随着各类智能体在应用场景的加速落地,2025年正被视为“智能体元年”。在这一背景下,应用形态飞速迭代,驱动业界重新审视大模型能力的来源。单纯依赖预训练堆叠数据和算力已难以拉开代际差距。与应用热潮同步升温的,是基础设施层面的强化学习技术。
大模型的竞争焦点正逐步从预训练转向后训练:如何让模型不仅能“说话”,更能在复杂任务中“思考、决策与自我纠错”?强化学习提供了一条可规模化的路径。但现实是,大模型的强化学习训练早已不是运行一个脚本那么简单——它更像是一项推理系统与训练系统深度耦合的复杂系统工程,需要在生成阶段榨干吞吐,在训练阶段承受沉重的反向传播与通信开销,最终演变为一门真正的分布式系统工程。
01 从 RLHF 到 RLVR
预训练像是“把百科全书背进脑子”,监督微调像是“统一答题格式”,而强化学习则更像“刷题 + 复盘”:训练越多、复盘越深刻,模型越可能学会将推理步骤当作一种可迁移的技能。但前提是,你必须首先明确强化学习的奖励信号来自哪里——奖励信号的性质将直接决定你系统的形态。本节将探讨强化学习奖励的来源及其核心算法。
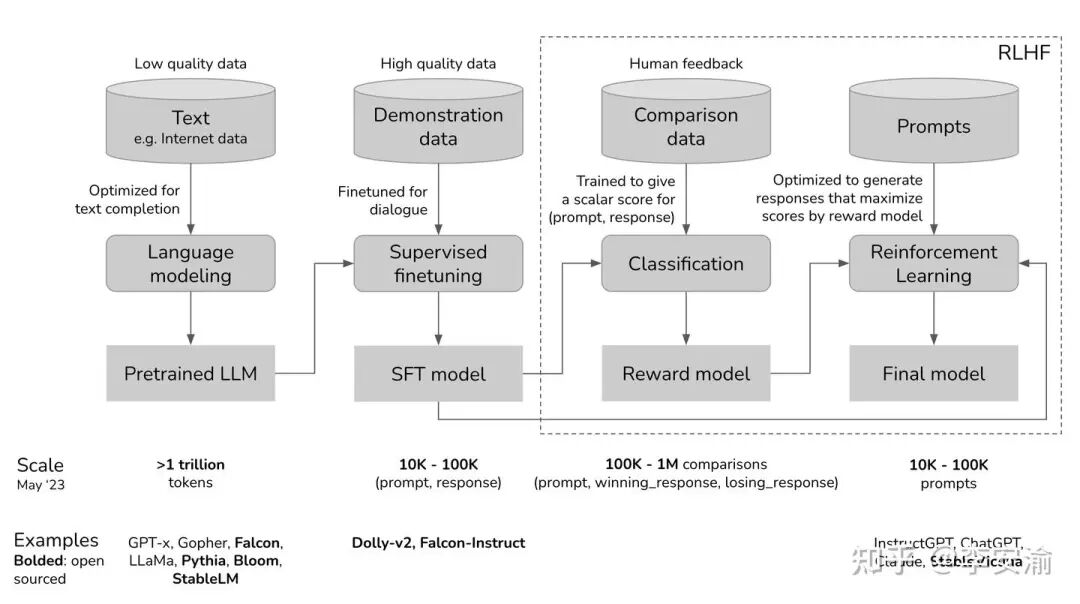
1. 三件套:SFT / RLHF / RLVR
监督微调 (Supervised Fine-Tuning, SFT):作为“监督”学习,这一阶段需要带“标签”的数据。在大模型领域,这类数据通常被称为指令跟随数据 (Instruction-Following Data) 或示范数据,常见格式为 [x, y]:
- x: Prompt / 指令 (可能包含上下文、角色设定、工具状态等)
- y: Response / 示范答案 (可以是自然语言,也可以是代码、JSON、工具调用等结构化输出)
一句话概括,SFT的目的就是把预训练阶段“会接龙”的模型,通过高质量示范,收束成一个“会按指令办事”的模型。因为在预训练阶段,大语言模型主要学习对海量文本分布的拟合,但并不天然知道用户期待的回答形态和任务意图。
从优化目标来看,SFT本质上仍是条件语言建模的最大似然训练:最大化示范答案在模型下出现的概率 maxθ∑E(x,y)~DsFT[logπθ(y|x)],等价地也可以写成最小化负对数似然损失 L_SFT(θ)=-E_{(x,y)∼D_SFT} [logπ_θ(y|x)]。由于高质量指令数据获取成本高,完成这一阶段后得到的模型通常称为 SFT Model,它不仅为后续强化学习提供了一个“已经比较像样”的策略起点,还常被作为冻结的参考策略 π_{ref},用于后续强化学习阶段的 KL 约束,以保持输出分布稳定,避免策略更新跑偏。
基于人类反馈的强化学习 (RLHF):一句话概括,RLHF 先用人类偏好训练一个“打分器”,再用强化学习让模型最大化这个分数,同时用 KL 约束把模型“拽住”。
既然已经有了监督微调阶段,为什么还需要基于人类反馈的阶段呢?这是因为 SFT 提供给模型的是“示范答案”,但在现实中,“好答案”并不唯一。对于很多开放式任务,存在大量同样合理的回答方式。SFT 往往只拟合了数据中的某种“写法”,在复杂场景下可能不够灵活。
RLHF 的核心优势在于:让模型先采样多个可能的回答进行探索,再由偏好模型告诉它“哪个更好”,从而获得更细粒度的学习信号。在实践中,经常看到 SFT + RLHF 的效果优于单纯 SFT。SFT 让模型“像样地回答”,RLHF 则让模型“更符合人类偏好”。
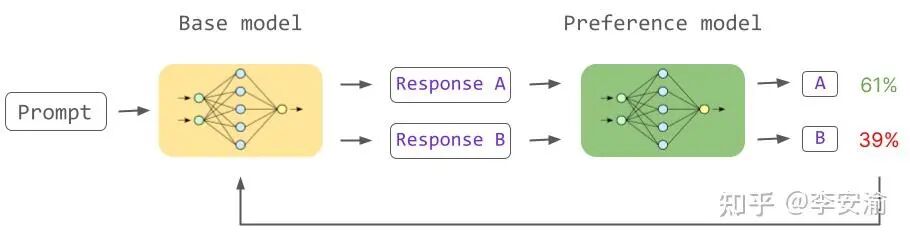
RLHF 的标准流程分为两步:
- 训练奖励模型 (RM):RM 的输入是一段文本 (prompt + response),输出是一个标量分数。偏好数据通常是三元组
(x, y+, y-),表示对于同一个 prompt,大家更喜欢 y+ 这个答案。常见的 RM 训练目标为:L_RM(φ)=-E(x,y+,y-)[logσ(rφ(x,y+)-rφ(x,y-))]。直观理解是希望 RM 让“更受偏好”的回答得分更高。工程上,RM 往往用 SFT 模型拷贝一份初始化参数,以保证具备与 Actor 相当的语言理解能力。
- 更新 Actor 模型:给定 prompt,当前策略
πθ 采样得到回答,RM 给出分数 r_{φ}(x,y)。我们希望更新 πθ,让期望得分更高,具体算法会在下一节详述。
具有可验证奖励的强化学习 (RL with Verifiable Rewards, RLVR):可以理解为后训练流程中新增的一块“硬信号”:在数学、代码等可验证环境中,模型生成回答后可以用规则、标准答案、判题器或单元测试自动判定对错,从而得到更稳定的奖励 r(x, y)。
相比 RLHF 依赖人类偏好训练出来的奖励模型,RLVR 的奖励更“客观”、更容易规模化。因此,可以把大量算力投入到更长时间的在线强化学习与更大规模的生成上,让模型在持续试错中自发形成更可靠的推理策略,从而涌现出思维链。从优化形式上看,RLVR 和 RLHF 类似,都是最大化奖励并用 KL 正则把策略“拽住”,只不过这里的 reward 来自可验证函数而非 RM:maxθℰ[r(x,y)]−βℰ[KL(πθ‖πref)]。
同时,RLVR 还带来一个新的“调参维度”:通过生成更长的推理轨迹、投入更多“思考token”,往往能进一步提升任务通过率——这也是推理模型与传统指令模型在体验上拉开差距的关键之一。若想了解更多关于强化学习和微调的最佳实践,可以参考 人工智能 板块的讨论。
02 RL算法
前面提到了 RLHF 中需要更新 Actor 模型 πθ(y|x),那么具体如何更新呢?这就涉及到各种更新算法,即如何利用采样样本,进行稳定、可重复、多轮迭代的策略更新。
1. PPO (Proximal Policy Optimization)
PPO 是一种具体的、基于策略梯度的强化学习优化算法。
- On-Policy / Near On-Policy:通常采用“采样一批轨迹 → 对这批数据做多轮小批量更新”的交替流程。
- Actor-Critic:需要同时训练策略网络和价值网络,用 value 作为 baseline 来计算优势函数、降低梯度方差。
PPO 的核心思想是:可以用旧策略 πθ_旧 采样出一批数据,然后对新策略 πθ 做多轮小批量更新,但每一步更新都不能离旧策略太远。PPO 用一个重要性采样比值来衡量“新旧策略差多少”:ρt(θ)=πθ(at|st)/πold(at|st)。
通过截断操作限制每次参数更新的幅度,从而间接约束策略更新的激进程度、防止训练不稳定:𝒮_PPO(θ)=∑t[min(ρt(θ)At,clip(ρt(θ),1-ε,1+ε)At)]。这里的 At 是优势函数,衡量“这个动作相对 baseline 的好坏”(常见做法是 A_t=\hat{R}_t-V_φ(s_t) 或用 GAE 来估计)。
2. GRPO (Group Relative Policy Optimization)
在 InstructGPT 时代,RLHF = SFT + RM + PPO。但在推理或 RLVR 这类序列级奖励更常见的设置里,训练一个能在每个 token 上都稳定工作的价值函数既昂贵又困难。
因此,一些研究工作提出了用 GRPO 作为 PPO 的变体:保留 PPO 风格的近端更新,但用“组内相对优势”替代 critic 估计的优势函数,从而显著降低训练侧的负担。GRPO 的出发点非常直接:对同一个 prompt 采样一组答案 {y_i}_{i=1}^G,得到对应的奖励 reward{r_i},然后把每个样本的优势设为组内归一化的相对收益:∧i=ri−mean(r)std(r)+ε。
接下来更新策略时,仍然使用 PPO 风格的截断目标函数,只是优势不再来自 critic,而来自组内相对比较。这就是 GRPO 能显著降低训练侧负担的根本原因:省掉了价值函数的训练与通信成本,把压力更多推给了生成阶段(需要更大组、更高并发采样)。这一点在 DeepSeek-Math 等工作中被明确提出:GRPO 是 PPO 的变体,核心是“组相对优势”替代 value function。
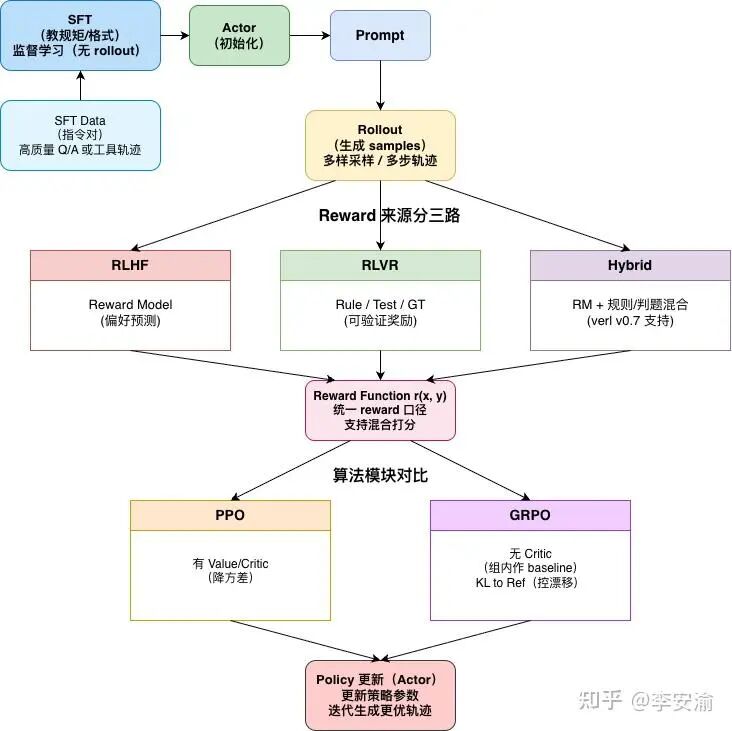
所以,结合上两节的内容,模型后训练时的数据流大致如下图所示:
03 Infra 的核心挑战:精神分裂的“混合负载”
如果说预训练是一台稳定运转的“重型压路机”,那 RL 训练更像一条随时变速的生产线:同一个模型在一个循环里要反复扮演两种角色——生成时像线上服务一样疯狂输出 token,训练时像预训练一样做重反传、重通信。
这就是所谓的混合负载,也是强化学习基础设施真正的难点来源:你不是在优化一个系统,而是在优化两个系统之间的切换成本和流水线效率。
先看 Rollout (生成) 阶段。它本质上是推理工作负载,目标是把吞吐榨干:需要尽可能高并发地生成样本,通常还要进行带温度的采样、生成更长的推理轨迹、甚至对同一个 prompt 采样一组候选。
- 任务:模型扮演“考生”,疯狂做题。
- 关键技术:KV Cache、动态批处理、张量并行。
- 引擎选择:vLLM、SGLang 等。
在这一侧,显存里最“值钱”的东西不是优化器状态,而是 KV Cache:它会随着并发数和生成长度线性增长,直接决定 token/s 的吞吐量。因此推理引擎更倾向于采用服务化架构,把动态批处理、KV 管理以及推理并行做到极致。
但 Train (训练) 阶段完全是另一个世界。它是训练工作负载,显存里更“沉”的是参数、梯度、优化器状态(再加上长序列下的激活值)。训练引擎会倾向于使用 ZeRO-3 / FSDP 这类切片策略,把参数、梯度和优化器状态分散到多卡上,靠重度通信换取可训练的模型规模。
- 任务:模型扮演“学生”,根据错题本更新脑子。
- 关键技术:反向传播、优化器状态、ZeRO-3 / FSDP。
- 引擎选择:PyTorch 生态(如 Megatron, DeepSpeed, FSDP)。
同一个模型,在这两种阶段的“权重布局/并行形态”往往不一致。训练侧常以 ZeRO/FSDP 为核心做切片,推理侧常以 TP/PP 为核心追求算子效率与稳定吞吐。于是,每次从训练切换到生成,都面临一个本质问题:模型权重到底以什么布局存在?如果布局不一致,就不可避免要经历一次重分片/参数同步/权重广播。
此外,混合负载还会带来一个典型的调度难题:生成阶段存在长尾。同一批 prompt 里,有的样本很快结束,有的则因长推理链路而耗时很久。如果采用同步训练,训练端经常会因为等最慢的那几个生成样本而空转;如果改成异步让生成和训练流水线并行,又会引入新的系统复杂度。也就是说,同步会浪费吞吐,异步会增加复杂度。
因此,强化学习基础设施的本质不是单纯训练,而是把推理系统和训练系统无缝拼接成一条高效的流水线。
04 verl——把“推理系统 + 训练系统”粘成一条流水线
前面说过:强化学习基础设施的本质不是“把训练写得更快”,而是把推理系统和训练系统拼成一条不漏水的流水线。一个值得关注的开源项目 verl 正是在做这件事——它不强行把训练和推理揉成同一种并行形态,而是承认二者天然不同:训练侧擅长重反传+重通信,推理侧擅长高吞吐+长尾调度。
verl 的价值在于:在两套系统之间搭建“桥梁”,把最棘手的数据流和参数流连接起来,同时将长尾生成阶段的吞吐问题纳入系统设计。其架构分为两层:底座是 verl-core (四大组件),上层是 verl-trainer (把组件拼成 on-policy / one-step-off-policy / fully async 等流水线)。
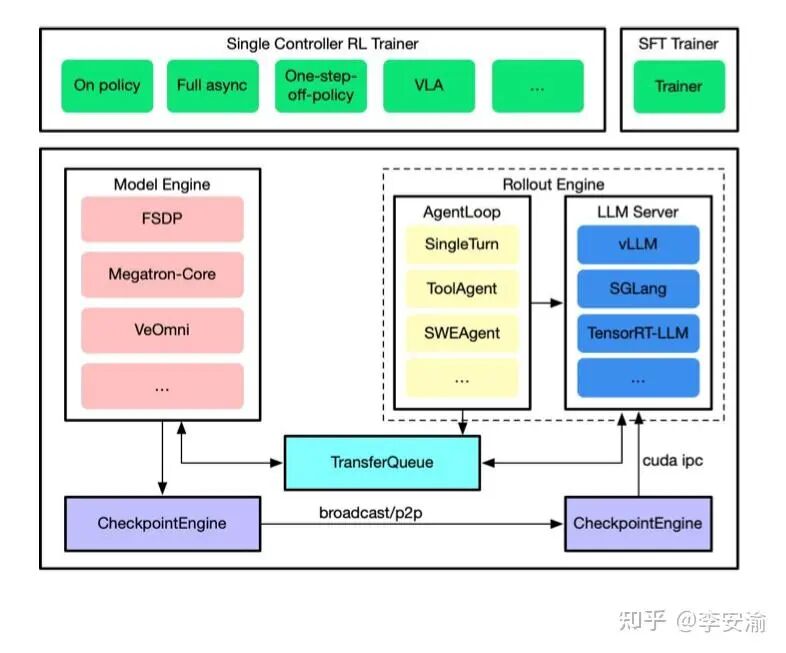
落到实现,verl-core 的“四大金刚”可以这样理解:
- Model Engine (炼丹炉):把训练侧后端封装成统一接口,屏蔽 FSDP/并行切片/通信细节,让上层训练器关注“强化学习控制逻辑”而不是“训练工程细节”。
- Rollout Engine (加特林):把推理侧做成更接近服务端的形式,并通过
AgentLoop 把“单轮生成/多轮推理/工具调用”这些生成控制逻辑收敛成可复用的循环。
- TransferQueue (物流枢纽):这是体现“工业味”的关键。它重点解决的是数据流:把生成阶段产生的轨迹、对数概率、奖励等训练数据稳定、高吞吐地送到训练侧,同时避免“所有数据都绕过单点控制器”导致的瓶颈。你可以把它当成强化学习流水线里的“传送带 + 缓冲仓”,负责削峰填谷、解耦长尾。
- Checkpoint Engine (参数流阀门):在训练与生成物理分离之后,最困难的是参数流:训练侧更新得很快,但生成侧必须持续拿到足够新的策略参数。
verl 把这件事抽象成可控的同步/传输机制,让“参数更新”变成持续流动。
当这四个组件齐备,verl-trainer 才能拼出不同的运行形态:同步 on-policy(简单但易被长尾拖慢)、one-step-off-policy(用“一步陈旧”换吞吐)、fully async(把生成器与训练器彻底解耦,数据流走 TransferQueue 不间断,参数流走 CheckpointEngine 持续更新)。
最后提醒一个常见误区:更清晰的区分轴是 同位切换 vs 资源池分离。前者节省带宽但切换成本高;后者能流水并行、吞吐更高,但需要更强的参数同步与队列治理。verl 的核心贡献,就是把这条权衡做成了工程化的可选项。对这类 开源实战 项目的深入解析,有助于我们更好地理解系统设计。
05 性能优化:对抗“长尾效应”的黑科技
随着 GRPO / RLVR 对生成吞吐的要求越来越高,生成阶段正在成为端到端迭代里的最大瓶颈。更麻烦的是,长思维链训练会放大典型的长尾轨迹问题:同一批请求里,响应长度差异巨大,最终导致大量 GPU 空转。
在强化学习工作负载中,生成阶段可能占到单步迭代时间的 60% 到 90% 以上。本节聚焦两类系统级解法,它们共同利用一个被长期忽视的事实——训练相邻步骤/轮次的输出“会押韵”:对同一提示,新旧策略生成的响应在 token 序列上高度相似,统计显示可复用 token 比例可达 75%–95%。
两条优化路线:
- 投机式生成 (Speculative Rollouts):复用历史 token,减少“重复生成”。
- 切分与调度 (Divided Rollout / Length-aware Scheduling):把长尾拆开、把负载抹平,减少“等待气泡”。
投机采样在服务场景称为投机解码;将其引入强化学习,本质是:不要每一轮都从零生成整条轨迹,而是把历史轨迹当作“草稿”,当前策略只做验证和少量续写。
SPEC-RL (Speculative Rollouts) 将投机解码的“草稿-验证”机制引入了强化学习的生成阶段:它复用上一轮的轨迹片段作为推测前缀,再由当前策略并行验证;一旦遇到第一个不一致的 token,就保留已验证前缀并从该位置开始续写,从而避免大量重复生成。
- 核心机制:草稿与验证
- 草稿:上一轮(旧策略)产生的轨迹片段。
- 验证:当前策略对草稿做并行概率计算,确定可接受的前缀;从第一个拒绝处继续生成。
SPEC-RL 报告在多个基准上生成时间可降低 2–3 倍,且不牺牲策略质量;并且它作为“纯生成阶段增强”,可以无缝接入 PPO/GRPO 等主流算法。
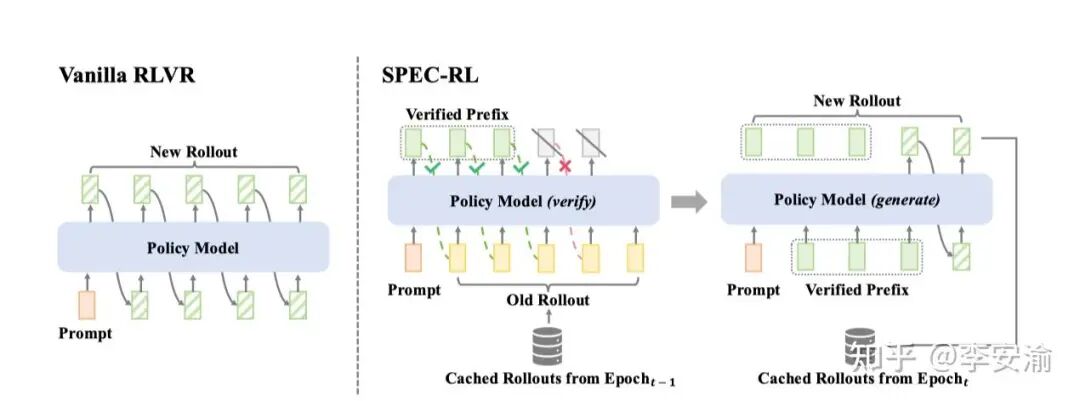
SPEC-RL 是基于 verl 框架进行开发的,这凸显了拥有一个良好抽象的基础设施对于快速实现和验证前沿优化思想的重要性。深入理解这类框架的组件和代码,对于构建高效的大模型训练系统至关重要。更多相关的 技术文档 和架构设计讨论,可以在技术社区中找到。如果你对AI基础设施、智能体等话题感兴趣,欢迎到 云栈社区 与其他开发者交流探讨。
 发表于 2026-1-15 05:24:21
|
查看: 163|
回复: 0
发表于 2026-1-15 05:24:21
|
查看: 163|
回复: 0
