随着大模型技术的迅猛发展,数据集作为人工智能核心三要素之一,其重要性日益凸显。在算法趋同、算力普惠的当下,高质量的数据集正成为构建差异化竞争优势的关键壁垒。高质量数据集的建设不仅是提升AI模型性能的基础,更是推动“人工智能+”行动有效落地的根本保障,标志着AI发展正步入“数据驱动”的新阶段。
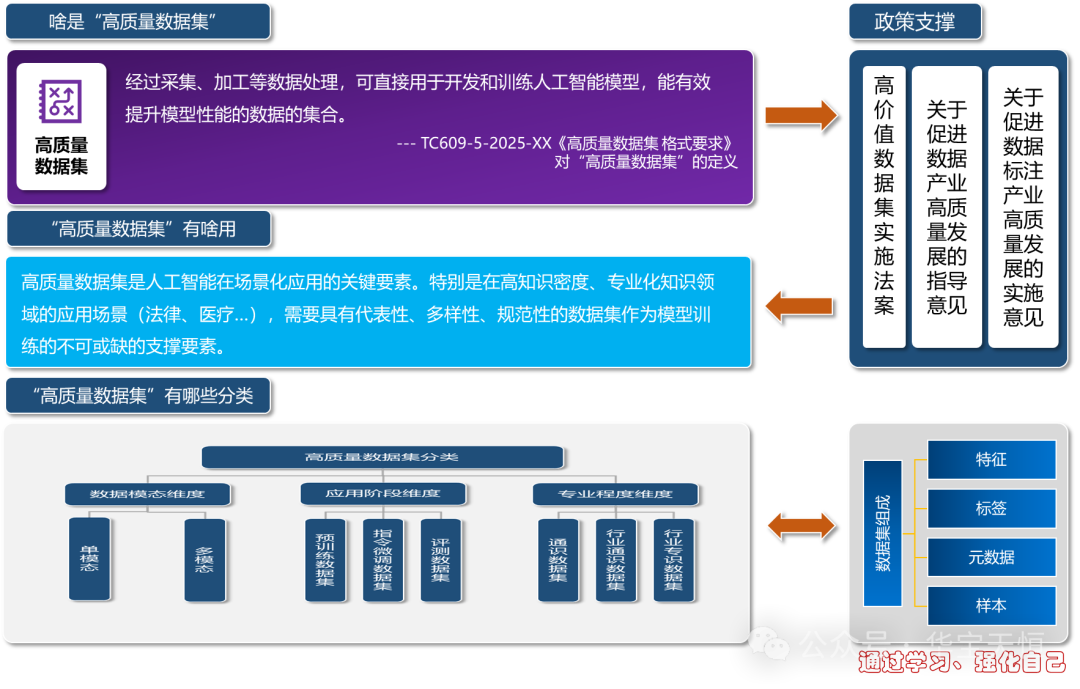
什么是高质量数据集?
高质量数据集是一个为特定机器学习任务而精心策划、清洗、标注和格式化后的数据集合。它本质上是“数据成品”或“精加工材料”,能够直接用于模型的训练、验证与测试。
其核心特征包括:
- 精准性: 数据本身及其标注(Label/Annotation)的准确率极高,错误率被控制在极低水平。
- 一致性: 整个数据集遵循完全统一的标注标准、格式与规范,避免了前后矛盾的情况。
- 相关性: 数据集中的每一个样本都与待解决的具体任务高度相关,无关或冗余数据已被有效剔除。
- 完整性: 所需的数据字段和标注信息齐全,不存在大量的缺失值。
- 平衡性与无偏性: 针对分类等任务,不同类别的样本数量相对均衡,并尽可能避免了数据引入有害的社会偏见。
- 任务导向: 数据集的结构完全围绕任务设计,例如图像分类数据集(图像+类别标签)、机器翻译数据集(源语言句+目标语言句)、问答数据集(问题+答案)等。
典型例子:
- ImageNet: 为图像分类任务构建的庞大数据集,包含超过1400万张手工标注的图像,涵盖2万多个类别。
- GLUE/SuperGLUE基准: 为评估自然语言理解模型性能而设计的系列数据集,包含情感分析、自然语言推理等多种任务。
- COCO (Common Objects in Context): 用于目标检测、分割和字幕生成的大规模数据集,每张图片都带有精确的对象边界框和分割掩码。
高质量数据集建设面临的“三大难点”
当前,高质量数据集的建设尚处于探索阶段,主要面临目标定位模糊、实施路径碎片化与技术底座薄弱三重挑战。
1. 目标定位模糊化
数据集建设常陷入“为数据而数据”的误区,智能场景的真实需求与数据工程的建设目标脱节。企业未能将数据工程的目标与核心业务指标深度绑定,导致海量数据难以转化为模型性能的有效提升。
2. 实施路径碎片化
从数据采集到模型训练的全链路缺乏系统性规划,无法形成体系化的构建与维护机制。这导致多源异构数据标准难以统一,跨部门协作困难,进而使得数据清洗、标注等环节的成本激增。
3. 技术底座薄弱化
现有数据处理技术难以应对复杂AI场景的需求,尤其是在多模态数据处理方面能力不足,制约了模型的迭代与规模化应用。同时,行业特性适配的工具链缺失,自动化程度低,严重依赖人力,导致工程落地效率低下。
如何建设高质量数据集?七大核心环节
建设高质量数据集是一项系统工程,需要企业从战略到执行的全方位投入。以下是七个环环相扣的关键环节。
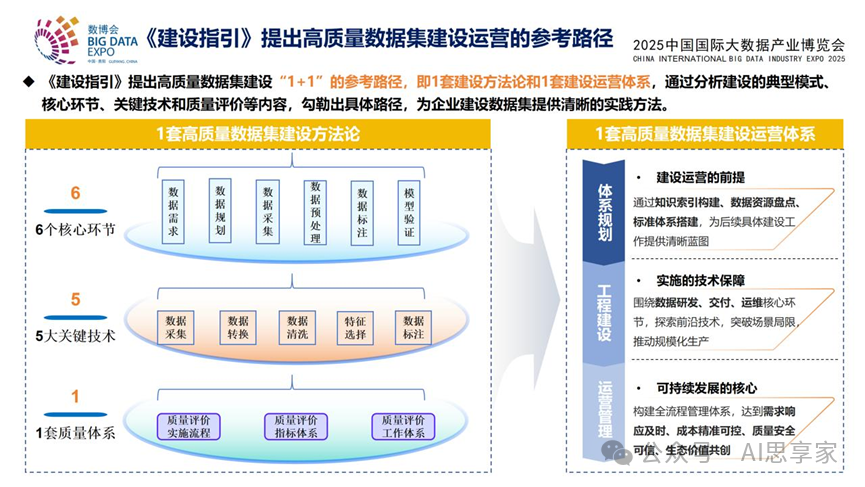
(图表来源:国家数据局官方网站)
环节一:明确业务目标,定义数据需求
数据建设绝不能无的放矢。一切数据工作的起点都必须是清晰的业务目标。 在动手收集任何数据前,必须明确:这些数据将用于解决什么具体的业务问题?支持何种决策?优化哪个流程?
关键行动: 召集业务部门与数据团队进行深度研讨,明确核心业务问题与对应的数据需求,并确定数据使用的优先级。
环节二:设计科学的数据架构
良好的数据架构是孕育高质量数据的蓝图,它决定了数据如何被组织、存储、集成和访问。传统的数据仓库与新兴的数据湖各有优劣,企业应根据自身情况选择。目前,越来越多的企业采用“湖仓一体”的混合模式,以兼顾数据处理的灵活性与管理规范性。
关键行动: 设计合理的数据分层(如原始层、清洗层、应用层),规划清晰的数据流向与集成方式,并选择适合的技术栈(如Hadoop、Spark、Flink等大数据组件)。
环节三:制定统一的数据标准
没有规矩,不成方圆。统一的数据标准是保障数据质量一致性的前提。 这包括数据命名规范、类型定义、编码规则、精度要求等。例如,确保全公司日期的格式统一为“YYYY-MM-DD”。
关键行动: 建立企业级的数据字典和元数据管理系统,制定严格的数据建模与数据库设计规范,并统一关键业务指标的计算口径。
环节四:建立数据质量监控体系
质量是测量出来的,更是监控出来的。必须建立覆盖数据全生命周期的质量监控体系。 通过设置校验规则,对数据采集、处理、加工的每一个环节进行质量检查,实现问题的及时发现与预警。
关键行动: 定义数据质量评估指标(完整性、准确性、时效性等),实施定期的数据质量探查与剖析,并建立自动化的质量告警与应急响应机制。
环节五:实施有效的数据治理
数据治理是确保数据质量的组织与制度保障。它涉及明确的组织架构、职责分工、流程制度与绩效管理。优秀的数据治理能够厘清数据责任方、管理方和使用方的权责,形成数据质量管理的闭环。
关键行动: 建立由高层驱动的数据治理委员会,明确各方的数据权责与流程制度,并将数据质量指标纳入相关部门和个人的绩效考核体系。
环节六:选择合适的技术工具
工欲善其事,必先利其器。合适的技术工具能极大提升数据建设的效率与质量。 从数据集成、开发、质量检查到数据服务,市场上有成熟的低代码平台与专业工具链可供选择。
关键行动: 客观评估企业现有的技术能力与未来需求,选择匹配的数据技术栈与工具(如ETL工具、数据质量管理平台),避免盲目追求最新技术,应选择最贴合企业现状的解决方案。
环节七:培养数据文化,持续优化
数据建设绝非一次性项目,而是一个需要持续迭代优化的过程。最核心的是在企业内部培育深入人心的数据文化。 让每位员工都认识到数据的重要性,自觉维护数据质量,主动运用数据驱动决策。
关键行动: 定期开展数据素养培训与最佳实践交流,建立数据质量的持续改进与反馈机制,并对优秀的数据实践案例进行表彰和奖励。
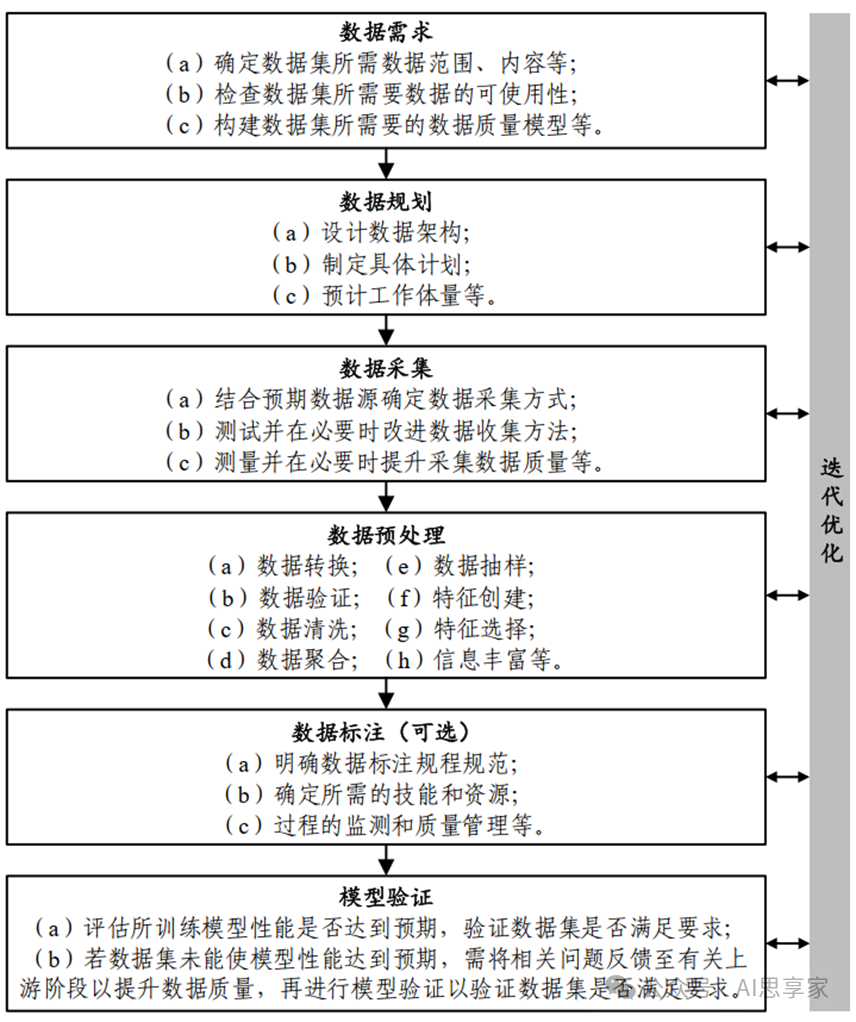
(摘录自《高质量数据集建设指引》)
附:《高质量数据集建设方案》参考图示



|  发表于 2025-12-16 18:00:29
|
查看: 271|
回复: 0
发表于 2025-12-16 18:00:29
|
查看: 271|
回复: 0
