一起,用更务实的方法,来解决真正卡脖子的问题。
你可能还会对云栈社区上关于 AI Infra 技术趋势 的更多内容感兴趣,那里有不少同路人在讨论类似的话题。
 发表于 2026-5-5 18:44:42
|
查看: 133|
回复: 0
发表于 2026-5-5 18:44:42
|
查看: 133|
回复: 0
