在构建能够支撑千万级QPS(每秒查询率)的大型系统时,数据库是最核心的组件之一。对于使用MySQL的架构师而言,实现从单库到高并发的演进是一条必经之路。本文将系统性地详解MySQL实现千万级QPS的完整技术方案。
第一阶段:单机性能极限优化
在考虑任何分布式方案之前,首先应最大化单台数据库服务器的性能,榨干其硬件和配置的潜力。
在理想条件下(例如纯读、小表、查询完全命中缓存),单实例MySQL的QPS可以达到5千到2万。

优化主要从以下三个方面入手:
-
硬件升级(垂直扩展)
- 存储:将硬盘更换为高性能的NVMe SSD,极大提升I/O吞吐。
- 内存:增加内存容量,使
innodb_buffer_pool_size可以设置得更大,让尽可能多的数据和索引缓存在内存中,减少磁盘访问。
- CPU:使用高频多核CPU,以应对高并发下的计算压力。
-
数据库配置调优
innodb_buffer_pool_size: 这是最重要的参数,通常设置为系统物理内存的60%-80%。innodb_flush_log_at_trx_commit: 根据业务对数据安全性和性能的要求进行权衡设置(如设置为2以获得更好性能)。- 其他如
max_connections、innodb_log_file_size等也需要根据实际情况调整。
-
索引与SQL优化
- 应严格避免全表扫描,为高频查询条件建立合适的索引。
- 利用覆盖索引(Covering Index)减少回表查询。
- 拆分或重构复杂的Join查询,降低单次查询的复杂度。
第二阶段:读写分离
当单机性能达到瓶颈,且压力主要来源于大量的“读”请求时,可以采用主从(Master-Slave)架构进行读写分离。
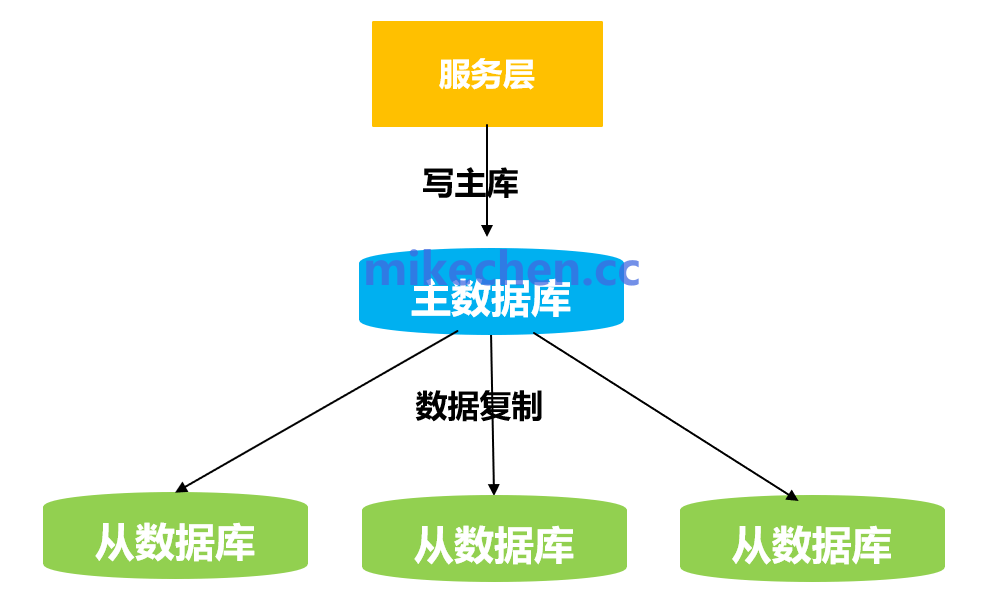
- 架构:一主多从。主库(Master)负责处理所有写入操作(INSERT、UPDATE、DELETE),多个从库(Slave)通过复制(Replication)同步主库数据,并分担读请求。
- 实现:需要一个中间件来路由请求。应用将写请求发给主库,读请求分发到各个从库。
- 工具:可以使用ProxySQL、MyCat或ShardingSphere的读写分离模块来实现自动路由。
- 瓶颈:此方案的性能上限受限于主库的写入能力和从库与主库之间的复制延迟。
第三阶段:引入缓存层
这是迈向千万级QPS的关键一步。数据库不应直接承受所有的高频访问请求,绝大部分热点数据的读取应由更快的缓存来承担。
- 技术栈:主要采用Redis或Memcached作为缓存服务。
- 模式:旁路缓存(Cache-Aside)。
- 应用先查询缓存。
- 若命中(Hit),则直接返回数据。
- 若未命中(Miss),则查询数据库,获取数据后回写到缓存中,再返回给应用。
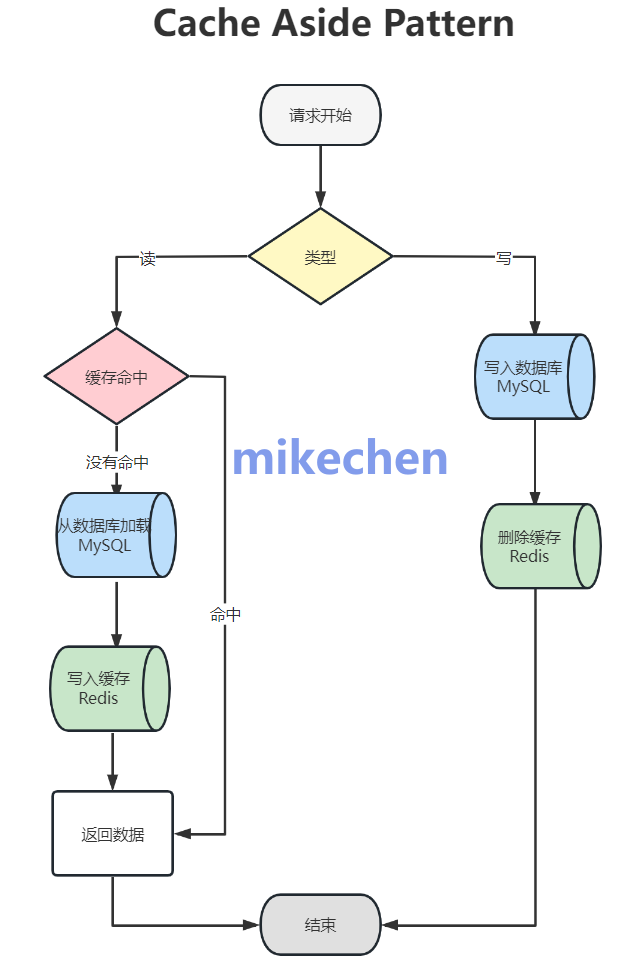
- 效果:一个设计良好的缓存层可以轻松消化掉80%甚至90%的读请求,将数据库的读QPS压力降低一个数量级,从而释放数据库资源来处理更核心的写入和复杂查询。
第四阶段:数据库拆分
当单库的数据量过于庞大(如单表行数超过千万级),或者写QPS达到单机瓶颈时,就必须对数据库本身进行拆分。
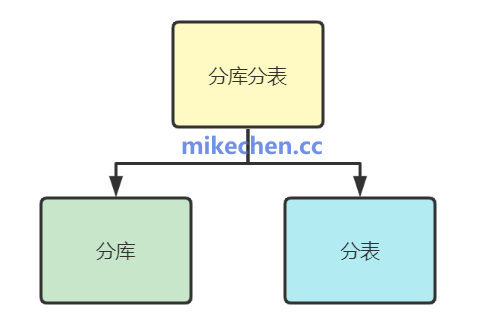
1. 垂直拆分 (Vertical Sharding)
按业务模块将不同的表拆分到独立的数据库实例中。
- 例子:将用户相关的表(
user_info)、订单相关的表(orders)、商品相关的表(products)分别部署在不同的MySQL实例上。
- 优点:降低单库复杂度,不同业务互不影响。
2. 水平拆分 (Horizontal Sharding)
当单张表的数据量或访问量过大时,将同一张表的数据按照某种规则分布到多个数据库的多个表中。
- 分片键 (Sharding Key):选择合适的分片键至关重要,例如用户ID(UserID)。常用的规则有取模、范围、哈希等。目标是尽可能让查询落在单一分片上,避免跨分片查询带来的性能损耗。
- 工具:此步骤通常需要引入专业的分布式数据库中间件,如ShardingSphere或Vitess。它们能透明地处理SQL解析、路由、结果合并等复杂逻辑,对应用层屏蔽分片细节。
通过以上四个阶段的演进——单机优化、读写分离、缓存加速、数据分片——一个原本的单体MySQL数据库便能逐步成长为能够支撑千万级QPS的高可用、可扩展的分布式数据库集群。每个阶段的选择都需要根据实际的业务压力、数据规模和团队技术栈来综合决策。 |  发表于 2025-12-24 16:29:16
|
查看: 218|
回复: 0
发表于 2025-12-24 16:29:16
|
查看: 218|
回复: 0
