在使用 Flink SQL 进行实时数据处理时,双流 Join 是一种极为常见的操作,广泛应用于广告效果分析(曝光流与订单流实时关联)、实时推荐(点击流与商品信息关联)等场景。然而,双流 Join 为了确保计算结果的准确性,需要在算子状态中维护两侧输入流的全量历史数据。随着作业持续运行,这一机制会带来一系列问题:
运维层面挑战:
- 状态数据量无限制增长,迫使开发者不断增加作业资源以维持高吞吐。
- 过大的状态容易导致 Checkpoint 超时,进而引发作业不稳定和频繁的 Failover。
- 状态作为 Flink 内部产物,在问题排查时难以直观探查其内部数据。
开发层面挑战:
- 当查询逻辑(Query)迭代修改后,原有状态难以复用,重启作业进行数据回追的代价高昂。
为解决上述痛点,Flink 社区在 2.1 版本引入了全新的 Delta Join 算子,并在 2.2 版本中对其功能进行了进一步扩展。Delta Join 的核心思路是摒弃在算子内部冗余存储全量状态的做法,转而利用双向 Lookup Join 直接查询外部源表中的数据。这种设计实现了对源表数据的复用,而非依赖本地状态。结合流存储 Apache Fluss,Delta Join 已在阿里巴巴淘宝天猫团队成功落地,与传统的双流 Join 相比,展现出显著优势:
- 消除了近 50 TB 的双流 Join 状态。
- 计算资源消耗(CU)降低了 10 倍。
- 作业恢复速度提升了 87%。
- Checkpoint 在秒级内即可完成。
01 双流 Join 实现原理
首先,我们简要回顾 Flink 双流 Join 的工作原理。
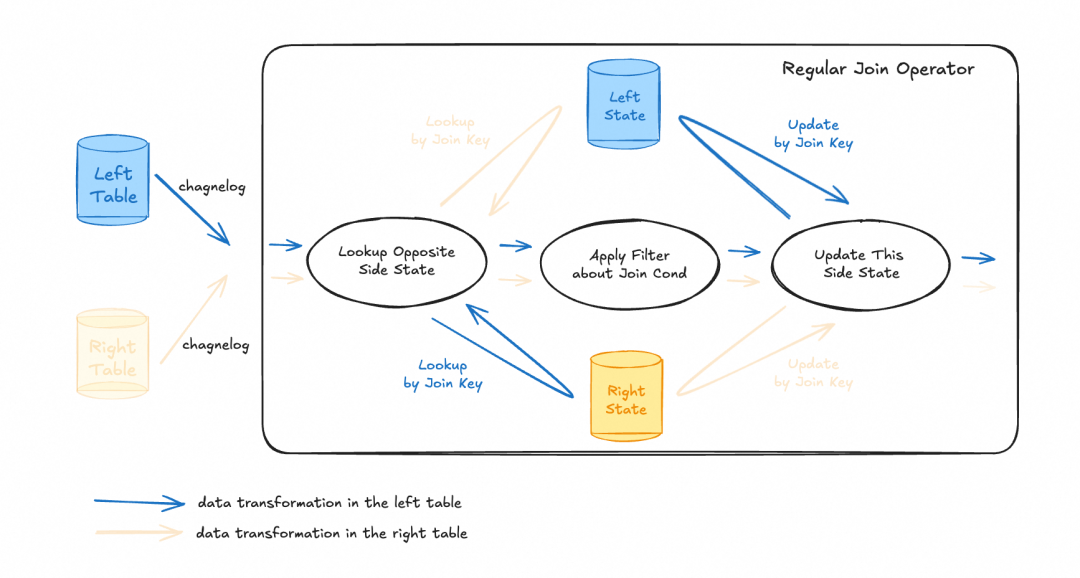
以处理左侧表(Left Table)的 changelog 数据为例,数据流入后主要经历三个阶段:
- 状态查询:根据 Join Key 查询对侧(右侧)的状态,获取历史上流入该侧的全部相关数据。
- 条件过滤与输出:使用 Join 条件对查询到的数据进行过滤,并输出匹配的结果。
- 状态更新:将当前输入的这条数据存入本侧(左侧)的状态中,以便后续右侧数据到来时能够正确匹配。
由于流计算具有无边界的特点,左右两侧数据匹配的时间点可能存在延迟。为了确保即使一侧数据延迟到达也能与另一侧数据关联并输出正确结果,必须将所有数据记录在状态中。虽然双流 Join 的算法保证了数据的正确性,但其状态会随时间推移无限增长,成为影响作业资源消耗和稳定性的关键因素。
目前虽有 Interval Join、Lookup Join、State TTL Hint 等手段来缓解或解决状态问题,但它们都面向特定业务场景,并在功能上有所取舍(例如 Lookup Join 无法追踪维表侧的数据更新,State TTL Hint 会放弃匹配超过 TTL 期限的数据)。
02 Delta Join 技术原理
从双流 Join 的原理可以看出,状态中记录的全量数据与源表中的数据基本一致。一个直观的改进思路是:复用源表数据来替代原有的本地状态。Delta Join 正是基于这一思想,它利用外部存储系统(如 Fluss)提供的索引能力,绕过状态查询,直接对外部存储发起高效的、基于索引的数据查询以获取匹配记录,从而消除了双流 Join 状态与外部系统之间的冗余数据存储。
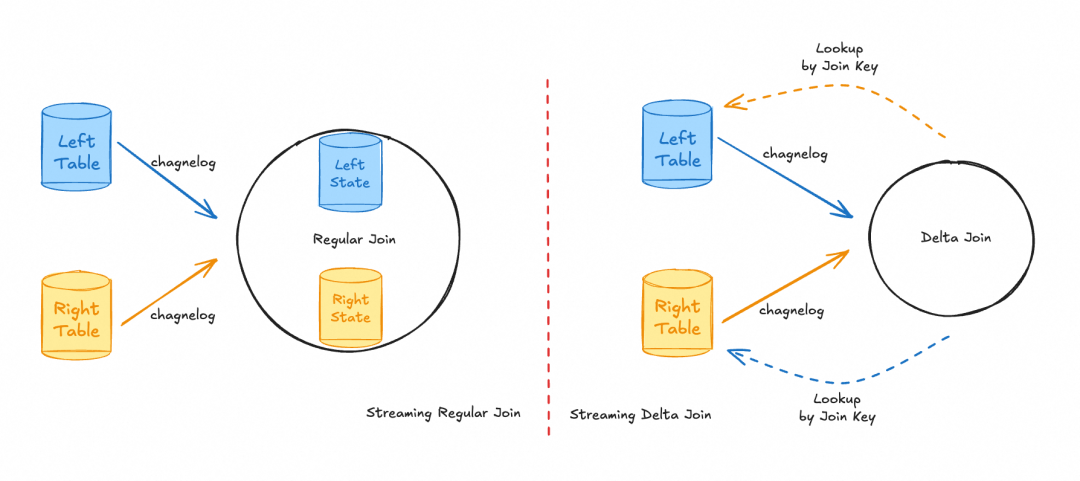
理论推导
以两路输入为例,增量更新 Join 结果的公式可表示为:
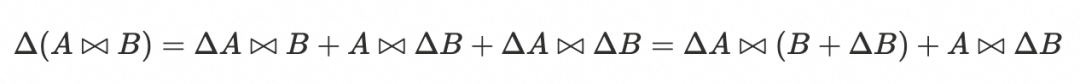
其中,A 代表左表的全量历史数据,ΔA 代表左表的增量数据。B 和 ΔB 的定义与之类似。计算 Join 结果的增量部分时,只需获取源表在上次计算后新产生的增量数据,并查询对侧源表的历史快照数据。因此,方案要求:
- 能够感知源表的增量数据。
- 能够访问源表的历史快照数据。
这对底层存储引擎提出了很高要求:需要支持快照隔离(Snapshot Isolation)以保证强一致性语义。然而现实存在几个问题:
- 目前仅部分存储支持快照概念,如 Paimon、Iceberg、Hudi 等。
- 快照生成间隔通常在分钟级别,无法满足实时处理需求。
- 指定快照查询时,该快照可能在存储系统中已过期。
鉴于上述限制,Flink 2.1 提出了一种满足实时性要求的、最终一致性(Eventually Consistent)的 Delta Join 方案。
最终一致性语义的 Delta Join
最终一致性的 Delta Join 不要求源表存储引擎支持快照,它总是查询源表当前最新的数据。其对应的公式变种如下:
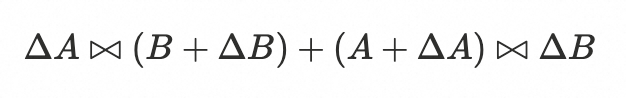
与强一致性 Delta Join 相比,最终一致性方案会多产生一部分额外的中间结果 ΔA ✕ ΔB,因此只能保证最终结果是一致的。
以下是双流 Join 与两种 Delta Join 的对比:
| 特性 |
双流 Join |
强一致性 Delta Join |
最终一致性 Delta Join |
| 延迟 |
低 |
高 |
低 |
| 状态大小 |
大 |
小 |
小 |
| 状态内数据 |
两侧输入全量明细 |
上次触发计算的快照id |
等待触发的异步队列 |
| 数据一致性 |
强一致性 |
强一致性 |
最终一致性 |
03 Delta Join 算子实现
为了提高算子吞吐能力,Delta Join 算子内部设计了一个 TableAsyncExecutionController 组件和两个结构完全相同的 DeltaJoinRunner 组件(分属左右两侧)。
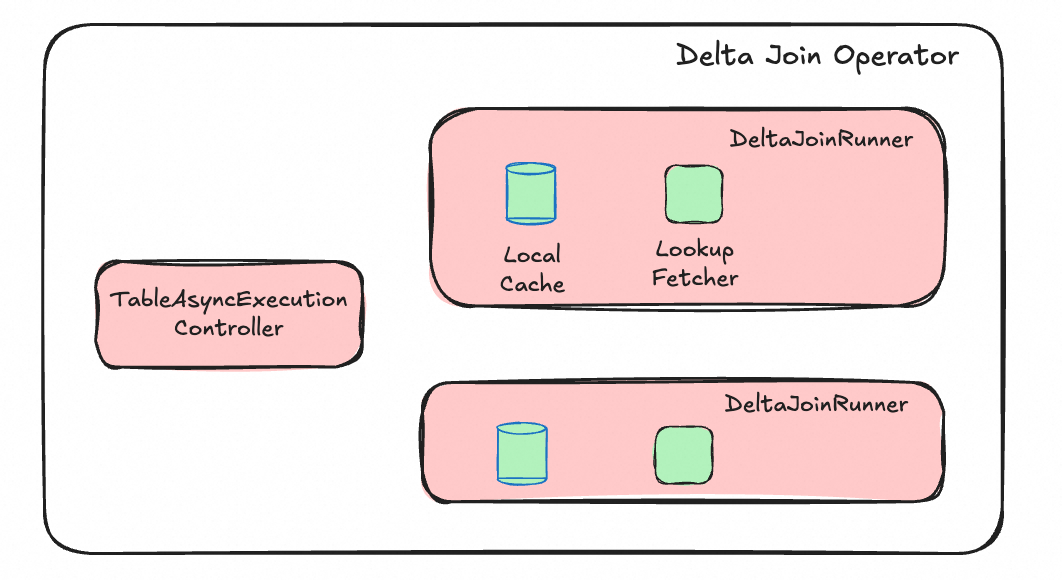
TableAsyncExecutionController 原理
该组件由 FLIP-519 引入,其核心机制是:严格保证相同 Join Key 的数据串行执行,同时允许不同 Key 的数据并行处理,再结合异步处理,显著提升吞吐。
其运行原理如下图所示:
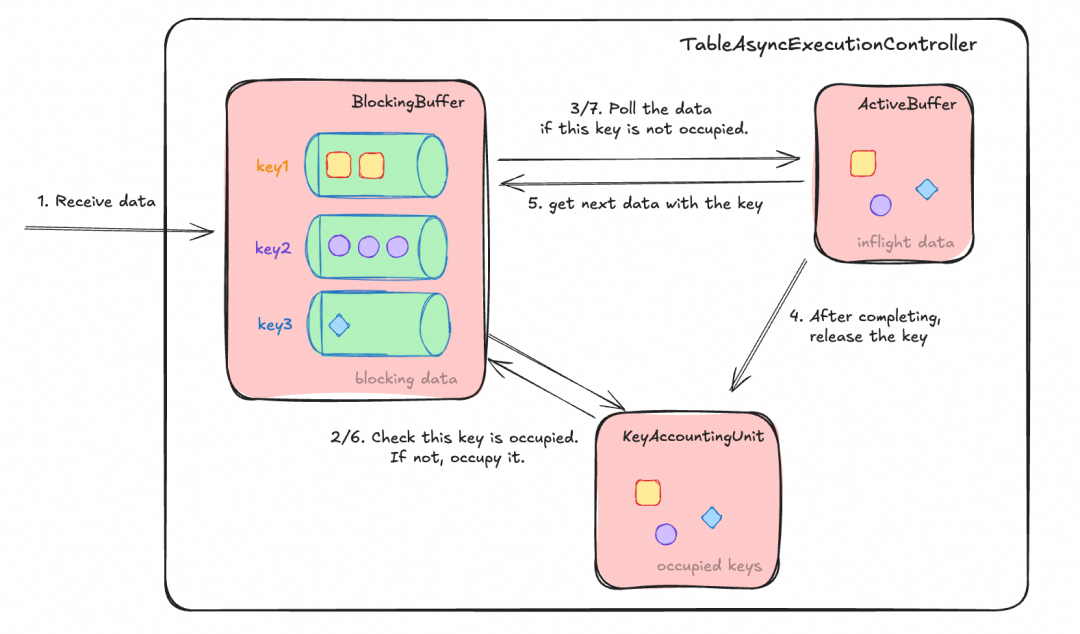
TableAsyncExecutionController 接收数据后,按 Key 分发到 BlockingBuffer 内不同 Key 的队列中。KeyAccountingUnit 会检查当前 Key 是否已被占用(即有数据正在执行)。若被占用,则返回等待;若未被占用,则“抢占”该 Key,并从队列中取出数据放入 ActiveBuffer,交由后续计算逻辑处理。同时注册回调函数,在数据处理完毕并输出后,于 KeyAccountingUnit 中释放该 Key,并继续处理 BlockingBuffer 中该 Key 的下一条数据。此机制有效避免了因分布式乱序导致的相同 Key 数据并发问题,是 FLIP-425 异步执行模型的简化版本。
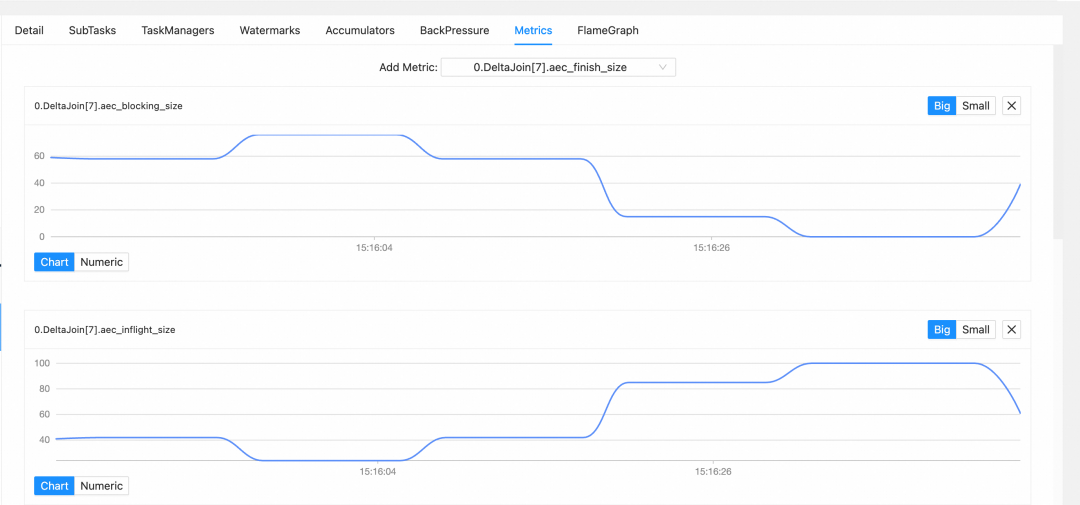
在实际场景中,算子的吞吐受限于 BlockingBuffer 允许的最大容量(各 Key 队列大小之和)。容量过小会限制异步并行能力的发挥,影响吞吐;容量过大则可能占用过多内存,并给外部存储带来较大查询压力。可通过以下参数调整:
table.exec.async-lookup.buffer-capacity: 1000 // 默认 100
通过监控以下 Metric 可判断是否需要调整:
aec_blocking_size:BlockingBuffer 内所有被阻塞 Key 的队列大小之和。值越大说明 Join Key 越密集,可考虑开启或增大 Delta Join Cache;若值较小但吞吐不佳,可尝试增大 table.exec.async-lookup.buffer-capacity。aec_inflight_size:ActiveBuffer 内正在执行计算的数据数量。值越大说明同时请求外部存储的数据较多,可能存在请求堆积,需检查外部存储状态或优化查询参数;值越小说明 Join Key 较密集,可考虑开启或增大 Cache。
提示:当使用 Apache Fluss 作为 Delta Join 的源表时,可通过 Flink Table Hint 在 Fluss 表上配置以下参数以提升查询效率:
client.lookup.queue-sizeclient.lookup.max-batch-sizeclient.lookup.max-inflight-requestsclient.lookup.batch-timeout
具体请参考 Fluss Connector Options。
04 DeltaJoinRunner 原理
DeltaJoinRunner 是负责执行 Lookup 查询的核心组件。由于算子需处理两侧数据,因此左右侧各有一个完全相同的 DeltaJoinRunner 来查询对侧表的数据。
如果每条数据都直接查询外部存储,会对存储系统造成巨大压力,算子吞吐将完全受限于外部系统的查询性能。若使用普通 Cache 缓存 Lookup 结果,则无法感知被查询表的数据更新。为此,Delta Join 引入了 驱动侧仅构建、Lookup 侧仅更新 的特殊 Cache 机制。
DeltaJoinRunner 组件(以左侧流查询右侧表为例)的运行原理如下,主要由 LocalCache 和 LookupFetcher 构成:
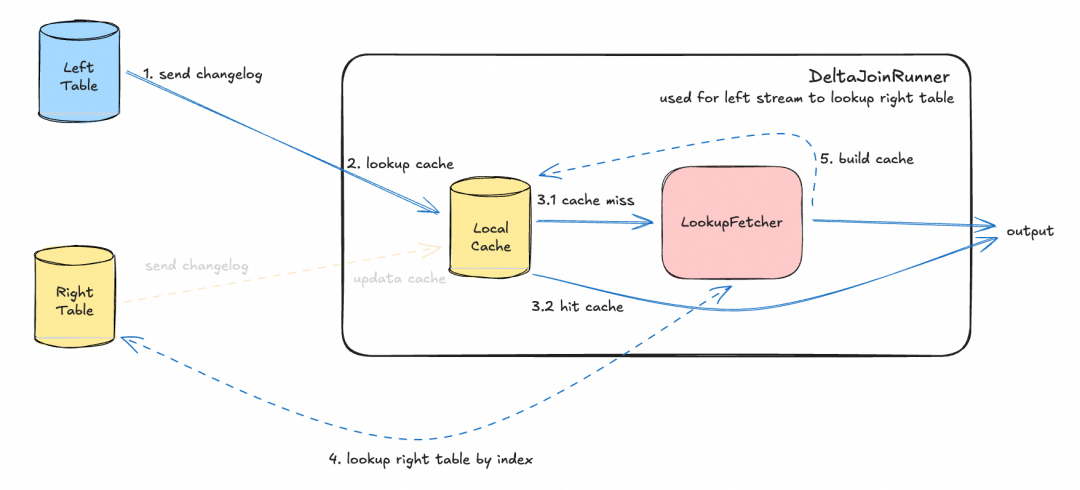
- 左侧数据到达:首先查询 LocalCache。
- 若有缓存,则直接输出结果。
- 若无缓存,则通过 LookupFetcher 利用右表的索引查询右表数据。查询返回后,在 LocalCache 中构建缓存,然后输出结果。
- 右侧数据到达:检查本 DeltaJoinRunner 中的 LocalCache。
- 若无相关缓存,则忽略此更新。
- 若有相关缓存,则更新缓存中的数据。
此 Cache 机制一方面在 Join Key 较为密集的场景下大幅提升算子吞吐,并减轻外部存储的查询压力;另一方面确保了对侧表的最新数据能及时更新缓存,使后续查询能匹配到正确的结果。
该 Cache 采用 LRU 策略,合理设置其大小至关重要。过小会影响命中率,过大则占用较多内存。可通过以下参数分别调节左右两侧 Cache 大小,或在每条数据的 Join Key 都不同、Cache 基本无效时关闭 Cache:
table.exec.delta-join.cache-enabled: true // 是否启用cache,默认为 true
table.exec.delta-join.left.cache-size: 10000 // 左表数据缓存大小,默认10000。左表较小或右流Key密集时建议设大
table.exec.delta-join.right.cache-size: 10000 // 右表数据缓存大小,默认10000。右表较小或左流Key密集时建议设大
可通过监控以下 Metric 判断是否需要调整 Cache 大小:
deltaJoin_leftCache_hitRate:右流查询左表时,左表 Cache 的命中率百分比(越高越好)。deltaJoin_rightCache_hitRate:左流查询右表时,右表 Cache 的命中率百分比(越高越好)。
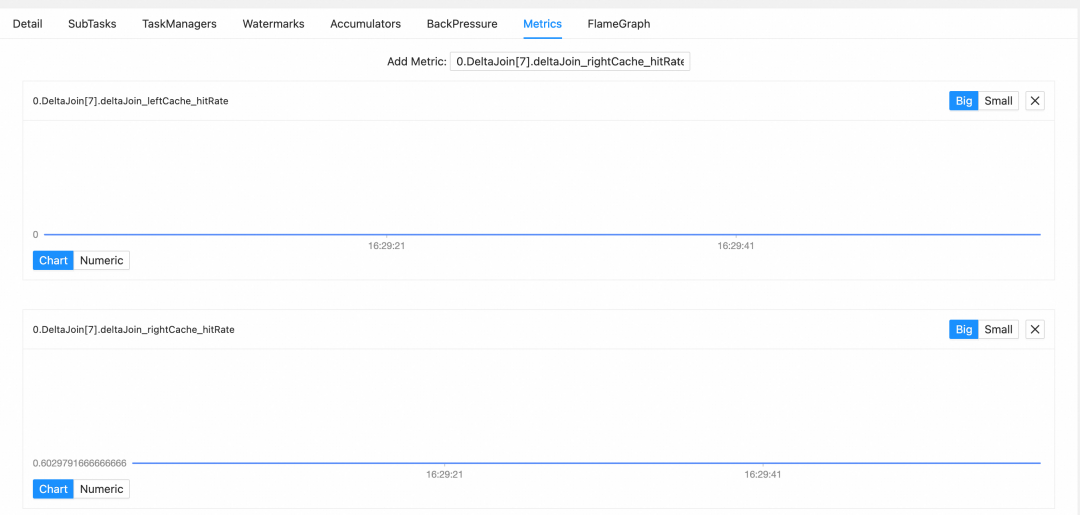
注:上图来源于后文实战章节的 Nexmark q20 变种 Query。由于右表(Auction 表)每次生成的 id 均不同,因此 deltaJoin_leftCache_hitRate 始终为 0。
05 实战演练
我们借用 Nexmark 数据集 中 q20 的查询语句,稍作修改后作为本次实战的示例代码。
-- 获取包含相应拍卖信息的出价表
INSERT INTO nexmark_q20
SELECT
auction, bidder, price, channel, url, B.`dateTime`, B.extra,
itemName, description, initialBid, reserve, A.`dateTime`, expires, seller, category, A.extra
FROM
bid AS B INNER JOIN auction AS A on B.auction = A.id;
-- WHERE A.category = 10;
方式一:使用 Docker 环境测试(推荐)
1. 环境准备
- 类 Unix 操作系统(Linux、Mac OS X)。
- 建议内存至少 4 GB,磁盘空间至少 4 GB。
2. 下载并运行 Docker 镜像
docker pull xuyangzzz/delta_join_example:1.0
docker run -p 8081:8081 -p 9123:9123 --name delta_join_example -it xuyangzzz/delta_join_example:1.0 bash
3. 运行任务 SQL
在 Docker 容器内执行:
# 启动 flink 和 fluss 集群
./start-flink-fluss.sh
# 创建相关表并启动 delta join 作业
./create-tables-and-run-delta-join.sh
之后,在宿主机访问 localhost:8081 即可查看 Flink UI,确认 Delta Join 作业正在运行。
4. 向源表插入数据
在 Docker 容器内执行:
./insert-data.sh
5. 观察 Delta Join 作业
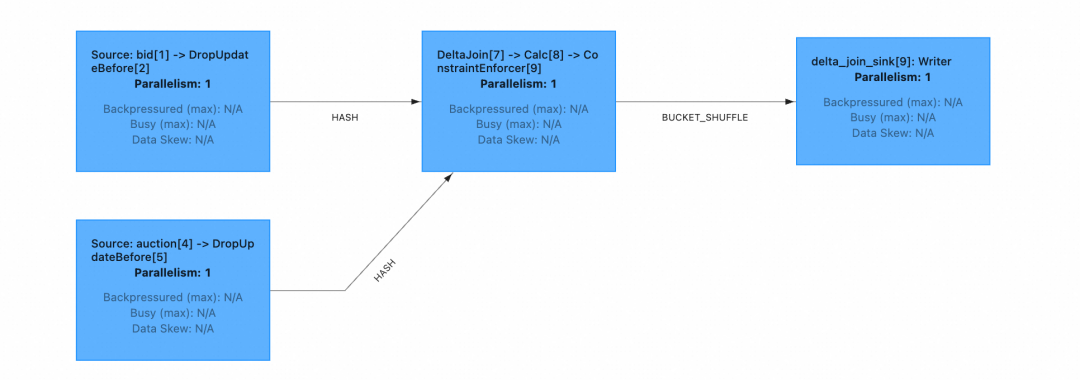
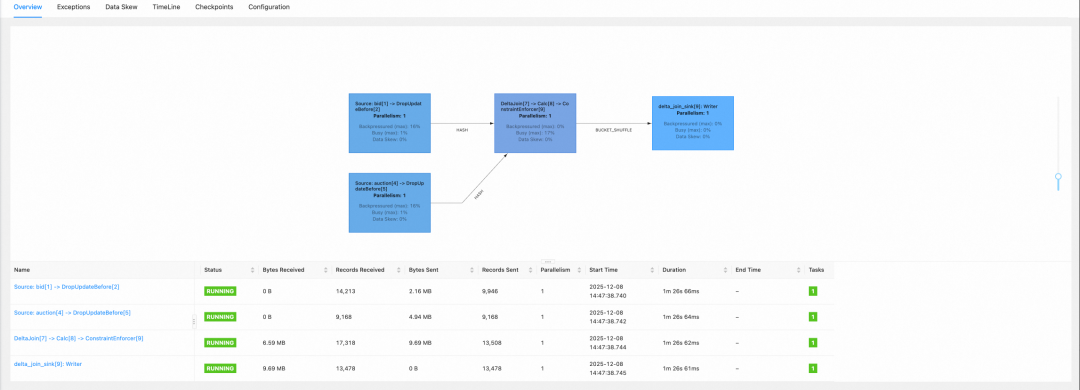
在 Flink UI 上即可看到 Delta Join 作业正在正常消费数据。
方式二:手工搭建环境测试
1. 环境准备
- 运行环境:类 Unix 系统,内存 ≥4GB,磁盘 ≥4GB,Java 11+ 并正确设置
JAVA_HOME。
- 准备 Apache Flink 2.2.0:
- 从官网下载并解压。
- 修改
./conf/flink-conf.yaml,将 taskmanager.numberOfTaskSlots 设置为 4(默认1)。
- 准备 Apache Fluss 0.8:
- 从官网下载 Fluss 0.8 并解压。
- 下载适配 Flink 2.1+ 的 Fluss 连接器。
- 准备 Nexmark 数据生成器:
- 克隆 Nexmark 项目 master 分支。
- 在项目根目录执行
mvn clean install -DskipTests=true。
- 获取生成的
nexmark-flink-0.3-SNAPSHOT.jar 文件。
2. 服务启动
- 启动 Flink:
- 将 Fluss 连接器 Jar 包和
nexmark-flink-0.3-SNAPSHOT.jar 放入 Flink 的 ./lib 目录。
- 在 Flink 目录下执行
./bin/start-cluster.sh,访问 http://localhost:8081 确认启动成功。
- 启动 Fluss:
- 在 Fluss 目录下执行
./bin/local-cluster.sh start。
3. 运行任务 SQL
-
创建 Fluss 表:
将以下 SQL 保存为 prepare_table.sql,并在 Flink 目录下执行 ./bin/sql-client.sh -f /path/to/prepare_table.sql。
CREATE CATALOG fluss_catalog WITH (
'type'='fluss',
'bootstrap.servers'='localhost:9123'
);
USE CATALOG fluss_catalog;
CREATE DATABASE IF NOT EXISTS my_db;
USE my_db;
CREATE TABLE IF NOT EXISTS fluss_catalog.my_db.bid(
auction BIGINT,
bidder BIGINT,
price BIGINT,
channel VARCHAR,
url VARCHAR,
`dateTime` TIMESTAMP(3),
extra VARCHAR,
PRIMARY KEY (auction, bidder) NOT ENFORCED
) WITH (
'bucket.key'='auction', -- fluss prefix lookup key
'table.delete.behavior'='IGNORE' -- Flink 2.2 delta join 暂不支持消费DELETE
);
CREATE TABLE IF NOT EXISTS fluss_catalog.my_db.auction(
id BIGINT,
itemName VARCHAR,
description VARCHAR,
initialBid BIGINT,
reserve BIGINT,
`dateTime` TIMESTAMP(3),
expires TIMESTAMP(3),
seller BIGINT,
category BIGINT,
extra VARCHAR,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'table.delete.behavior'='IGNORE'
);
CREATE TABLE fluss_catalog.my_db.delta_join_sink(
auction BIGINT,
bidder BIGINT,
price BIGINT,
channel VARCHAR,
url VARCHAR,
bid_dateTime TIMESTAMP(3),
bid_extra VARCHAR,
itemName VARCHAR,
description VARCHAR,
initialBid BIGINT,
reserve BIGINT,
auction_dateTime TIMESTAMP(3),
expires TIMESTAMP(3),
seller BIGINT,
category BIGINT,
auction_extra VARCHAR,
PRIMARY KEY (auction, bidder) NOT ENFORCED
);
-
启动 Delta Join 作业:
将以下 SQL 保存为 run_delta_join.sql,并执行 ./bin/sql-client.sh -f /path/to/run_delta_join.sql。
CREATE CATALOG fluss_catalog WITH (
'type'='fluss',
'bootstrap.servers'='localhost:9123'
);
USE CATALOG fluss_catalog;
USE my_db;
INSERT INTO delta_join_sink
SELECT
auction, bidder, price, channel, url,
B.`dateTime`, B.extra,
itemName, description, initialBid, reserve,
A.`dateTime`, expires, seller, category, A.extra
FROM bid AS B
INNER JOIN auction AS A
ON B.auction = A.id;
在 Flink UI 上确认作业已启动。
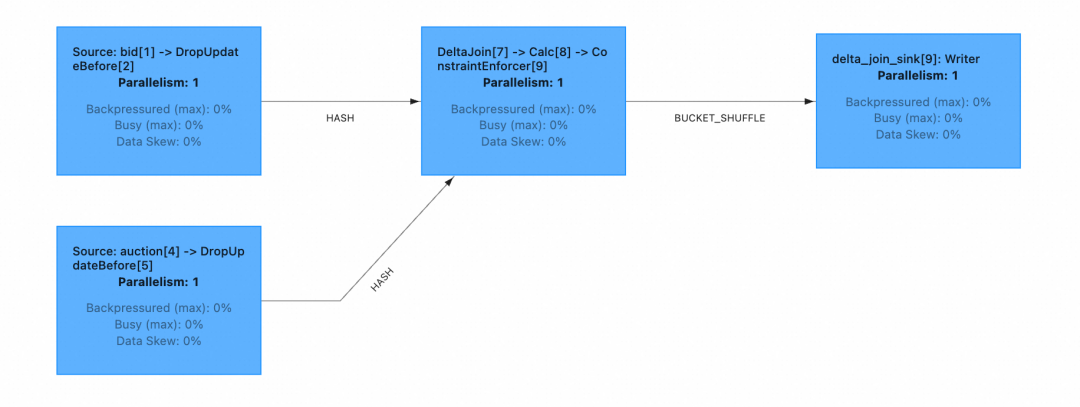
4. 插入数据到源表
将以下 SQL 保存为 insert_data.sql,并执行 ./bin/sql-client.sh -f /path/to/insert_data.sql,启动两个数据注入作业。
(注:此处为节省篇幅,省略了冗长的 insert_data.sql 内容,其核心是创建Nexmark模拟数据源并写入 bid 和 auction 表。)
5. 观察 Delta Join 作业
在 Flink UI 上查看运行的 Delta Join 作业,确认其正在正常消费数据。
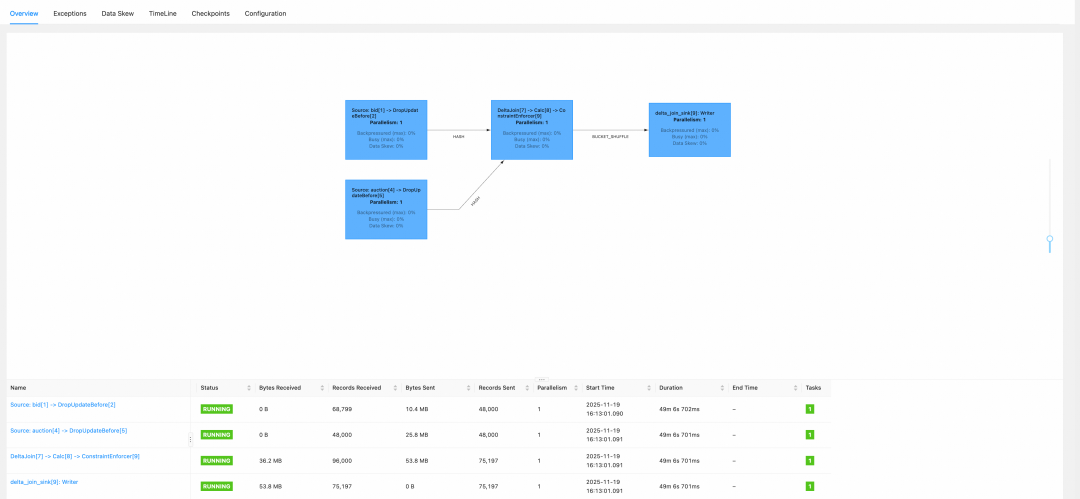
06 现状与未来展望
目前 Delta Join 仍在持续演进中,Flink 2.2 已支持多种常用 SQL 模式,具体可参考官方文档。
未来计划主要围绕以下几个方向推进:
- 完善最终一致性 Delta Join:
- 支持 Left / Right Outer Join。
- 支持消费包含 DELETE 操作的 CDC 源。
- 支持级联(Cascading)Delta Join。
- 探索强一致性方案:结合 Paimon、Iceberg、Hudi 等支持快照的存储引擎,实现分钟级延迟的强一致性 Delta Join。
参考文档
- Apache Flink Delta Join 用户文档
- Apache Flink Delta Join FLIP-486
- Apache Fluss Delta Join 用户文档
 发表于 2025-12-19 02:42:18
|
查看: 286|
回复: 0
发表于 2025-12-19 02:42:18
|
查看: 286|
回复: 0
