TL;DR
这是系列文章的第一篇,从协议演进的视角回看 RDMA 的关键分叉点。后续还会有一篇从芯片微架构的角度解释:为什么 Mellanox 早期能在与 BRCM/Intel 等厂商的竞争中占先,以及在 AI 网络时代又为什么引出 DPU、SuperNIC 等新形态与一系列新矛盾。
这几天读到《比特分享 | 无损网络、反压及拥塞扩散》后,顺手又翻出 2016 年 SIGCOMM 的《RDMA over Commodity Ethernet at Scale》。问题是:真的“at scale”了吗?工业界为此折腾多年、不断修修补补,但很多争论其实源自一开始的设计取舍与假设偏差。
如果用一句金融风控里大家都懂的话来类比:刚性兑付必定带来流动性风险。换到网络工程语境就是:无损(Lossless)网络必定放大大规模组网的系统性风险。一些厂商至今仍坚持用 PFC 做“刚兑”,却很难清晰解释其边界与代价,同时还在 SmartNIC 与 DPU 之间继续“划物种”。
网络抽象来看无非三块:拓扑、路由、流控。所谓第一性原理,往往可以被浓缩为一句:Smart Edge, Dumb Core。更完整的表述可以参考 RFC1925《The Twelve Networking Truths》(建议配合基础概念一起看:TCP/IP 网络基础)。但现实里同类错误反复出现:把问题挪来挪去、把多个问题粘成一个高度耦合的复杂方案,最后系统性失稳。
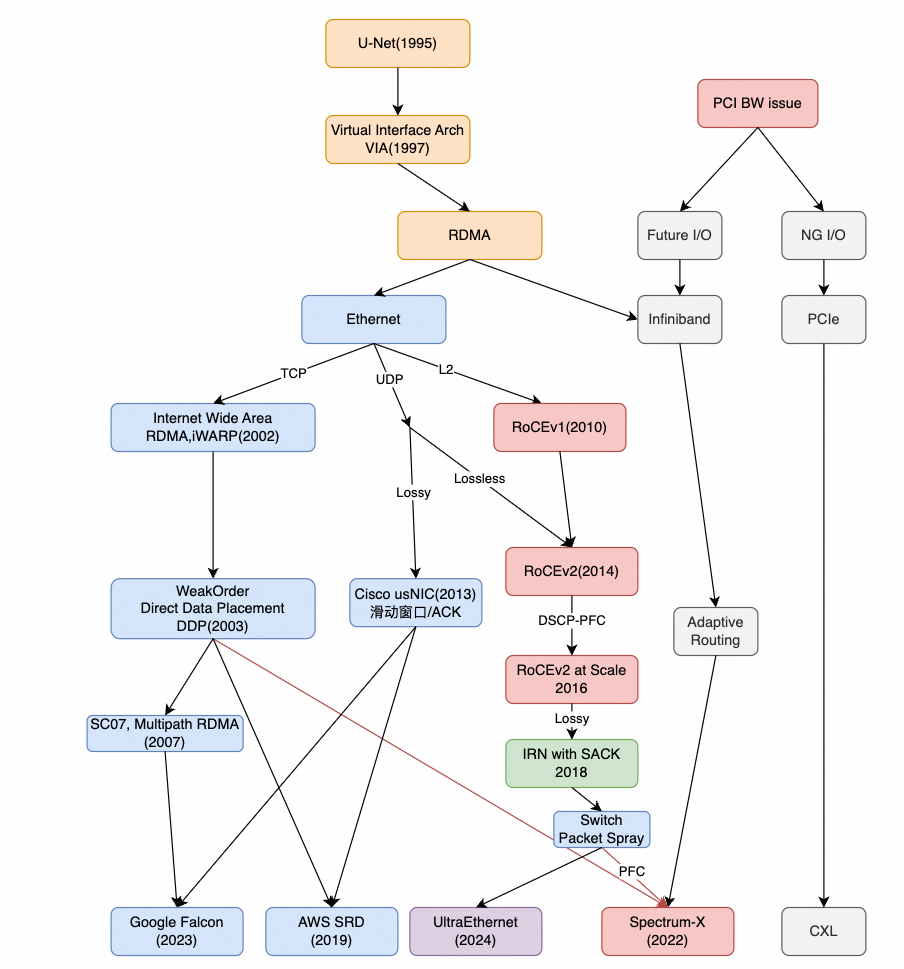
下面按时间线整理 RDMA/RoCE 的演进脉络。把这笔“糊涂账”理顺之后,很多争论会自然变得清晰。

1. RDMA / InfiniBand 的历史脉络
1.1 RDMA 的起点:Kernel-Bypass 的现实需求
RDMA 的思想可以追溯到 1995 年,其中一个关键人物是现任 AWS CTO 沃纳·沃格尔斯(Werner Vogels)。相关材料可参考:
- 《Scalable Cluster Technologies for Mission-Critical Enterprise Computing》[3]
- Cornell 课程材料《High performance networking Unet and FaRM》[4]
- 《RDMA [1]: A short history of remote DMA networking》[5]
早期 RDMA 的名字是 U-Net,核心动机是直面 Kernel 处理数据包的诸多“硬伤”(额外拷贝、上下文切换、不可控抖动等):

随后形成了 RDMA 的早期结构雏形:

1997 年出现了基于 U-Net 接口 + Remote DMA Service 的 Virtual Interface Architecture(VIA)。
1.2 InfiniBand:一次“带宽不够用”的产业合流
InfiniBand 的诞生与当下 AI 时代的带宽焦虑颇为相似:互联网爆发初期带宽告急,催生了两个组织 Future I/O 与 NGIO。其中 NGIO 由 Intel 主导,Sun/Dell 参与;Future I/O 由 Compaq/IBM/HP 支持。即便当时有 PCI-X,一些高端系统也逐渐逼近 PCI 总线能力极限。随后 IBTA(InfiniBand Trade Association)成立,成员横跨硬件与软件厂商(包括 Microsoft)。
IBTA 的目标相当激进:同时替代主机内 I/O 的 PCI、机房互联的以太网、存储互联的 FiberChannel,以及集群互联(如 Myrinet),甚至设想过 Composable Disaggregation Server over IB Fabric。
Mellanox 1999 年成立,最初致力于 NGIO 产品,随后推出 10Gbps 的 InfiniBridge 产品线。
历史的转折点在于:当“处理器能力远大于互联带宽”之后,路线分歧变得尖锐。互联网泡沫破灭后,Intel 转向 PCIe,微软也停止 IB 开发转而支持以太网。多年后微软却成为几大云中少数坚持 IB 的玩家之一,又与 OpenAI 等生态一起推动以太网路线——技术轮回并不稀奇。
之后 Myrinet 在超算领域长期折腾,最终 Mellanox 基本吃下超算互联的大盘并与 Voltaire 合并。另一家 IB 供应商 QLogic 被 Intel 收购;Myrinet 随后被 Google 收购而落幕。但二十年后再看 Google Falcon、Intel Omnipath,仍能看到历史留下的“基因”。
1.3 RDMA over Ethernet:三条路线的差异
1.3.1 iWARP:面向“Internet 级”问题定义
从 2002 年开始,IETF 推动定义 RDMA over Ethernet:iWARP(Internet Wide Area RDMA Protocol)。其问题定义更大——目标是在整个 Internet 上运行 RDMA,因此对乱序、重传、拥塞控制等都做了完整考虑,可靠传输层选择 TCP。
值得注意的是:能帮助 RDMA 在以太网实现多路径的技术(如 DDP)在 2002 年就出现了,2007 年 SC07 也有讨论;但另一边某些实现直到多年后仍未把这些能力“做干净”(这部分会在后文再回到)。
1.3.2 RoCEv1:为了低延迟,退回到二层
2010 年,InfiniBand 与以太网“联姻”,RoCEv1 出现。但为了低延迟,它只使用以太网链路层协议,甚至没有 IP 头——某种意义上,反而忘了早期 U-Net 时代还以 UDP 作为基础的事实。
Intel 当年吐槽 RoCEv1 的视频也很有代表性:《iWarp: The Movie | Intel Business》[6]
1.3.3 RoCEv2:回到 UDP,但走向 PFC 的“刚兑”
RoCEv1 推进数年仍难以落地,2014 年底终于补上 IP/UDP 头形成 RoCEv2,某种程度上回到了早期 U-Net 的 UDP 选择。
但在拥塞与可靠性上,RoCEv2 继承了 InfiniBand 为替代主机内总线而采用的思路:必须支持类似 Go-back-N 的重传语义,最终在 2016 年逐步走向 基于 PFC 的无损以太网(Lossless Ethernet)。这条路线一走就是十年,并带出大量规模化问题。
1.3.4 Cisco usNIC:低延迟 + 端到端机制的另一种取舍
思科 usNIC 发布早于 RoCEv2,在 RoCEv1 时代思科也公开质疑过(《HPC in L3》[7])。usNIC 的关键做法是:底层采用 UDP 并支持 Unreliable Datagram 语义,同时通过滑动窗口/ACK/重传等机制,把延迟从同期 iWARP 产品约 3us 拉低到 1.57us,配合 Cisco 3548 低延迟交换机实现端到端 < 2us:


更多细节可参考演讲《Lawrence Berkeley Lab Nov 2013 talk: Cisco Userspace NIC (usNIC)》[8]
从拥塞控制角度看,滑动窗口/ACK/重传这类端到端机制,与今天 Google Falcon 的一些方向在思想上非常接近。某种意义上,这里已经隐约出现了未来 UEC 与英伟达路线的“终局形态”。那么问题来了:RoCEv2 为什么会在之后十年里持续偏离?
2. RoCEv2 的“误入歧途”:十年回看
围绕 RoCEv2 的规模化问题,微软/Google 的 HPC 专家、Cray(HPE) Slingshot 团队以及博通交换机芯片团队在论文《Datacenter Ethernet and RDMA: Issues at Hyperscale》[9][11] 中做了系统总结。把它与 2016 年 SIGCOMM《RDMA over Commodity Ethernet at Scale》对照看,很多“看似技术细节”的争论其实指向同一件事:问题被搬运了,而不是被解决。
2.1 惯性导致的“刚性兑付”路径
RFC1925 有一句非常尖锐:
It is easier to move a problem around ... than it is to solve it.
从 RoCEv1 到 RoCEv2,某些实现的核心诉求之一是尽可能复用既有 RNIC 设计:换个包头、快速上线。但二层互联难以在数据中心落地,于是仓促补上 IP/UDP 头解决路由问题;流控却继续沿用主机内总线式的假设,把主机内通信中常见的 Go-back-N 等机制扩散到以太网环境。
在主机内通信里,距离短、信号完整性好、延迟极低,很多“粗糙但有效”的机制能跑得很好;但当你进入“多跳、可丢包、可乱序、可故障、可拥塞”的以太网,这些机制就会把系统拖进深水区。
2.2 微软的推动与“暂时隐藏”的代价
微软早期停止 IB 开发,转向以太网。RoCEv2 出现后,微软在分布式系统上做出过非常亮眼的工作:FaRM(Fast Remote Memory) 系列论文与系统,包括:
- 《FaRMv1: Fast Remote Memory》:基于 RDMA 构建分布式事务(2PC、OCC),利用 RDMA 单边写与环形缓冲区实现低延迟消息原语,并提出无锁读(Lock-Free READ)算法
- 《No compromises: ...》:在高性能下提供严格可串行化/持久性与高可用
- 《FaRMv2: ... with Opacity》:利用 RDMA 单边操作协调全局时钟并按时间戳排序事务
- 基于 FaRM 的分布式内存图数据库《A1》在 Bing 搜索落地
但在工程落地中,PFC/拥塞树等问题一度被 DSCP-Based PFC “遮住了”:症状被压住,根因并未消失。
RFC1925 的另一句也很贴切:
It is always possible to aglutenate multiple separate problems into a single complex interdependent solution. In most cases this is a bad idea.
本质上是“网卡端的拥塞控制问题”,被搬到交换机侧用 DSCP-Based PFC 去兜底。此时再回头看《RDMA over Commodity Ethernet at Scale》:它真的做到了 large-scale 吗?

同一时期,Cisco usNIC 在拥塞控制上更“端到端”,但产业采购在 25Gbps NIC 时代开始明显向 CX4 聚拢,其他路线逐步边缘化。
2.3 IRN:迟来的“端侧修正”
2018 年,论文《Revisiting Network Support for RDMA(IRN)》[10] 提出反思并给出一个方向性的修正:

经历多年坑之后,问题终于被重新摆回 RNIC:能否不依赖“刚兑式”Lossless?
IRN 一边又把 iWARP 拉出来对比,一边老老实实借鉴 TCP 的丢包恢复机制,用选择性重传替代 Go-back-N:

它至少在方向上远离了 PFC 的刚性兑付,但仍遗留一个关键疑问:为什么不进一步参考 usNIC,把滑动窗口式的拥塞控制也补齐?后续以 Rate-Based CC 为主的选择,又引出了新一轮问题。
2.4 AI 热潮下“重回 Lossless”
到了 2023 年,大模型训练对 RDMA 带宽需求激增,Spectrum-X 等宣传又回到了 Lossless 叙事:

背后原因并不玄学:Packet Spray、Adaptive Routing 等 AI 网络常用能力,会与某些端侧拥塞控制逻辑产生冲突;在工程取舍上,有人选择放弃 Lossy 路线,回到 Lossless 的“老办法”。
3. RDMA 的现代化:从“协议耦合”走向“分层与端到端”
3.1 RoCEv2 的系统性问题(Hyperscale 视角)
《Datacenter Ethernet and RDMA: Issues at Hyperscale》[11] 对 RoCEv2 的批评非常集中,核心要点可以概括为:
- RoCE 的传输层继承自早期 InfiniBand 的简单硬件实现,依赖保序与 Go-back-N 语义;在“无丢包、强保序”的网络中表现最好
- 传统以太网交换机缓冲区满会丢包,通常依赖端到端重传;为了迎合 RoCE,于是引入 PFC 做链路级“无丢包”,但这会跨层干扰、放大复杂性,影响关键工作负载效率
- RoCE 的语义、负载均衡与拥塞控制继承自 InfiniBand,倾向于“消息按序到达”,客观上限制了很多数据包级负载均衡机制;而 AI 训练往往是长流,多路径对作业完成时间很关键
- RoCEv2 的 ECN 拥塞控制用二进制信号表示拥塞,缺少细粒度反馈,可能需要多次 RTT 才能逼近合理速率;配置上也很难与其他流量真正“和平共处”
这些问题推动了 UltraEthernet 组织出现,试图对 RDMA 进行现代化改造:

3.2 2007 年 iWARP 的多路径与乱序:其实很早就有人想清楚了
2007 年论文《Analyzing the Impact of Supporting Out-of-Order Communication on In-order Performance with iWARP》[12] 开篇就强调:要容忍网络故障与拥塞,支持多路径越来越重要——这几乎就是今天 AI 训练网络的关键词。
其核心思路是采用 Weak Ordering 的 Direct Data Placement:
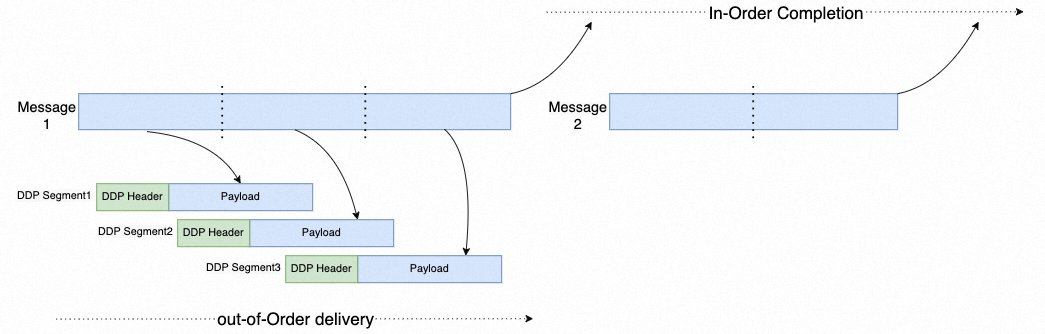
看到这张图,再看 UltraEthernet 常提的 Out-of-Order Delivery / In-Order Completion,就会发现:很多被称作“RDMA 现代化”的概念,早在 2002~2007 年就已经以另一种形式出现过。
这也是 Mellanox 在多年后做多路径时借鉴的方向之一;但 Re-Order 处理依旧存在缺陷,其中一部分与其微架构实现相关(后续文章再展开)。
3.3 AWS SRD:端到端多路径 + 端到端拥塞控制的“组合拳”
AWS SRD 主要为云上超算解决两个现实问题:一是 QP 爆炸,二是与 VPC 内 TCP 等流量混跑。其拥塞控制在《A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC》[13] 中有详细介绍,里面把“多路径转发”和“端到端拥塞控制”的耦合讲得非常直接:拥塞时是换路径,还是降速?
文中指出:
- 多路径 spraying 能降低中间交换机负载,但对 incast(多对一汇聚造成接收侧端口缓冲耗尽)无能为力
- spraying 甚至可能让 incast 更糟:同一发送端的 micro-burst 走不同路径同时抵达,从而放大瞬时拥塞
- 因此,多路径传输的拥塞控制必须让所有路径上的累积排队量保持尽可能低
SRD 的目标表述也很“第一性原理”:在最小化在途字节(minimum in-flight)的前提下公平获取带宽,尽量避免队列堆积与丢包(而不是靠丢包探测)。它的控制方式与 BBR 有相似之处,但加入数据中心多路径的考量:基于 per-connection 动态 rate limit + inflight limit,全局拥塞用 RTT/速率估计检测,单路径拥塞则通过 rerouting 独立处理。
如果说 SRD 的代价,主要在于与传统 RC/Verbs 生态的兼容压力:作为云服务,AWS 能推动客户与软件供应商做配套改造;但在很多历史包袱更重的环境里,这并不容易。
3.4 阿里 Solar RDMA:面向存储网络的协议演进
在存储业务场景中,也存在多 QP、写入非阻塞等需求,传统 RC 语义容易引入头阻塞等问题。阿里提出了 Solar RDMA,公开论文为《From luna to solar: the evolutions of the compute-to-storage networks in Alibaba cloud》[14]。
3.5 Google Falcon:把“传输/加密/RDMA语义”拆开
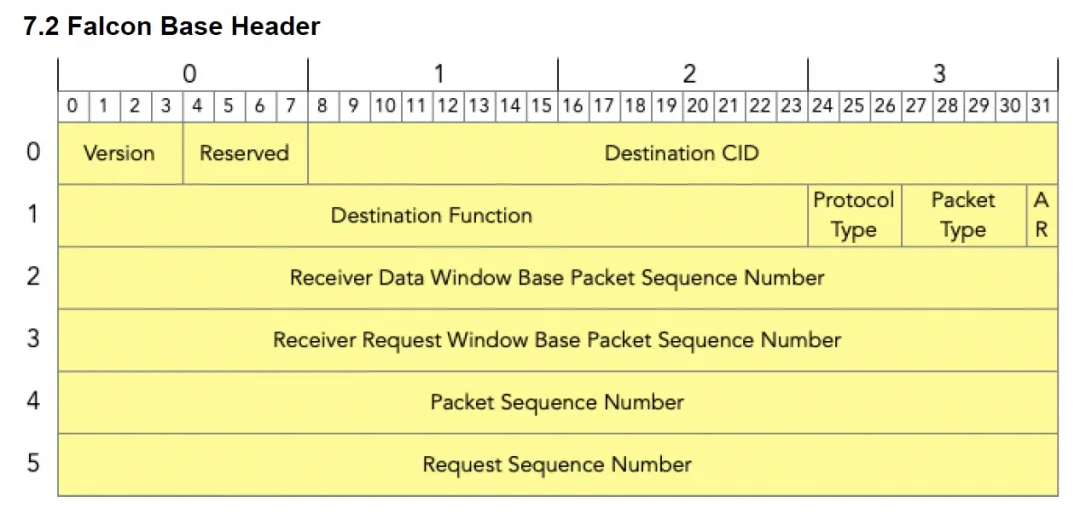
Google Falcon 的关键路线之一,是把可靠传输层与 RDMA 语义解耦,并使用成熟的 Swift 拥塞控制。下面这段话值得细读:

结合 RFC1925 的提醒:把多个问题强行粘合在一起,往往是灾难的开端。Falcon 比较突出的点包括:
- 传输/加密/RDMA 语义解耦
传输层抽象为 PUSH/PULL;加密独立在 PSP 套件;RDMA/NVMe 作为 ULP 定义,通过不同 Header 分层解耦。
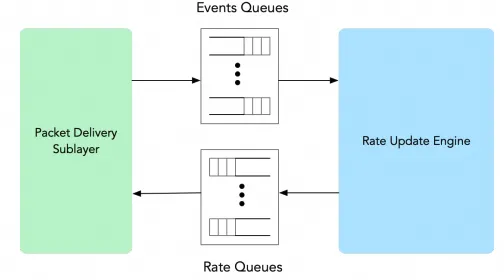
- 拥塞控制与数据路径解耦
由独立的 Rate Update Engine 负责拥塞控制逻辑。
有意思的是,Mellanox 过去评价 iWARP 时常给出“复杂分层”的对比图:
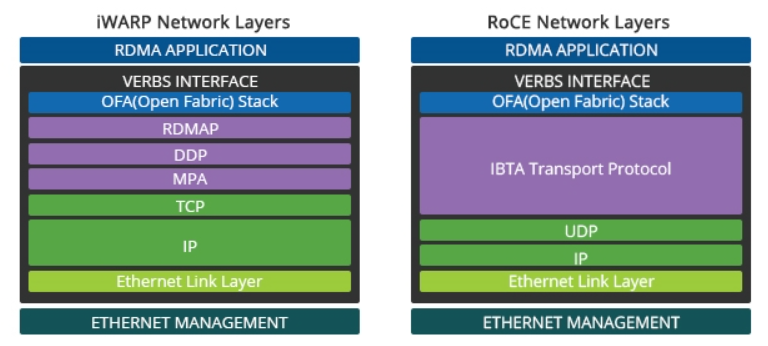
但换个角度看,iWARP 恰恰也是通过分层把传输与 RDMA 语义拆开;相较 RoCEv2 的“杂糅式”堆叠,协议边界更干净——至少 RoCEv2 后来不也把 DDP 等能力逐步补进来了。
当然 Falcon 也有短板:尤其在多路径上,PLB 算法对大模型训练的集合通信并不理想,同时缺少类似 AWS 那样更激进的 Packet Spray 能力。
3.6 UltraEthernet:问题定义清楚,但“核心权力”放哪儿仍值得追问
UEC 把问题讲得很清楚:要多路径、要应对 AI 训练的长流与 bursty 集合通信。但在解法上,一条重要方向是依赖交换机侧的 Random Packet Spray;而在拥塞控制上,业界仍缺少足够统一、清晰、可操作的路径。
这里值得回到那句:Smart Edge, Dumb Core。当组织谈“端网协同”时,首先需要想清楚:哪些能力必须在交换机里?哪些应该留在端侧?是否真的要高度依赖交换机的拥塞信号,还是应该优先保证端侧“不占队列、少堆积”?
4. 结论
本文回顾了 RDMA 的发展历程,可以看到 RoCE 在协议演进上走了不少弯路:从 RoCEv1 到 RoCEv2 的关键取舍,再到 PFC 带来的长期规模化困扰。反过来看,同期的 usNIC 已经给出过相当端到端的思路。后来 Lossy RDMA 看似在走向正路,但又因为 Packet Spray 等 AI 网络特性需求,在一些路线选择上重新回到 Lossless。
另一条路径(AWS SRD、Google Falcon)在演进上显得更“干净”:分层清晰、端到端闭环更强,少走许多系统性弯路。真正能把第一性原理贯彻到工程边界的人并不多;更多时候,我们看到的是把复杂度不断外溢、堆叠,再用更复杂的机制去“补洞”。
4.1 根因之一:内存语义与消息语义的错位复用
很多争论的根本,来自不同总线协议/通信域的差异。以 PCIe 为例:
- PCIe 作为
主机内(Intra-Host) 扩展卡与 CPU 通信标准存在近 20 年,DMA 广泛用于芯片间通信
- RoCE 把 DMA 操作扩展到
主机间(Inter-Host) 以太网,试图构建 Lossless RoCE
- Go-back-N 对丢包极度敏感,于是发展出 DCQCN 等依赖 PFC 的可靠传输/拥塞控制
- 随着网络规模扩大与 VPC/Overlay 普及,这类架构带来更大的延迟抖动与死锁风险
- Lossy RoCE 尝试绕开 PFC,但仍在拥塞控制与可规模化部署上遇到瓶颈
- 同时,主机内互联也在演进:GenZ、CCIX、CXL 等用以缓解延迟与一致性等问题
更关键的是:主机内与主机间通信在设计原则上存在根本差异,本质上是 内存语义 与 消息语义 的差别:
- 拓扑:主机内多为固定树状拓扑与固定编址(如 PCIe DFS);主机间拓扑非固定,且多路径与 Overlay 使调度更复杂
- 延迟:主机内可做到 <200ns 且相对固定;主机间以太网通常数微秒且不确定性更高
- 丢包:主机内靠仲裁与 credit token 调度通常不丢包;主机间常因拥塞或中间节点失效丢包,强行构建无丢包网络代价高、利用率低
- 一致性:主机内 RTT 极低,可用 MESI 等缓存一致性协议;主机间实现一致性困难且带来编程模型挑战
- 保序:主机内为一致性往往需要严格保序且易实现;主机间因多路径与安全设备调度等乱序更常见
- 报文大小:主机内常以 flit/CacheLine(64B)粒度为主;以太网常见 1500B/9000B
当只掌握一个 domain 的经验,却把它不加边界地复用到另一个 domain,行业就会进入长周期的“停滞+补洞”。今天仍有人讨论“CXL 能否用于 GPU Scale-Out/Scale-Up”“UltraEthernet 能否做 ScaleUp 网络”,其背后往往就是语义与边界未厘清。
4.2 AI 集群到底需要怎样的网络?
反过来问:AI 训练网络追求的是 HPC 那种“几个字节消息的极致延迟”吗?通常不是。更准确的目标是:在可容忍的延迟范围内,尽量把带宽做大,并尽量压住长尾。
回到那句:Smart Edge, Dumb Core。集合通信非常 bursty,但也别忘了 RFC1925 的提醒:
With sufficient thrust, pigs fly just fine. However, this is not necessarily a good idea.
很多拥塞控制算法试图更精确测量交换机队列深度等信号,但引入更多外部测量往往拖慢收敛、放大耦合。一个现实的思考是:为什么不把 rate-based CC 换成 window-based 的思路,让交换机队列尽量浅就够了?在 MoE 的 all-to-all、以及与 TCP 等其他流量混跑时,这类端侧约束可能还有额外收益。(相关运维落地往往绕不开系统参数与观测链路,可结合:Linux/并发与网络排障)
另外,RFC1925 还有两句经常被实践反复验证:
- 把多个独立问题粘成复杂互依解法,很多时候是灾难的起点
- 推卸问题比解决问题容易
例如某些场景会采用 Rail-Based 组网与流量工程去“绕开”哈希冲突,而不是从根本上提升多路径与端到端控制能力——这类取舍未必错,但需要明确它是在移动问题还是解决问题。
最后,再回到“减法”:
In protocol design, perfection has been reached not when there is nothing left to add, but when there is nothing left to take away.
极致压榨几百 ns 延迟当然在 HPC 时代有明确商业价值,但作为工业界广泛使用的协议,RoCEv1/RoCEv2 引发的长期系统性问题也已经足够深远,以至于今天仍在纠结是否必须把一些能力割裂成不同“物种”:

真的需要这样分离吗?AWS 和 Google 并没有走同样的路径——问题究竟出在哪里?回到 RDMA 历史演进那张图,再结合第一性原理,读完本文你应该能把很多争论重新“放回它该在的位置”。
参考资料
[1] 比特分享 | 无损网络、反压及拥塞扩散: https://mp.weixin.qq.com/s/pBAH2UGkGbEBA3PWXG90pA
[2] RDMA over Commodity Ethernet at Scale: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/11/rdma_sigcomm2016.pdf
[3] Scalable Cluster Technologies for Mission-Critical Enterprise Computing: https://www.cs.vu.nl/~ast/Theses/vogels-thesis.pdf
[4] High performance networking Unet and FaRM: http://www.cs.cornell.edu/courses/cs6410/2016fa/slides/24-networked-systems-rdma.pdf
[5] RDMA [1]: A short history of remote DMA networking: http://thinkingaboutdistributedsystems.blogspot.com/2016/12/rdma-1-short-history-of-remote-dma.html
[6] iWarp: The Movie | Intel Business: https://www.youtube.com/watch?v=ksXmfZxqMBQ
[7] HPC in L3: https://blogs.cisco.com/performance/hpc-in-l3
[8] Lawrence Berkeley Lab Nov 2013 talk: Cisco Userspace NIC (usNIC): https://www.youtube.com/watch?v=ZycqcMEfVo0
[9] Datacenter Ethernet and RDMA: Issues at Hyperscale: https://arxiv.org/abs/2302.03337
[10] Revisiting Network Support for RDMA: https://arxiv.org/pdf/1806.08159.pdf
[11] Datacenter Ethernet and RDMA: Issues at Hyperscale: https://arxiv.org/abs/2302.03337
[12] Analyzing the Impact of Supporting Out-of-Order Communication on In-order Performance with iWARP: https://web.cels.anl.gov/~thakur/papers/sc07-iwarp.pdf
[13] A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC: https://assets.amazon.science/a6/34/41496f64421faafa1cbe301c007c/a-cloud-optimized-transport-protocol-for-elastic-and-scalable-hpc.pdf
[14] From luna to solar: the evolutions of the compute-to-storage networks in Alibaba cloud: https://dl.acm.org/doi/abs/10.1145/3544216.3544238
[15] 转自公众号作者:zartbot
 发表于 2025-12-24 17:29:00
|
查看: 280|
回复: 0
发表于 2025-12-24 17:29:00
|
查看: 280|
回复: 0
