一、为什么我们需要湖仓一体?—— 一个真实的业务痛点
场景:某电商平台实时用户行为分析
- 旧架构:
- 离线数仓:Hive + Spark,T+1 产出用户画像、GMV 报表;
- 实时链路:Kafka + Flink → 实时大屏(仅展示最近1小时行为);
- 核心问题:
- 数据割裂:无法联合分析“过去24小时”用户行为路径;
- 运维复杂:两套存储(HDFS + Kafka)、两套计算(Spark + Flink);
- 成本高:实时状态存储无法复用离线特征。
诉求明确:一份存储,同时支撑批处理(T+1报表)和流处理(实时推荐),且保证读写一致性。
这正是湖仓一体(Lakehouse)的核心价值——在对象存储(如 S3/OSS)上构建兼具数据湖灵活性与数仓 ACID 能力的统一底座。
二、我们的实践流程:从 Hive 数仓到 Iceberg 湖仓
我们选择 Apache Iceberg(理由见第三节),迁移采用 双写过渡 + 增量切换 策略:
Step 1:存量表迁移(Hive → Iceberg)

注意:不直接 ALTER TABLE,避免影响线上任务;先双写验证数据一致性。
Step 2:新链路接入(Flink 实时写入 Iceberg)
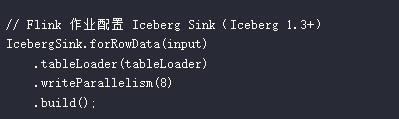
- 关键配置:
- 开启 equality-delete 支持 CDC 更新(如用户标签变更);
- 分区策略:按 event_time 小时分区,平衡查询性能与小文件数量。
Step 3:统一查询入口
- BI 工具 → Trino → Iceberg(交互式查询);
- ETL 任务 → Spark → Iceberg(批处理);
- 结果:同一张 user_behavior_iceberg 表,既可查 T+1 全量,也可查近1小时实时行为。
三、架构选型:Iceberg vs Delta Lake vs Hudi(2026年视角)
| 维度 |
Apache Iceberg |
Delta Lake |
Apache Hudi |
| ACID 支持 |
强(基于快照) |
强(基于事务日志) |
强(基于 timeline) |
| 流批统一写入 |
强(Flink/Spark 成熟) |
(Flink 生态支持仍在演进中,大规模生产落地案例少于 Iceberg) |
强(Flink 原生支持强) |
| Schema Evolution |
强(列级变更) |
强 |
强 |
| Time Travel |
强(快照回溯) |
强 |
强 |
| 社区 & 生态 |
中立(Netflix/Apple 主导) |
Databricks 绑定 |
Uber 主导,阿里云深度集成 |
结论:
- 若 强依赖 Databricks + Spark -> 选 Delta;
- 若 需 Flink 实时写入 + 多引擎(Trino/Spark/Presto)查询 -> Iceberg 更开放;
- 若 高频更新(如 CDC)且接受 MOR 模型 -> Hudi 是优选。
四、避坑指南:这些坑我们都踩过
坑1:小文件爆炸(尤其 Flink 流式写入)
- 现象:每分钟生成数百个小文件,查询性能暴跌;
- 解法:
- 定期执行 compaction(Iceberg)或 clustering(Delta);
- Flink 写入时设置 write.distribution-mode=hash + 合理并行度(建议 ≤ 分区数)。
坑2:元数据膨胀(快照过多)
- 现象:metadata/ 目录 GB 级增长;
- 解法:定期清理快照(保留7天):

坑3:分区设计不合理
- 错误:对 高基数字段(如亿级 user_id) 直接分区 → 分区数爆炸;
- 正确:按 时间(天/小时) + 低基数维度(如 country, channel) 分区。
五、性能优化:让湖仓真正“快”起来
1. Z-Ordering(Iceberg) / Data Skipping(Delta)
重要说明:Iceberg 不支持 WRITE ORDERED BY(这是 Delta 语法)!
Iceberg 正确用法(Spark 3.2+):
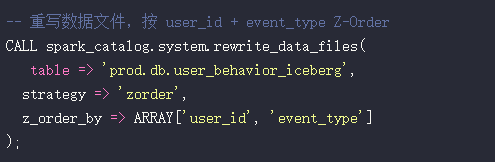
效果:WHERE user_id='xxx' AND event_type='click' 查询跳过 80% 文件,提速 5x+。
注意:Z-Order 重写是 计算密集型操作,建议在业务低峰期执行,并监控 Spark 资源消耗。
2. 缓存层加速
- 对高频表,用 Alluxio 缓存热数据到内存/SSD;
- Trino 开启
hive.cache.enabled=true(针对 S3/HDFS)。
3. 计算下推(Predicate Pushdown)
- 确保查询引擎能将过滤条件下推至 Iceberg 元数据层;
- 验证方式:
EXPLAIN 查看是否显示 num files skipped。
六、未来展望:湖仓一体不是终点
1. 向量湖仓(Vector Lakehouse)
Iceberg 社区正在探索向量索引支持,部分商业发行版(如 Tabular)已提供实验性能力。未来可直接在湖上跑 AI 推理。
2. Serverless 化
AWS Athena / BigQuery Omni 将湖仓能力封装为服务,运维成本趋近于零。
3. 统一 Catalog
Apache Nessie / AWS Glue Data Catalog 正成为跨引擎元数据的事实标准。
但请清醒:
湖仓一体 不能替代数仓建模,也不能解决 脏数据、业务逻辑混乱 等根本问题。
它只是让“好的数据架构” 更容易实现。
结语:务实者的选择
湖仓一体不是魔法,而是一套工程权衡后的技术方案。
如果你正面临:
- 实时与离线数据割裂;
- 运维多套存储成本高;
- 需要强一致性与灵活 Schema;
那么,从一张 Iceberg 表开始尝试,比等待“完美架构”更重要。
最后提醒:
技术选型没有银弹,只有“当下最合适”。
评估清楚团队技能、业务规模、长期成本,再行动。
希望这篇关于 Apache Iceberg 构建湖仓一体的实践分享,能为你带来启发。如果你在数据架构方面有更多想法或问题,欢迎在云栈社区的大数据技术论坛中进行交流探讨。 |  发表于 2026-1-15 05:19:34
|
查看: 228|
回复: 0
发表于 2026-1-15 05:19:34
|
查看: 228|
回复: 0
