在全球人工智能领域竞争快速升温的当下,谷歌与 OpenAI 再次在同一天抛出重磅更新,令整个行业的注意力高度集中。
昨天夜里,谷歌发布了全新“重新构想”的 Gemini Deep Research 版本,并首次开放了嵌入式研究智能体 API。
而几乎同时,OpenAI 正式发布了备受期待的 GPT-5.2(代号 Garlic)。两家公司围绕智能体(Agent)未来、基础大模型能力边界以及应用生态主导权的竞争,正进入一个前所未有的焦灼阶段。这一次,双方在大模型能力上的攻防几乎精确地踩在同一时间窗口。
谷歌推出全新Deep Research Agent
谷歌推出的全新 Gemini Deep Research 工具是一款智能 Agent,能够整合海量信息并处理提示信息中大量的上下文数据。谷歌表示,客户使用 Deep Research Agent 执行的任务范围广泛,从尽职调查到药物毒性安全研究均有涉及。
谷歌还表示,很快会将这款全新的 Deep Research Agent 集成到其各项服务中,包括谷歌搜索、谷歌财经、Gemini 应用以及广受欢迎的 NotebookLM。
具体而言,Deep Research Agent 有哪些能力?
在此次更新中,Google 不仅对 Deep Research Agent 进行了架构级的再设计,还以 Gemini 3 Pro 为核心基础模型,构建了一个更加稳定、准确、可追溯的深度研究系统。新版 Deep Research Agent 的能力提升可总结为三个关键方向:模型升级、推理稳定性突破以及交互能力全面增强。
先说模型升级。新版 Deep Research Agent 完全基于 Gemini 3 Pro 构建,而 Gemini 3 Pro 被谷歌视为其迄今最“真实”、最可靠、最适合长链推理的旗舰模型版本。
为了构建这样的智能体,谷歌采用了多步强化学习(Reinforcement Learning over Multi-step Trajectories)的训练策略。其目标非常明确:在长达数十步、数百步的复杂研究任务中,AI 必须保持推理路径稳定,减少出现幻觉的概率,并确保连续决策过程中的一致性。
传统 LLM 在长链推理中的主要痛点之一,就是每一步推理都会引入累计误差——只要一个幻觉性的节点,就可能导致整个输出结果失效。谷歌强调,新版 Deep Research 在这一点上取得重大突破:
- 多轮强化学习优化决策序列
- 在冗长任务链中显著减少逻辑偏移
- 更稳定的检索—分析—推理—引用闭环
这使得 Deep Research 可以承担以往 LLM 无法胜任的任务,例如完整执行跨天级研究、政策评估、多源数据整合和全流程尽职调查。
新版 Deep Research Agent 的另一个核心优势是其超大规模上下文处理能力。在 Gemini 3 Pro 的支持下,它可以一次性处理远超以往的资料量,包括学术论文、官方报告、长篇网页内容等,更重要的是,谷歌为 Deep Research 加入了一项“研究级标准能力”:它会为每一条观点、每一个结论自动附上可追溯引用来源。引用不仅是网址链接,而是结构化地指向原文中的关键片段或段落,以确保输出可信、观点可查。
此次版本更新还包括两项关键新能力:开源全新网络研究智能体基准:DeepSearchQA 和全新交互 API。
在当前行业中,网络研究型智能体缺乏统一衡量标准。为了证明谷歌取得的进展,谷歌创建了一个新的基准测试。这个新基准测试名为 DeepSearchQA,旨在测试智能体在复杂的多步骤信息检索任务中的表现。谷歌已将该基准测试开源。
DeepSearchQA 开源地址:https://www.kaggle.com/benchmarks/google/dsqa/leaderboard
DeepSearchQA 包含 17 个领域共 900 道精心设计的“因果链”任务,每一步都依赖于先前的分析。与传统的基于事实的测试不同,DeepSearchQA 衡量的是全面性,要求智能体生成详尽的答案集。这既评估了研究的精确度,也评估了检索召回率。
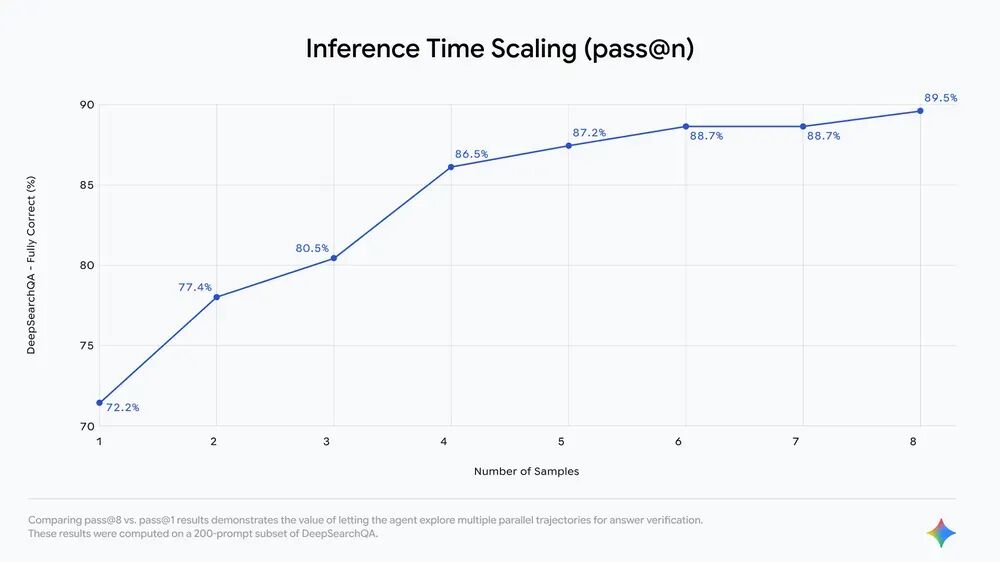
全新的 Deep Research Agent 在“人类最后的考试”(HLE)和 DeepSearchQA 测试中取得了最先进的成果,并在 BrowseComp 测试中表现最佳。它经过优化,能够以更低的成本生成高质量的研究报告。
基准测试结果如下,其基于 Gemini 3 Pro 核心构建,但采用智能体工作流程来实现最先进的性能:
- 人类的最后考试(HLE): 46.4%
- DeepSearchQA: 66.1%
- BrowseComp: 59.2%

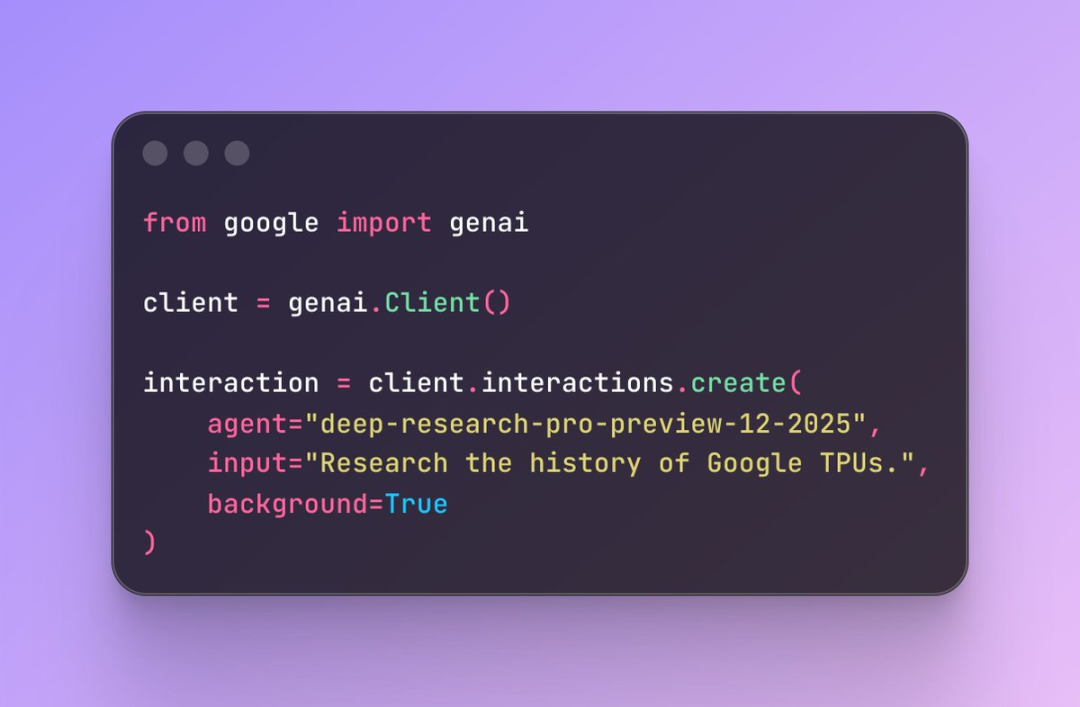
Interactions API 是谷歌此次发布的最具战略意义的能力之一。它让开发者首次能够以结构化方式控制智能体的行为状态、推理步骤、长链任务执行、中间状态存储等,这意味着以前开发者只能“向模型发问”,而现在开发者可以“调教智能体如何执行任务”,为构建复杂AI应用提供了更高阶的API支持。
技术社区反响与性能对比
在谷歌发布新版 Deep Research Agent 后,技术社区的反应同样值得关注。
在 Hacker News 与 Reddit 相关讨论帖中,不少开发者表达了对谷歌此次“真正把 Agent 做成工程化产品”的肯定。有网友指出,谷歌首次在产品层面强调“可验证引用”“端到端多步推理稳定性”,是 AI Agent 领域一次明显的进步。
但也有观点保持谨慎,一位 Reddit 用户批评道:“谷歌用自家基准证明自己最强,这种事情已经发生过太多次了。我们需要的是在真实网页、真实任务中的第三方测试。”
由于谷歌这款新 Agent 的发布时间与 OpenAI GPT-5.2 是同一天,自然难逃网友们将两者相比较的命运。为了将两者进行更清晰的对比,有网友找出了 OpenAI 研究员 Sebastien Bubeck 在领英上的发文,在这篇发文中,Sebastien Bubeck 称 GPT-5.2 在人类的最后考试(HLE)中的得分是 45%,而谷歌这款新的 Agent 的得分是 46.4%,略高于 GPT-5.2。

模型与平台能力的双重竞争
基础模型能力始终是两家公司最具标志性的竞争焦点。
2025 年初,谷歌推出的 Gemini 3 Pro 以其更“真实”、更可依赖、幻觉率更低的特性,试图在长链推理和专业任务场景中重建优势。而 OpenAI 在最新发布的 GPT-5.2(Garlic)中,强化了逻辑一致性、工具调用稳定性以及智能体行为的自主性。
两者之间的能力差距被行业评论认为“已进入毫厘级别”——差距常常只体现在特定任务场景,而不再是全局性的优势。
如果说基础模型决定了智能体能否思考,那么智能体平台能力则决定了智能体能否执行任务。
谷歌此次对 Gemini Deep Research Agent 进行全面重构,可视为其正式加入智能体战争的关键节点。新版 Deep Research Agent 具有三大亮点:
- 基于 Gemini 3 Pro 全面重写推理链路
- 采用多步强化学习训练,保持长链任务中决策一致性,显著降低幻觉概率
- 提供全链路引用,可追溯每个观点的证据来源
更关键的是,谷歌推出了结构化控制智能体行为的 Interactions API,开发者可以对智能体的每一阶段、每一子任务进行高度可控的调度与状态管理。
OpenAI 的智能体体系则更侧重通用性和自由度。Agent API、OpenAI Swarm、BrowserAgent、CodeAgent 已形成一个完整的智能体开发框架。
两者竞争的核心在于:未来软件开发将以智能体为核心,而谁掌握了智能体框架标准,谁就掌握了新一代计算范式的主导权。
 发表于 2025-12-15 00:49:19
|
查看: 237|
回复: 0
发表于 2025-12-15 00:49:19
|
查看: 237|
回复: 0
