本文将通过一个简单、低成本的Ping测试实验,深入剖析云计算环境中跨可用区(AZ)的网络延迟,并探讨其对高可用架构设计与技术选型的深远影响。
低成本Ping测试实验设计
整个测试流程简单直接,成本可控在极低范围内,主要包括以下4到5个步骤:
- 资源准备:在主流云厂商的默认推荐区域,按需(非包月)创建三台中档配置(如4C8G或8C16G通用型)的云主机。确保它们位于同一个地域(Region),其中两台(称为Server-1、Server-2)部署在同一可用区(AZ),第三台(Server-3)部署在同Region的另一个AZ。为所有实例配置按流量计费的公网IP,并按常规配置内网交换机和安全组。
- 登录控制机:通过公网IP SSH登录到Server-1。在云控制台记录下Server-2和Server-3的内网IP与公网IP,后续操作无需登录这两台服务器。
- 执行Ping测试:避开网络晚高峰(如下午6点至11点),在Server-1上依次执行以下Ping命令,每个目标至少Ping 10次以获取稳定数据:
ping 127.0.0.1ping <Server-1内网IP>ping <同AZ的Server-2内网IP>ping <Server-1的内网网关IP>ping <跨AZ的Server-3内网IP>ping <三台服务器的公网IP>
- 清理资源:保存测试日志或截图后,立即释放所有云服务器以控制成本。
- (可选)对比验证:为增加数据可信度,可更换测试Region或云厂商重复上述步骤。

实验环境与对象的深度解读
上述步骤看似基础,但每个细节都蕴含了对云计算环境特性的考量。
关于测试环境:
- 厂商选择:选择大型云厂商作为测试基准,因其基础设施规模与性能指标常被视为行业标杆,且其按小时计费与快速资源交付模式能完美支持此类低成本实验。
- 机型选择:中档通用型云主机避免了低配实例可能存在的资源调度优先级干扰,也规避了高配实例可能采用的物理网卡直通等非常规优化,结果更具普适性。
- 时机选择:避开业务晚高峰,能最大概率降低宿主机负载和网络拥塞对微秒级延迟测量的影响。
- 工具局限性:Ping(ICMP)的软件开销使其在微秒级测量上并不绝对精确,且网络QoS策略可能对其有特殊处理。但其结果与真实网络延迟存在强正相关性,本实验的单机发起测试方式增强了这种相关性的一致性。
- 延迟概念:需明确区分单向延迟与往返延迟(RTT)。应用层通常关注RTT,而网络基础设施讨论可能侧重单向延迟。
关于测试对象——Region与AZ:
在云原生基础设施中,Region(地域)和AZ(可用区)是构建高可用性的基石。绝大多数用户理解到“同Region内网互通,不同AZ隔离故障”这一层。
深入来看,AZ在云厂商视角下是一个独立的硬件资源池(计算、存储、网络),池内资源可灵活调度,但池间硬件隔离。Region则是通过同城高速光纤环网将多个AZ互联而成的逻辑整体,它实现了AZ间资源的逻辑统一与无缝调配。
这就引出了一个核心矛盾:为了实现故障隔离,不同AZ需要足够的物理距离(如>100公里)以避免共同风险;但为了支持低延迟双活,AZ间又需要足够近(如同园区)以保障网络性能。查阅各云厂商文档可知,业界在此存在两种设计倾向:一种追求远距离真隔离,一种追求近距离低延迟。

实测数据结果与分析
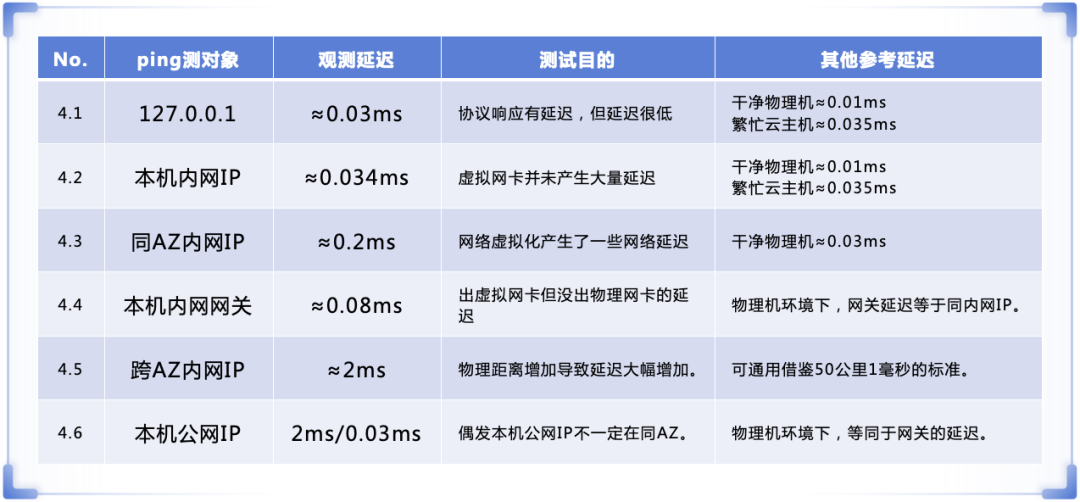
以下是基于前述方法的实测数据分享。需再次强调,Ping值在微秒级存在误差,但它与真实网络延迟的强正相关关系足以揭示重要规律。
- Ping 127.0.0.1:延迟约0.03ms。此步骤用于验证协议栈基础开销。
- Ping 本机内网IP:延迟约0.034ms。说明虚拟网卡本身带来的额外延迟极低。作为对比,纯净物理机的同类测试延迟约为0.01ms。
- Ping 同AZ另一主机:延迟约0.2ms。相比前一步,增加的约0.16ms延迟主要源于VXLAN等网络虚拟化技术开销及跨多层物理交换机的转发延迟。在云计算环境中,同AZ内延迟低于0.5ms通常被认为是良好水平。
- Ping 本机内网网关:延迟约0.08ms。明显低于Ping同AZ邻居的延迟,这是因为云上的分布式虚拟路由器很可能与云主机位于同一台宿主机上,数据并未出物理网卡。
- Ping 跨AZ另一主机:延迟跃升至约2ms。这明确体现了跨机房光纤传输的代价。不同云厂商或不同AZ对间的延迟通常在0.5ms到5ms之间,这个数值直接关联到AZ间的物理距离。
- Ping 公网IP:出现有趣现象,本机Ping本机公网IP延迟可能与跨AZ延迟相当(~2ms),而Ping同AZ邻居的公网IP延迟却很低(~0.3ms)。这暗示着NAT网关可能漂移到其他AZ,属于架构设计中的一个观察点。
延迟阈值如何影响技术选型
跨AZ延迟的具体数值并非偶然,它直接对应着不同的分布式系统技术选型与可行性边界。例如,在研究“强一致性集群对网络延迟的容忍度”时,云厂商的AZ延迟设计提供了重要参考。
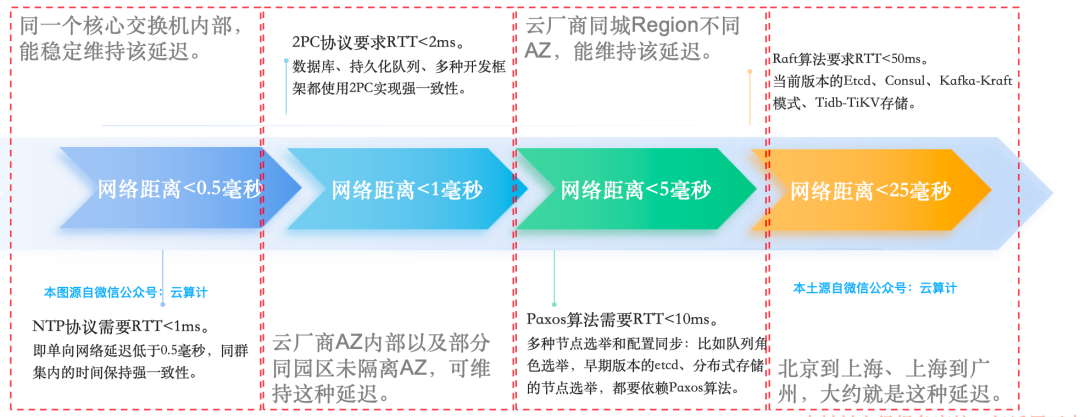
结合行业专家理论与实践,可以从强一致性分布式系统的视角得到以下关键阈值:
- < 0.5ms:这是保障同一AZ内NTP服务高精度同步、维持集群节点时间强一致的基准线。
- < 1ms:基于2PC(两阶段提交)协议的服务集群能正常工作的上限,超过此延迟,集群性能会急剧下降甚至不如单AZ部署。
- < 5ms:这是许多云厂商对跨AZ延迟的常见设计目标,在此范围内,基于Paxos算法的分布式系统可以稳定运行。
- ~25ms:像Raft这类算法,为了在CAP定理中优先保证分区容错性(P)而放宽强一致性要求,因而可以容忍更高的延迟。
总结:从技术指标到产品定位
理解跨AZ延迟的意义,不能局限于技术参数,它本质上是云厂商产品定位与客户技术需求相互博弈的体现。
- 高延迟(~5ms)策略:意味着AZ间距离可能更远,真故障隔离能力更强,云厂商机房选址和成本控制更灵活,但运维复杂度也相应增加。适合对灾难恢复(DR)要求极高的场景。
- 低延迟(<1ms)策略:AZ可能位于同园区甚至同楼内,为实现跨AZ双活提供了近乎顺滑的体验,运维和备件库可以集中,但需共同承担局部基础设施风险。适合对业务连续性要求苛刻的应用。
- 客户视角:选择云服务或设计架构时,需明确自身“跨AZ”部署的核心诉求是“高可用隔离”还是“低延迟双活”,从而做出有侧重的选择。
- 厂商视角:提供透明、准确的AZ延迟信息,并据此设计数据库、消息队列等托管服务的集群方案,是提升产品竞争力和客户信任度的关键。
综上所述,一个简单的Ping测试可以成为洞察云计算底层网络架构与上层应用设计联系的窗口。深入理解这些“习惯值”背后的原理,有助于研发、架构师及产品决策者在技术选型与产品定义中做出更明智的判断。

|  发表于 2025-12-22 19:46:06
|
查看: 258|
回复: 0
发表于 2025-12-22 19:46:06
|
查看: 258|
回复: 0
