本文系统回顾了2017年至2020年间,深度学习技术在视频编码帧内预测领域的关键进展。综述涵盖了全连接神经网络(IPFCN)、卷积神经网络(CNN)、混合网络以及生成对抗网络(GAN)等多种模型。这些模型通常以相邻的重建像素或结合传统预测值作为输入,输出更精确的当前块像素预测,旨在提升整体编码效率。实验表明,这些方法能有效降低码率,提升预测精度。文章将深入解析不同网络结构(如多尺度卷积神经网络MSCNN、卷积编码解码网络IPCED)如何针对不同尺寸的编码块进行优化,并探讨将深度学习预测模式与传统模式集成的不同策略。
在视频编码标准如 HEVC/H.265 中,帧内预测是利用空域相邻已重建像素来预测当前块像素值的关键技术。传统方法依赖于角度模式、DC模式和Planar模式。随着 人工智能 技术的发展,基于深度学习的帧内预测已成为研究热点,其主要网络类型可归纳为:
- 全连接神经网络(FCN)
- 卷积神经网络(CNN)
- 全连接与卷积网络的结合
网络的输入输出主要分为两类:
- 直接预测:输入相邻重建像素,直接输出当前块的预测像素。
- 预测增强:输入相邻重建像素和HEVC的传统帧内预测像素,输出增强后的预测像素(相当于对传统预测结果进行 refinement)。
以下是按技术路线梳理的各代表性工作详解。
全连接神经网络(FCN)方案
1. 基于全连接网络的图像编码帧内预测 (IPFCN)
这是首篇将全连接神经网络用于帧内预测的研究,称为IPFCN(Intra Prediction using Fully Connected Net)。
网络架构
对于待预测的 N×N 块,网络输入是其相邻的重建像素(共 4N*L + L² 个像素,L 常设为8),经过 K 层全连接网络,最终输出预测的 N×N 个像素。除最后一层外,其余层均使用 PReLU 作为激活函数。
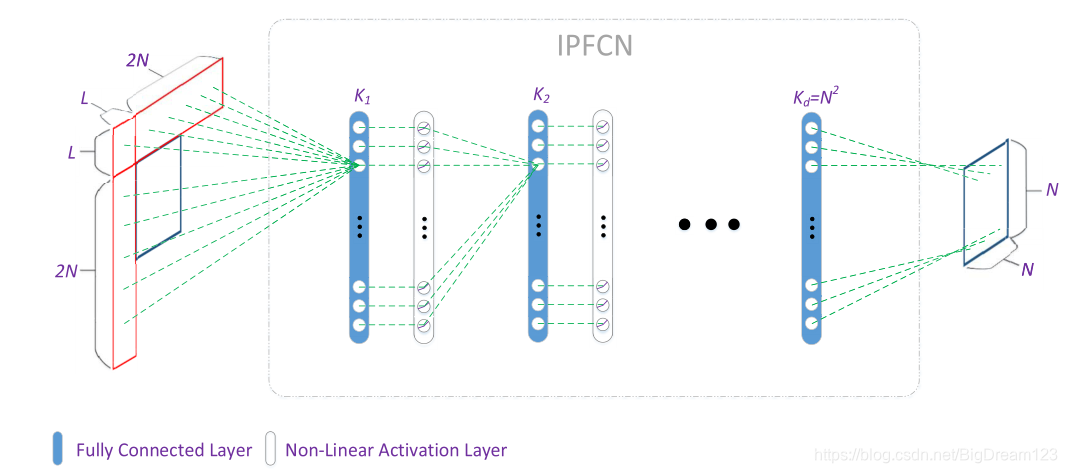
图1:IPFCN 全连接网络架构示意图
训练策略
- 损失函数:采用欧式损失,并添加正则项防止过拟合。
- 训练数据:使用 New York city library 图像库,通过 HM 编码器在 QP {22, 27, 32, 37} 下编码,并将所有QP下的数据混合训练,使一个网络能适应不同量化参数。
- 数据筛选:为剔除过于复杂、不具备普适性的图像块,计算每个块的原始值与预测值之间的 MSE,并保留那些 MSE 小于整图平均 MSE 两倍的块。
- 两种模型:
- IPFCN-D:将训练数据按传统模式分类(角度模式 2-34 为一类,DC 和 Planar 为另一类),分别训练两个模型。
- IPFCN-S:使用全部数据训练单一模型。
网络超参数分析
作者通过实验确定了最佳网络结构:
- 深度:4层网络在性能与复杂度间取得了最佳平衡。
- 宽度(维度):针对不同块大小,4×4块使用512维,8×8和16×16块使用1024维,32×32块使用2048维。
集成与性能
将IPFCN集成到HM16.9中,在CTC All Intra配置下测试。结果表明,IPFCN-D平均可节省约3.4%的BD-rate,IPFCN-S平均节省约2.9%。
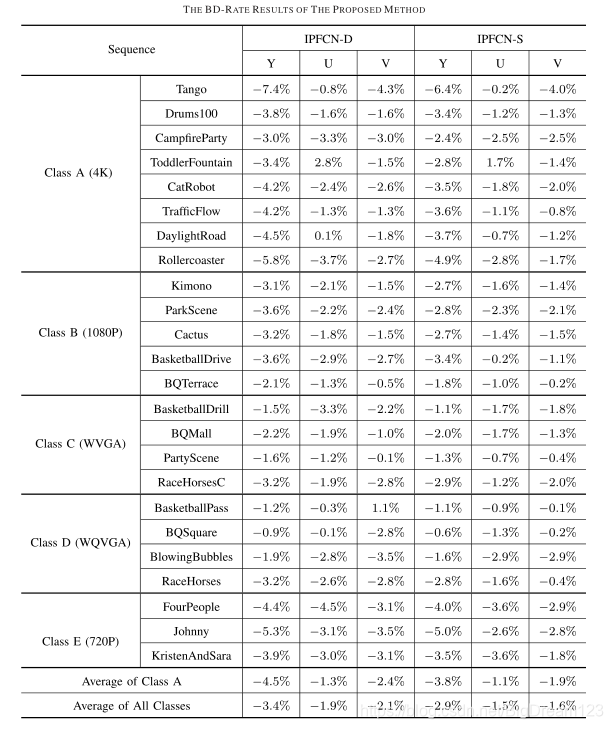
图2:IPFCN-D 与 IPFCN-S 在 HEVC 测试序列上的 BD-rate 节省性能
2. 基于神经网络的视频编码帧内预测
该工作同样使用全连接网络,并创新性地引入了第二个网络来动态选择预测模式。
双网络结构
- 预测生成网络:一个4层全连接网络,输入为当前块上方两行和左侧两列的重建像素,直接输出预测像素。
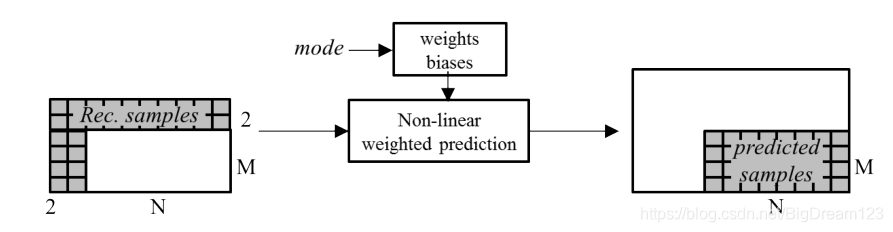 图3:用于生成预测信号的全连接网络结构
图3:用于生成预测信号的全连接网络结构
- 模式决策网络:另一个全连接网络,输入为相邻重建像素,输出为各种神经网络预测模式的概率分布。编码器选择概率最高的模式,并将该模式索引传至解码端。
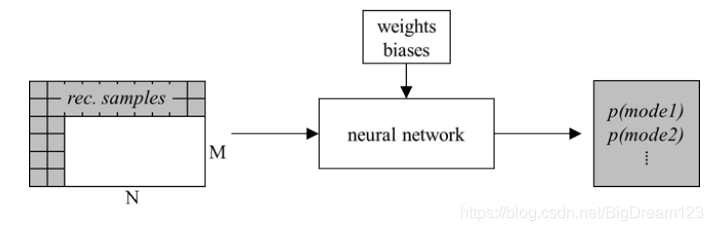 图4:用于选择最佳预测模式的神经网络结构
图4:用于选择最佳预测模式的神经网络结构
性能表现
该方案在标准测试序列上取得了显著的码率节省,具体性能如下图所示。
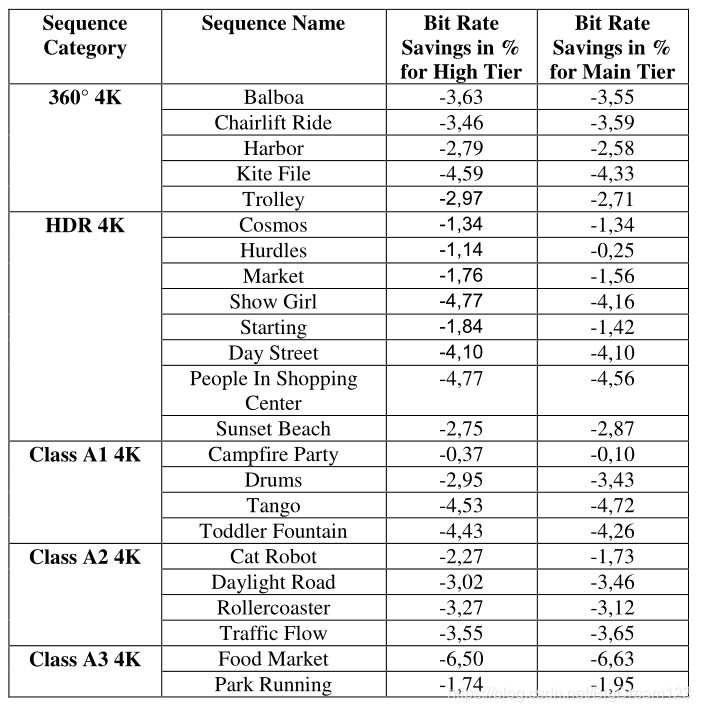
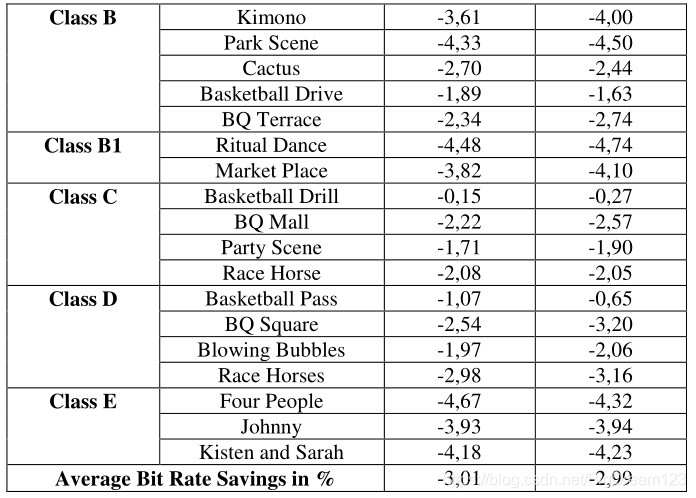
图5:该方案在 High Tier 和 Main Tier 配置下的比特率节省情况
卷积神经网络(CNN)与混合网络方案
3. 上下文自适应的神经网络预测
本文提出了一种混合网络策略,核心思想是:全连接网络更擅长处理小块,而卷积网络对大块性能更优。因此构建了一个预测神经网络集(PNNS),针对不同块大小切换使用不同的网络。
核心洞察
- 网络选择:对 4×4 和 8×8 块使用全连接网络,对更大块使用卷积网络。
- 训练数据:提出使用原始(未失真)数据训练的神经网络,能够很好地泛化到不同QP下的重建像素,简化了训练流程。
网络结构
- 全连接网络(用于小块):
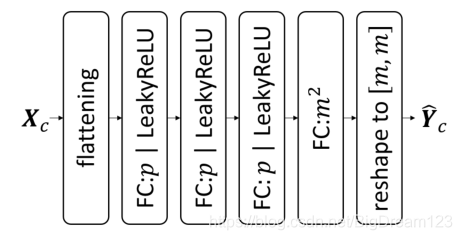
- 卷积网络(用于大块):
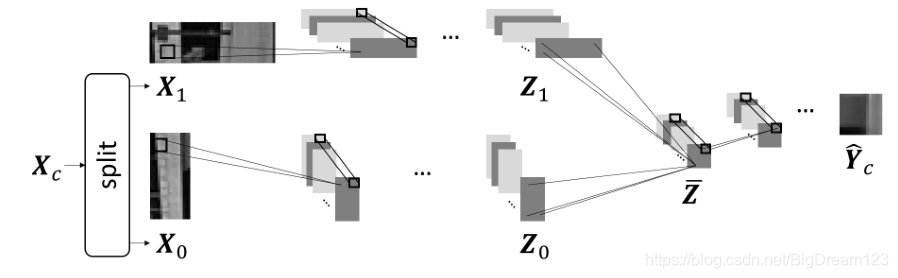
集成策略
在HEVC中提出了两种集成方式:
- 替换(Substitution):用PNNS替换传统模式中最不常用的一个模式(如模式18)。
- 切换(Switch):在RDO过程中,让传统模式和PNNS模式竞争,选择率失真代价更优者。
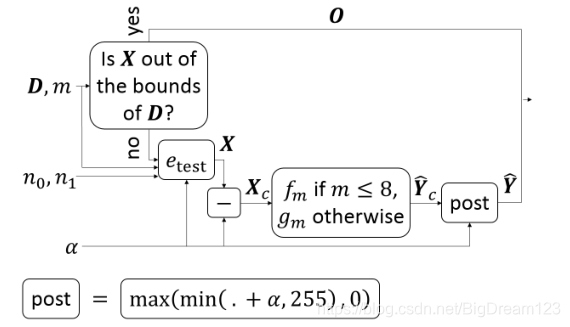
图6:PNNS在HEVC中的集成流程图
性能对比
PNNS-Switch方法的性能优于之前提出的IPFCN方案。
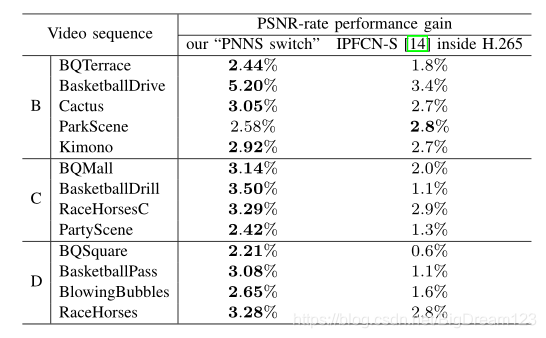
图7:PNNS-Switch 与 IPFCN 的 PSNR-Rate 性能增益对比
4. 基于卷积编码解码网络的帧内预测
本工作提出了一种称为IPCED的卷积编码器-解码器网络。
- 编码器:采用多尺度跳跃连接结构,融合深层全局特征与浅层局部特征。
- 解码器:采用多级分支,以由粗到精的方式合成预测结果。
网络针对4×4, 8×8, 16×16, 32×32的TU分别设计。输入是当前PU的HEVC传统预测值及其三个相邻重建块,输出是优化后的预测值。
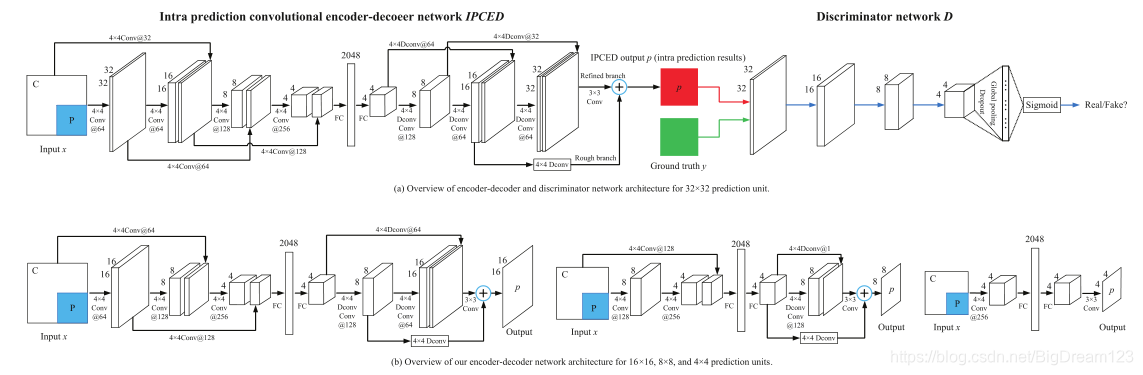
图8:IPCED 网络结构(含鉴别器D,仅用于训练)
对抗训练
为提升预测图像的真实感,在训练中引入了GAN思想:
- 生成器(G):即IPCED网络,其损失函数为 MSE损失 和 对抗损失 的加权和。
- 鉴别器(D):用于区分预测块和原始块,促使生成器产生更自然的纹理。
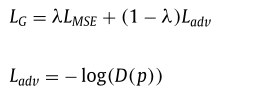
图9:生成器(G)的混合损失函数公式
性能
在HM16.0上的测试表明,IPCED能显著提升编码效率,并在不同尺寸的PU上都被频繁选为最佳模式。
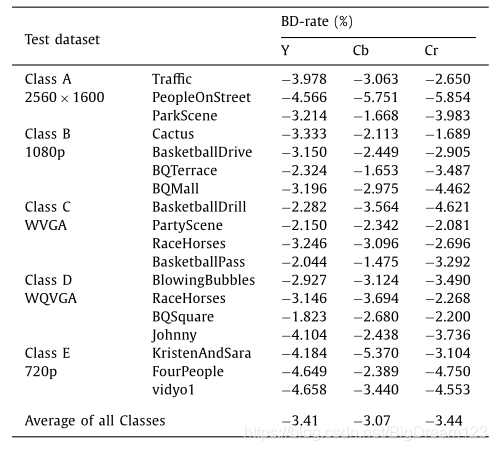
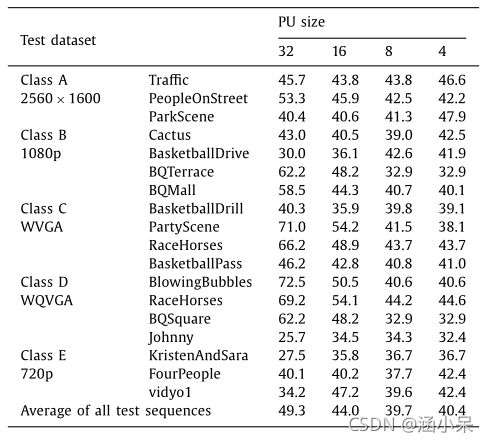
图10:IPCED的编码性能(左)及各尺寸PU被选为最佳模式的百分比(右)
5. 基于多尺度卷积神经网络的帧内预测
本文提出了多尺度卷积神经网络(MSCNN)。其动机是:不同大小的编码块需要不同大小的感受野来捕捉上下文信息。
网络架构
MSCNN分为两部分:
- 多尺度特征提取网络:通过不同比例的下采样、卷积和上采样操作,提取并融合多尺度特征,使用固定3×3卷积核即可有效覆盖大块像素的远程依赖。
- 重建网络:整合多尺度特征,生成最终预测。
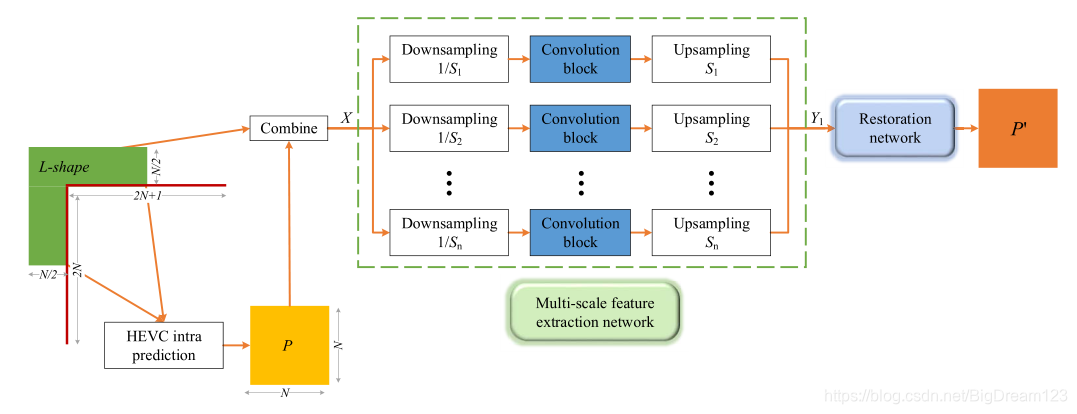
图11:MSCNN 整体网络结构示意图
针对不同尺寸的TU(4×4, 8×8, 16×16, 32×32),设计了不同复杂度的特征提取网络。
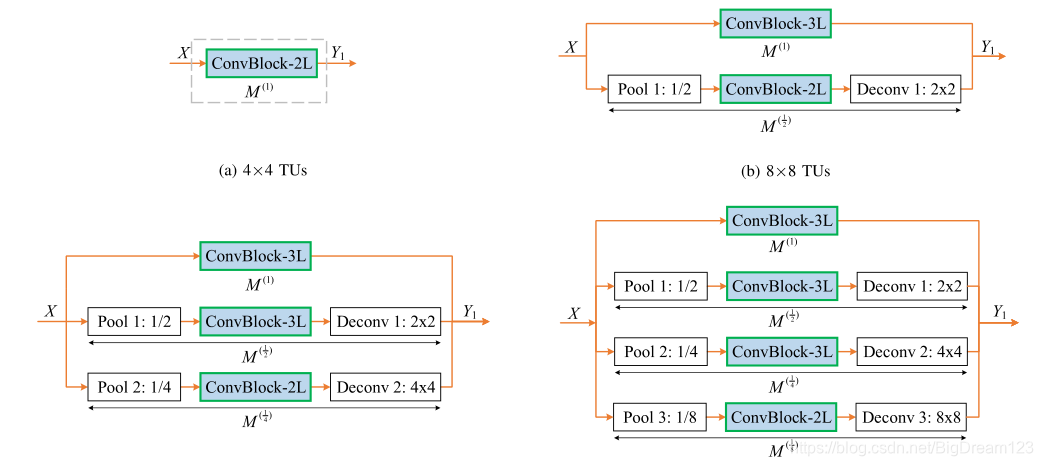
图12:针对不同尺寸TU设计的特征提取网络结构
训练与集成
- 训练数据筛选:仅对纹理复杂的块(即预测误差MSE大于一定阈值的块)进行训练,因为平坦区域传统方法已足够好。
- 集成:在CU级别设置标志位。在RDO过程中,MSCNN与传统模式一同参与竞选。
实验表明,MSCNN能有效节省码率,且在不同类型视频内容中均有应用。
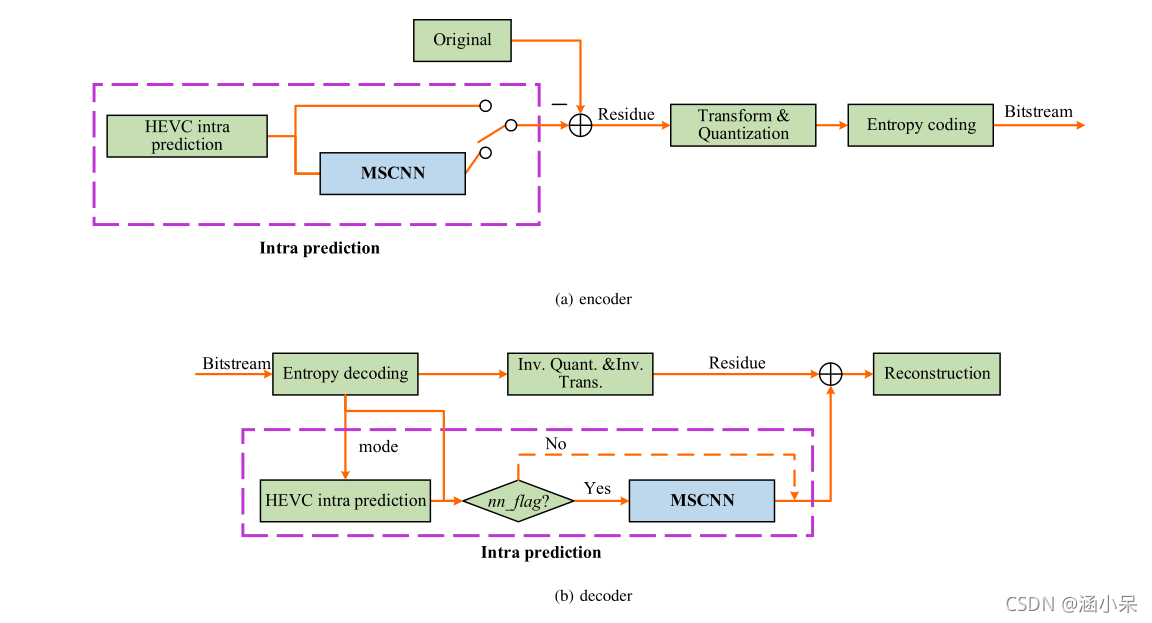
图13:MSCNN 集成于 HEVC 编码器与解码器的框图
生成对抗网络(GAN)方案
6. 基于生成对抗网络的帧内预测
本工作首次将GAN直接用于帧内预测,在CTU级别进行操作。
网络结构
- 生成器(G):输入当前CTU及其三个相邻重建CTU,输出预测的CTU像素。
- 鉴别器(D):包含全局鉴别器和局部鉴别器,分别用于判断整个重构图像区域和预测CTU块本身的真实性。
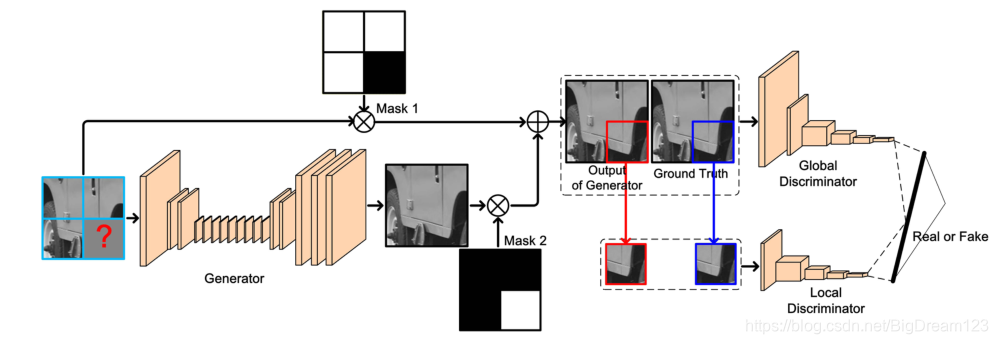
图14:基于GAN的帧内预测网络整体结构
多模式生成
通过为生成器输入不同的初始值(对应0-34共35种模式),可产生35种不同的预测结果。编码器遍历这些模式并选取RD代价最优者。
性能分析
实验证明,引入鉴别器能有效提升预测质量。与仅使用生成器(1 mode)相比,完整的GAN方案(35 modes)性能更优。
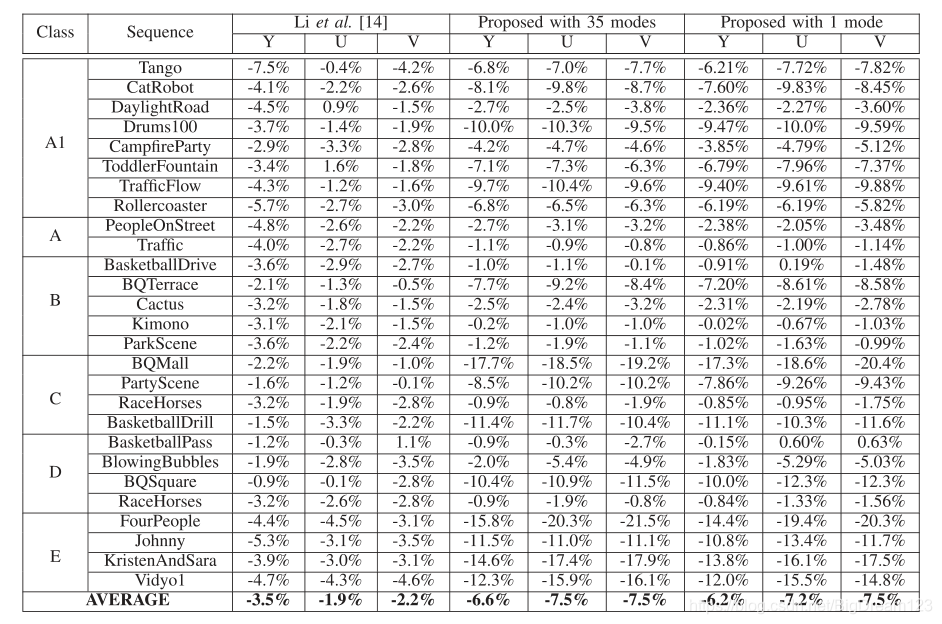
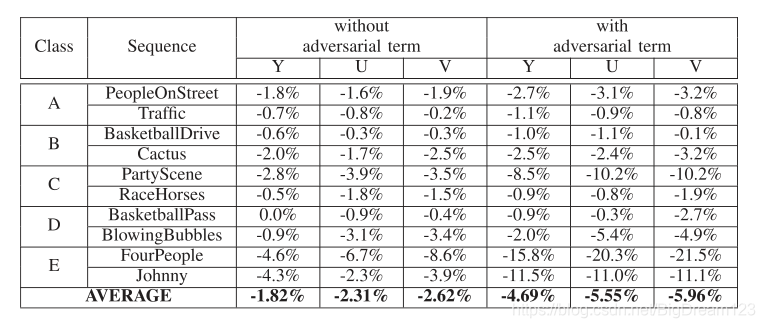
图15:GAN方案性能对比(左)及鉴别器作用分析(右)
前沿探索与总结
7. 使用多个神经网络增强帧内预测
本文重点探讨了将神经网络预测模式(NM)与传统模式(TM)集成的两种策略:
- 模式增加:在现有35个TM之外,新增若干个NM。需要重新设计模式编索引码。
- 模式替换:用NM替换掉一个或多个TM(如最常用或最不常用的模式)。
文中使用一个输入为五个相邻重建块的全连接网络作为NM,为相关研究提供了重要的集成方法论参考。
8. 全神经网络模式的变块大小帧内预测
这项工作激进地提出完全用神经网络取代传统的35种帧内预测模式。为4×4到32×32的每种块大小和每种“模式”都训练了对应的神经网络(4×4/8×8用FCN,16×16/32×32用CNN)。
工作流程
- 通过SATD代价初步筛选出少数候选模式。
- 将候选模式与MPM模式组成候选列表。
- 通过RDO比较,确定最终的最佳神经网络模式。
训练
采用“预训练 + 微调”策略:先用所有块数据预训练模型,再根据每种模式对应的最佳块数据对特定模型进行微调。
该方案展示了在 流媒体 等应用场景下,端到端深度学习预测取代传统手工设计模式的潜力,在HM16.9上取得了积极的编码增益。
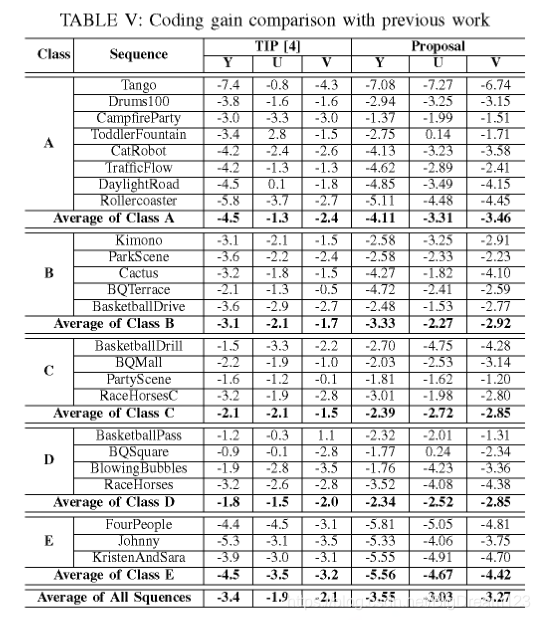
图16:全神经网络模式方案在HEVC中的性能表现
总结
从2017年到2020年,基于深度学习的帧内预测技术经历了从全连接网络到卷积网络、再到复杂生成对抗网络的演进。这些研究在 HEVC/H.265 框架内验证了深度学习提升编码效率的有效性,其核心思想、网络设计、训练技巧和集成策略为后续更先进的视频编码标准(如VVC)以及 人工智能 驱动的编码优化奠定了坚实基础。未来,结合 PyTorch、TensorFlow 等现代框架,设计更低复杂度、更高效率的神经网络预测模型,仍是该领域的重要方向。
 发表于 2025-12-24 17:28:42
|
查看: 204|
回复: 0
发表于 2025-12-24 17:28:42
|
查看: 204|
回复: 0
