2024年12月17日,Google正式发布了Gemini 3 Flash模型。这不仅仅是一次简单的版本迭代,更是对当前大模型技术与商业模式的一次深刻重塑。凭借高达90.4%的GPQA Diamond准确率与令人震惊的每百万Token仅0.5美元的输入成本,Gemini 3 Flash标志着高性能AI模型正迈向普惠化时代。本文将深入分析其核心技术,探讨它如何在性能与成本的平衡上实现对竞争对手的超越。
自适应思维:快思考与慢系统的动态调度
Gemini 3 Flash最核心的进化在于其「自适应思维深度」机制。Google工程师摒弃了为所有任务分配固定计算资源的传统方式,转而让模型能够根据问题的复杂度,在Minimal、Low、Medium、High四个思维档位间动态切换。
这意味着,处理简单查询时,模型调用的是高效轻量的推理路径;而面对复杂的Python异步编程或系统架构难题时,它会自动激活更深层、链式更长的逻辑推理能力。这种类似于人类“系统1”与“系统2”协作的机制,使其在Humanity‘s Last Exam基准测试中取得了33.7%的高分。它不再是一个匀速运转的黑箱,而是一个懂得合理分配“认知资源”的高效智能体。
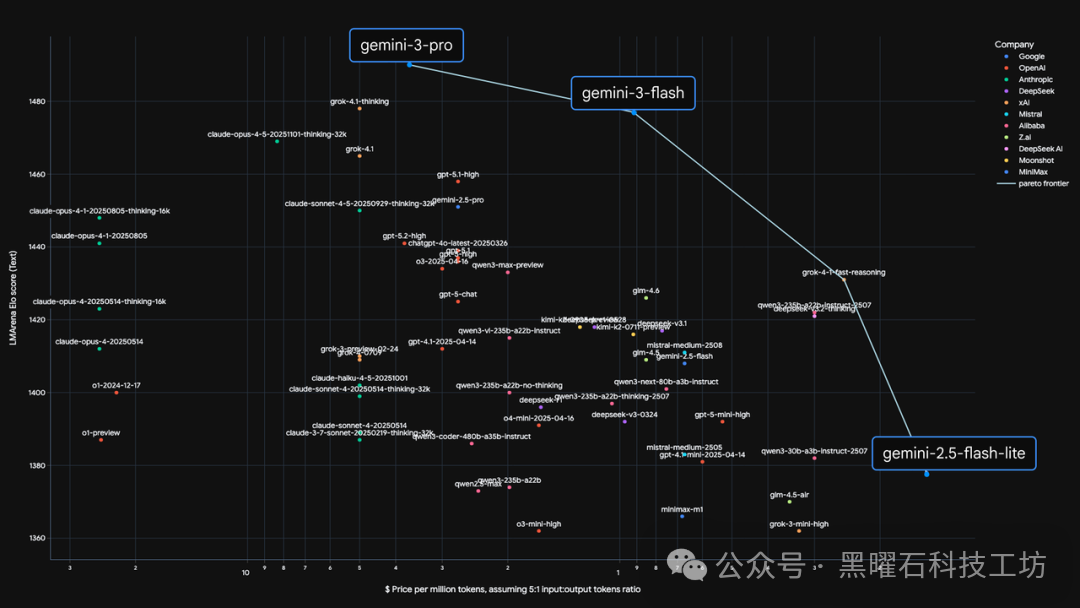
成本革命:帕累托前沿的暴力突破与行业影响
上图的帕累托前沿曲线清晰地展示了Gemini 3 Flash带来的颠覆性优势:它以每百万Token输入0.5美元的低廉成本,在LMArena Elo竞技场中成功跻身性能第一梯队。这不仅是对竞争对手的强力挑战,更是对整个AI云原生服务定价策略的重新定义。
当推理成本降至如此低的水平时,AI应用的想象空间被极大地拓宽了。高频率调用的“自愈式Agent”、复杂多步骤的工作流,将从概念验证走向规模化企业级应用。开发者能够以极低的代价进行数百万次逻辑调用,使得AI正从一项昂贵的技术选配,转变为像水电一样的基础设施。
原生多模态:对动态视频流的本质理解
与仍需借助外部工具处理多模态信息的模型不同,Gemini 3 Flash实现了真正的“原生多模态”架构。它能够直接理解视频流中的时序逻辑与动态信息,而非简单分析静态帧序列。在Video-MMMU测试中取得87.6%的高分,证明其可以像人类一样,观看一段冗长的教学或操作视频,并实时提炼关键步骤与信息。
这种能力结合其1M的上下文窗口,使其成为处理监控流、屏幕录制、交互演示等非结构化现实数据的强大工具。它不仅具备了快速“观看”的能力,更拥有了深度“理解”动态场景的潜力。
代码统治力:极速迭代让Agent工作流成本归零

在SWE-bench Verified榜单上,Gemini 3 Flash以78%的通过率超越了自家的Pro版本。这看似反直觉的结果,实则体现了“速度即智能”的新范式。在Agentic Workflow中,模型通常需要经历“规划-执行-错误-修正”的多轮循环。Flash版本极低的单次响应延迟,使得它能在相同时间内进行更多轮次的试错与自我修正。
这彻底改变了AI辅助编程的范式。开发者无需追求一次生成完美代码,可以构建一个允许快速、多次迭代的自动化修复管道。Gemini 3 Flash的发布,相当于赋予了开发者近乎“无限”的廉价试错权,这将极大加速复杂算法与系统的开发进程。

|  发表于 2025-12-24 06:22:36
|
查看: 264|
回复: 0
发表于 2025-12-24 06:22:36
|
查看: 264|
回复: 0
