
量化投资公司Ariste AI的业务涵盖自营交易、资产管理及高频做市。在量化交易研究中,数据读取速度与存储效率是决定研究迭代效率的关键。团队在构建基础设施时,面对总量超500TB的行情与因子数据,经历了从本地盘到最终选择“JuiceFS文件系统 + MinIO对象存储”的四阶段演进,通过缓存与分层架构实现了数据的高速访问与集中管理,为行业提供了可行的参考方案。
量化投资存储的核心挑战:规模、速度与协作
量化流程通常包含数据层、因子与信号层、策略层及执行层,构成完整闭环。在此过程中,存储系统面临三大挑战:
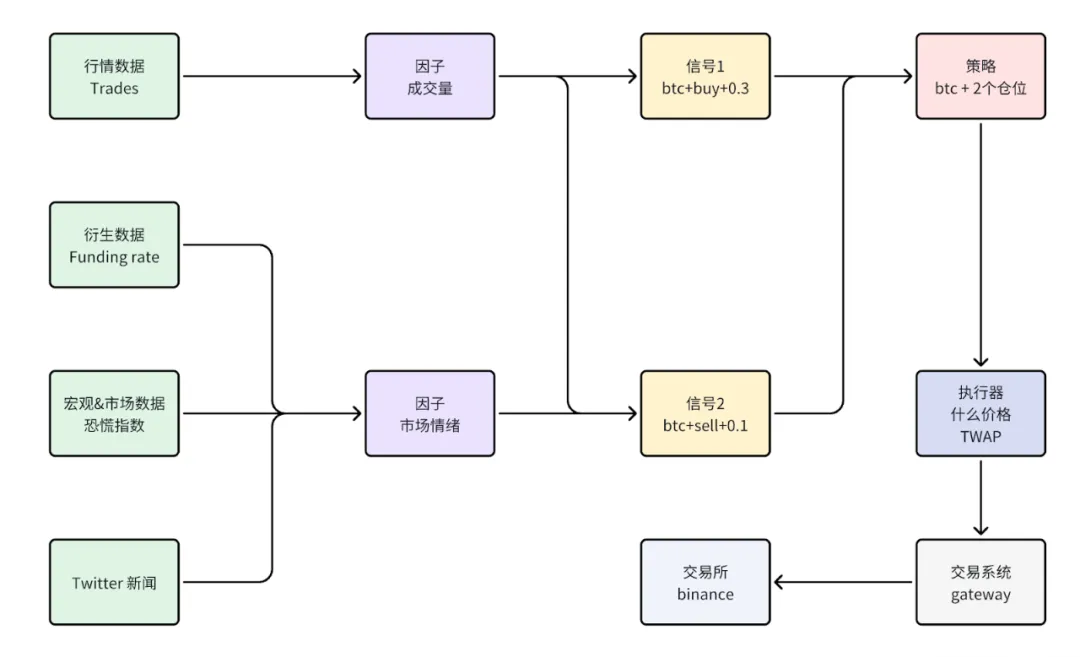
量化业务流程示意图
- 海量数据与快速增长:研究需处理历史行情、新闻及自研因子等数据,总量近500TB,且每日新增数百GB行情数据,传统磁盘难以承载。
- 高频访问与低延迟需求:研究效率直接取决于数据读取速度,高频数据访问对I/O延迟极为敏感。
- 多团队并行与数据治理:多个研究团队需并行实验,要求存储系统能实现安全的数据隔离,防止混淆与泄露。
为应对这些挑战,理想的存储系统目标应统一高性能、易扩展与可治理:
- 高性能:单节点读写带宽突破500MB/s,延迟低于本地磁盘感知阈值。
- 易扩展:支持存储与计算资源按需水平扩容,业务无需改造。
- 可治理:提供细粒度权限控制、操作审计与数据生命周期管理能力。
存储架构的四阶段演进之路
阶段一:本地盘起步的便利与局限
项目初期,团队使用Quantrabyte研究框架,数据直接存储在本地磁盘,读取速度快,迭代迅速。但问题很快显现:多研究员重复下载相同数据造成浪费;服务器约15T的存储容量迅速告急;团队间协作与成果复用困难。
阶段二:MinIO集中管理的双刃剑
为解决上述问题,团队引入MinIO进行集中管理,将所有数据存入其中,实现公共数据统一下载与多团队权限隔离共享,提升了空间利用率。然而,新瓶颈出现:MinIO社区版无缓存功能,在高频随机读写场景下延迟较大,严重影响研究效率。
阶段三:引入JuiceFS缓存加速
为解决性能瓶颈,团队引入JuiceFS缓存加速方案。通过客户端本地RAID5存储挂载,利用高效缓存机制,读写性能提升约三倍,显著改善了高频共享数据的访问体验。

但随着业务数据量突破300TB,本地存储的扩容瓶颈凸显。在RAID5架构下扩容速度慢、风险高,难以满足业务持续增长需求。
阶段四:JuiceFS + MinIO集群的终局架构
最终,团队采用JuiceFS + MinIO集群架构,完美解决了性能与扩容难题:
- 持续高性能:JuiceFS提供充足的客户端缓存,充分满足高频访问场景。
- 便捷集群扩展:基于对象存储集群,可快速横向扩容,仅需添加磁盘即可灵活提升容量。
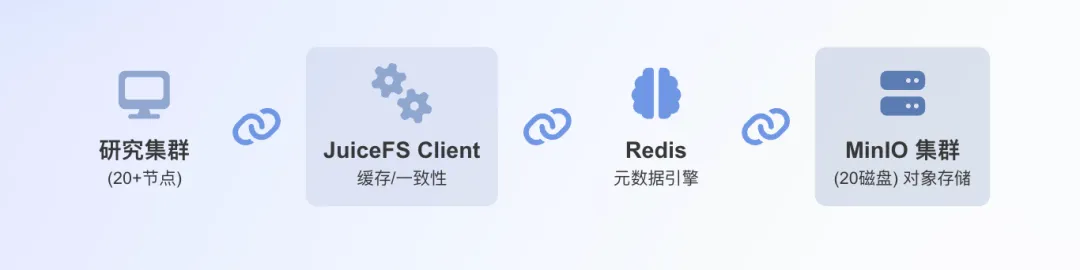
这四阶段演进验证了“缓存加速、弹性对象存储与POSIX兼容”三位一体方案在量化场景下的可行性,在性能、成本与治理间取得了良好平衡。
性能与成本收益
采用JuiceFS与MinIO结合的架构后,系统带宽与资源利用效率实现飞跃。引入JuiceFS缓存层后,回测任务执行效率大幅提升,1亿条Tick数据回测耗时从数小时降至数十分钟。

读写带宽变化
同时,基于完整的数据生命周期分层存储策略,实现了存储成本由高到低的平滑过渡,整体存储成本下降超40%。

Ariste AI数据生命周期分层存储策略
运维实践与未来展望
多租户治理
团队建立了完善的数据隔离与权限管理体系:通过命名空间(如 /factor/A)实现逻辑隔离;支持用户、团队、项目三维度精细权限管理,并与POSIX ACL无缝对接;建立完整审计日志系统,满足合规要求。
可观测性与自动化运维
围绕缓存命中率、I/O吞吐量、延迟与写入重试率四大核心指标构建监控体系。基于Grafana实现运维闭环,并在扩容前通过模拟压测验证系统能力,实现了自动化、可预测的高标准运维。
回测系统中的数据更新设计
回测系统采用基于DAG(有向无环图)的架构提升效率与可维护性。将数据处理、特征计算等环节抽象为节点,通过依赖图管理。系统内置版本控制,当数据更新时,能自动识别需重算节点,实现高效的增量更新。
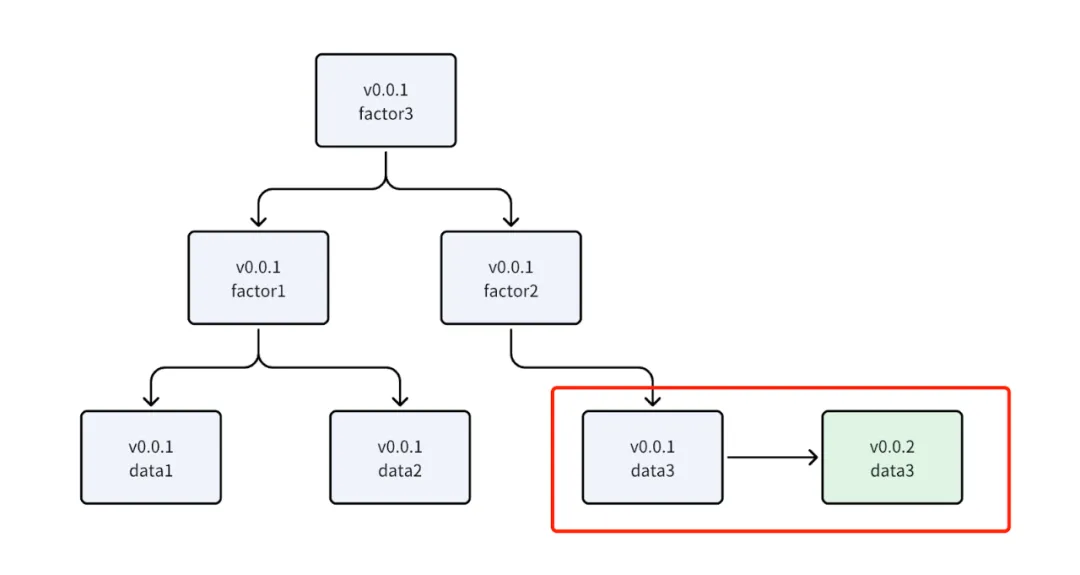
回测数据版本更新示意图
未来展望
未来,团队计划从三方面持续优化:
- 元数据高可用升级:计划将元数据引擎从Redis迁移至TiKV或PostgreSQL,构建跨机房高可用架构。
- 混合云分层存储:对接公有云S3与Glacier服务,构建智能冷热分层体系,实现容量弹性与成本最优。
- 研究数据湖统一治理:构建统一数据湖平台,集成Schema注册、自动数据清洗与目录治理服务,提升数据资产管理效率。
|  发表于 2025-12-20 03:44:23
|
查看: 236|
回复: 0
发表于 2025-12-20 03:44:23
|
查看: 236|
回复: 0
