随着大模型在各行业的广泛应用,推理阶段的效率瓶颈日益凸显。Transformer架构的自回归机制与长上下文需求,共同将压力指向了KVCache——这项“以存代算”的关键技术,在加速推理的同时也带来了巨大的显存开销。当GPU算力不再是唯一瓶颈,如何从根本上优化数据流转与计算冗余?
业界普遍采用稀疏注意力等算法进行优化,但大多聚焦于计算层本身。华为开源的UCM则提供了一条系统级的解题思路。它不仅引入几何稀疏注意力算法,更在系统IO和调度策略上进行了深度创新,旨在重新定义AI推理的效能边界。本文将深入剖析其背后的三大核心技术。
掌握核心要点
- 系统级稀疏化新思路:理解GSA算法如何超越传统稀疏注意力,通过块表征与系统IO协同,优化KVCache在存储层级间的流动效率。
- KVCache重用与加载技术:学习“自适应渐进式重算”如何精准修复位置编码偏差,以及“KV Cache直通HBM”机制如何通过零拷贝和计算加载交叠隐藏IO延迟。
- 投机推理创新路径:了解PMR-Tree后缀检索如何用“记忆检索”替代部分“模型计算”,并通过算力感知的动态规划解决高并发加速失效问题。
UCM的代码已开源在Github,从提交记录来看,项目保持活跃更新。
在深入其核心技术前,有必要先了解行业对推理场景的基本共识。
从标准注意力到稀疏注意力机制
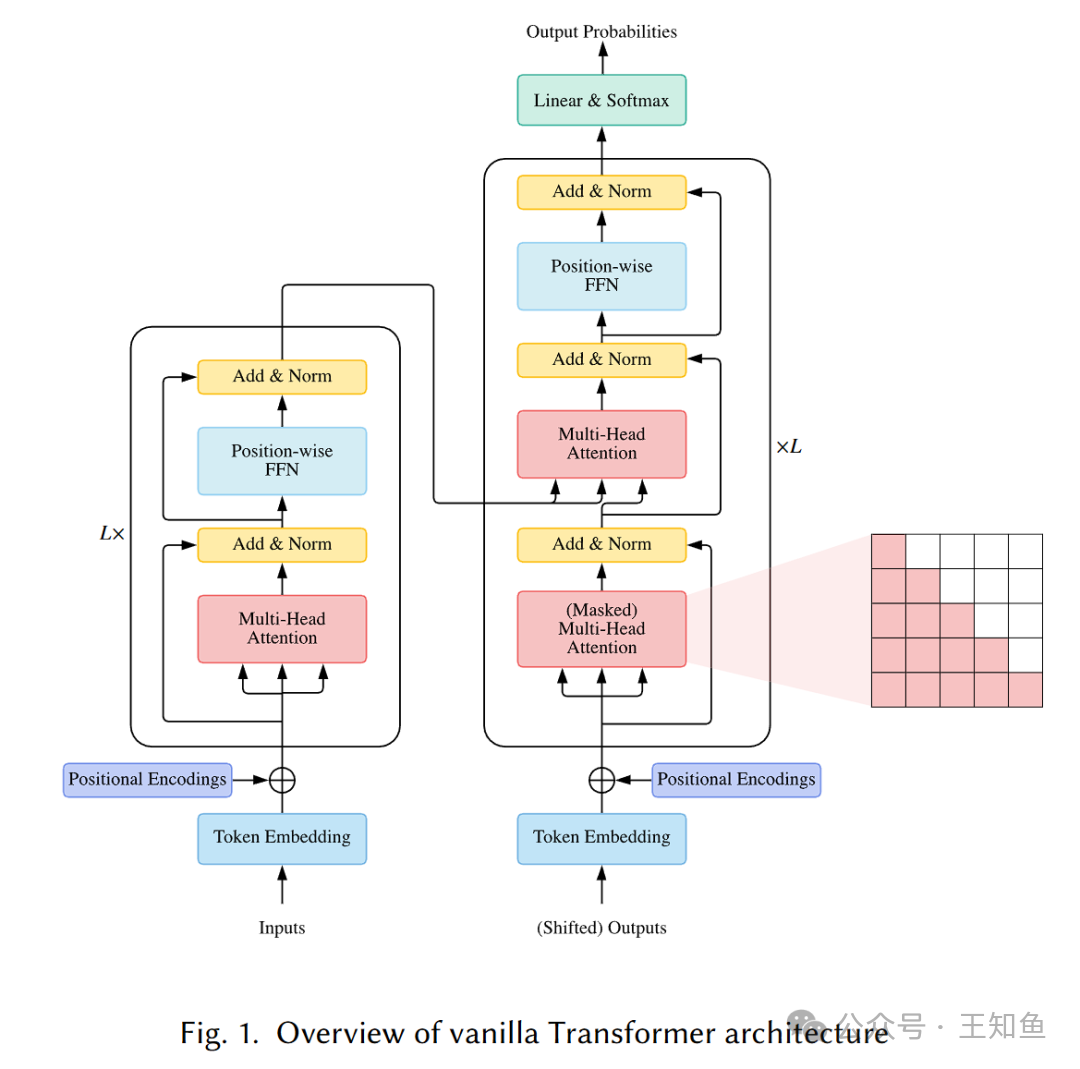
标准的Transformer注意力机制计算和空间复杂度随序列长度呈平方级增长,对算力与显存需求极高,难以直接商用。因此,稀疏注意力成为推动AI应用落地的关键技术。
稀疏注意力通过引入“归纳偏置”,打破了“全体都算”的模式,其主要优势包括:
- 计算效率提升:将复杂度从平方级降至近线性,使长序列处理成为可能。
- 硬件资源消耗降低:无需生成完整注意力分数矩阵,大幅减少GPU显存占用。
- 缓解内存带宽瓶颈:减少GPU在HBM和SRAM间搬运全注意力矩阵的数据I/O,提升运行速度。
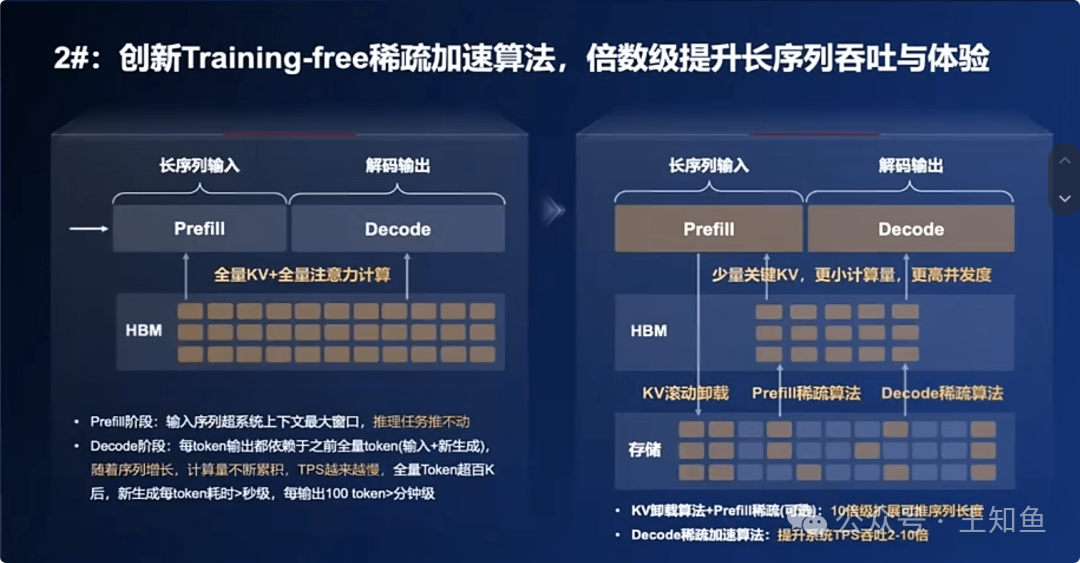
大语言模型以自回归方式生成文本,即基于已生成的所有token,一次只生成下一个token。这造成了严重的串行瓶颈。就像砌墙,必须等前一块砖砌好才能砌下一块,尽管GPU拥有强大并行能力,却被迫进行序列化等待,在生成长文本时效率低下。
KVCache:以存代算的经济价值
KVCache是一种推理时优化技术,核心目标是加速自回归生成过程。
- 解决的问题:避免为生成第
t 个token而重复计算前 t-1 个token的Key和Value向量。
- 工作原理:“计算一次,处处使用”。将已计算的K、V向量缓存在GPU HBM中,生成新token时只需计算其Q、K、V,并与Cache中的所有历史K、V进行注意力计算。
- 效果与代价:将生成时间复杂度从 O(n²) 降至 O(n),但不断增长的Cache本身也成为了长上下文推理的新显存瓶颈。
了解以上背景后,我们来看UCM的创新思路。
GSA:几何稀疏化推理加速算法
推理稀疏化算法的演进
稀疏化优化经历了多个阶段的演进:
- IO/内存优化(奠基):如FlashAttention、xFormers,优化HBM与SRAM间的数据访问,不减FLOPs,为后续优化提供底层基础。
- KV Cache结构稀疏(早期工程化):如vLLM的PagedAttention、滑动窗口KV,优化Key/Value的存储,减少内存使用,但不改动QK计算逻辑。
- Attention算后稀疏:如Top-K裁剪,需先算完整QKᵀ再裁剪,计算效率提升有限。
- Query驱动算前稀疏(先进):如QUEST,直接针对QK内积计算进行优化,首次在FLOPs级别实现减法。
GSA的由来与优势
GSA属于广义的“结构稀疏化”,但进行了关键创新:
- 继承与融合:承袭了按块结构对齐和动态自适应的思路。
- 系统级协同:提出几何块表征+KV Cache压缩协同稀疏化,针对“外存<->显存”数据流动瓶颈与精度损失,以系统级稀疏和推理效率为目标。
- 核心机制:
- 块内表征:使用最大范数选取重要token,再用SVD进行信息概括,兼顾稀疏与表征质量。
- 流动优化:通过块级几何表征结合卸载与预取算法,物理减少需要搬运的数据量,优化KVCache在存储层级间的流动。这种对系统IO的深度优化,是云原生/IaaS时代软硬件协同思维的体现。
- 自适应策略:支持根据高延迟或高并发等不同场景,灵活切换稀疏化与缓存复用模式。
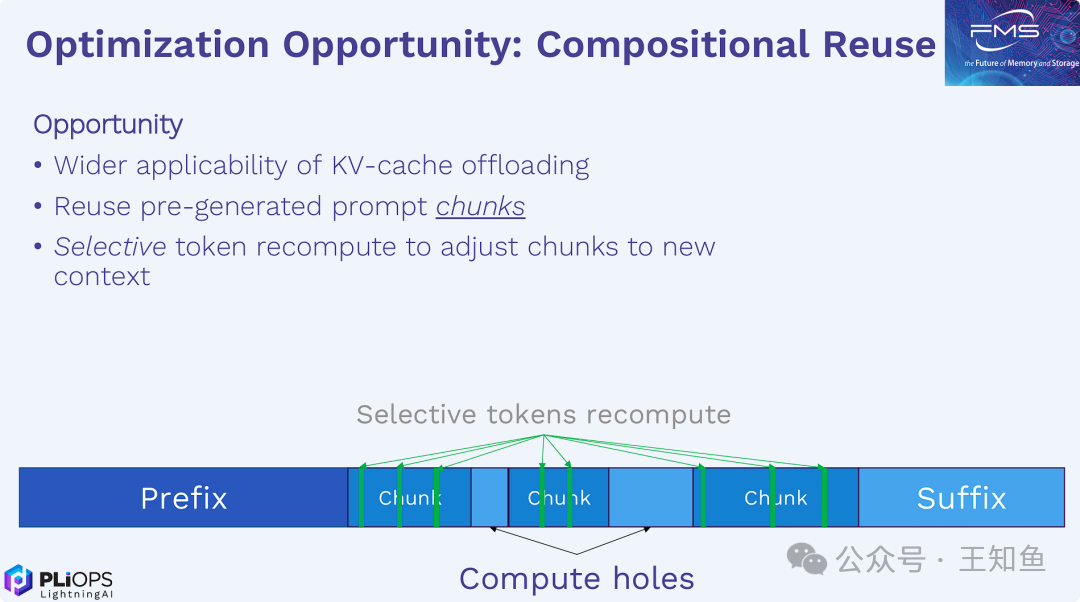
KV Cache重用技术
提高已生成KVCache的利用率是提升长上下文推理效率的关键。UCM在现有片段重用基础上进行了改良。
自适应渐进式重算
重用KV Cache时,拼接新输入会导致位置编码偏差。UCM通过动态评估token级KV漂移程度,决定分层、按需的重算比例。
- 渐进式:靠近输入层的网络,对位置敏感,重算比例高;靠近输出层的网络,更关注抽象语义,对精确位置不敏感,重算比例递减。这是计算资源的最优分配。
- 自适应:为每个token评估“KV漂移程度”,仅对超过设定阈值的偏差进行补算,实现精准修复,避免算力浪费。
KV Cache 直通 HBM 的加载-计算交叠
传统方案数据加载路径长、延迟高。UCM的创新机制包含两方面:
- 零拷贝直通HBM:允许KV Cache数据从外存(如SSD)通过PCIe直接传输至GPU HBM,绕过CPU内存中转,缩短路径,降低延迟。
- 加载-计算交叠流水线:在算子内部,当计算第
i 层注意力时,系统并行预取第 i+1 层所需的KV块。将数据加载耗时隐藏在计算耗时中,让GPU计算单元持续工作。

这项技术深度优化了数据从存储到计算单元的路径,是解决网络/系统层面IO瓶颈的典范。
PMR-Tree:后缀检索预测加速算法
为打破自回归的串行瓶颈,业界发展了投机推理技术:先用快速方法生成一个未来token的“草稿”序列,再由主模型一次性并行验证。UCM的PMR-Tree为生成“草稿”提供了高效的内存检索方案。
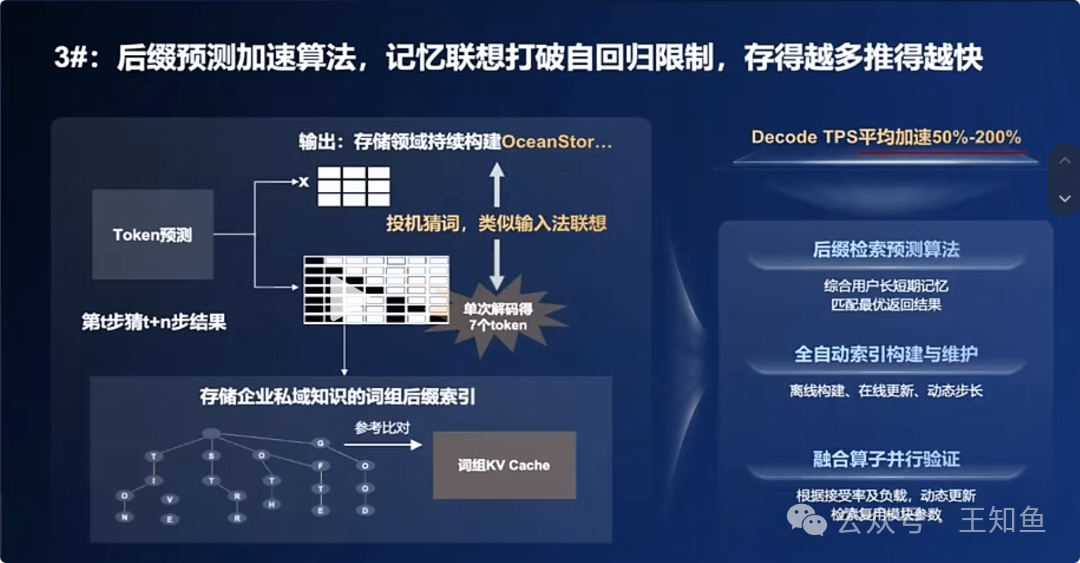
工作原理:从记忆中检索“猜测”
- 构建记忆体:系统持续观察处理中的文本,构建可搜索的PMR-Tree索引,存储大量文本序列及其常见后缀。
- 实时检索:在生成过程中,根据已产生的序列实时查询记忆树。
- 生成与验证:若找到匹配历史,则检索出的后缀作为高概率“草稿”提交给主LLM进行一次性并行验证。
UCM的三大创新点
针对现有方案“粗放、冗余、高并发下失效”的痛点,UCM进行了如下优化:
- 更智能的PMR字典树:利用多源数据(私域知识、模型响应)构建,记录失败经验优化检索,增加KV语义、时间等多维度元数据,提升匹配精度。
- 层次化检索策略:采用“粗筛精排”流程,先快速过滤,再对少数候选精细打分,降低无效计算,提交高质量草稿。这种基于特征的检索与排序策略,在人工智能的检索增强生成领域具有通用价值。
- 算力感知的动态规划:系统动态感知GPU负载,根据并发量为每个请求动态调整“猜测”token的预算。高并发时减少预算保证稳定性,低并发时增加预算最大化加速,确保高并发下仍有稳定加速收益。
总结与思考
UCM开源的核心价值在于为计算与存储生态提供了一个协同优化AI推理的合作平台。其强调算法与系统(如IO路径、内存管理)的深度协同,指向了未来AI推理优化的重要方向——软硬件一体化的系统级工程。
延伸思考:
- 未来AI推理优化的主要突破点,将更依赖于纯粹的算法创新,还是软硬件一体化的系统级工程?
- 在真实生产环境中,如何为不同业务(如实时对话、文档摘要)找到“自适应渐进式重算”等动态策略的最佳参数平衡点?
- PMR-Tree构建的“长时记忆”系统,在处理动态或私域知识时,可能面临哪些数据一致性、安全性和管理挑战?
|  发表于 2025-12-19 16:45:01
|
查看: 302|
回复: 0
发表于 2025-12-19 16:45:01
|
查看: 302|
回复: 0
