最近V4的技术报告讨论度很高,其中TileLang也占据了一部分篇幅,主要总结了社区近期的技术进展,以及将其投入实际工业界应用后的一些打磨经验。
这篇文章带大家简单解读一下技术报告中TileLang的部分,同时也分享一些关于编译器DSL在真实模型基础设施中定位的思考。
开头附上TileLang本体的项目位置,以及最近DeepSeek开源的TileKernels——一系列由TileLang实现的高效LLM小算子。
本文目录
- DSL v.s. 专家手写
- TileLang 的设计精髓
- V4 设计报告里的几个点
- 总结一下
- 读者评论

DSL v.s. 专家手写
随着基础模型架构的收敛,模型中的计算模式变得固定,因此现在的Infra团队基本选择手写kernel来追求更高的性能上限。这使得DSL/编译器看起来重要性越来越低。现在甚至出现了像MegaKernel这样更极端的理念,试图将手写调度的潜力发挥到极致。在这种大背景下,DSL的定位似乎有些尴尬。
从TileKernels开源库可以看到,其中的算子以不带Tensor Core的操作为主,包括elementwise与reduce的组合、类型转换及索引操作等。同时,技术报告中也提到,TileLang在V4基础设施中通过一系列fused kernel取代了模型中的细粒度小算子。这样一来,在Infra层面就形成了DSL负责零碎小算子,而Attention、GEMM则由专家定制优化的格局。我个人认为,这套Infra整体结构是相当健康的。这里自然引出一个问题:为什么这部分零碎算子的fused kernel不手写呢? 当然,手写是完全可以的。但DSL在这类算子上的优势十分明显。
- 开发优势: 通常我们对DSL的认知是开发成本与性能之间存在权衡,但对于这类小算子,几乎不存在这种权衡。主要是因为这类受内存带宽限制的算子大多不需要Tensor Core,因此像各种Warp Specialization的复杂问题也就更少了,DSL的性能基本可以追平手写的上限。在这个前提下,用DSL开发确实快得多。这一来一回,性能无损外加开发速度提升,优势自然就很大了。
- 维护与迁移优势:除了开发上的优势,DSL在维护上的心智负担也很低。用DSL维护的算子库会更加简洁,如果问题是编译器导致的,甚至不需要改动算子库本身。同时,它对硬件的依赖也较低,在不同后端之间迁移也更加轻松愉快。
对于带Tensor Core的算子,TileLang同样能有不错的开发表现。典型例子比如TileLang仅用80行Python代码就实现了FlashMLA 95%的性能[1],以及最近Qwen团队开源的FlashQLA[2],其使用TileLang实现的GDN在特定场景下达到了超越FlashInfer的性能。个人认为在这方面,DSL的意义主要体现在以下几点:
- 学术Idea的快速验证,即用少量的开发成本换取80%-90%的性能,对于学术界,尤其是各种魔改Attention的工作来说,这是个很不错的工具。
- 同时还能作为数据流的建模参考,放在
examples里大家也更好阅读学习。
- 此外,TileLang的编译栈可以生成源代码级的产物(例如CUDA后端的
.cu文件,作为对比,Triton是直接将MLIR下沉到PTX)。因此也可以想象利用DSL打好模板,生成源码后再交由专家进行极致优化的场景。
- 对于未来的Agent,DSL会不会比源码更好读?这点暂时还无法确认。目前AI写CUDA的水平已经很高了,主要还是因为语料充足,像TileLang这类自制语言的语料就太少了。不过,目前基于SKILL来写不复杂的kernel,体验上已经不错了,对比zero-shot写CUDA甚至体验会略好一些。如果能收集到充足的语料,TileLang提供的抽象可以让AI只关心数据流,不用学习复杂的Layout怎么写,从理论上讲,这还是很有利于Agent的。
TileLang 的设计精髓
探讨完关于DSL的一些思考,这一小节我简单分享一下我个人对TileLang设计亮点的理解。相较于Triton,TileLang给人的第一印象可能是显式地暴露了内存层级(L0、L1、L2)。不过,个人认为TileLang最精妙的部分还在于Fragment和Parallel这两个抽象。
Fragment是对同一个block中所有线程的寄存器集合所构成的抽象。写过CUDA的同学都知道,CUDA的SIMT编程模型分为block、warp、thread等多个层级。对于一个并行计算任务,我们通常需要在这些层级上层层拆分。将任务拆分到不同的block上通常比较简单,但将任务映射到warp、线程,这一问题就变得复杂得多,尤其是当MMA这类带有严格Layout要求的指令出现时。
TileLang的思路就是利用Fragment抽象,让用户将一个block内的任务当作一个整体来考虑,而Fragment的具体实现——即逻辑上的A[i,j]具体映射到哪个物理寄存器——则交由编译器自动推导。同时,与之相伴的是引入了在Fragment上的迭代,也就是Parallel抽象。
它背后自然对应着不同的线程,对于A[i,j]这样的访问,实际上就是对应线程对自己本地寄存器的访问。与Triton通常使用的Tile-Level的micro-op(tl.op)相比,拥有Fragment与Parallel加持的TileLang,支持更细粒度、精确到element-wise(A[i, j])的操作逻辑。 这样用户编程时的体感就是这样的:
# 节选自:https://github.com/tile-ai/tilelang-puzzles/blob/main/ans/06-softmax.py
# online softmax 实现的片段
log2_e = 1.44269504
A_local = T.alloc_fragment((BLOCK_N, BLOCK_M), dtype)
cur_max_A = T.alloc_fragment([BLOCK_N], dtype)
cur_exp_A = T.alloc_fragment([BLOCK_N, BLOCK_M], dtype)
for i, j in T.Parallel(BLOCK_N, BLOCK_M):
cur_exp_A[i, j] = T.exp2(A_local[i, j] * log2_e - cur_max_A[i] * log2_e)
对寄存器做了这种抽象后,我们发现原来的多层编程模型拥有了一种优美的一致性——所有东西都是Tile。Shared memory、registers不过是不同内存层级的Tile,我们只需要关心不同层级间的Tile搬运以及Tile上的计算。
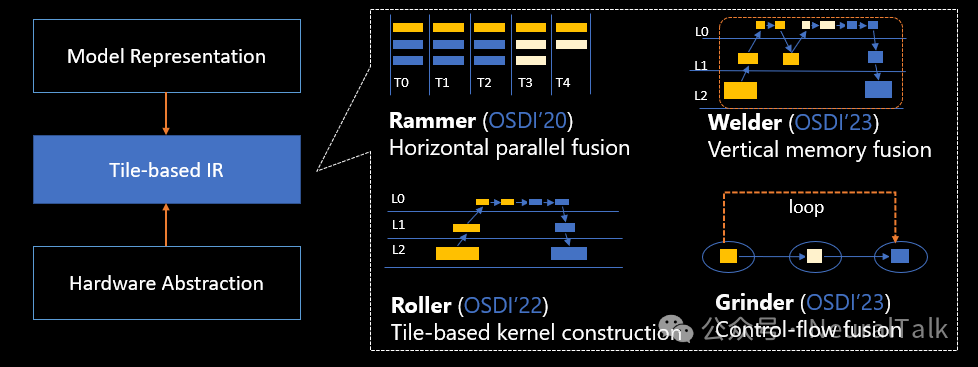
这种抽象,个人感觉是MSRA的深度学习编译器四部曲[3]长期积累总结而来,最终在TileLang中呈现出的精华形态。不过限于篇幅,笔者只能浅谈辄止,感兴趣的读者可以前往阅读TileLang在ICLR'26上的文章[4]细细品味。
V4 设计报告里的几个点
最后带大家读一下V4报告中TileLang部分的几个技术点。
首先是Host CodeGen。这部分主要是TileLang通过利用TVM-FFI[5]极大地减少了主机侧的开销,包括kernel launch、一些Tensor的检查等。做法是把这部分开销从Python侧移到C++侧,作为kernel的host侧逻辑一起被编译进去。实际收益非常明显,同时也要感谢强大的TVM社区打造出TVM-FFI这样的高质量基础设施。
第二点是Z3 Prover的集成。之前TileLang使用的代数系统是TVM自带的一套arith,这套系统的证明能力比较弱,有许多简单的条件它都无法证出。你可能会问,为什么编译器里需要这种证明工具?这是因为Tensor Program本身就包含大量index计算,最简单的需求比如边界判断:
if i < N:
A_local[i] = 1 # Buffer write guarded by condition
TileLang会帮你自动插入这类边界判断的if语句。不过,如果程序的上下文信息能够“证明”这个i绝不会越界,即i < N恒真,那就可以不插入这个if。这里就需要用到Prover来处理这类问题。当然,还有更多例子,例如向量化等。这些问题本质上都能被转化为整数表达式的证明。集成完Z3之后,我们也悲剧地发现bug更多了——因为原来并非没有bug,而是证明器太弱导致了采用了相对保守的策略。
第三点是精度与bitwise对齐方面。这方面,包括后续许多算子的batch invariant性质,对像RL这类高精度需求的场景来说至关重要,这也正是只有将编译器投入真实的工业界使用中才会发现的问题。TileLang在这方面做了很多细致的工作来保证精度,包括默认关闭fast-math、采用IEEE的intrin,同时与NVCC这类主流编译器对齐代数变换的逻辑。这里面有很多“规则怪谈”,例如NVCC会进行各种神秘的fma fuse,导致一些看起来完全相等的表达式,结果却并不bit-identical。
总结一下
TileLang在V4基础设施中扮演了非常重要的角色,也作为一个范例引发我们思考:在这样的时代背景下,DSL究竟需要扮演一个什么样的角色。总之,非常欢迎大家试用和学习:云栈社区 为你提供了丰富的技术文档支持,目前官方文档[6]、TileLang-Puzzles[7]、TileOPs[8]以及XPUOJ[9]都提供了海量的资料、实例以及评测方法。相信你也能体会到其中的精妙之处!
读者评论

参考资料
- TileLang 仅用 80 行 Python 代码就实现了 FlashMLA 95%的性能: https://zhuanlan.zhihu.com/p/27965825936
- FlashQLA: https://github.com/QwenLM/FlashQLA
- MSRA 的深度学习编译器四部曲: https://www.microsoft.com/en-us/research/articles/ai-compilor/
- TileLang 在 ICLR'26 的文章: https://openreview.net/pdf?id=Jb1WkNSfUB
- TVM-FFI: https://github.com/apache/tvm-ffi/
- 官方文档: https://tilelang.com/deeplearning_operators/gemv.html
- TileLang-Puzzles: https://github.com/tile-ai/tilelang-puzzles/
- TileOPs: https://github.com/tile-ai/TileOPs
- XPUOJ: https://xpuoj.com/
 发表于 2026-5-13 18:54:01
|
查看: 157|
回复: 0
发表于 2026-5-13 18:54:01
|
查看: 157|
回复: 0
