之前,我们已经探讨了如何通过Ollama在本地运行大语言模型,以及在没有GPU的情况下使用llama.cpp在PC上进行部署。
许多人可能认为“在本地运行模型”已经是一项成熟的技术。然而,当你真正尝试构建一个可长期使用、可交付、可维护的本地AI功能时,会发现模型本身反而是相对容易解决的部分。
本文将深入介绍另一个关键工具——跨平台统一推理框架NexaSDK。

本文旨在:
- 阐明NexaSDK所解决的核心工程问题。
- 拆解NexaSDK的实际部署与应用流程。
- 从选型角度,对比NexaSDK、Ollama、llama.cpp和LM Studio。
一、为何“本地跑模型”不等于“本地AI可用”
首先,指出一个常见的认知误区。
你可能已经成功完成了以下操作:
- 使用llama.cpp运行了一个模型。
- 或用Ollama通过一行命令启动服务。
- 再通过LM Studio在本地进行对话交互。
这很容易让人产生“本地AI已经准备就绪”的错觉。但一旦你试图进行以下任何一项实践,挑战便随之而来:
- 将AI能力嵌入到桌面软件或移动App中。
- 在多设备、多操作系统平台上实现稳定运行。
- 精确控制内存占用、启动速度和推理延迟。
- 同时支持文本生成、Embedding向量化及RAG检索增强生成。
- 将其作为一项需要长期维护和迭代的产品功能进行交付。
此时你会发现:
现有工具更像是“运行模型的实验工具”,而非“构建产品的基础设施”。
NexaSDK的出现,精准地填补了这一空白。
NexaSDK的基本信息可通过其GitHub仓库查阅,其中包含详细的中文文档:
https://github.com/NexaAI/nexa-sdk
二、NexaSDK究竟是什么?
NexaSDK是一个“本地大模型推理与集成SDK”。

用工程化的语言描述:
它既不是模型本身,也不是一个终端应用,而是一个旨在“将本地大模型转化为可嵌入软件组件”的运行时环境与工具集合。
你可以这样理解它的层次:
- 上层:提供稳定、统一的API(涵盖文本生成、Embedding、多模态等)。
- 中层:负责推理任务调度、内存管理、KV Cache优化。
- 底层:处理CPU、GPU、NPU等不同硬件的适配与性能优化。
它关注的核心不是“模型的智能程度”,而是:
模型在真实的软件产品环境中,能否长期、稳定、可控地运行。
NexaSDK解决的核心工程问题
1. 性能不可控的本地推理
直接运行模型常遇到以下问题:
- 启动速度缓慢
- 推理延迟波动大
- 内存占用出现峰值
- 多个任务并行时相互干扰
NexaSDK在工程层面提供的解决方案包括:
- 模型量化(支持INT8 / INT4)
- 推理计算算子优化
- KV Cache的高效管理
- 推理线程的智能调度
核心观点是:
不应要求每位应用开发者都去深入研究如何极致压榨模型性能。
2. 平台碎片化的本地AI部署
现实开发环境是多样化的:
- 操作系统:Windows、macOS、Linux
- 处理器架构:x86、ARM
- 计算硬件:CPU、GPU、NPU
如果直接使用底层引擎,意味着:
- 每个平台都需要一套独立的适配代码
- 每次升级或变更都充满风险
NexaSDK的核心价值在于:
对上提供统一接口,对下封装硬件差异。
应用层开发者只需关注业务逻辑,例如:
load model → generate → stream tokens
3. 产品化能力不足的本地AI工具
许多工具能够运行模型,但缺乏产品化所需的完整能力:
- 没有统一的Embedding接口
- 实现RAG需要自行拼接多个组件
- 接入多模态功能需额外集成
- 模型的生命周期管理完全依赖手动编码
而NexaSDK的目标非常明确:
你可以将其视为“本地化的OpenAI API运行时”。
三、NexaSDK的基本部署与使用流程
1. 准备运行环境
所需环境并非云服务器,而是:
- 一台本地机器(CPU即可,GPU性能更佳)
- 充足的内存(建议8GB起步)
- 支持的目标平台(桌面、边缘设备或移动端)
需注意,NexaSDK本质是嵌入式SDK,而非独立的桌面应用程序。
2. 加载本地模型
核心原则只有一个:
模型文件存储于本地,推理计算也在本地完成。
典型的工程目录结构如下:
/models
├── qwen_xx.gguf
├── embed_xx.gguf
在代码中,你需要进行的操作类似于:
- 初始化Runtime环境
- 加载指定的模型文件
- 配置推理参数(如上下文长度、并发数等)
关键在于理解:
这些参数属于“工程优化参数”,而非Prompt设计技巧。
3. 调用生成与Embedding接口
NexaSDK提供的是稳定的编程API,而非命令行工具。
典型应用场景包括:
- 文本生成(用于Copilot、对话系统)
- 向量生成(用于RAG、语义搜索)
- 流式输出(提供更友好的用户体验)
这一步的核心价值在于:
你的业务代码将与“模型的具体实现细节”解耦。
4. 构建本地RAG系统(强烈推荐)
若要充分发挥NexaSDK的价值,强烈建议搭配RAG系统。
最小化的架构流程如下:
Documents/Code
↓
Local Embedding (NexaSDK) # 例如,利用Python的FastAPI搭建RAG服务时,可在此环节集成
↓
Vector DB (FAISS/Chroma)
↓
Top-K Context Retrieval

必须注意一个关键工程原则:
Embedding向量必须在本地生成,否则将失去隐私保护和低延迟的优势。
四、工具选型对比:NexaSDK vs Ollama vs llama.cpp vs LM Studio
这是开发者最为关注的部分。

1. 定位对比(本质分析)
| 工具 |
本质定位 |
| NexaSDK |
工程级的本地AI集成SDK |
| Ollama |
本地模型运行与管理服务 |
| llama.cpp |
底层推理引擎(C++实现) |
| LM Studio |
本地AI图形化客户端 |
一句话总结:
- llama.cpp 是“发动机”。
- Ollama 是封装好的“整车”。
- LM Studio 是开箱即用的“成品车”。
- NexaSDK 是“工业级零部件”加上“标准接口”。
2. 工程能力对比
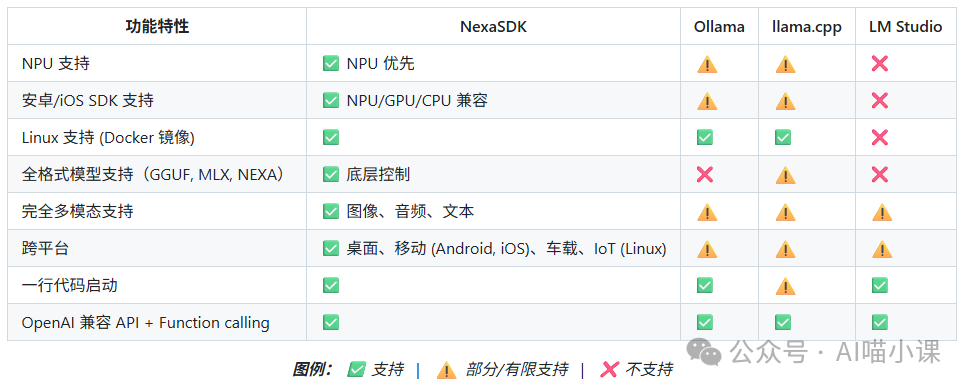
3. 如何选择?
- 如果你的目标是开发产品、集成Copilot或构建工具 → 选择 NexaSDK。
- 如果你需要快速拉起一个本地模型服务进行测试 → 选择 Ollama。
- 如果你希望深入研究推理底层或进行定制化优化 → 选择 llama.cpp。
- 如果你仅仅想要一个本地AI聊天工具 → 选择 LM Studio。
何时不适用NexaSDK?
- 你仅仅想“体验和玩耍”模型。
- 你不打算编写任何工程代码。
- 你不关心功能的长期维护。
- 你只需要一个桌面端的聊天应用。
NexaSDK是面向生产的工程工具,而非娱乐软件。
五、如何将本地模型集成为Copilot?
查看下面的工程级结构图:
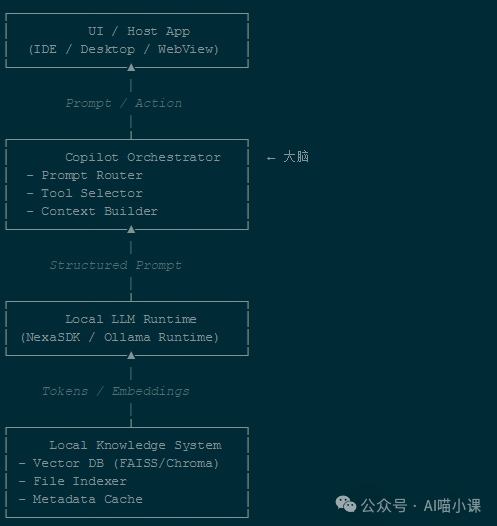
简而言之:
Copilot = 编排器 + 本地模型 + 本地知识库 + 用户界面
其中的“编排器”负责核心调度工作:
1. Prompt路由
- 判断用户意图类型:
- 代码生成?
- 知识查询?
- 文本润色?
- 执行特定操作?
2. 上下文构建
- 动态拼装有效上下文:
- 当前编辑的文件
- 相关的会话历史
- RAG检索到的知识片段
- 严格控制Token预算
3. 工具选择
- 决定是否及如何调用外部工具:
- 本地文件搜索
- 代码AST分析
- Git差异比对
- Shell命令执行(谨慎使用)
你可以将编排器理解为:
将用户模糊的自然语言意图,翻译成模型能够稳定、准确执行的结构化任务指令的中枢系统。 在构建此类复杂的后端调度逻辑时,选择像Golang这样高性能、高并发的语言来开发RESTful API,是确保服务响应速度与稳定性的常见工程实践。
通过本文的梳理,我们可以看到,从运行一个模型到将其转化为可靠的工程化组件,需要像NexaSDK这样的专业工具来填补基础设施的空白。这不仅是技术的迭代,更是开发生态从实验走向成熟应用的标志。深入了解人工智能领域的工程化工具链,对于构建真正可用的本地AI应用至关重要。
 发表于 2025-12-24 00:51:48
|
查看: 309|
回复: 0
发表于 2025-12-24 00:51:48
|
查看: 309|
回复: 0
