近年来,Agent(智能代理)方向的研究论文投稿量呈现爆发式增长,相关论文下载量已突破120万次,且中稿率保持可观。这一现象背后,反映了Agent领域正处于发展的黄金窗口期,对于希望在此方向发表论文的研究者而言,高效的学习路径、对核心系统形态的把握以及技术融合创新的洞察显得尤为关键。
本文从系统形态、技术基础与创新三大维度出发,系统梳理了131篇涵盖顶会热点(如“多智能体”、“大模型智能体”)的经典与前沿论文,并规划了从入门到应用的全流程学习路径。此外,文末附带了谷歌发布的321个Agent落地案例及配套代码,旨在为研究者提供一套完整的入门与论文写作资源。
Agent 核心系统形态
理解Agent的核心系统形态是入门的第一步,它直接定义了智能体的协作模式与适用场景。
单智能体
单智能体系统指能够独立完成任务的个体,其研究聚焦于“个体决策与自主执行”,典型应用包括个人助理、单一机器人控制等。
ATA: Adaptive Transformation Agent for Text-Guided Subject-Position Variable Background Inpainting
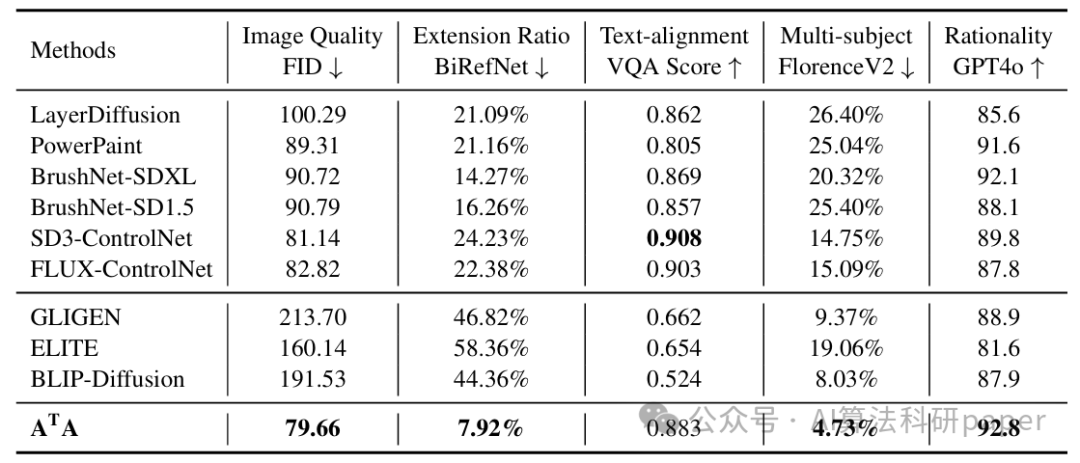
方法: 该论文提出了自适应变换单智能体(AᵀA)。它以Hunyuan-DiT为基础框架,通过包含反向排列PosAgent块的RDT模块来预测并调整图像中主体的位置,并引入位置切换嵌入以支持“自适应”与“固定”两种补全模式。经过混合训练后,该智能体在文本引导的背景补全任务(支持主体位置可变或固定)中表现出色。
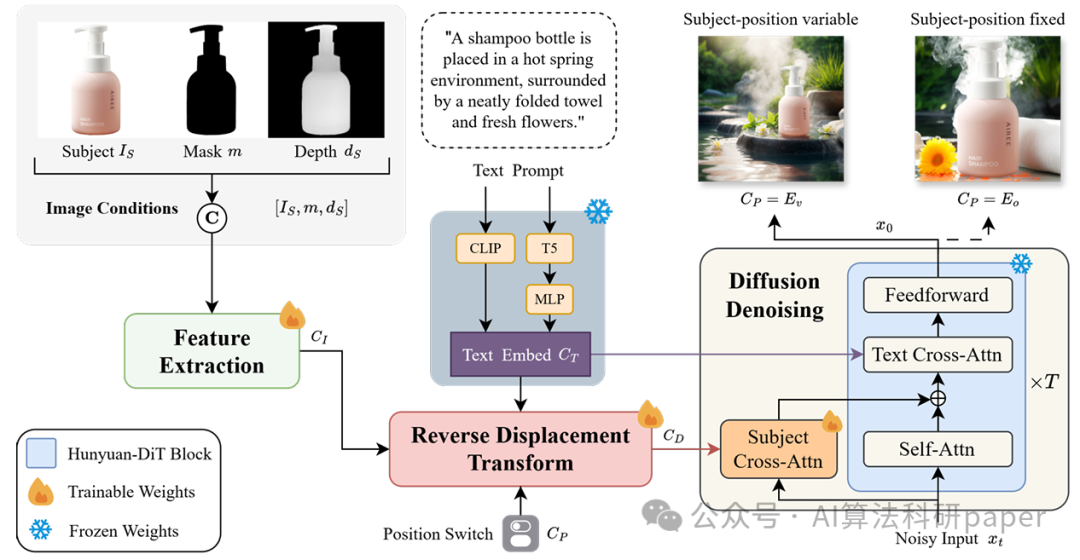
创新点:
- 定义了“文本引导下主体位置可变的背景补全”这一新任务,使智能体能自适应调整主体位置以更好地融合背景。
- 设计了包含反向位移变换(RDT)模块的AᵀA单智能体,利用反向排列的PosAgent块优化主体位置,有效缓解图像变形。
- 为AᵀA增加了位置切换嵌入机制,使其能灵活切换工作模式,并配合混合训练策略以适应不同的补全场景。
多智能体
多智能体系统由多个协同工作的智能体构成,核心研究问题在于“群体协作与冲突解决”,例如自动驾驶车队、多模态医疗诊断团队等。
V-Stylist: Video Stylization via Collaboration and Reflection of MLLM Agents
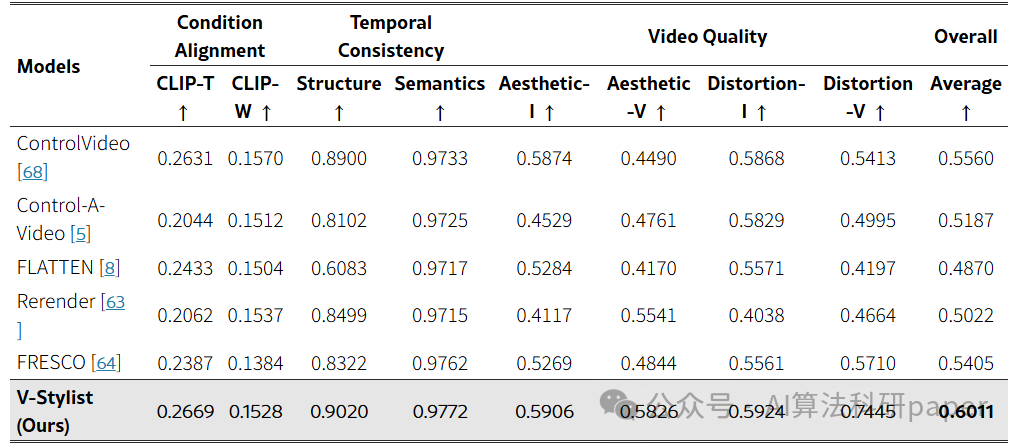
方法: 该论文提出了V-Stylist多智能体系统,用于完成文本引导的视频风格化任务。系统内部分工明确:Video Parser智能体负责解析视频并生成描述提示;Style Parser智能体通过树状搜索匹配最合适的风格模型;Style Artist智能体则进行多轮反思以精细调整风格化参数。三个智能体协同工作,解决了视频风格化中的过渡、匹配与控制等核心难题。论文同时还构建了TVSBench评测基准。
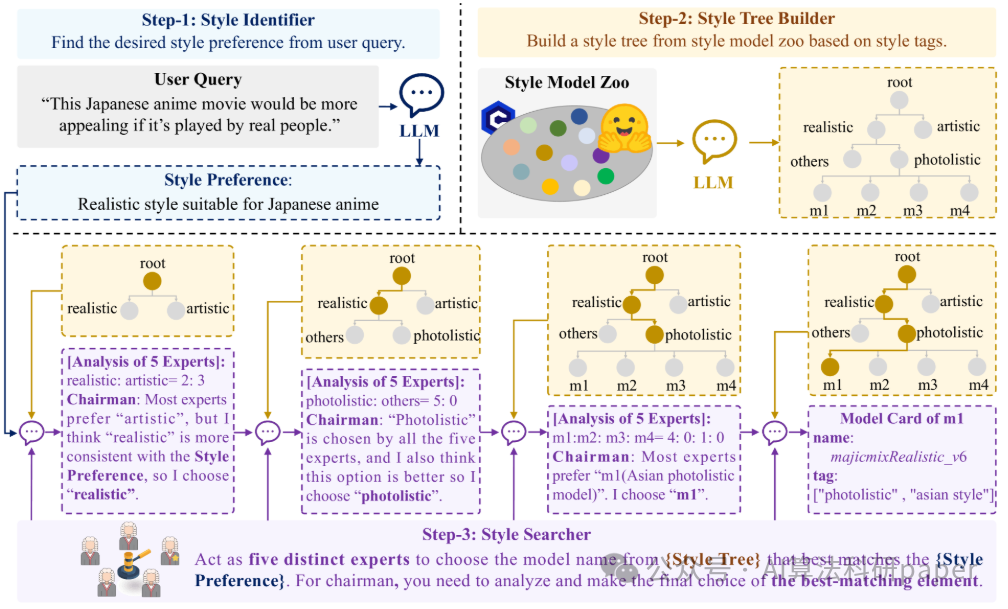
创新点:
- 提出了一个分工协作的多智能体系统框架,通过Video Parser、Style Parser和Style Artist三个专属智能体分别攻克视频过渡、风格匹配和细节控制三大挑战。
- 为每个智能体配备了特色机制:视频解析与提示生成、树状风格搜索、以及基于多轮反思的参数优化。
- 构建了TVSBench评测基准,包含50个视频和17种风格,填补了复杂视频风格化任务缺乏系统性评估的空白。
Agent 技术基础与融合创新
这部分内容涵盖了实现Agent的“技术底座”与前沿“创新方向”,包括从构建、应用到评估的全链路,以及与其他领域的技术交叉,是论文选题的关键来源。
大模型智能体
以大语言模型为核心驱动的Agent技术体系是当前的主流范式,其研究覆盖了智能体“构建、应用、评估”的全流程。
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
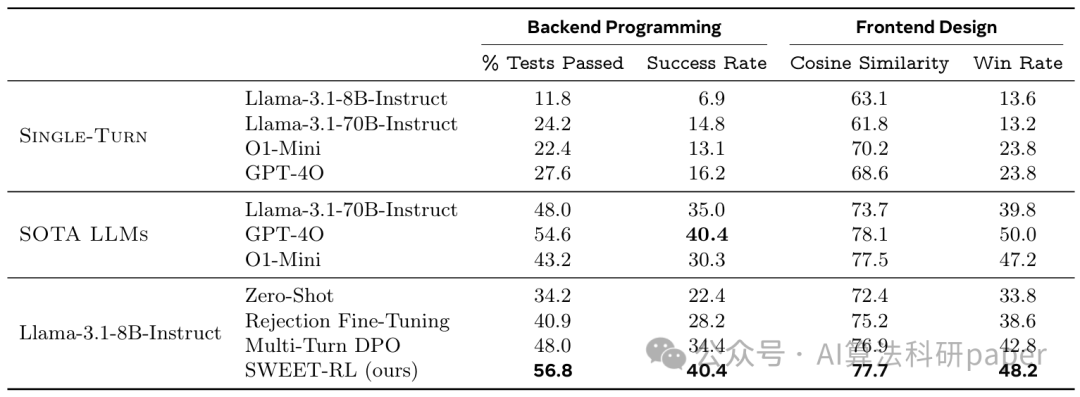
方法: 为提升大模型智能体在多轮协作任务中的表现,该研究首先构建了ColBench基准(涵盖编程、设计等真实场景)。随后提出了SWEET-RL算法:该算法让智能体在训练阶段利用额外的参考信息学习回合级的优势函数,继而优化策略,从而解决了传统强化学习方法中价值函数泛化性差的问题。实验表明,该方法使Llama-3.1-8B模型的性能提升了6%,并能达到与GPT-4o相媲美的水平。这体现了大模型驱动智能体在复杂推理任务上的巨大潜力。
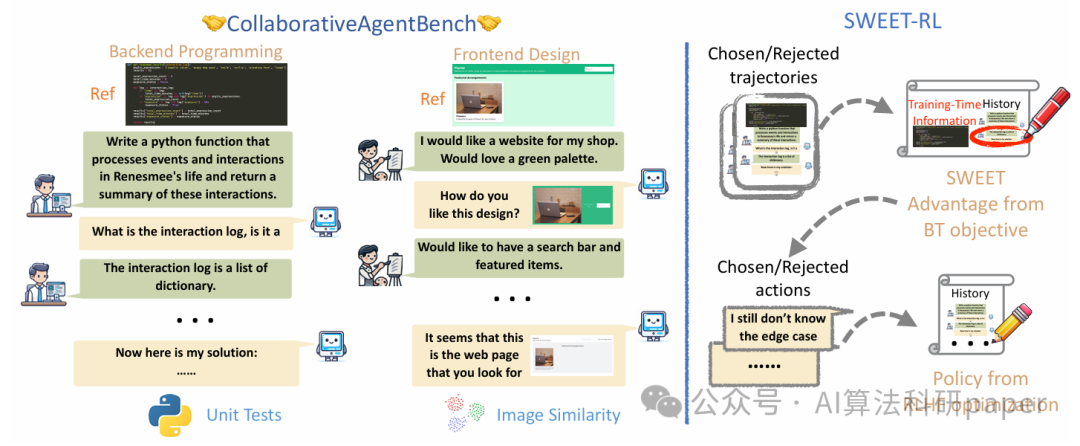
创新点:
- 建立了ColBench基准,覆盖编程、设计等需多轮交互的真实协作场景,并利用大语言模型模拟交互以进行低成本评估,弥补了现有基准的不足。
- 提出了SWEET-RL算法,创新性地让智能体借助训练时的参考信息学习优势函数,避免了传统价值函数拟合的局限性,提升了策略优化效率。
- 设计了两阶段训练流程,将学得的优势函数作为奖励模型,并采用DPO优化策略,显著提升了大模型智能体的协作性能。
Graph+AI Agents
将图计算技术与Agent相融合是一种新兴的创新范式,旨在提升智能体的推理效率、优化记忆管理并增强多体协同能力。
AFLOW: AUTOMATING AGENTIC WORKFLOW GENERATION
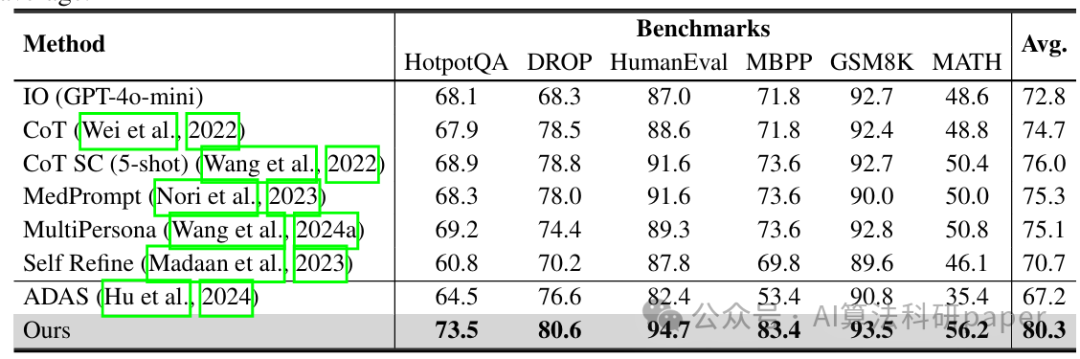
方法: 该论文提出了AFLOW框架,用于自动化生成大模型智能体的工作流。其核心是将工作流构建为一个代码化的搜索空间,利用蒙特卡洛树搜索结合预定义算子进行探索,由大模型负责对工作流节点进行修改与扩展,并根据执行反馈进行持续优化。在6个基准数据集上的测试表明,AFLOW平均性能超越现有方法5.7%。尤为突出的是,它能使较小规模的模型以仅相当于GPT-4o 4.55%的成本,在特定任务上达到后者水平。这种基于图的智能体工作流优化方法为平衡性能与成本提供了新思路。
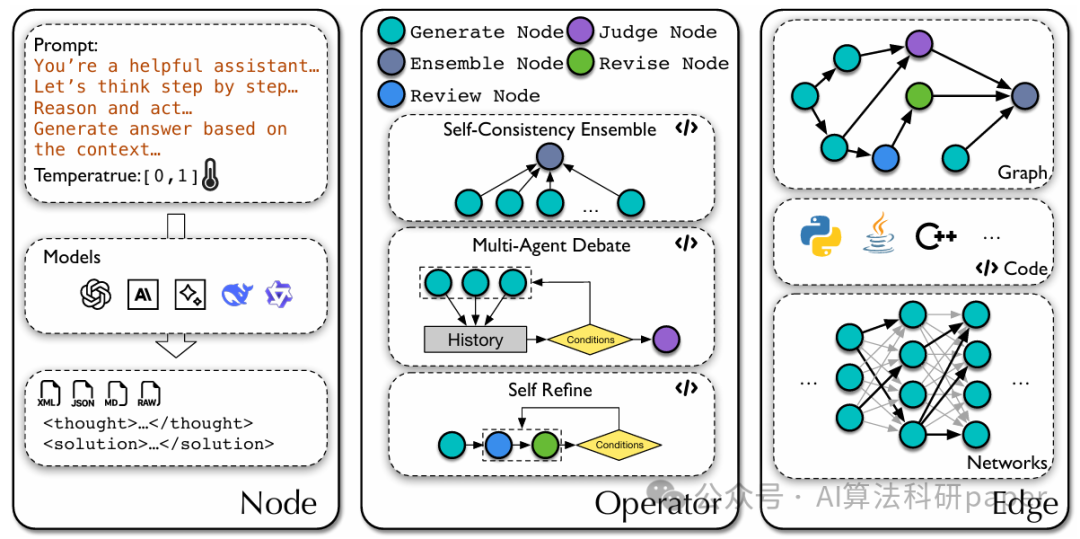
创新点:
- 将大模型智能体的工作流优化问题形式化为一个代码化的图搜索问题,用节点和逻辑边进行建模,无需依赖人工设计。
- 提出了AFLOW自动化框架,结合蒙特卡洛树搜索的探索能力、预定义算子的操作集以及大模型的扩展与反馈优化机制。
- 在多个任务上实现了高性能与低成本的平衡,使得轻量级模型能够以极低代价在特定领域媲美顶级大模型,展现了极高的应用性价比。
|  发表于 2025-12-19 00:19:57
|
查看: 220|
回复: 0
发表于 2025-12-19 00:19:57
|
查看: 220|
回复: 0
