基于大语言模型(LLM)的应用,如智能体和复合AI系统,正越来越依赖于上下文适应(context adaptation)。与直接修改模型权重不同,这种方法通过在输入中添加强指令、结构化推理步骤或特定领域格式来提升模型表现。
近期,斯坦福大学与SambaNova AI的研究者联合提出了Agentic Context Engineering (ACE)框架。其核心思路是:不触及模型参数,而是专注于优化输入的上下文。ACE让模型自身生成指令(prompt)、反思效果并进行迭代改进,从而构建出一个信息密集且持续演化的“操作手册”。
现有方法的局限:简洁性偏差与上下文崩溃
尽管上下文适应前景广阔,但现有方法面临两大关键限制。
- 简洁性偏差:许多提示词优化器倾向于追求简洁、通用的指令,而非全面积累知识。这种抽象过程往往会丢失对实际应用至关重要的领域启发式方法、工具使用指南和常见失败模式。
- 上下文崩溃:依赖LLM对上下文进行整体重写的方法,容易随时间推移退化成更短、信息更少的摘要,导致性能急剧下降。这在需要保留详细任务知识的领域(如金融、法律分析)中尤为致命。
研究者在AppWorld基准测试上观察到了这一现象。当要求LLM在每一步都完全重写累积的上下文时,上下文会发生“崩溃”:在某一时刻拥有超过1.8万个令牌、准确率达66.7%的上下文,下一步骤可能突然缩减至122个令牌,准确率骤降至57.1%,甚至低于不做任何适应的基准水平(63.7%)。
 图:上下文崩溃示意图。完全重写会导致信息量(Token数)和任务准确率突然下降。
图:上下文崩溃示意图。完全重写会导致信息量(Token数)和任务准确率突然下降。
ACE框架设计:构建演化的操作手册
针对上述问题,ACE框架提出了解决方案。它不将上下文压缩为精炼摘要,而是将其视为一个随时间累积和组织策略的、不断演化的操作手册(playbook)。
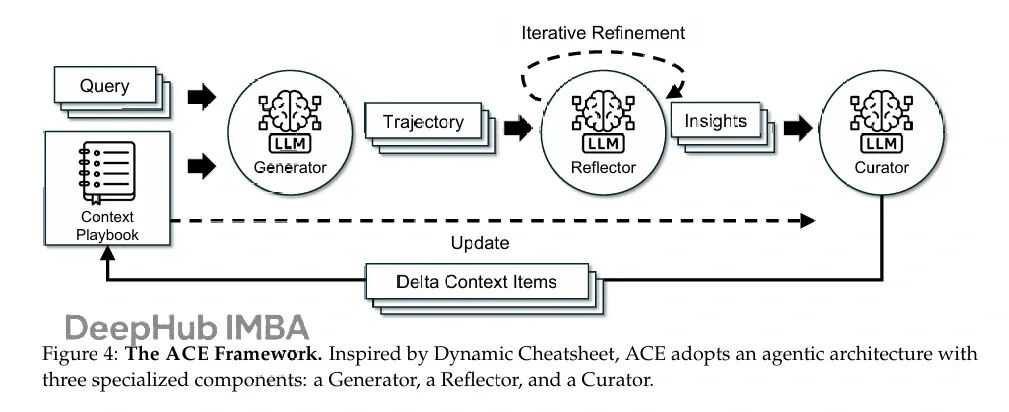 图:ACE框架工作流程,包含生成(Generation)、反思(Reflection)和策展(Curation)三个核心模块。
图:ACE框架工作流程,包含生成(Generation)、反思(Reflection)和策展(Curation)三个核心模块。
ACE的工作流基于模块化的生成-反思-策展循环:
- 生成器 为新查询生成推理轨迹,暴露有效策略和反复出现的问题。
- 反思器 批判性地分析这些轨迹,提取经验教训。
- 策展器 将这些教训合成为紧凑的“增量条目”,并通过轻量级(非LLM)逻辑确定性地合并到现有上下文中。
这种设计的关键在于 “增量更新” 和 “生长-精炼”机制。
- 增量更新:上下文被结构化为独立的“要点”(bullet)集合,每个要点包含元数据(如使用计数)和内容(如一条可复用策略)。更新时,只修改相关的要点,而非重写整个上下文,从而避免知识丢失。
- 生长-精炼:新要点会被追加,现有要点会就地更新(如增加有用次数)。系统会通过语义嵌入比较来定期去重和修剪冗余,确保上下文既全面又紧凑。
实验结果:性能显著提升,成本大幅降低
研究者在智能体任务(AppWorld)和领域特定任务(金融推理)上对ACE进行了评估。
在智能体任务上的表现
在AppWorld基准测试中,ACE展现出显著优势:
- 在离线适应设置下,ACE比基于GPT-4驱动的智能体性能高出10.6%。
- 即使在没有真实标签(ground-truth)的在线适应中,ACE也能通过学习执行反馈(如代码执行成功/失败)实现平均14.8%的性能改进。
- 值得注意的是,使用开源模型DeepSeek-V3.1并结合ACE框架,其整体性能(平均59.4%)已与排行榜上顶尖的、基于GPT-4.1的生产级智能体(IBM CUGA,60.3%)相当。
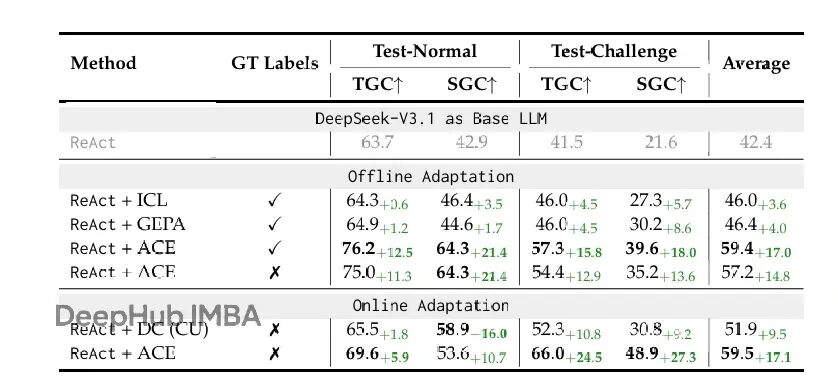 图:AppWorld排行榜结果对比,ACE框架助力小模型达到顶尖专有系统水平。
图:AppWorld排行榜结果对比,ACE框架助力小模型达到顶尖专有系统水平。
在金融推理任务上的表现
在需要精确领域知识的FiNER和Formula金融分析任务中:
- ACE在离线设置下,比基于少量示例学习(ICL)和提示优化器(GEPA)等方法平均提升8.6%。
- 这证明了结构化、演化的上下文在掌握专门概念和策略方面的有效性。
效率与成本优势
得益于增量更新和并行处理“增量”的能力,ACE在效率和成本上优势明显:
- 在AppWorld的离线适应中,相比GEPA,ACE减少了82.3% 的适应延迟和75.1% 的推演(rollout)次数。
- 在FiNER的在线适应中,相比动态备忘录(Dynamic Cheatsheet),ACE减少了91.5% 的适应延迟和83.6% 的Token成本。
 图:ACE在适应延迟和成本上相比基线方法有巨大优势。
图:ACE在适应延迟和成本上相比基线方法有巨大优势。
讨论与展望
ACE框架的提出,为人工智能系统的优化提供了新视角。它表明,有时与其追求更庞大的模型,不如更智能地设计与模型的“对话”方式。
- 对工程部署的启示:现代服务基础设施(如KV缓存复用)已针对长上下文优化,使得ACE这类产生丰富上下文的方法在实际部署中越来越可行。
- 对持续学习的价值:ACE为传统模型微调提供了一个灵活、高效的替代方案。其上下文是人类可解释的,这支持了“选择性遗忘”,对于满足隐私法规或修正错误信息具有重要意义。
- 与现有技术结合:未来工作可以探索将ACE与其他适应技术(如参数高效微调PEFT)相结合,以发挥更大效能。
总结
斯坦福等机构提出的ACE框架,通过智能化的上下文工程,在不修改大模型任何参数的情况下,显著提升了其在复杂任务上的性能。它通过生成、反思、策展的循环,构建了一个持续学习和演化的“操作手册”,有效克服了现有方法的简洁性偏差和上下文崩溃问题。
实验结果证明,ACE不仅在智能体和专业领域任务上表现卓越,还大幅降低了适应过程的成本和延迟。这为构建更灵活、可解释且能持续自我改进的AI系统开辟了新的道路。随着对人工智能系统交互方式理解的深入,类似ACE这样专注于优化输入的方法可能会变得越来越重要。 |  发表于 2025-12-18 23:54:27
|
查看: 248|
回复: 0
发表于 2025-12-18 23:54:27
|
查看: 248|
回复: 0
