TL;DR
全文约 3 万字,围绕 SIGCOMM 论文 《Falcon: A Reliable, Low Latency Hardware Transport》 做了较完整的翻译、整理与工程化对比分析,并结合 CIPU eRDMA 的实现经验讨论其取舍与边界。本文为技术观点讨论,不涉及任何推广信息。
论文链接:https://dl.acm.org/doi/10.1145/3718958.3754353
0. Abstract:为什么要做 Falcon?
论文在摘要里先肯定了 RoCE 的优势:“high performance with minimal host CPU”。Kernel bypass 确实能显著降低 CPU 负担,但作者紧接着强调 RoCE “best suited to special-purpose deployments”,本质是在说:RoCE 的高性能建立在一个苛刻假设之上——网络必须近似无损(lossless)。
在通用以太网数据中心里,拥塞与丢包是常态。为了创造“无损”环境,RoCE 部署通常依赖 PFC,但 PFC 本身会引入严重问题:例如队头阻塞(Head-of-Line Blocking)与死锁,部署和调试成本极高,运维复杂度也会显著上升。
因此,RoCE 往往被限制在专用隔离网络中(如存储网络、AI 训练后端网络)。Falcon 的问题背景也就非常明确:如何让硬件传输在“有损的通用以太网数据中心”里稳定工作,并保持高性能?
Falcon 的定位是:
“We introduce Falcon, the first hardware transport that supports multiple Upper Layer Protocols (ULPs) and heterogeneous application workloads in general-purpose Ethernet datacenter environments (with losses and without special switch support).”
这里有三个关键词:
- hardware transport:可靠传输能力在硬件侧落地,追求线速与低延迟;
- general-purpose Ethernet datacenter environments:不依赖 PFC、不依赖交换机特殊功能(例如 Adaptive Routing/Packet Spray),甚至不要求依赖 INT 等 Telemetry;
- multiple ULPs:用统一传输承接 RDMA、NVMe 以及其他异构 workload。
作者归纳的技术支柱主要有四条:
delay-based congestion control with multipath load balancing:基于 Timely/Swift 的延迟信号拥塞控制,并扩展到多路径(如 PLB)。a layered design with a simple request-response transaction interface:把上层 RDMA/NVMe 等语义映射到简化的 Push/Pull 事务模型,降低“每个 ULP 各做一套可靠传输”的复杂度。hardware-based retransmissions and error-handling for scalability:把 SACK、快速恢复、错误处理尽可能放在硬件数据路径中,避免异常导致性能断崖式下降。a programmable engine for flexibility:引入可编程引擎(FAE)做策略,硬件做机制,平衡性能与可演进性。
1. Introduction:目标与约束是什么?
现代数据中心工作负载(HPC、横向扩展 AI/ML、实时分析)对网络提出了非常明确的要求:高带宽、低延迟、高消息速率(Mops/sec),同时还要“尽量少占用主机 CPU”。
论文用 Google 软件传输 Pony Express 与硬件 Falcon 做了对比,强调硬件加速的性能空间:
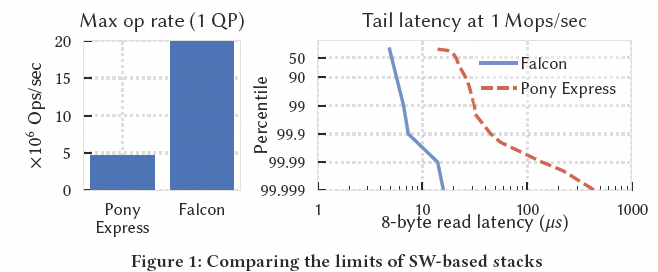
作者给出的目标非常清晰:
- 基于商用以太网数据中心网络连接计算、存储与加速器;
- 通过行业标准接口(如 IB Verbs、NVMe)支持混合工作负载;
- 在多样网络条件(丢包、乱序、超售、多租户、异构拓扑)下仍保持可预测性能。
从云的视角看,“标准接口”极其关键:标准接口意味着更低的迁移成本与更好的生态兼容。文章后续也多次围绕这一点展开对比。
此外,作者也指出硬件传输在可靠性、拥塞控制、多路径方面往往落后于软件传输(Google 在软件侧已有 Swift/RACK-TLP、PLB/PRR 等能力),Falcon 的一个重要动机就是把这些“生产级能力”带回硬件路径。
论文也给出了核心设计要点概览:
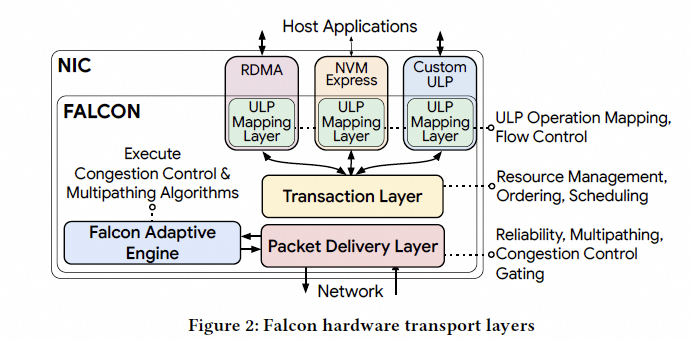
2. 现有硬件传输的不足及业务需求
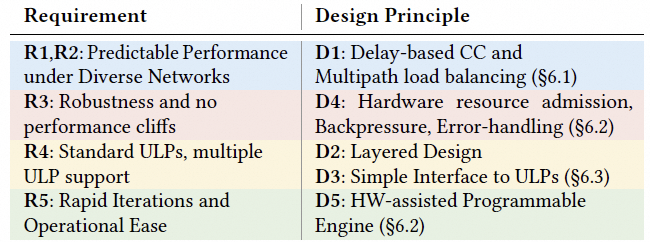
2.1 业务需求(R1-R5)
这一章的方法论做得很扎实:作者先定义“好的硬件传输协议应该满足什么”,再用它批判 RoCE 的不足。五个需求(R1-R5)构成评估框架:
- R1:可预测性能(Predictable Performance)
强调不是“平均值”,而是 稳定性与接近最优,尤其关注长尾。
- R2:适应多样化网络(Adaptability to Diverse Networks)
要能在超售、多租户、异构拓扑等“真实网络”里生存。
- R3:压力下鲁棒性(Robustness under stress)
高带宽、高 Mops、海量 QP,同时应对乱序、丢包、抖动、拥塞等极端情况。
- R4:兼容性
支持 IB Verbs 与 NVMe,尽量不改应用。
- R5:易运维与可演进
不希望“修一个问题就得换硬件”,需要机制与策略分离与在线迭代能力。
这五条几乎就是“云上通用 RDMA/存储网络”的现实约束集合。
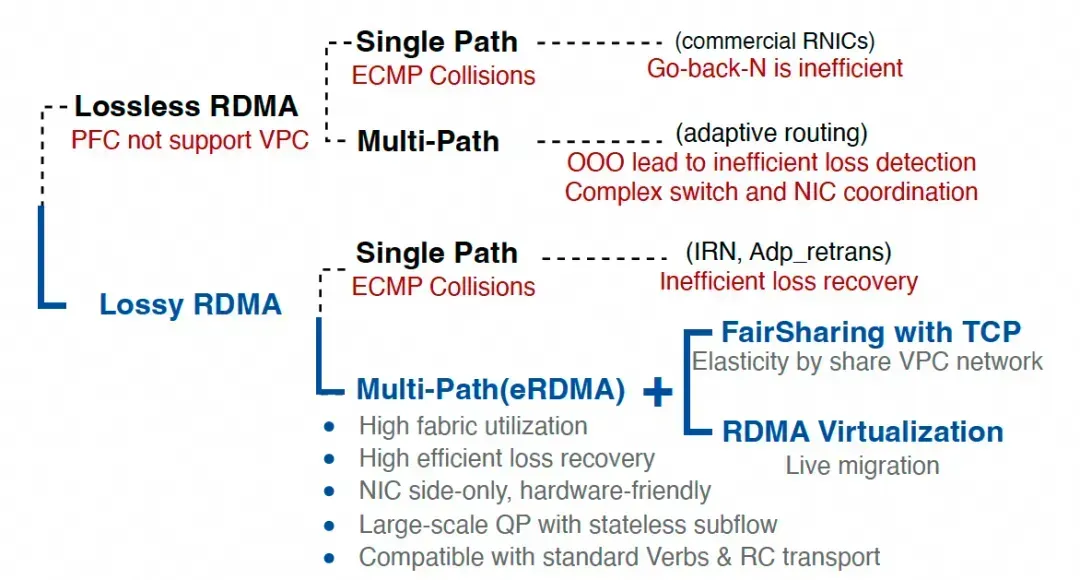
2.2 RoCEv2 的缺陷
论文用 R1-R5 框架系统性批判 RoCE,结论是:RoCE 继承了 Infiniband 时代“近似无损”的基因,在有损、多路径的以太网环境中会暴露结构性问题。
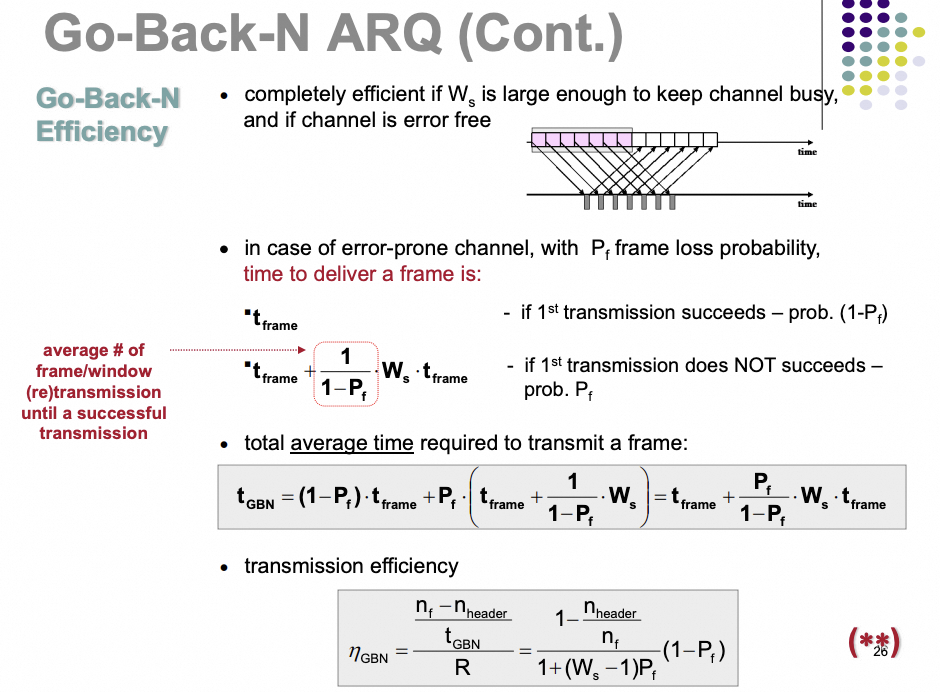
缺陷一:丢包恢复机制落后
- 传统 RoCE 依赖 Go-Back-N,丢一个包可能回退重传一串包。
- 即便启用 Selective Repeat(SR),也存在:
- 非通用:并非所有 RDMA 操作都支持;
- 低效:NACK 触发的恢复慢且不精确;
- 语义冲突:丢包后乱序交付会冲击 IB Verbs 语义。
RoCE 接收端为了维持顺序,丢包后往往丢弃乱序到达包,导致无法像 TCP 那样精准反馈缺失区间;如果要上 SACK 级别信令,通常需要大改硬件缓冲或调整语义。
论文里也用公式与图说明了 Go-Back-N 的丢包容忍性问题:
缺陷二:协议层不支持多路径
多路径天然带来乱序,而 RoCE 的丢包检测与严格保序语义对乱序非常敏感,很容易把乱序误判为丢包,触发伪重传、队列膨胀、吞吐下降,最终很多系统又不得不回到 PFC(无损)来掩盖路径差异,形成恶性循环。
缺陷三:拥塞控制与数据路径分离
RoCE 拥塞控制多为“外挂式”:依赖带外 probe 收集信号,响应迟缓。与之对照,Falcon(以及 TCP/Swift)强调带内信号与逐包响应,能在数据中心这种快速变化的环境里更及时地收敛。与拥塞控制相关的更通用网络基础可参考云栈社区的网络/系统专题资料。
3. 概述及设计原则
作者在这一章把 R1-R2 与 R3-R5 分开讨论:前者偏端到端性能,后者偏硬件实现与生态兼容。
3.1 Falcon Overview
Falcon 是面向连接(connection-oriented)的可靠传输,为 RDMA、NVMe 等 ULP 提供端到端可靠性,主要组件:
- ULP 映射层:把 RDMA/NVMe 操作映射到 Falcon 连接与事务,处理流控。
- 事务层(TL):请求-响应接口、资源管理、调度与排序。
- 包交付层(PDL):基于延迟的拥塞控制、时间轮整形、SACK/RACK-TLP 丢包恢复。
- Falcon 自适应引擎(FAE):可编程策略引擎,协同实现 CC 与多路径。
- 加密:可与 PSP/IPSec 等结合做认证与加密。
Falcon 的分层设计继承了 Pony Express 的思想,但职责拆分不同:Falcon 让 TL 负责 ULP 操作排序,而分片更多由 ULP 自己处理。
3.2 在多样网络中实现可预测性能(D1)
作者认为很多接收端驱动方案(Homa/NDP/EQDS/pHost)依赖“网络无超售”的假设不现实;Packet Spray 需要相对同构拓扑,对跨域或异构网络不友好。因此 Falcon 的关键原则是:
D1:基于延迟的拥塞控制 + 多路径负载均衡
- 基于 Swift 的逐包 RTT 测量,利用多时间戳把延迟分解到主机、NIC 与网络;
- 用时间轮(Carousel / Timing Wheel)做细粒度整形,改善公平性并降低拥塞队列;
- 多路径侧用 subflow + PLB/PRR 做“实时调度 + 保护性换路”。
丢包恢复方面,Falcon 选择 SACK + RACK-TLP:用时间启发式区分乱序与丢包,并对尾部丢包用 TLP 加速恢复。
3.3 硬件设计挑战与原则(D2-D5)
硬件实现必须同时覆盖“顺序到达的快路径”和“丢包/乱序/超时/错误”的常态路径,并在 O(100K) 连接规模下避免性能断崖。因此作者提出:
- D2:分层设计
明确职责边界,降低硬件复杂度。
- D3:支持多 ULP 的简单接口
用统一事务接口接入更多协议。
- D4:带反压与错误处理的资源准入
通过片上缓冲吸收乱序,硬件快速重传,逐连接反压实现隔离,避免错误路径拖垮吞吐。
- D5:硬件辅助的可编程引擎(FAE)
策略在软件可迭代,机制在硬件线速执行。
软硬件划分图:

4. 详细设计
4.1 可靠性:bitmap SACK + RACK-TLP
Falcon 的目标是在乱序与丢包都常见的情况下,尽量少重传并尽快恢复。
-
接收端(RX)
用 bitmap 维护接收窗口的 PSN 状态,并在 ACK 中携带。只要片上资源允许,会接收乱序包,甚至包含窗口之外的数据包(这会带来实现复杂度,但可提高鲁棒性)。论文示例中使用 128-bit bitmap。
-
发送端(TX)
收到 ACK 后,结合时间戳与 bitmap 用 RACK 启发式定位需要重传的包:
1) bitmap 标记已收的包忽略;
2) 在“约一个 RTT 内”的包先不触发重传,避免把乱序当丢包;
3) 超过 rack_rto 的包触发重传。
-
TLP(Tail Loss Probe)
长时间无进展时发送探测包,促使接收端回 ACK,再由 RACK 推动快速恢复。
-
FAE 的作用
根据网络 RTT 与抖动动态计算 rack_rto 与 TLP 参数,实现“机制/策略分离”。
这一设计在“有损 + 多路径乱序”场景下尤其关键:RACK 的时间窗口本质上把发送窗口分成“乱序容忍区”和“真实丢包区”。
关于 bitmap 方式的一个工程取舍:窗口大小受 bitmap 覆盖范围限制。若链路 BDP 非常大(例如更高带宽、更长 RTT 的跨域路径),窗口绕回与覆盖不足可能会带来额外复杂性,需要在实现上进行补偿设计。
4.2 可编程拥塞控制:fcwnd + ncwnd(Swift 变体)
Falcon 把拥塞控制拆成两层:
- FAE:实现 CC 算法,根据 CC 信号计算窗口;
- PDL:测量信号并用调度器 + 时间轮执行窗口。
Falcon 使用两个窗口:
fcwnd:网络拥塞窗口(Fabric Congestion Window)ncwnd:NIC 拥塞窗口(NIC Congestion Window)- 有效窗口为两者的最小值。
网络拥塞信号(Fabric):用硬件时间戳测 RTT 分量。数据包携带 t1,远端记录 t2,ACK 携带 t3 和最新 t1/t2,本地记录 t4,无需时钟同步即可估算网络延迟:
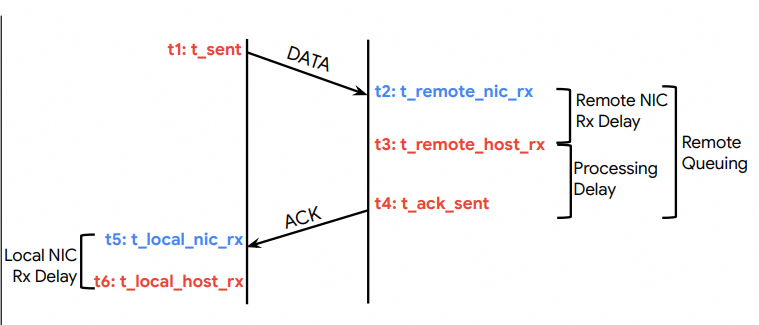
接收端 NIC 拥塞信号(Rx NIC):用 Rx 缓冲区占用率作为反馈,随 ACK 返回给发送端,驱动 ncwnd,防止“网络没堵但接收端 NIC/主机侧堵了”的隐性拥塞导致丢包。
4.3 多路径:subflow + Flow Label + 逐流 fcwnd
多路径是 Falcon 的核心元素:单连接通过多条路径提升单连接性能与鲁棒性。它需要两类决策:
- 为连接选择一组路径(subflow 集合)
- 为每个包选择具体 subflow
Falcon 的做法是为每个连接维护一个 flow 列表,每个 flow 对应一个 IPv6 Flow Label,交换机在 ECMP/WCMP 之外对 Flow Label 参与哈希,使不同 flow 映射到不同路径:
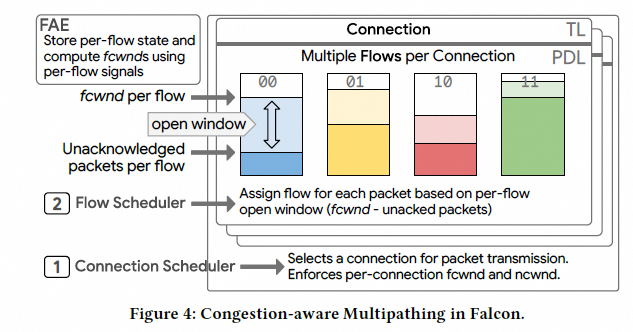
Falcon 的关键取舍:
- 连接内共享 PSN 空间:降低 per-flow PSN 带来的状态开销与硬件复杂度;
- 逐流维护拥塞状态与 fcwnd:提升调度精度;
- PDL 负责调度,FAE 负责窗口与 Flow Label 重新分配(PLB/PRR);
- 可靠性机制(bitmap + RACK-TLP)要能在跨流乱序下正常工作。
工程上需要注意的复杂度点:
- 若每连接 subflow 很多,而连接数达到 O(100K),逐流 fcwnd 的计算与状态管理会显著抬高成本;
- subflow 较少时又可能出现单 subflow 大象流;
- PLB/PRR 与 Swift 的协同不好做,收敛速度与稳定性取决于实现细节。
总体上,Falcon 的优势在于:无需依赖交换机特殊能力即可实现多路径(基于 Flow Label 的信息熵扩展),并把多路径机制封装在传输层内。
4.4 支持多种 ULP:Push/Pull 事务模型
Falcon 用统一的 Request-Response Transaction 接口承接多 ULP。核心抽象是两类事务:
- Push:请求方向响应方发送数据(如写)
- Pull:请求方从响应方接收数据(如读)
ULP 操作到 Push/Pull 的映射如下:

接口设计要解决两点:
- 事务类型是否感知?
Falcon 选择“类型感知”,以避免请求-响应死锁,并能更精细地做拥塞控制与调度(例如 Pull 响应不受 ncwnd 约束,因为请求方已预留接收资源)。
- 事务粒度是什么?
选择 MTU 粒度:大操作拆成多个 MTU 级 Pull 事务,使资源管理更细粒度、硬件更简化。
排序语义:每连接可配置 ordered 或 unordered。ordered 兼容 IB Verbs 的严格语义;unordered 面向现代应用的独立操作。排序依赖 RSN(请求序列号),而不仅是 PSN。
有序写操作示意:
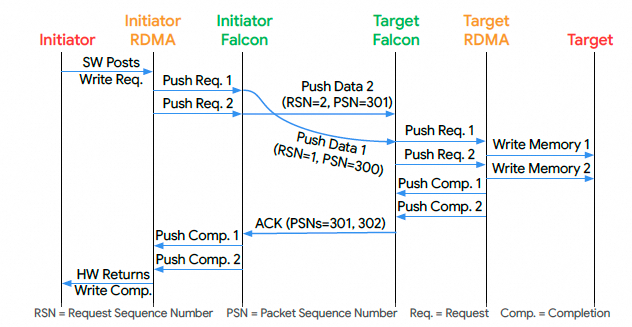
增强错误通知:除了兼容传统语义,还支持更细粒度的 “CIE(Complete in Error and Continue)”,允许单操作错误不必导致整连接终止,提升大规模系统稳定性。
4.5 硬件资源管理:避免死锁与抖降
Falcon 引入片上资源支持乱序接收与可靠性,资源分两类:
- contexts:固定大小元数据(序列号、排序/可靠性状态等)
- buffers:可变大小元数据与数据包载荷
为避免请求-响应协议中的死锁,TL 需要精细的资源划分与生命周期管理。
资源划分(Resource Carving):
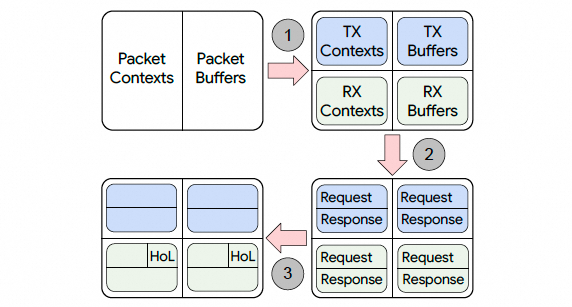
- TX / RX 分池:避免“只发不收/只收不发”死锁
- Req / Resp 分池:避免请求耗尽资源导致响应无法推进
- HoL / non-HoL:保障有序连接的协议推进(HoL 资源阈值以上只接纳队头请求)
资源生命周期:发起方在发出请求时同时预留 Tx 与对端响应的 Rx 资源,从源头抑制反向路径 incast,并保证响应总有资源可接收。
当资源耗尽:
- 对 ULP 通过 Xon/Xoff 反压;
- 对网络侧通过资源 NACK 反馈。
4.6 连接隔离:动态阈值 + 逐连接反压
没有隔离时,慢连接会长时间占用资源,拖慢快连接。Falcon 在 TL 中实现隔离:
- 逐连接 Xon/Xoff 反压;
- 类似交换机缓冲管理的 动态阈值(DT);
- FAE 动态调节 DT 的参数,使“慢连接少用资源、快连接多用资源”,提升公平性与尾延迟表现。
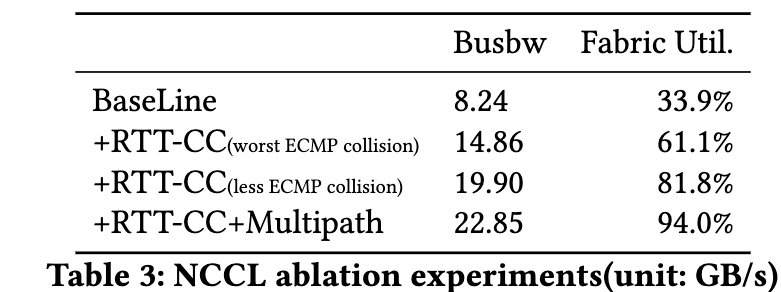
5. 可扩展硬件传输的实现经验
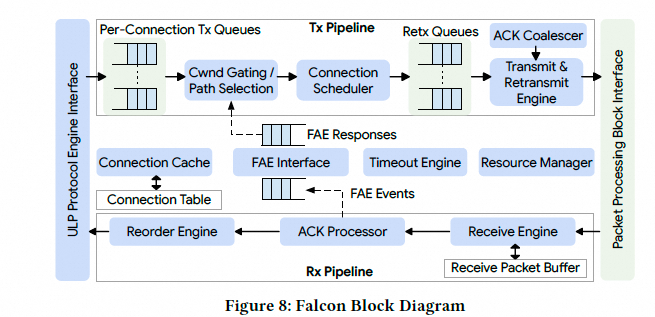
5.1 集成到 NIC/IPU
Falcon 被做成独立 HW 模块,可集成到 FNIC 或 IPU。论文描述它已集成到 Intel E2100 200Gbps IPU,并扩展到 400/800Gbps。Falcon 依赖:
- 独立 Timing Wheel 模块(或内置)
- 靠近以太网端口的精确时间戳
- 常与内联加密模块协同(利用 PSP/IPsec 的字段携带信息)
集成示意:

Falcon 硬件框图:
5.2 值得注意的实现选择
片上 NIC 资源(On-NIC Resources)
为了乱序缓冲,需要按 BDP 量级规划缓冲。论文给出 200Gbps/50us RTT BDP 约 1.2MB,400Gbps 约 2.4MB,800Gbps 约 4.8MB,并认为在先进工艺下面积开销可控。极端 corner case 还允许从片上 SRAM 溢出到外部 DRAM。
连接状态缓存(Connection State Caching)
在超大规模下缓存 miss 率接近 100% 会导致吞吐和延迟断崖式下降。Falcon 为缓存 miss 预留足够内存带宽,并引入更大的二级缓存以改善 miss 带宽与延迟,代价是面积与带宽开销,但换来“可预测持续性能”。
错误处理(Error Handling)
传统做法把异常留给固件,Falcon 为避免性能抖降,将丢包恢复与错误处理尽量硬件化:维护逐包上下文,硬件线程扫描链表处理超时与重传。
5.3 FAE 的实现与扩展
FAE 运行在 IPU 的通用 CPU 核上,通过共享内存队列与 PDL 通信,采用事件-响应格式:
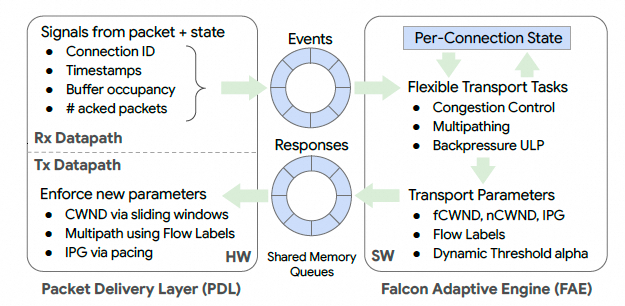
论文总结的“机制在 PDL,策略在 FAE”的映射大致包括:
- 可靠性:ACK bitmap、RACK、TLP(PDL) + RTO/阈值计算(FAE)
- 拥塞/流控:窗口与 pacing(PDL) + fcwnd/ncwnd/IPG/目标延迟等计算(FAE)
- 多路径:路径感知调度器(PDL) + Flow Label 分配与逐流 CC(FAE)
- 隔离:动态阈值机制(PDL) + alpha 等动态参数(FAE)
为解决状态管理导致的 cache miss,FAE 从“无状态(PDL 携带状态)”演进到“有状态 + prefetch”,在处理事件前预取后续事件对应状态,降低 miss 代价。
6. 评估
论文评估 Falcon 的可靠性、多路径、硬件性能以及对 MPI/HPC 和热迁移的影响。测试平台为 32 台机器,Falcon NIC 200Gbps;对比 NVIDIA CX-7 400Gbps(RoCE,RTTCC)。多路径与 RACK-TLP 等部分由于缺少大规模真实组网,使用硬件仿真验证的模拟器,拓扑类似 Jupiter 三级网络。
6.1 Falcon 协议性能(对比 RoCE RC)
6.1.1 丢包恢复
丢包影响(goodput):点到点单 QP,8KB 消息,200Gbps,交换机制造丢包/乱序。

结果显示:丢包率上升时 Falcon 吞吐基本维持线速;RoCE(GBN/SR/AR)吞吐显著下降,即便 SR 在 1% 丢包也明显落后。核心原因是 Falcon 的 SACK/RACK-TLP 能精准重传缺失包并快速恢复。
乱序影响与 RACK-TLP:乱序率增加时 Falcon 仍稳定,RoCE 尤其 GBN 几乎崩溃。RACK 用时间启发式区分乱序与丢包,显著降低伪重传。
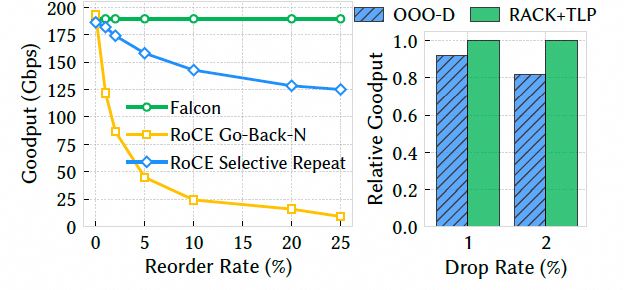
右图还显示:相较早期 OOO-D(按乱序距离)算法,RACK-TLP 吞吐提升 7–18%,TLP 对尾部丢包尤为有效。
RoCE 不同模式对比:加入 Adaptive Routing 后表现更差。
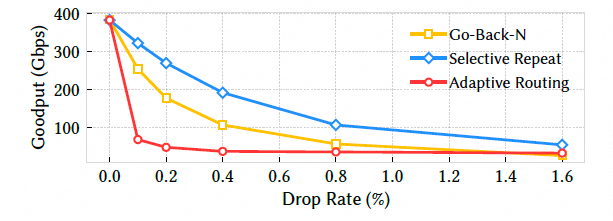
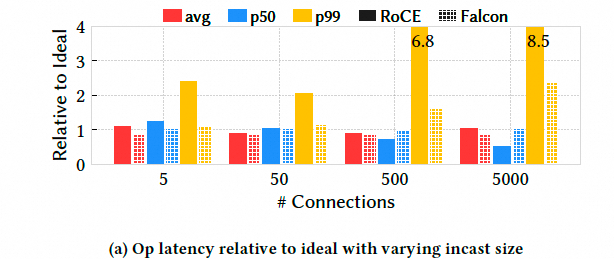
6.1.2 拥塞控制
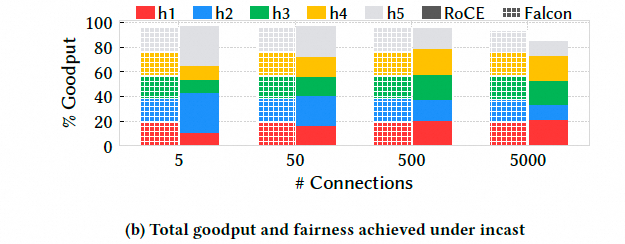
Fabric 拥塞与 incast:5→1 incast,5000:1 压力下 Falcon p99 延迟约为理想值 2 倍,RoCE 高达 8.5 倍;Falcon 总吞吐近线速,RoCE 丢失 13%。说明 Swift 变体在高拥塞下更快、更准地响应。
Host 拥塞(接收端 PCIe 降速):展示 ncwnd 的价值。Falcon 能在约 5 个 RTT 内收敛到瓶颈带宽,瓶颈解除后也能更快恢复。
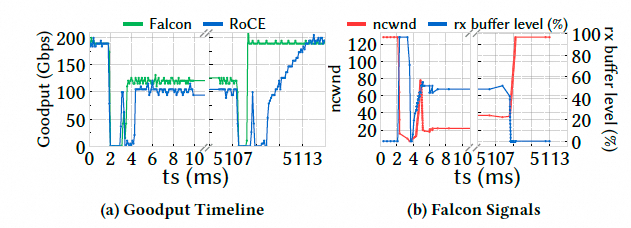
6.1.3 多路径(仿真)
这一节基于仿真:两 Rack 各 24 host,对比单路径与多路径。
- 高负载下多路径延迟可显著降低,并能承受更高网络负载:
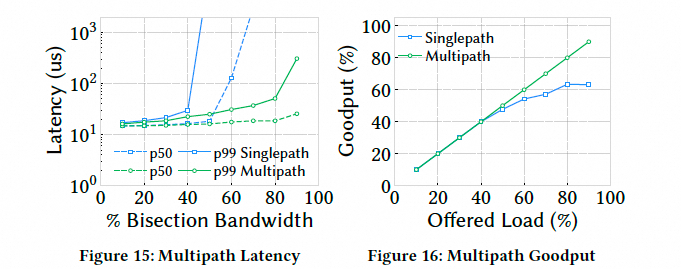
- 拥塞感知调度优于简单轮询(高负载下低 2–4 倍延迟):
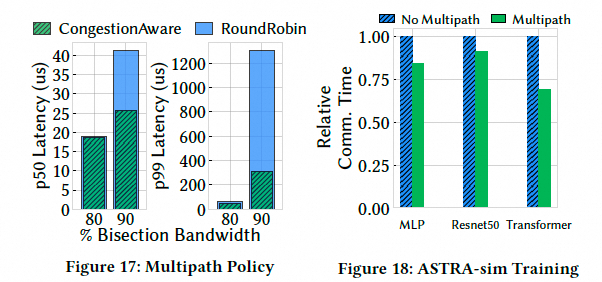
- ASTRA-sim 模拟训练:多路径可减少通信时间并带来训练时间收益:
6.1.4 硬件性能
不同消息 size 的延迟:
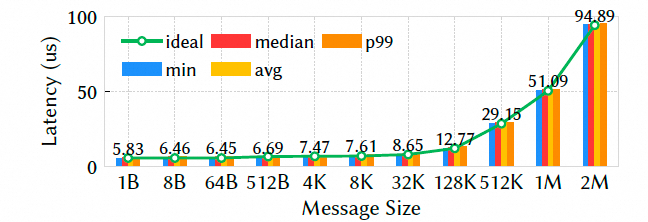
Falcon p99 与中位数很接近,尾延迟控制较好。
带宽可扩展性与 Mops:单 QP 可达 20Mops,12 个 QP 达到 120Mops 峰值。

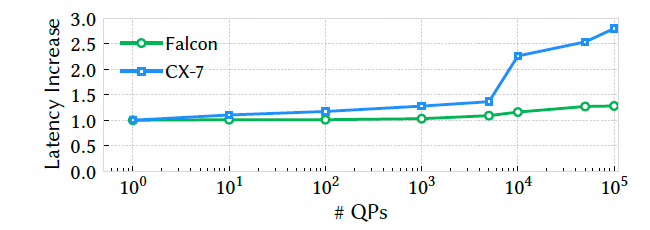
连接数扩展:对比 CX7,QP 增加后 CX7 延迟陡增,Falcon 更稳定:
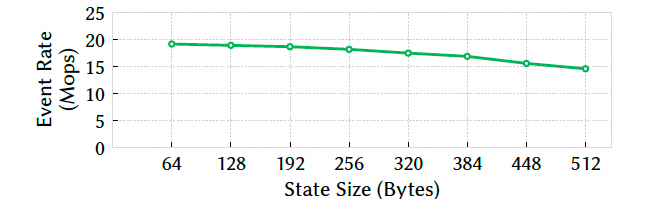
FAE scaling(prefetch):带 prefetch 的 FAE 在百万连接下仍保持稳定处理速率,并对响应延迟与 state size 较不敏感:
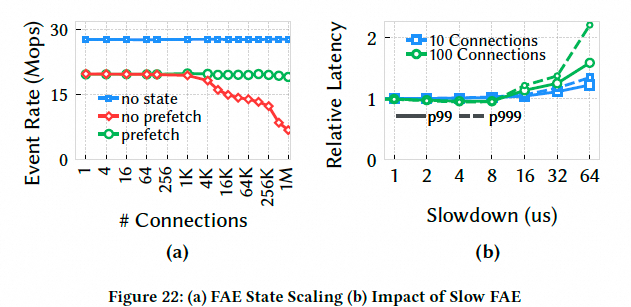
隔离性:混合快流与慢流,无隔离时快流延迟增加 63 倍;启用动态反压后控制在约 3 倍:
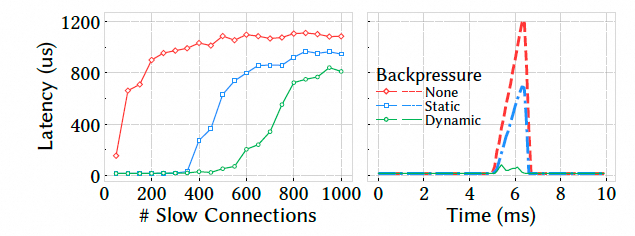
6.1.5 真实应用
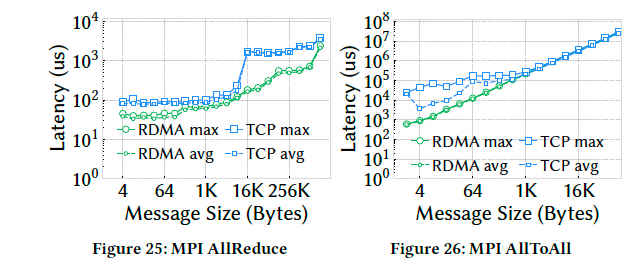
- MPI 集合通信(AllReduce/AllToAll):RDMA-Falcon 相对 TCP 提升 4.3–5.5 倍:
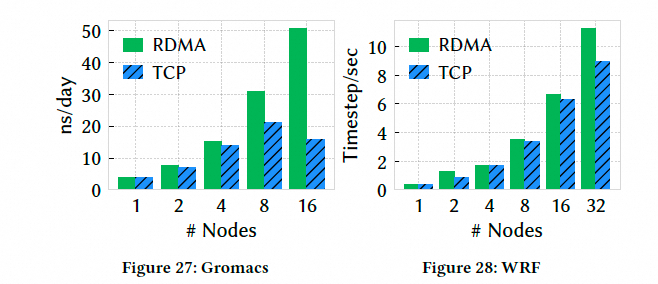
- HPC 应用(GROMACS、WRF):性能提升与时间缩短:
- NVMe-over-Falcon:网络存储可达本地 SSD 90%+:

- VM 热迁移:相较 Pony Express,关键阶段加速明显:
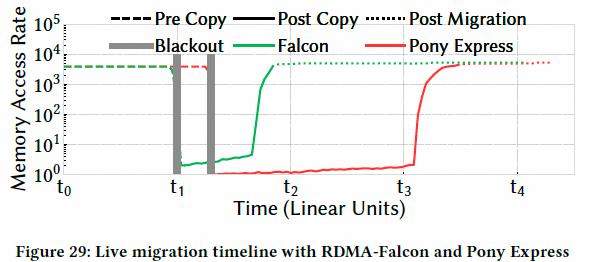
7. 相关工作要点(论文视角梳理)
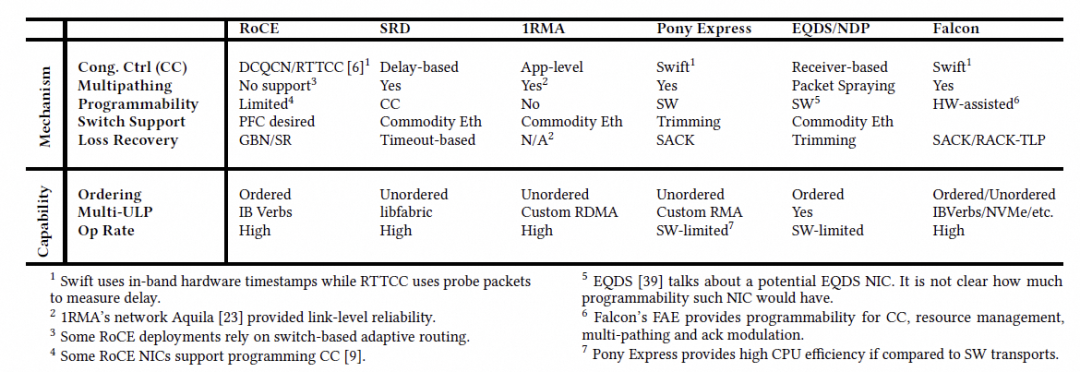
论文用表格对比了多类方案(CC、多路径、可编程性、接口等):
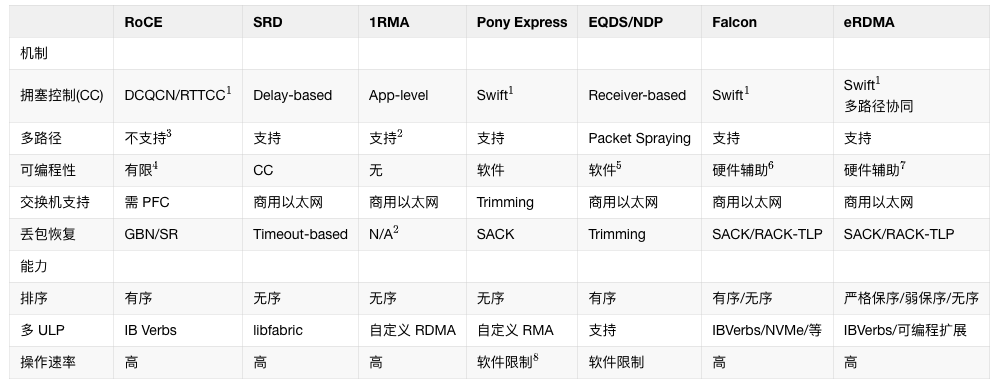
其中几个对比点值得关注:
- Swift vs RTTCC:Swift 强调带内时间戳,RTTCC 偏带外 probe;
- UET(UEC):偏 libfabric,与 IB Verbs 生态兼容路径不同;
- SRD:更偏应用侧排序与接口选择;Falcon 强调“多路径 + 仍兼容 IB Verbs 严格语义”。
8. 总结:Falcon 的价值与边界
论文给出的总结要点是:Falcon 试图把硬件传输从“专用无损网络”带到“通用有损以太网数据中心”,并同时覆盖专用与通用工作负载。其关键特征包括:
- 分层架构(ULP/TL/PDL/FAE)
- 硬件机制 + 软件策略(可演进)
- 原生多路径(同时兼顾有序语义)
- SACK/RACK-TLP 等现代可靠性机制
- 不依赖 PFC、无需特殊交换机功能即可获得可预测性能
从工程取舍角度看,Falcon 的设计亮点在于:在保持 IB Verbs 兼容的前提下,把“有损 + 多路径 + 可预测性能”这组矛盾约束尽可能同时满足;其挑战与潜在代价也集中在:片上资源规划、连接状态缓存体系、逐流状态与算法收敛、以及在极端 BDP/跨域场景下窗口与状态管理的复杂度。
参考资料
- Falcon: A Reliable, Low Latency Hardware Transport
https://dl.acm.org/doi/10.1145/3718958.3754353
- 转自公众号作者:zartbot
 发表于 2025-12-24 17:09:18
|
查看: 320|
回复: 0
发表于 2025-12-24 17:09:18
|
查看: 320|
回复: 0
