对于需要维护超大表(如更新旧数据、分批删除或数据迁移)的DBA或开发者而言,利用ctid(元组物理位置)将大表切分为多个小块处理是标准操作。然而,该操作长期存在一个显著瓶颈:严格依赖单进程执行。
随着提交0ca3b169被合并至PostgreSQL 19(master分支),这一局面得以改变——TID范围扫描(TID Range Scans)正式支持并行执行。
根据基准测试,这项新特性在特定场景下可带来高达3倍的速度提升。
一、核心痛点:规划器的艰难抉择
PostgreSQL自版本14起便支持TID Range Scans,允许基于物理块号扫描表的特定切片:
SELECT * FROM my_large_table WHERE ctid >= '(0,0)' AND ctid < '(10000,0)';
这已成为类似AWS DMS或逻辑复制初始化器等工具拆分海量表的标准方式。但问题在于,此扫描节点此前严格限定为单工作进程。
这迫使PostgreSQL查询规划器陷入两难。面对大数据集查询,规划器不得不在以下两者间权衡:
- TID范围扫描:I/O高效(仅读取请求的块),但无法利用多核。
- 并行顺序扫描:CPU高效(可占用所有CPU核心),但I/O浪费(可能读取大量无关块以进行过滤)。
规划器常会误判,选择并行顺序扫描,因为CPU收益看似能抵消I/O损耗。这直接导致数据库为利用工作进程而读取了远超必要的数据量。
二、解决方案:并行执行与智能分块策略
新提交的代码引入了允许Tid Range Scan节点参与并行查询计划的基础架构。其核心逻辑是将块范围动态分配给可用的并行工作进程,实现并发数据块获取。
该实现(约500行代码)复用了并行顺序扫描中的“块分块”逻辑,但并非简单均分。为避免数据密度不均导致的负载倾斜,它采用了衰减块大小策略:
- 大块启动:工作进程初始领取大块,以最小化共享状态锁开销。
- 逐渐缩减:随着扫描推进,分块尺寸逐步缩小。
- 细粒收官:扫描临近结束时,工作进程每次仅领取1个块。
这种“缓慢递减”机制确保了不会出现一个工作进程处理巨大尾块而其他进程空闲的情况,强制所有进程大致同时完成扫描,最大化资源利用率。
三、基准测试:性能数据验证
为验证效果,我们创建了一个包含1000万行的表bench_tid_range,并使用ctid范围条件(扫描前50%数据)运行count(*)查询。
测试查询:
SELECT count(*) FROM bench_tid_range WHERE ctid >= '(0,0)' AND ctid < '(41667,0)';
测试结果:
| 环境 |
工作进程数 |
执行时间 (中位数) |
加速比 |
| Pg 18 (之前) |
0 |
448 ms |
1.00x |
| Pg 19 (之后) |
0 |
435 ms |
1.03x |
| Pg 19 (之后) |
1 |
238 ms |
1.88x |
| Pg 19 (之后) |
2 |
174 ms |
2.58x |
| Pg 19 (之后) |
3 |
151 ms |
2.97x |
| Pg 19 (之后) |
4 |
150 ms |
2.98x |
| Pg 19 (之后) |
5 |
147 ms |
3.05x |
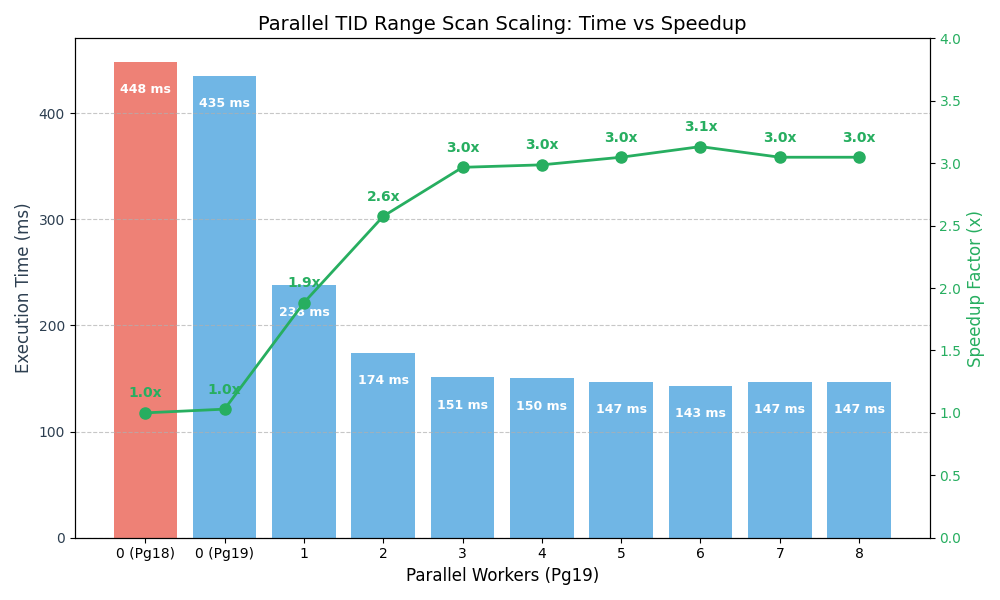
数据显示,仅启用1个工作进程(实际为Leader+1 Worker)即可大幅降低执行时间。对此工作负载,2-3个工作进程附近达到最佳平衡点。
四、对比:为何不直接使用并行顺序扫描?
或许会有疑问:在Pg 18中,为何不让规划器直接选择4工作进程的并行顺序扫描?那样不比单进程扫描半个表快吗?
我们通过设置enable_tidscan = off并强制使用4个工作进程进行测试:
- 执行时间:约230 ms。
- I/O:访问了全部约83k个页面。
而新的并行TID范围扫描(约150 ms)仍比强制的并行顺序扫描快35%,且产生的I/O负载仅为后者的一半(仅访问约41k个页面)。这真正实现了快速执行(并行化) 与高效资源利用(精准范围界定) 的兼顾。
五、对实际工具链的影响
如果您维护着在PostgreSQL实例间迁移数据的内部脚本,很可能编写过手动计算块范围、划分大表并派生多进程处理的复杂代码。
随着PostgreSQL 19的到来,这部分复杂性有望简化。您可以发出更宽泛的TID范围查询,并信赖规划器能够有效地在集群的I/O与CPU资源之间分配工作任务。
六、如何复现测试
以下是设置测试表并运行基准测试的SQL步骤:
-- 1. 创建测试表
DROP TABLE IF EXISTS bench_tid_range;
CREATE TABLE bench_tid_range (id int, payload text);
-- 2. 插入1000万行数据,生成约41k个页面
INSERT INTO bench_tid_range
SELECT x, 'payload_' || x FROM generate_series(1, 10000000) x;
-- 3. 执行VACUUM,设置可见性映射并冻结行(对稳定基准测试很重要)
VACUUM (ANALYZE, FREEZE) bench_tid_range;
-- 4. 为会话启用并行设置
SET max_parallel_workers_per_gather = 4; -- 可尝试2, 4, 8
SET min_parallel_table_scan_size = 0; -- 即使对小表也强制考虑并行扫描
-- 5. 运行查询并分析执行计划与缓冲区使用
EXPLAIN (ANALYZE, BUFFERS)
SELECT count(*)
FROM bench_tid_range
WHERE ctid >= '(0,0)' AND ctid < '(41667,0)';
七、总结
这是一项令人欣喜的底层引擎改进。它或许不会改变日常的即席查询,但对于构建自定义数据维护脚本的数据库管理员和开发者而言,并行执行基于TID的扫描无疑成为优化工具箱中一项强大而高效的新工具。
八、参考
- 核心提交 0ca3b169:查看详情
- 社区讨论帖:阅读讨论
- 技术解析博文(英文):
 发表于 2025-12-14 18:44:33
|
查看: 222|
回复: 0
发表于 2025-12-14 18:44:33
|
查看: 222|
回复: 0
