机器作为基础设施层面的核心监控对象,其存活状态、CPU、内存、磁盘使用率等指标的监控至关重要。在典型的Prometheus生态中,通常使用标签对机器进行分组,并通过PromQL语句配置告警规则。
夜莺监控同样支持使用PromQL进行规则配置,但在机器存活监控上有着不同的设计。此外,夜莺内置的“业务组”概念,作为一种与标签类似的分组机制,为机器监控带来了新的便利,使得常规指标监控也有了更多样的实现方式。本文将对这些方法进行详细阐述。
机器存活监控
我们推荐使用Categraf采集主机指标,并通过Prometheus remote write协议将数据推送到夜莺监控。这种模式业内通常称为PUSH模式。而在经典的Prometheus生态中,通常在机器上部署Node Exporter,由Prometheus Server主动拉取数据,这被称为PULL模式。
PULL模式能够直观地感知机器存活状态——如果Prometheus拉取Node Exporter失败,则意味着机器不可达,可以通过up指标配置告警:
up{job="node-exporter"} == 0
然而,在PUSH模式下,无法天然获得这样一个up指标。试想,如果Categraf存活,它可以上报up=1;一旦Categraf或所在主机宕机,便无法上报任何数据,自然也无法上报up=0,因此无法依赖此指标判断机器状态。
为此,夜莺监控在告警规则中专门提供了 Host类型 的告警规则:
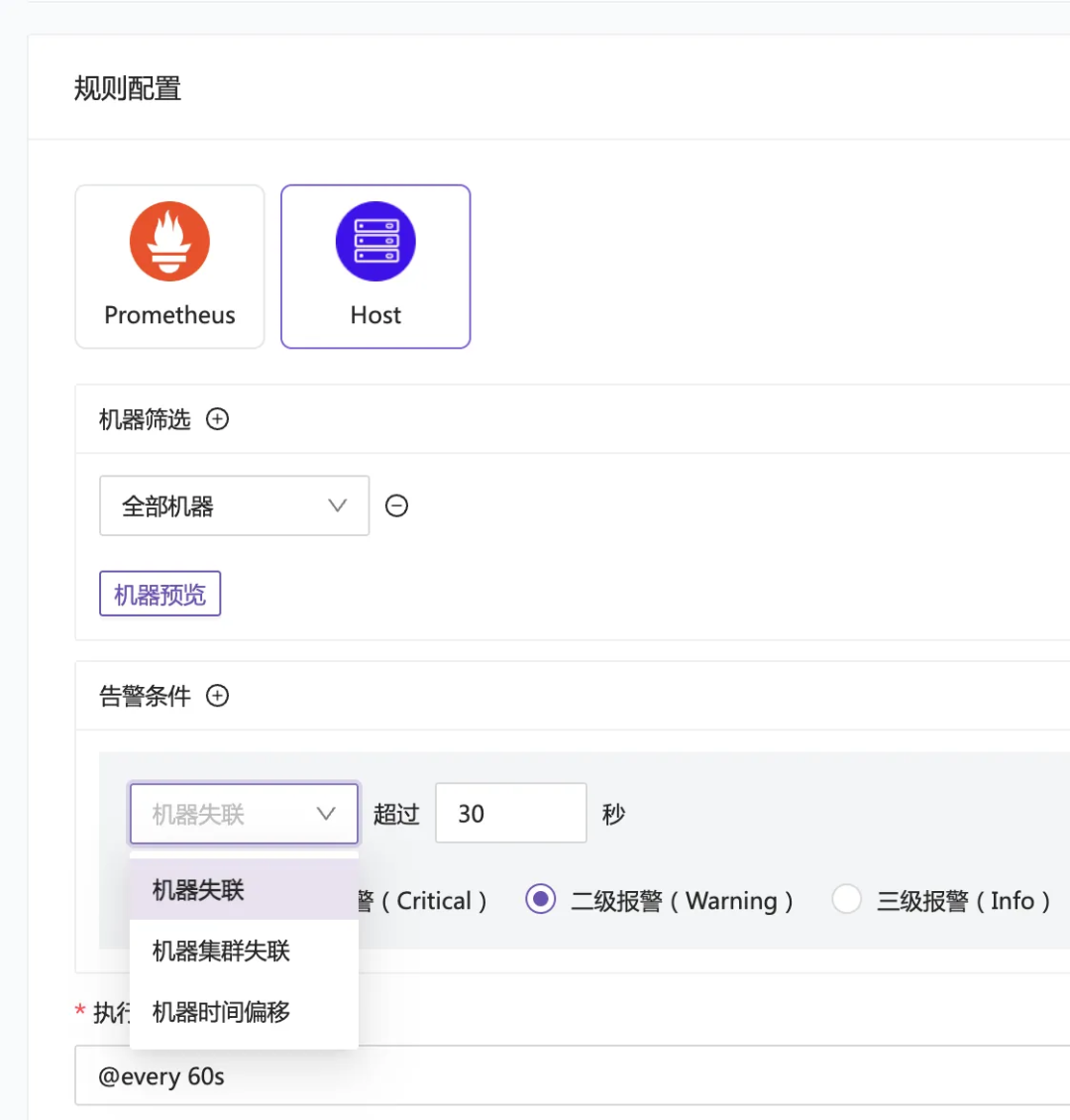
其原理是:服务端周期性地检测目标机器是否有心跳或监控数据上报。如果在规则配置的时间窗口内未收到任何信息,则判定机器失联并触发告警。
注意:Host告警模式除“失联”检测外,还包含“时间偏移”告警。这里的时间偏移是指Categraf所在机器与夜莺服务端(若使用n9e-edge模块,则为n9e-edge所在机器)之间的时间差,而非机器与NTP服务器之间的偏移。
机器普通指标监控
所谓普通指标监控,即通过Prometheus数据源配置PromQL,对CPU、内存、磁盘等机器指标进行监控。只要指标中含有机器的唯一标识(在夜莺中为ident标签),我们都可将其视作机器指标监控。
方法一:使用标签过滤
这是Prometheus生态中最常见的方式,通过标签筛选特定机器群体并配置规则。例如,仅对生产环境(env="prod")的机器设置CPU使用率告警:
cpu_usage_active{env="prod"} > 90
若想为其他环境的机器设置不同阈值(如80%),则需另配一条规则:
cpu_usage_active{env!="prod"} > 80
此方法的局限在于,如果某些机器指标中缺少env标签,则上述两条规则均无法覆盖这些机器。
方法二:使用业务组变量
假设一个告警规则只希望对“Default Busi Group”和“DevOps”两个业务组下的机器生效,可以按如下方式配置:

上图创建了一个“机器标识”类型的变量ident,其范围限定在指定的两个业务组内。随后在PromQL中引用该变量作为过滤条件。
变量模式还有一个高级用法:为特殊机器设置单独阈值。例如,上述两个业务组的默认CPU阈值为80,但其中一台机器负载常态较高,需将阈值设为88。此时可以额外配置一个阈值变量,并搭配变量筛选条件:
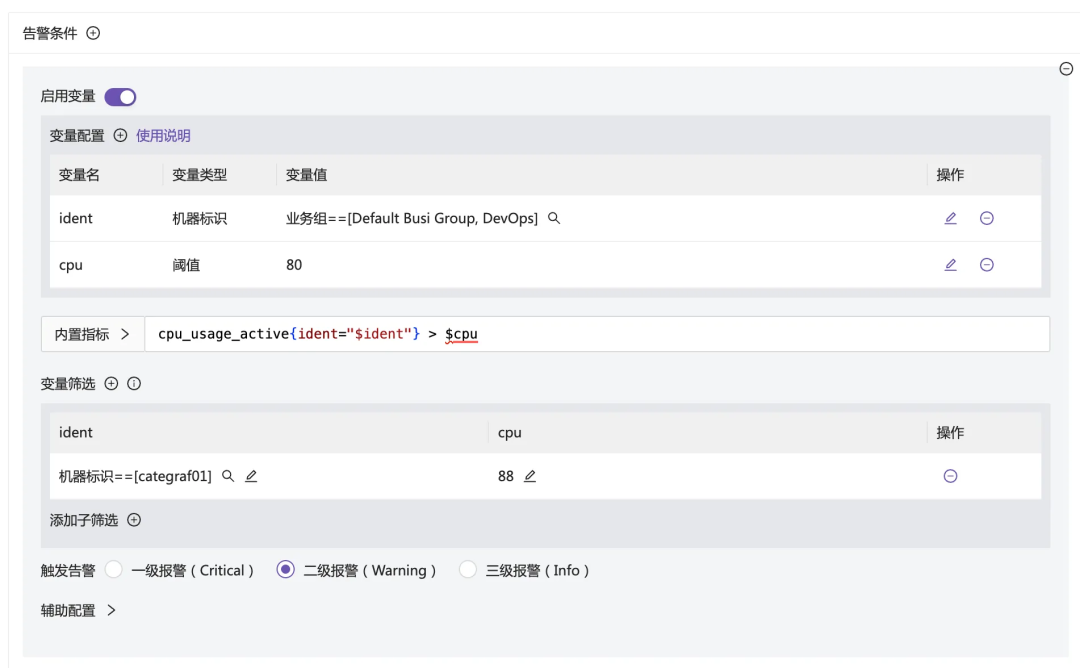
此方式虽然配置稍显复杂,但能精准应对复杂的实际场景。它适合各团队分散管理自身告警规则的协作模式。对于由运维团队统一管理所有机器告警规则的公司,则更推荐下述方式。
方法三:在通知规则中灵活分配通知人
我们可以配置一条PromQL告警规则,发现所有异常机器并生成告警事件,然后将这些事件交由通知规则处理。在通知规则中,再根据机器的业务组归属,将告警灵活路由给不同的负责人。
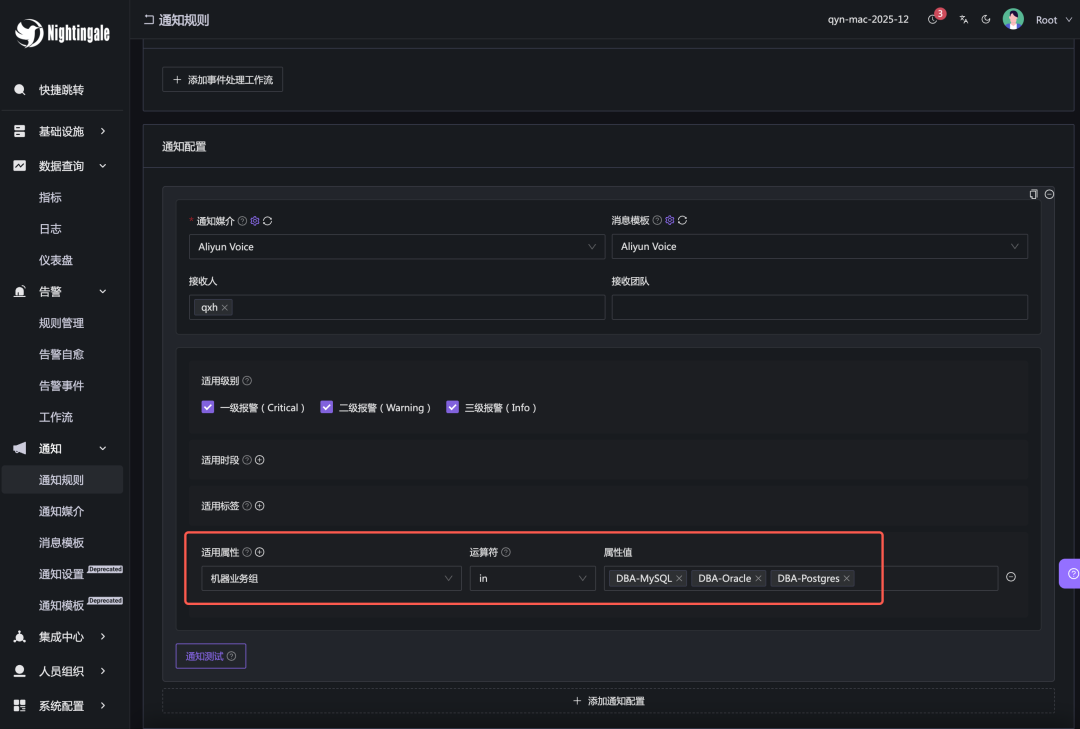
如上图示例,该通知规则使用阿里云电话通道,并设置了“机器业务组”过滤条件。当告警事件包含ident标签(即机器信息),且该机器属于DBA-MySQL、DBA-Oracle、DBA-Postgres其中之一时,告警便会发送给对应的DBA人员。
说明:早期版本中“仅在本业务组生效”的过滤方式,因其性能开销较大(每个规则需查询全量数据后再过滤),在新版夜莺中已不再推荐使用。
 发表于 2025-12-18 04:30:46
|
查看: 298|
回复: 0
发表于 2025-12-18 04:30:46
|
查看: 298|
回复: 0
