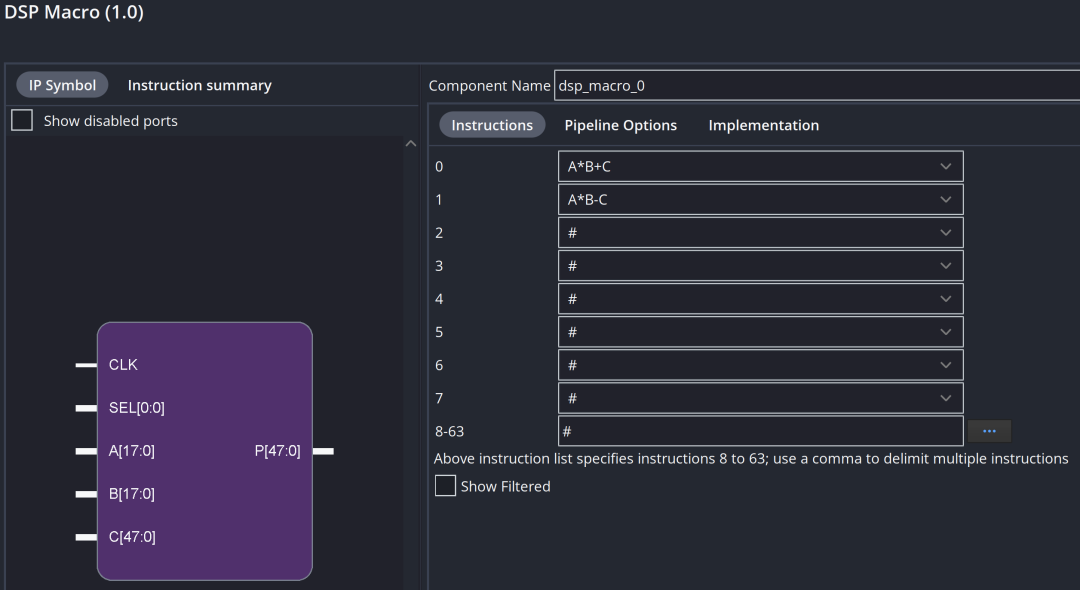
在众多算法实现中,乘法运算、乘加运算及乘累加运算广泛应用。使用RTL代码实现这些基础运算是个不错的选择。若进一步优化代码,例如增加参数化位宽设置,能显著提升代码的可移植性和复用性。同时,为确保代码能高效映射到FPGA内部的乘加器(如DSP48),需遵循特定的编码规范。此外,即使遵循规范,也可能面临期望使用级联端口而综合后未实现的情况。这时,DSP Macro IP核便能派上用场。
以AB+C和AB-C为例,在下图界面中,0~7的序号用于填写计算指令,指令个数决定了端口SEL的位宽,从而可利用单个DSP48实现动态功能切换。需注意,这并不代表该模块仅消耗DSP48资源;计算指令间的差异可能导致额外消耗Fabric中的LUT和FF。
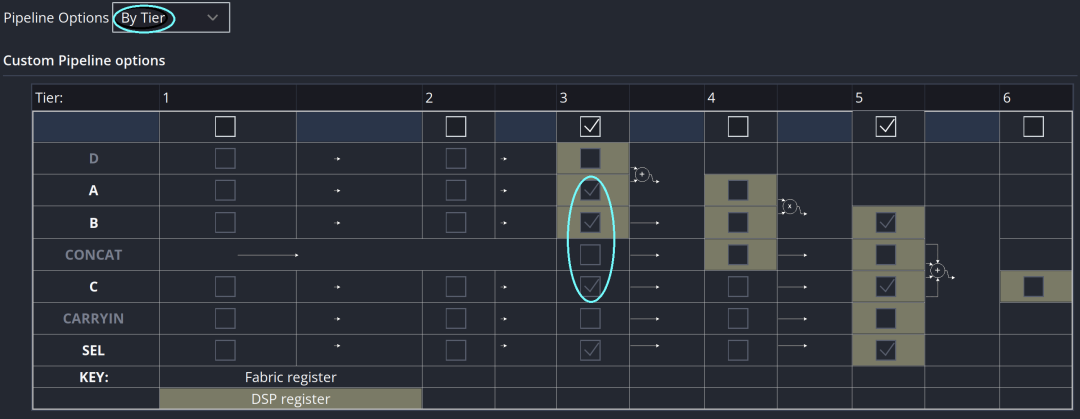
使用DSP Macro时,设置流水寄存器是关键环节。提供三种方式:By Tier、Expert和Automatic。以By Tier方式为例,用户只需在1~6对应方框中勾选,例如勾选第3级流水,则A/B/C端口对应的寄存器会被选中——这些寄存器部分位于DSP48内部,部分在外部,但均能确保数据对齐。
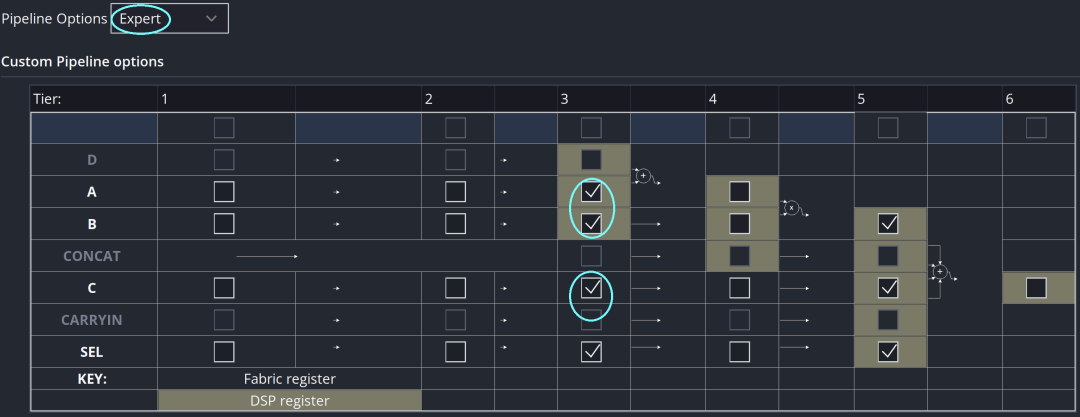
Expert模式允许用户分别指定每个数据通道的寄存器,如下图所示。可独立勾选A/B/C端口对应的流水寄存器,各数据通道间的延迟差由用户自行控制。
DSP Macro的另一优势是明确展示进位输入/进位输出端口。前者在填写计算指令时显现,后者在Additional Ports栏目下呈现,从而清晰支持级联操作。级联操作带来两大益处:专用级联线延迟更小,利于时序收敛;同时减小寄生电容,有助于降低功耗。
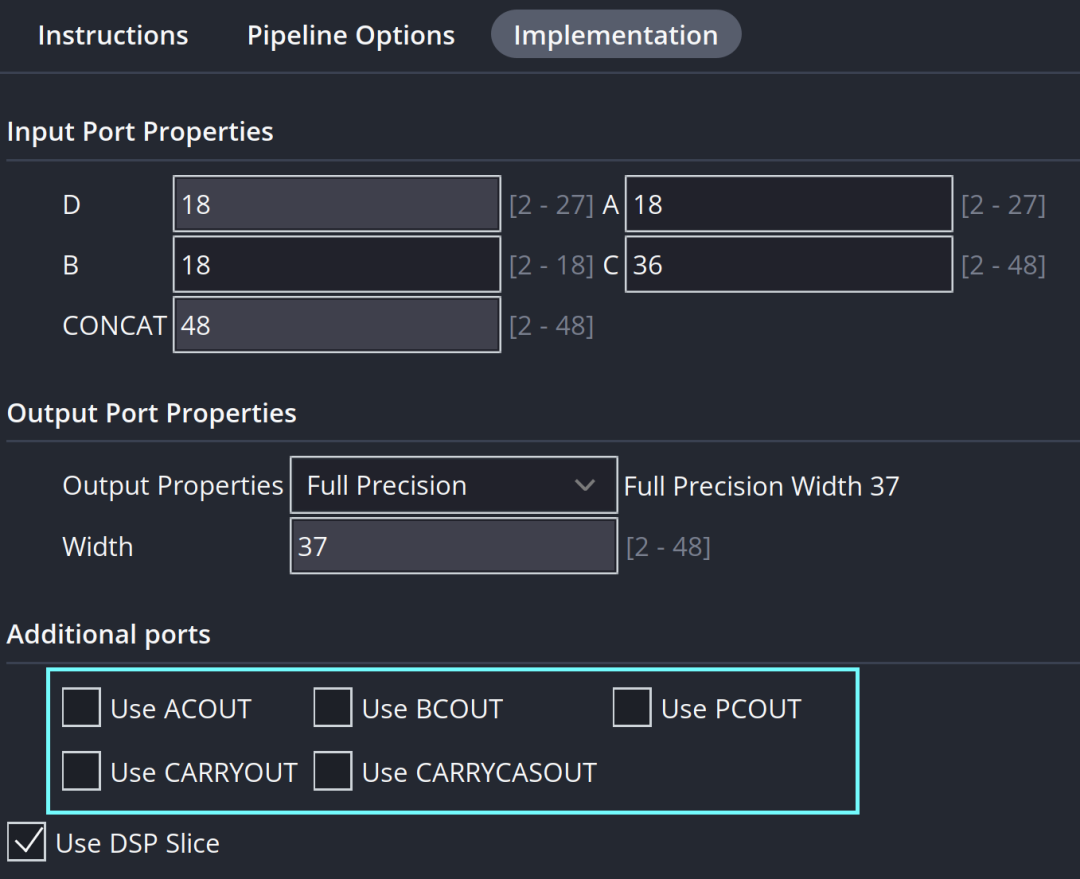
综上,在实际工程中,应依据算法特性,利用DSP Macro启用级联端口,充分发挥级联线带来的时序与能效优势。 |  发表于 2025-12-13 04:49:21
|
查看: 251|
回复: 0
发表于 2025-12-13 04:49:21
|
查看: 251|
回复: 0
