Gemma 3 270M是Google推出的一款轻量级开放模型,虽然参数规模不大,但能力不俗。它延续了Gemini模型的技术精髓,并以一种更轻量、更易于定制的方式呈现。
你可以在不到一小时的时间内完成对其的微调,并将模型压缩至300MB以下,从而让它能够直接在浏览器中运行。
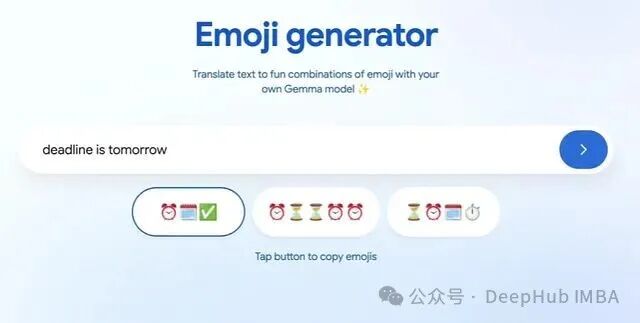
本文将演示如何使用Gemma模型创建一个自定义的表情符号翻译器——一个能够将文本转换为表情符号并在本地运行的小型模型。

第一步:引导Gemma进行“Emoji思维”
Gemma是一个通用模型。如果你直接要求它将文本翻译成表情符号,它的回应通常会过于礼貌。
提示词:
“Translate this text into emojis: what a fun party”
模型回应:
“Sure! Here is your emoji: 🥳🎉🎈”
这并非我们期望的结果。对于这个应用,我们只需要纯表情符号的输出——不要任何文字,不要“Sure!”,只要有趣的表情。
因此,我们可以通过微调来改变它的行为。
构建微型数据集
从一个简单的JSON文件开始,定义输入文本和对应的表情符号输出。
[
{ "input": "what a fun party", "output": "🥳🎉🎈" },
{ "input": "good morning sunshine", "output": "☀️🌻😊" },
{ "input": "so tired today", "output": "😴💤" }
]
在Colab中进行微调
以往微调大模型需要昂贵的A100 GPU和大量时间,但现在情况不同了。利用QLoRA技术(仅更新少量参数),在Google Colab提供的免费T4 GPU上就能高效完成微调。
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 关键:为Gemma设置pad_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # 可选:使用自动类型以提升效率
device_map="auto" # 可选:如果可用,自动映射到GPU
)
dataset = load_dataset("json", data_files="emoji_dataset.json")
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj", # Attention层
"gate_proj", "up_proj", "down_proj" # MLP层
],
lora_dropout=0.05,
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
training_args = TrainingArguments(
output_dir="./gemma-emoji",
num_train_epochs=3,
per_device_train_batch_size=4,
save_steps=100,
logging_steps=10,
evaluation_strategy="no",
)
# 关键:适用于因果语言模型的正确数据整理器
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # 因果语言模型,非掩码语言模型
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
tokenizer=tokenizer,
data_collator=data_collator
)
trainer.train()
完成训练后,模型将学会只生成表情符号。
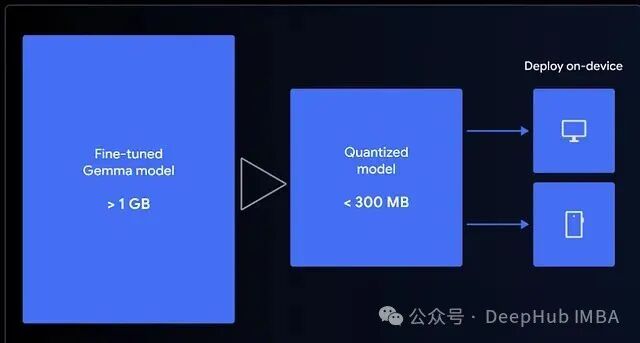
第二步:压缩模型以适配Web环境
微调后的模型大小约为1GB,以LLM的标准看很小,但对于浏览器而言仍然偏大。
为了能在本地运行,我们使用LiteRT将其量化为4-bit(如果偏好Transformers.js,也可以选择转换为ONNX格式)。这个量化版本非常适合MediaPipe或Transformers.js,它们都能利用WebGPU来调用设备硬件。这意味着模型实际上是在你的浏览器中执行的。
第三步:在浏览器中运行模型
最有趣的部分来了——无需服务器,无需调用API,也无需等待网络延迟。
使用MediaPipe的GenAI Tasks,可以直接在浏览器中加载并运行我们微调好的模型。
const genai = await FilesetResolver.forGenAiTasks(
'https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai@latest/wasm'
);
const llmInference = await LlmInference.createFromOptions(genai, {
baseOptions: { modelAssetPath: 'path/to/yourmodel.task' }
});
const prompt = "Translate this text to emoji: what a fun party!";
const response = await llmInference.generateResponse(prompt);
console.log(response);
模型一旦被缓存,即可完全离线运行。实现零延迟、完全隐私,甚至在飞行模式下也能正常工作。
更小的模型意味着应用加载更快,最终用户体验更佳。
总结
这个项目从开始到结束花费了不到一个小时。经过测试,它甚至能生成我偏爱的表情符号风格。如果你一直想尝试本地AI,可以从一个小目标开始:选择一个简单任务,利用Hugging Face的Transformers库和PyTorch微调Gemma模型,将其量化,然后部署到浏览器中直接运行。
因为AI的未来不仅仅是云端的大型模型,也包含那些存在于你设备本地、触手可及的小型智能。
 发表于 2025-12-21 19:16:53
|
查看: 240|
回复: 0
发表于 2025-12-21 19:16:53
|
查看: 240|
回复: 0
