在网络通信的七层模型中,数据链路层扮演着“街区邮递员”的角色。它不关心跨城市的复杂路由(那是网络层的职责),只专注于在同一个物理或逻辑网段内,将数据帧准确投递到正确的“门牌号”——即MAC地址。Linux作为现代操作系统的网络多面手,其实现二层转发的机制,既凝聚了经典网络理论的精髓,也展现了独特的工程智慧。本文将深入内核,剖析数据包如何跨越这座“网络之桥”。
第一章:核心概念全景
1.1 什么是二层转发?
设想一栋办公大楼,每个房间都有唯一的房号(MAC地址)。当A房间需要送一份文件给B房间时,会出现两种场景:
- 场景一:B房间在同一楼层(同一广播域)。A直接走到B门口交付文件——这个过程就是二层转发。
- 场景二:B房间在另一栋大楼。A需要先将文件交给大楼的收发室(网关),由收发室负责外部投递——这个过程就是三层路由。
用技术语言描述:
- 二层转发:基于MAC地址,在数据链路层(OSI第二层)进行帧转发的行为。
- 工作范围:同一IP子网内(即同一广播域)。
- 决策依据:MAC地址表(也称为转发表)。
- 典型设备:交换机、网桥,以及支持桥接功能的Linux主机。
1.2 关键概念详解
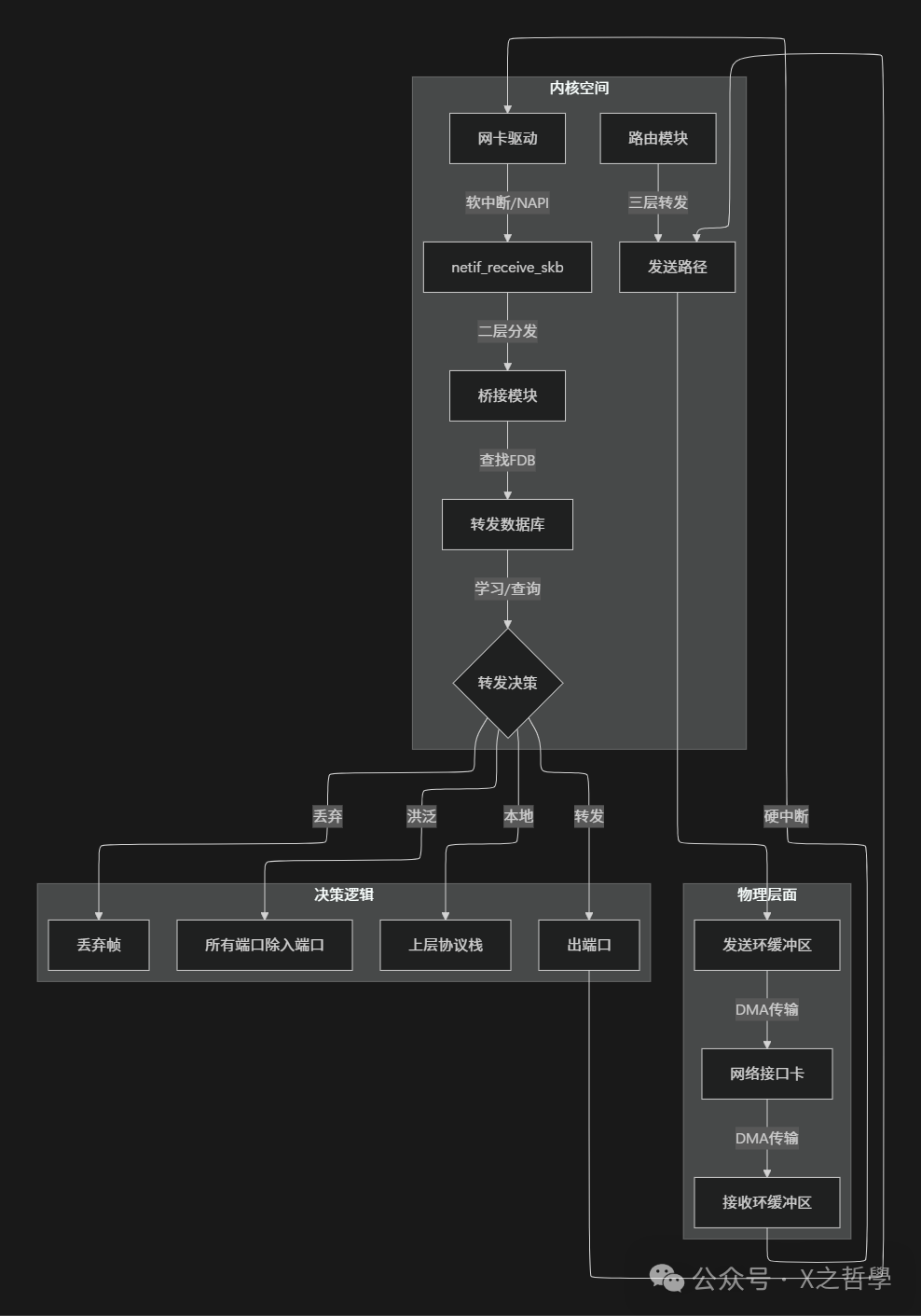
表1:二层转发与三层路由核心对比
| 维度 |
二层转发 |
三层路由 |
| 工作层 |
数据链路层(L2) |
网络层(L3) |
| 寻址依据 |
MAC地址(硬件地址) |
IP地址(逻辑地址) |
| 寻址范围 |
同一广播域(子网内) |
跨广播域(子网间) |
| 设备角色 |
透明(设备不修改帧) |
参与(设备修改IP包头) |
| 表项学习 |
自动学习(观察源MAC) |
手动配置或动态路由协议 |
| 协议示例 |
ARP、STP、Ethernet |
IP、ICMP、OSPF、BGP |
| Linux模块 |
bridge, macvlan, veth |
ip_tables, ip_forward, 路由表 |
第二章:内核架构深度剖析
2.1 核心数据结构
2.1.1 sk_buff:数据包的万能容器
// 简化的sk_buff结构(基于Linux 5.x内核)
struct sk_buff {
union {
struct {
/* 这两个指针定义了数据区的边界 */
unsigned char *head; /* 分配的内存起始 */
unsigned char *data; /* 当前数据起始 */
unsigned char *tail; /* 当前数据结束 */
unsigned char *end; /* 分配的内存结束 */
};
struct rb_node rbnode; /* 用于某些队列的红黑树节点 */
};
struct sock *sk; /* 所属socket(可为NULL) */
unsigned int len; /* 数据总长度 */
unsigned int data_len; /* 分片数据长度 */
__u16 mac_header; /* MAC头偏移 */
__u16 network_header; /* 网络头偏移 */
__u16 transport_header; /* 传输层头偏移 */
/* 重要:设备相关信息 */
struct net_device *dev; /* 接收/发送的设备 */
struct net_device *input_dev; /* 实际输入设备 */
/* 二层转发关键字段 */
unsigned char *mac_header; /* MAC头指针(与偏移量重复但方便) */
__be16 protocol; /* 从驱动来的协议(ETH_P_IP等) */
/* 桥接相关 */
struct net_bridge_port *br_port; /* 如果从桥端口进入 */
/* 控制缓冲区 - 存储私有数据 */
char cb[48] __aligned(8);
/* 引用计数 */
refcount_t users;
};
可以将sk_buff理解为一个物流公司的标准化货箱:
head和end标定了货箱的物理边界。data和tail指示了箱内当前有效货物的位置。- 各层头部指针(如
mac_header)就像是贴在货箱不同位置的标签,标识着各段信息。
dev字段则记录了这个货箱当前正位于哪辆“卡车”(网络接口)上。
2.1.2 net_device:网络接口的身份证
struct net_device {
char name[IFNAMSIZ]; /* 接口名:eth0, br0等 */
unsigned long mem_end; /* 共享内存结束 */
unsigned long mem_start; /* 共享内存开始 */
unsigned long base_addr; /* I/O基地址 */
/* 操作函数集 */
const struct net_device_ops *netdev_ops;
const struct ethtool_ops *ethtool_ops;
/* 硬件地址 */
unsigned char addr_len; /* 硬件地址长度 */
unsigned char perm_addr[MAX_ADDR_LEN]; /* 永久硬件地址 */
unsigned char addr_assign_type; /* 地址分配类型 */
/* 设备统计 */
struct net_device_stats stats;
/* 重要:设备所属命名空间和链表 */
struct net *nd_net; /* 网络命名空间 */
/* 桥接相关 */
struct net_bridge_port *br_port; /* 如果此设备是桥端口 */
/* 特性标志 */
unsigned int flags; /* 设备标志 */
/* MTU相关 */
unsigned int mtu; /* 最大传输单元 */
/* 队列规则 */
struct Qdisc *qdisc;
};
net_device就像是司机的驾驶证,它完整描述了“车辆”(网络接口)的详细信息:车辆本身的数据(名称、地址)、驾驶规则(操作函数集)、行驶记录(统计信息)。如果这辆车挂靠在某个物流中心(网桥),那么br_port字段就记录了对应的连接信息。理解这些基础数据结构是掌握 Linux 网络协议栈 运作的关键。
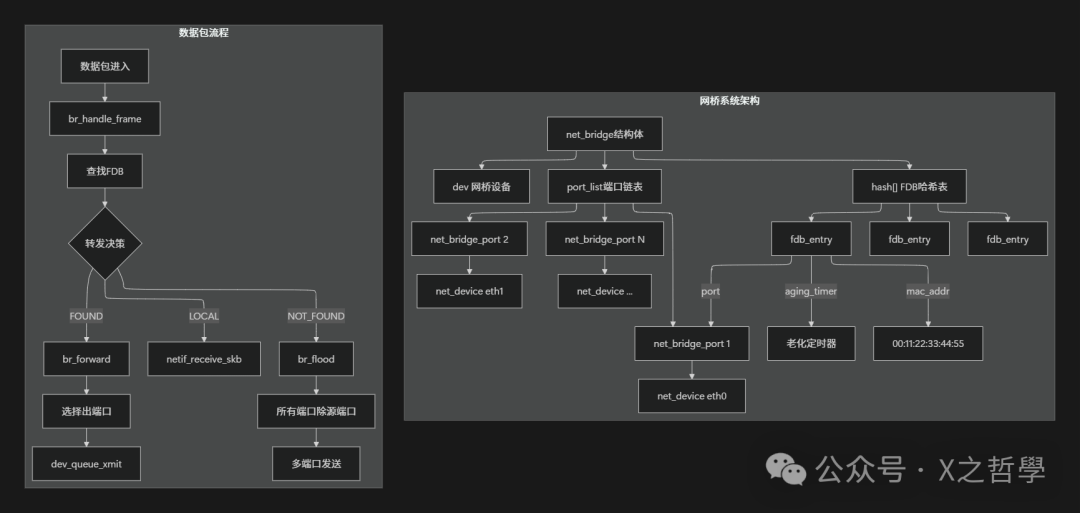
2.2 桥接核心:net_bridge 与 net_bridge_port
/* 网桥端口结构 */
struct net_bridge_port {
struct net_bridge *br; /* 所属网桥 */
struct net_device *dev; /* 关联的网络设备 */
/* 端口状态(STP相关) */
u8 state; /* 端口状态 */
u16 port_no; /* 端口号 */
/* 转发数据库(FDB)相关 */
struct hlist_head fdb_head; /* 此端口学到的MAC表项 */
/* 统计 */
struct bridge_port_stats statistics;
/* 定时器 */
struct timer_list forward_delay_timer;
struct timer_list hold_timer;
};
/* 网桥结构 */
struct net_bridge {
spinlock_t lock; /* 网桥锁 */
struct list_head port_list; /* 端口链表 */
/* 转发数据库(核心!) */
struct hlist_head hash[BR_HASH_SIZE]; /* MAC地址哈希表 */
struct list_head fdb_list; /* FDB项链表 */
/* 网桥设备 */
struct net_device *dev; /* 对应的net_device */
/* STP相关 */
bridge_id designated_root; /* 指定根桥 */
u32 root_path_cost; /* 到根路径开销 */
/* 老化时间 */
unsigned long ageing_time; /* MAC表项老化时间 */
unsigned long fdb_timeout; /* FDB超时时间 */
};
第三章:一帧的完整旅程
3.1 接收路径:从网卡到桥模块
跟踪一个以太网帧的生命周期,它从网卡进入内核后的关键一站:
// 简化的接收路径(netif_receive_skb -> 桥处理)
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
// ... 省略其他处理 ...
// 重要:检查数据包是否从桥端口进入
if (skb->dev->rx_handler && skb->dev->rx_handler_data) {
struct net_bridge_port *br_port;
br_port = rcu_dereference(skb->dev->rx_handler_data);
if (br_port) {
// 交给桥模块处理
return br_handle_frame(br_port, skb);
}
}
// 否则,走正常协议栈处理
// ...
}
3.2 核心决策逻辑:br_handle_frame
// 桥接处理入口(简化版)
rx_handler_result_t br_handle_frame(struct sk_bridge_port *p, struct sk_buff *skb)
{
// 1. STP检查:如果端口被STP阻塞,丢弃帧
if (p->state == BR_STATE_BLOCKING)
goto drop;
// 2. 更新源MAC学习
if (!is_broadcast_ether_addr(eth_hdr(skb)->h_source) &&
!is_multicast_ether_addr(eth_hdr(skb)->h_source)) {
// 关键:学习源MAC地址
br_fdb_update(p->br, p, eth_hdr(skb)->h_source, 0);
}
// 3. 检查目的MAC
if (is_broadcast_ether_addr(dest)) {
// 广播:除入端口外所有端口洪泛
br_flood(p->br, skb, BR_FLOOD_BROADCAST, false);
return RX_HANDLER_CONSUMED;
}
if (is_multicast_ether_addr(dest)) {
// 组播:根据IGMP snooping等决定
if (br_multicast_rcv(p->br, p, skb))
goto drop;
br_flood(p->br, skb, BR_FLOOD_MCAST, false);
return RX_HANDLER_CONSUMED;
}
// 4. 单播:查找FDB
fdb = br_fdb_find(p->br, dest, 0);
if (!fdb) {
// 未知单播:洪泛
br_flood(p->br, skb, BR_FLOOD_UNICAST, false);
return RX_HANDLER_CONSUMED;
}
// 5. 找到表项,根据端口决定
if (fdb->dst == p) {
// 目的端口与源端口相同:过滤(避免环路)
goto drop;
}
// 6. 转发到特定端口
br_forward(fdb->dst, skb);
return RX_HANDLER_CONSUMED;
drop:
kfree_skb(skb);
return RX_HANDLER_CONSUMED;
}
3.3 转发数据库(FDB):二层转发的“大脑”
FDB(Forwarding Database)是决策的核心,其工作原理类似邮局的邮政编码簿。
struct net_bridge_fdb_entry {
struct hlist_node hlist; /* 哈希链表节点 */
struct net_bridge_port *dst; /* 目的端口 */
mac_addr addr; /* MAC地址 */
unsigned long updated; /* 最后更新时间 */
unsigned long used; /* 最后使用时间 */
u16 vid; /* VLAN ID */
u8 is_local:1, /* 是否是本地MAC */
is_static:1; /* 是否是静态表项 */
/* 引用计数 */
refcount_t rcu_head;
};
/* 关键:FDB查找函数 */
struct net_bridge_fdb_entry *br_fdb_find(struct net_bridge *br,
const unsigned char *addr,
__u16 vid)
{
struct net_bridge_fdb_entry *fdb;
// 计算哈希值
int hash = br_mac_hash(addr, vid);
// 遍历哈希桶
hlist_for_each_entry_rcu(fdb, &br->hash[hash], hlist) {
if (ether_addr_equal(fdb->addr.addr, addr) && fdb->vid == vid) {
// 找到匹配项,更新最后使用时间
fdb->used = jiffies;
return fdb;
}
}
return NULL; /* 未找到 */
}
/* FDB学习/更新:自动学习的核心 */
void br_fdb_update(struct net_bridge *br, struct net_bridge_port *source,
const unsigned char *addr, u16 vid)
{
struct net_bridge_fdb_entry *fdb;
// 查找现有表项
fdb = br_fdb_find(br, addr, vid);
if (!fdb) {
// 新MAC地址:创建表项
fdb = fdb_create(br, source, addr, vid);
if (!fdb)
return;
} else {
// 已有表项:更新端口和计时器
if (fdb->dst != source) {
fdb->dst = source;
fdb->updated = jiffies;
}
}
// 重置老化计时器
mod_timer(&fdb->timer, jiffies + br->ageing_time);
}
表2:FDB表项类型与特性
| 类型 |
学习方式 |
老化时间 |
典型用途 |
示例 |
| 动态表项 |
自动学习(观察源MAC) |
300秒(默认) |
普通主机通信 |
00:11:22:33:44:55 dev eth0 |
| 静态表项 |
手动配置 |
永不过期 |
安全要求/特殊设备 |
bridge fdb add ... permanent |
| 本地表项 |
自动生成(接口MAC) |
永不过期 |
桥自身接口 |
网桥自身的MAC地址 |
第四章:关键技术实现细节
4.1 多端口转发:洪泛与选择性转发
/* 洪泛实现:向多个端口发送 */
void br_flood(struct net_bridge *br, struct sk_buff *skb,
enum br_pkt_type pkt_type, bool do_flood)
{
struct net_bridge_port *p;
struct sk_buff *skb2;
// 遍历所有端口
list_for_each_entry_rcu(p, &br->port_list, list) {
// 不向接收端口回送(避免环路)
if (p->state == BR_STATE_FORWARDING &&
p != skb->dev->br_port) {
// 复制skb(每个端口需要独立的副本)
skb2 = skb_clone(skb, GFP_ATOMIC);
if (!skb2)
continue;
// 设置输出设备
skb2->dev = p->dev;
// 发送到端口
br_forward_port(p, skb2);
}
}
// 释放原始skb
kfree_skb(skb);
}
/* 单端口转发 */
static void br_forward(struct net_bridge_port *to, struct sk_buff *skb)
{
// 检查端口状态
if (to->state != BR_STATE_FORWARDING)
goto drop;
// 设置输出设备
skb->dev = to->dev;
// 发送
dev_queue_xmit(skb);
return;
drop:
kfree_skb(skb);
}
4.2 VLAN处理:虚拟隔离的关键
/* VLAN过滤检查 */
bool br_allowed_ingress(struct net_bridge *br, struct net_bridge_port *p,
struct sk_buff *skb, u16 *vid)
{
__be16 proto;
// 检查是否有VLAN标签
if (!br_vlan_get_tag(skb, vid)) {
// 有VLAN标签
if (!br_vlan_filtering_enabled(br))
return true;
// 检查端口是否允许该VLAN
return br_vlan_find(p->vlan_info, *vid) != NULL;
} else {
// 无VLAN标签:使用PVID(端口默认VLAN)
*vid = p->pvid;
return p->pvid != 0;
}
}
/* VLAN转发决策 */
static void br_handle_vlan(struct net_bridge_port *p, struct sk_buff *skb, u16 vid)
{
struct net_bridge_fdb_entry *dst;
unsigned char *dest = eth_hdr(skb)->h_dest;
// 在指定VLAN内查找FDB
dst = br_fdb_find(p->br, dest, vid);
if (!dst) {
// VLAN内洪泛
br_flood_vlan(p->br, skb, vid);
} else {
// VLAN内单播转发
br_forward(dst->dst, skb);
}
}
第五章:动手实践:构建Linux网桥
5.1 环境准备与网桥创建
#!/bin/bash
# 创建网络命名空间(模拟多个主机)
ip netns add ns1
ip netns add ns2
ip netns add ns3
# 创建veth对(虚拟以太网线缆)
ip link add veth1 type veth peer name br-veth1
ip link add veth2 type veth peer name br-veth2
ip link add veth3 type veth peer name br-veth3
# 将一端移动到命名空间
ip link set veth1 netns ns1
ip link set veth2 netns ns2
ip link set veth3 netns ns3
# 在命名空间内配置IP
ip netns exec ns1 ip addr add 192.168.1.10/24 dev veth1
ip netns exec ns2 ip addr add 192.168.1.20/24 dev veth2
ip netns exec ns3 ip addr add 192.168.1.30/24 dev veth3
# 启动命名空间内的接口
ip netns exec ns1 ip link set veth1 up
ip netns exec ns2 ip link set veth2 up
ip netns exec ns3 ip link set veth3 up
# 在默认命名空间创建网桥
brctl addbr br0
ip link set br0 up
# 将veth另一端加入桥
brctl addif br0 br-veth1
brctl addif br0 br-veth2
brctl addif br0 br-veth3
# 启动桥端口
ip link set br-veth1 up
ip link set br-veth2 up
ip link set br-veth3 up
5.2 验证与测试
# 查看桥状态
brctl show br0
# 输出示例:
# bridge name bridge id STP enabled interfaces
# br0 8000.000000000000 no br-veth1
# br-veth2
# br-veth3
# 查看FDB(初始为空)
bridge fdb show dev br0
# 从ns1 ping ns2
ip netns exec ns1 ping 192.168.1.20 -c 3
# 再次查看FDB(已学习到MAC)
bridge fdb show dev br-veth1
# 输出示例:
# 00:11:22:33:44:55 dev br-veth1 self permanent # 本地MAC
# aa:bb:cc:dd:ee:ff dev br-veth1 vlan 1 # 学习到的ns2 MAC
5.3 数据包捕获与调试
# 在桥设备上抓包
tcpdump -i br0 -n -e
# 查看详细桥接信息
bridge -d link show
# 监控FDB变化(实时)
bridge monitor fdb
# 查看内核桥接统计
cat /sys/class/net/br0/bridge/stp_state
cat /sys/class/net/br0/bridge/ageing_time
# 修改桥参数
echo 200 > /sys/class/net/br0/bridge/ageing_time # 修改老化时间
echo 1 > /sys/class/net/br0/bridge/stp_state # 开启STP
这些命令是 Linux 运维和网络调试 中的常用技能,对于理解网络行为至关重要。
第六章:高级特性与优化
6.1 硬件卸载与eBPF加速
// eBPF程序示例:在TC层加速桥接
SEC("tc")
int handle_ingress(struct __sk_buff *skb)
{
void *data_end = (void *)(long)skb->data_end;
void *data = (void *)(long)skb->data;
struct ethhdr *eth = data;
// 边界检查
if (data + sizeof(*eth) > data_end)
return TC_ACT_OK;
// 快速路径:检查是否是本地流量
if (is_local_mac(eth->h_dest)) {
// 重定向到上层协议栈
bpf_skb_under_cgroup(skb, &cgrp, 0);
return TC_ACT_OK;
}
// 查找FDB(使用BPF映射作为快速缓存)
struct fdb_key key = { .mac = eth->h_dest };
struct fdb_value *port = bpf_map_lookup_elem(&fdb_map, &key);
if (port) {
// 找到:直接重定向到端口
bpf_redirect(port->ifindex, 0);
return TC_ACT_REDIRECT;
}
// 未找到:交给内核慢路径
return TC_ACT_OK;
}
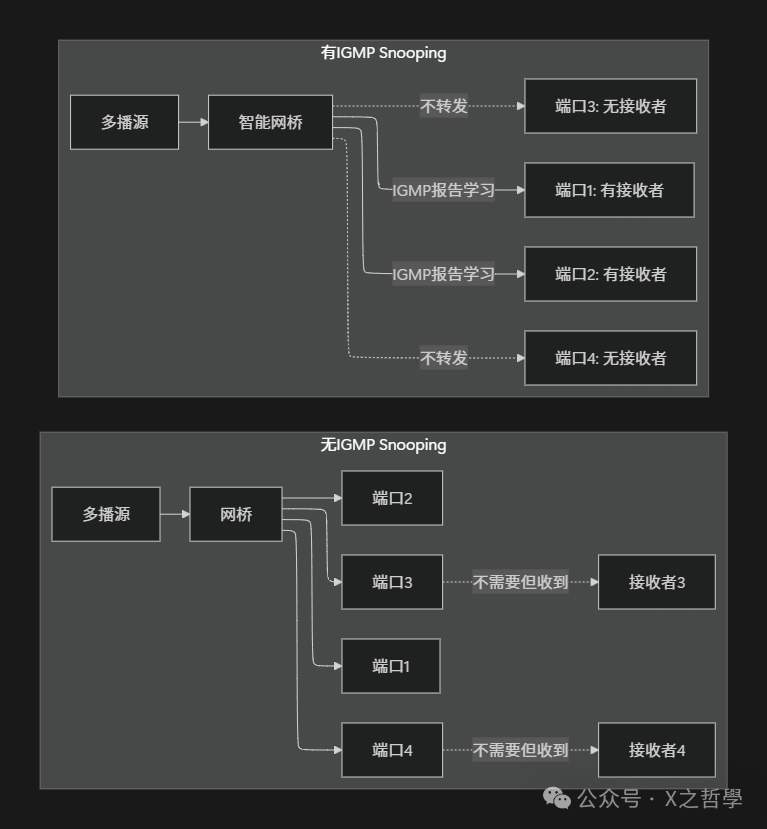
6.2 多播优化:IGMP Snooping
第七章:故障排查工具箱
表3:Linux二层转发调试工具集
| 工具类别 |
命令/工具 |
用途 |
示例 |
| 基础查看 |
ip link, bridge, brctl |
查看桥接配置 |
bridge link show |
| FDB操作 |
bridge fdb |
MAC地址表管理 |
bridge fdb add dev eth0 00:11:22:33:44:55 |
| 数据包分析 |
tcpdump, wireshark |
抓包分析 |
tcpdump -i br0 -e -n |
| 性能监控 |
ethtool -S, bpftool |
统计与性能 |
ethtool -S br0 |
| 内核调试 |
dropwatch, perf |
丢包分析 |
dropwatch -l kas |
| 流量控制 |
tc, iproute2 |
QoS与策略 |
tc qdisc add dev br0 root handle 1: htb |
| 系统状态 |
/sys/class/net/* |
sysfs信息 |
cat /sys/class/net/br0/bridge/stp_state |
| 网络命名空间 |
ip netns, nsenter |
命名空间操作 |
ip netns exec ns1 ip addr |
7.1 常见问题排查流程
# 1. 检查桥接基本状态
bridge link show 2>/dev/null || brctl show
# 2. 检查FDB表
bridge fdb show
# 3. 检查STP状态(如果启用)
bridge -d link show | grep -A2 "state"
# 4. 检查接口统计(丢包等)
ip -s link show br0
# 5. 实时监控
# 终端1:监控FDB变化
bridge monitor fdb
# 终端2:监控链路变化
bridge monitor link
# 终端3:抓包分析
tcpdump -i br0 -e -n -v
# 6. 内核跟踪(需要debugfs)
echo 1 > /sys/kernel/debug/tracing/events/net/netif_rx/enable
cat /sys/kernel/debug/tracing/trace_pipe
第八章:设计思想与演进
8.1 Linux桥接的设计哲学
- 透明性:桥接对终端设备完全透明,无需额外配置。
- 自学习:自动构建转发表,极大减少人工维护成本。
- 无环路设计:通过生成树协议(STP)防止广播风暴。
- 软硬件分离:驱动层与协议栈层清晰划分,易于维护和扩展。
- 可扩展性:通过Netfilter钩子等机制支持丰富的过滤和策略功能。
8.2 与现代网络的融合

在云原生和虚拟化时代,Linux桥接从物理网络延伸至虚拟网络,成为 容器和云原生网络方案(如Docker bridge、Kubernetes网络插件)的底层基石,其核心思想历久弥新。
总结
经过深度探索,我们可以看到Linux二层转发是一个优雅而复杂的系统,完美体现了Unix设计哲学:
- 模块化设计:FDB、端口管理、STP等组件各司其职。
- 清晰的抽象层次:从硬件驱动到协议栈,自底向上的抽象非常清晰。
- 软硬件协同:在保证功能灵活性的基础上,通过TC、eBPF等方式追求极致性能。
- 强大的可观测性:提供了从命令行工具到sysfs的丰富调试接口。
理解Linux的桥接实现,不仅有助于我们高效地调试网络问题,更能让我们深入领悟:
- 操作系统如何抽象和管理复杂的网络资源。
- 内核空间与用户空间是如何协作完成网络任务的。
- 在虚拟化技术蓬勃发展的今天,传统网络概念如何焕发新生,继续支撑着从物理机到容器的庞大网络世界。
 发表于 2025-12-14 13:33:19
|
查看: 230|
回复: 0
发表于 2025-12-14 13:33:19
|
查看: 230|
回复: 0
