引言
Mellanox 作为一家价值 60 亿美金、最终被英伟达收购的公司,有大量值得复盘的成功经验;但其早期芯片微架构也在新业务时代遭遇了不少结构性挑战。
本文从应用需求与芯片架构两个维度回看 RDMA 这十年的演进:一方面分析 Mellanox 在 HPC 低时延时代的胜出路径;另一方面解释为何其在 RoCE 上反复摇摆(Lossless/Lossy/Lossless),以及在 AIGC 时代暴露出的拥塞控制与多业务融合问题。
Those who do not study history, are doomed to repeat it
TL;DR
Mellanox 靠着 ASIC 架构与 HPC 对极低延迟的刚需,在很长一段时间内击败了大量基于网络处理器(NP)微码架构实现 RDMA 的厂商(Tile Based NIC)。但也正因为其架构在存储/云/AI等场景存在天然短板,使得在有损以太网上的拥塞控制难以落地。
随后通过收购 EzChip 与 Tilera 的技术积累,Mellanox 开始构建基于 BlueField 的产品线,将路线转向 ASIC FastPath + 通用处理器 的组合架构。这也是其他 DPU 厂商大体一致的选择:例如定制的 Cavium/Marvell Octeon10、Intel Mt. Evans 等,都属于类似思路——对 HPC 提供足够低的时延,同时对 AI 场景的拥塞控制与多业务 offload 提供足够算力,并能覆盖存储/安全等复杂功能。
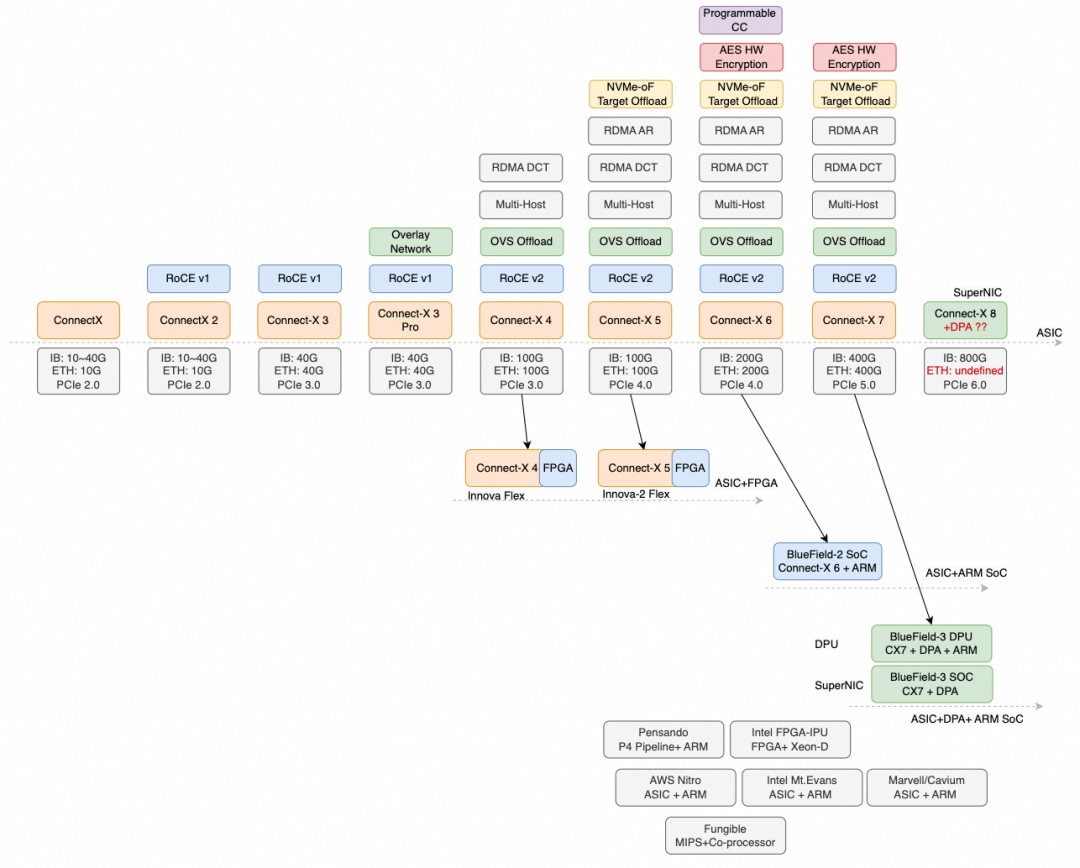
因此可以看到:英伟达在 ConnectX-8 这一代把定位直接拉到 SuperNIC,市场策略更侧重于基于 IB 继续走 Lossless 路线;而以太网侧在宣传上更多交给 BlueField-3 以及未来的 BlueField-4。另一方面,纯微码 NP 方案会在 AI 场景面临拥塞控制算力不够、在 HPC 场景面临时延偏大,同时灵活性又不如 BF3 的尴尬处境:高吞吐受限于 CC 算力,低时延又卷不过 ASIC。
从工业界角度看:ASIC 加速经常性路径,通用 CPU 提供可编程性,往往是数据密集型业务的“终局形态”。二十年前路由器演进到多业务路由器,从 ASIC 演进到 Network Service Processor;二十年后网卡演进到 DPU/SuperNIC/SmartNIC 等多业务融合网卡,其微架构也会再走一次类似的路。
目录
1. 从应用看 RDMA 的业务需求
1.1 Kernel-Bypass,TCP 透明替代
1.2 HPC
1.3 分布式数据库
1.4 分布式存储
1.5 AI 大模型训练
1.6 RDMA 应用的流量模型
2. 延迟为王的时代
2.1 延迟的影响因素
2.2 InfiniBand 诞生原因
2.3 HPC:Mellanox InfiniBand 的成功之路
2.4 Ethernet 的低延迟之争
3. 复杂业务带来的架构转型
3.1 SmartNIC 时代
3.2 成也 ASIC,败也 ASIC
3.3 DPA 算力置换
3.4 自适应路由与多路径转发
3.5 RDMA 现代化
3.6 UEC:另一个 Converged Ethernet 的故事
4. 历史的重复,架构的选择
4.1 网络处理器与网卡处理器的异同
5. 总结
A. 附录:RDMA 应用分析
A.1 分布式数据库
A.1.1 Oracle RAC
A.1.2 IBM DB2 PureScale
A.1.3 Microsoft FaRM
A.1.4 PolarDB 严格一致性读及 Serverless 架构
1. 从应用看 RDMA 的业务需求
正如 RFC1925 “网络十二条军规”所说:
It is always something. (corollary). Good, Fast, Cheap: Pick any two (you can't have all three).
对网络而言,核心衡量指标基本就三个:带宽 / 延迟 / 抖动。脱离应用只谈指标,往往只能得到“纸面最优”而非“业务最优”。在讨论 RDMA 设备的芯片架构之前,先从应用视角拆解业务需求。
(下面用 Y/N 做粗粒度对比)
| 场景 |
极低延迟 |
高带宽 |
INCAST |
QP 数 |
| HPC |
Y |
N |
N |
Y |
| 分布式 DB |
Y |
N |
N |
N |
| 分布式存储 |
Y |
N |
Y |
Y |
| AI 大模型 |
N |
Y |
Y |
Y |
注:为了不干扰阅读,附录提供更细的应用分析;对部分系统与并行计算背景(如偏微分方程数值解、典型分布式事务系统等)也可按专题进一步展开。
1.1 Kernel-Bypass:TCP 透明替代
从 1995 年 U-Net 开始,RDMA 的第一个典型场景就是 Kernel-Bypass。
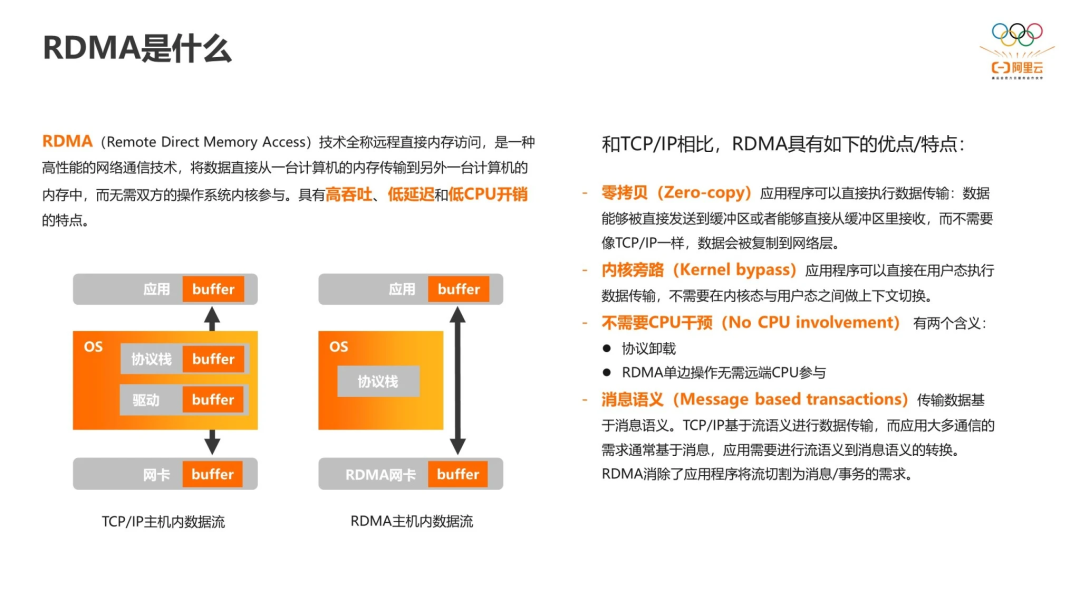
IBM 在大型机上基于 RDMA 技术实现了 SMC-R(Shared Memory Communications over RDMA)。SMC 被 IBM 开源到 Linux 代码中,同时 IBM 也提出了 IETF RFC7609 描述 SMC-R 的实现方式。其次,SMC 本身也是一种协议:Linux 下为 AF_SMC,可以在 socket 中直接指定使用,不需要额外 hack,实现上与 TCP 等价。用户无需改代码即可通过 SMC-R 透明加速 TCP。
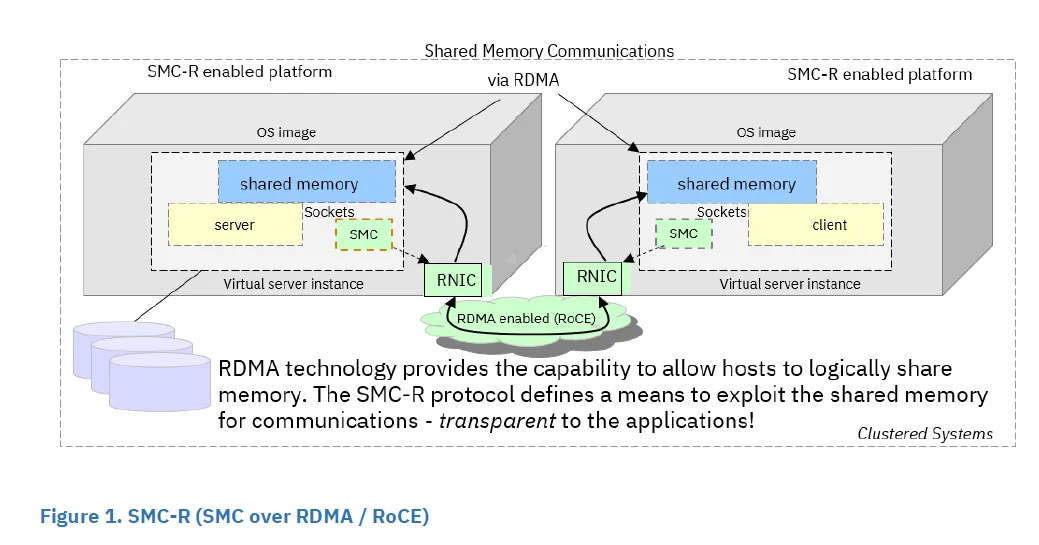
在云上也可以落地此类能力。例如支持 eRDMA 的虚拟服务器上可以使用 SMC-R,对 Redis 这类典型应用无需代码改动即可提升明显吞吐(常见能达到 40%+,取决于业务模型与环境)。这类方案本质上依赖对操作系统网络栈与底层网络机制的理解,可结合 TCP/IP 等网络与系统基础 体系化梳理。
1.2 HPC
主要特征:极低延迟,QP 数量
HPC 广泛用于科学研究、生物制药、基因测序、CAD/CAE、气象预报、计算模拟等。通常利用 RDMA 加速 MPI 通信,降低集合通信延迟与长尾。
在超算中很大一类应用是对连续物理系统(如流体、电磁场)进行分析与模拟,本质上是求解大规模、多参数偏微分方程的数值解。用有限差分等方法离散后,会转化为求解线性方程组;传统 Gauss-Seidel 迭代效率不高,因此出现多重网格方法用于并行计算。
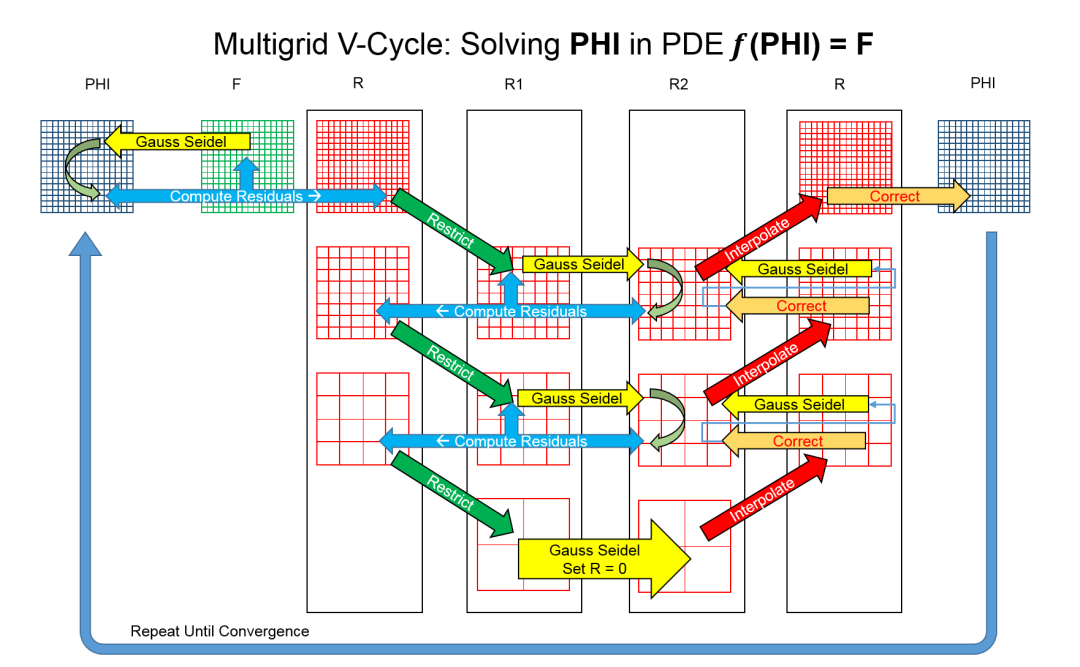
多重网格的关键在于:在不同尺度网格上计算,借助粗网格维度低、迭代快的性质,在细到粗时施加约束,在粗网格求解后再通过延拓算子插值回细网格。
这类应用通常伴随大量计算核数而需要大量 RDMA QP 互通,且通信量往往较小,因此静态时延成为关键影响因素。
1.3 分布式数据库
主要特征:极低延迟,单边操作
分布式数据库处理分布式事务一致性时,需要尽可能降低延迟。早期 Oracle RAC 采用的集群技术与 RDMA 的数据结构在设计理念上高度相似;IBM DB2 PureScale 也使用集中式的 Global Cache 层;Microsoft FaRM 则基于环形内存空间构建单边操作语义的 RPC,并进一步构建了基于 RDMA 的一致性事务处理能力。云数据库中也有用 RDMA 实现严格一致性读与弹性能力的例子(附录详述)。
在事务一致性约束下,网络通信延迟往往是关键路径。工业界常见做法是利用 RDMA 单边操作避免在事务关键路径引入远端 CPU;但单边语义也会引入通知、顺序依赖与异常路径处理等复杂性,反过来对 NIC/DPU 的能力提出更高要求。
1.4 分布式存储
主要特征:QP 数量,Incast 长尾延迟
分布式存储主要服务于存算分离:计算集群通过网络访问后端 Block/Chunk 服务。典型拓扑如下:
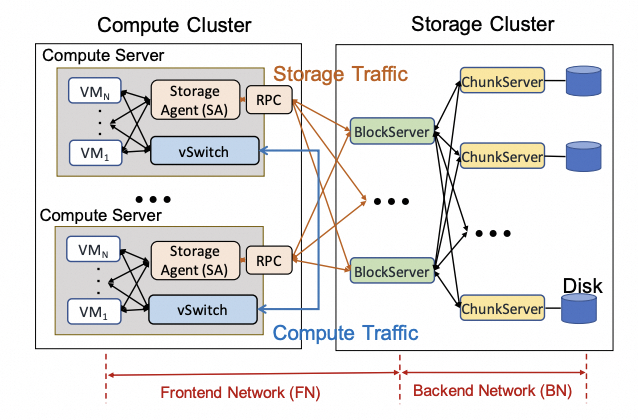
Block Server 与 Chunk Server 往往要同时服务多个连接,并发响应大量读写。例如数百个计算节点同时向一个 Block Server 写入会出现 Incast,触发队列膨胀与长尾延迟。
业内实践中,为避免头阻塞与 QP 数量爆炸,一些方案会引入 RD(Reliable Datagram)语义进行优化(后文“RDMA 现代化”会展开),其动机与存储 IO 并发模型密切相关。
1.5 AI 大模型训练
主要特征:QP 数量,Incast 长尾延迟,带宽大且突发高
AI 训练中集合通信常呈现“批量同步”特征(oblivious bulk sync, OBS),流量非常 bursty,瞬时可打满链路;MoE 等模型带来的 All-to-All 通信使抑制 Incast 更关键。

但训练场景下消息 size 通常较大,对静态时延不如 HPC 那样敏感,同时 GPU 也可通过更大粒度的通信(例如 LL128 等机制)在一定程度上隐藏时延。
1.6 RDMA 应用的流量模型
一篇论文《Datacenter Ethernet and RDMA: Issues at Hyperscale》对 RDMA 业务做了简要归纳,覆盖数据中心东西向流量(HPC、AI 训练/推理、存储),以及在微服务或 FaaS 流量中使用的场景,总结出三类模式:
Incast(IN)
多个源向单个目的节点并发发送数据流,由于缺少协同产生拥塞。其严重程度受并发源进程数与事务大小影响。在生产网络中这类模式常随机出现。
示例:100 个客户端向一个存储服务器提交 10KiB 写事务;客户端并不知道潜在拥塞,因此都以满带宽发送,数据包很快填满缓冲区并阻塞其他流量,最终导致 SLA 受损。最具挑战的 Incast 常由小 BDP(Bandwidth Delay Product)事务触发,使拥塞控制在事务完成前难以获得可靠信号;带宽持续增长会把更多工作负载推入这一“危险区”。
Oblivious Bulk Synchronous(OBS)
很多 HPC 与 AI 训练工作负载可表示为“计算步骤”和“全局通信步骤”交替进行的模型。OBS 的通信模式由少量参数决定(通信大小、进程数),与数据内容无关,通常可在启动前静态决定;MPI 的集合通信操作就是典型 OBS,因此可以从算法层面规避部分 Incast。
OBS 可由进程数、计算时间、每端点通信大小建模:若计算与通信都很小,整体对延迟敏感(常见于 HPC 与 AI 推理);而分布式训练的通信量更大,往往更带宽敏感。
Latency-Sensitive(LS)
部分工作负载中消息延迟(有时包括消息速率)处于核心地位。有些属于 OBS,但也存在更复杂、数据依赖的消息链,构成应用关键性能路径。它们通常是 Strong Scaling 类型,时间至关重要且必须容忍低效执行。大规模仿真(油气勘探、天气预报等)以及某些事务处理/搜索/推理都属于此类,常要求个位数微秒级延迟。
2. 延迟为王的时代
早期 RDMA 主要用于 HPC,目标是极低延迟。Mellanox 基于 ASIC 的方案在这一场景中逐渐击败了原本 HPC 互联的垄断者 Myrinet,也在竞争中压过了一批基于 NP 微码固件实现 RDMA 的厂商。
2.1 延迟的影响因素
互联延迟通常包含两部分:静态延迟 + 动态延迟。
- 静态延迟:PHY/设备处理延迟 + 链路传播延迟
- 动态延迟:消息大小 / 带宽(传输时延) + 传输过程中的队列等待、丢包重传等

注:图片来自《High Performance Ethernet for Computing and Storage Systems》
当交互消息很小时,影响主要来自静态延迟;随着消息增大,传输时延逐步上升。在 HPC 大量偏微分方程数值解任务中,通信 size 可能只有几个字节,静态延迟成为关键;但随着部署规模变大,如果拥塞控制不当导致排队,队列时延会反过来成为主要瓶颈。
2.2 InfiniBand 诞生原因
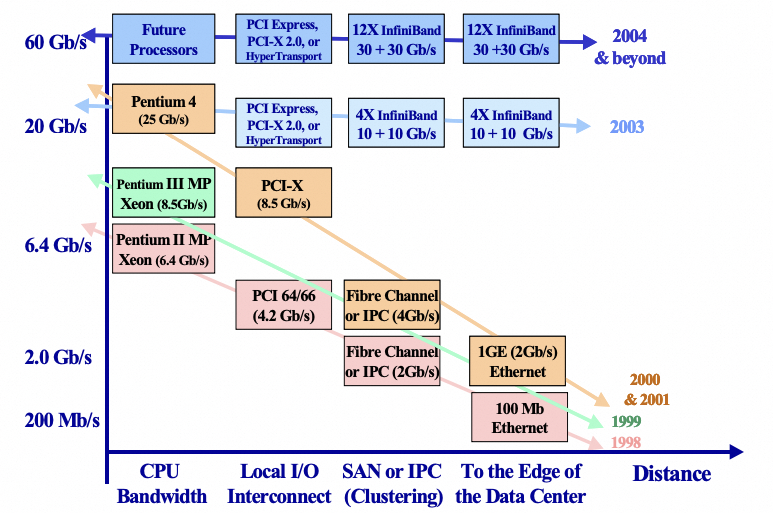
InfiniBand 起源于 1999 年,目标是处理器能力越来越强后 PCI 总线带宽(10Gb/s)演进受限的问题。那时出现了 NGIO 与 Future I/O 两个组织,NGIO 由 Intel 主导,Mellanox 也在当时成立开发相关技术。最终 Intel 在 2002 年停止 IB 相关开发转向支持 PCIe,因此两者在设计上有不少相似。
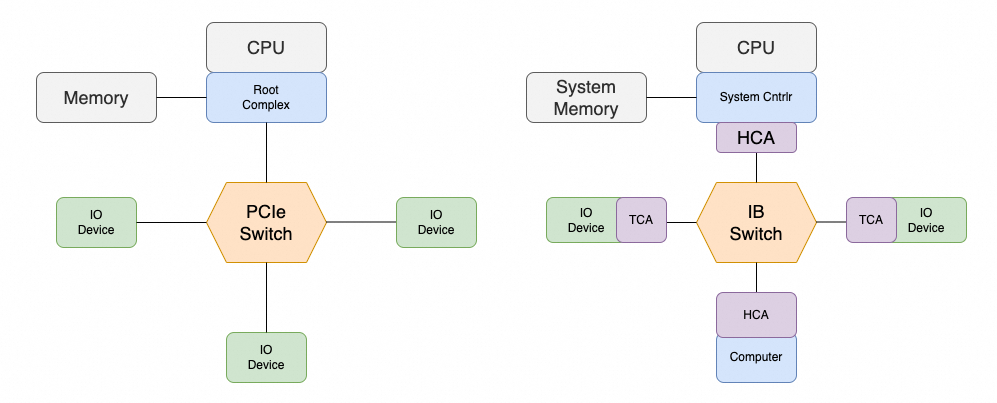
由于要承载大量细粒度 I/O 请求,高带宽、低延迟成为协议设计第一要素,同时拥塞控制也延续主机内总线的 Lossless + Credit-based 机制。
类似 PCIe 多 lane 的方式,IB 也通过多 lane 提升带宽以匹配主机互联带宽。在当时以太网还处于 1Gbps,带宽优势显著。
IB 单 lane 在一对双绞线(4 wire)上支持 2.5Gbps,通过 4x(16 wire)支持 10Gbps,通过 12x(48 wire)支持 30Gbps,连接器如下:

IB 还曾希望融合数据中心内 PCI/以太网/集群互联与存储 FiberChannel,统一互联:
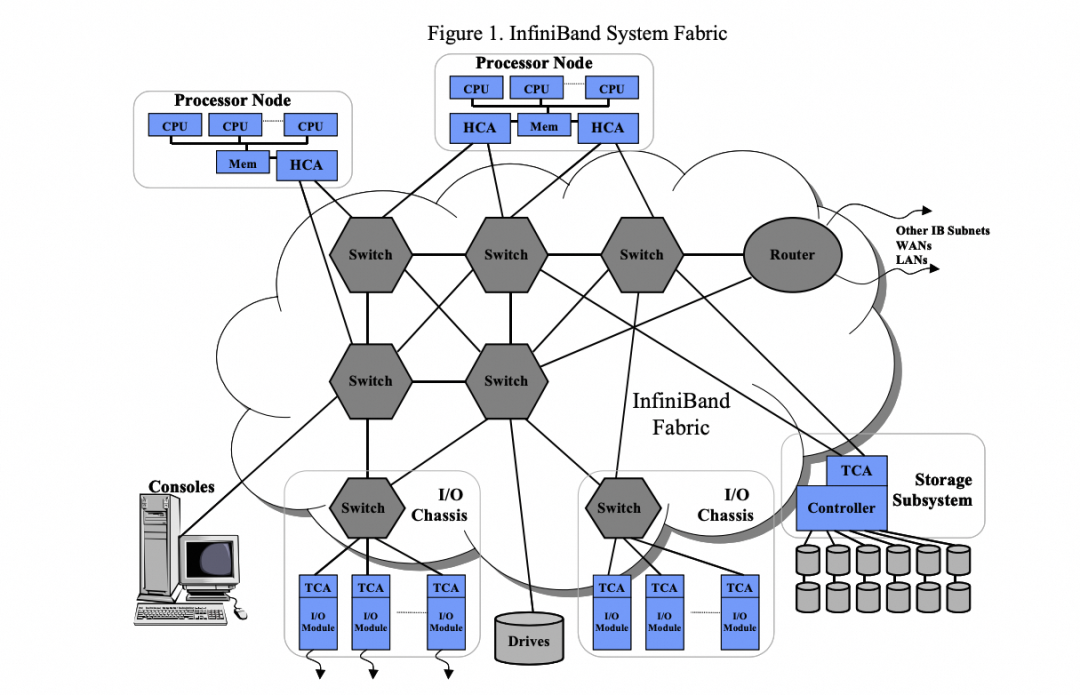
但后来仍演进成 LAN/IB/SAN 三张独立网络,一个重要原因就是:
Good, Fast, Cheap: Pick any two
IB 成本对通用计算与存储依然过高,于是逐渐出现 FCoE / RoCE 等 Converged Ethernet 需求以平衡成本。
2.3 HPC:Mellanox InfiniBand 的成功之路
InfiniBand 诞生时,HPC 正从专用网络向 Myrinet 迁移。Myrinet 来源于 CalTech 的 Mosaic 超算实验平台,针对低延迟通信进行了优化,其网卡硬件结构如下:
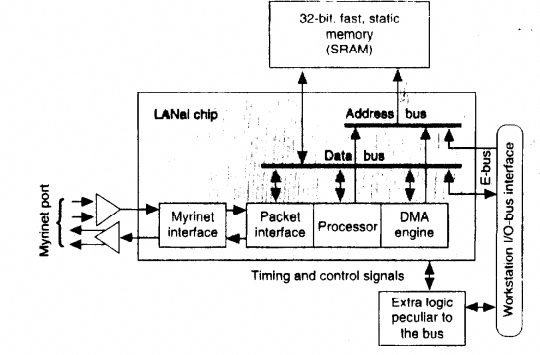
通过在 LANai 芯片上开发 Firmware,可对多种集合通信原语进行卸载与加速,这也是可编程网卡早期雏形。
TOP500 超算集群部署规模的演进如下,2002~2004 年 Myrinet 一度占据 TOP500 互联约 30% 市场:
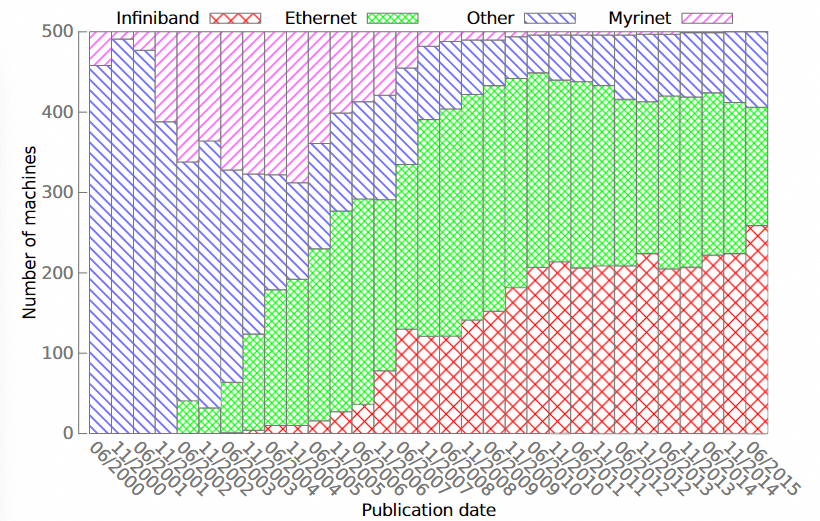
但随着 10Gbps 以太网与 InfiniBand 产业链成型,多方竞争下 Myrinet 生态封闭逐渐落败;Mellanox/Voltaire/Qlogic 等 IB 厂商与部分 10GbE 厂商逐渐胜出。
2008 年思科停售 IB 交换机产品线;2010 年 Mellanox 收购 Voltaire 后,QLogic 成为唯一能竞争的 IB 厂商,但两年后也将 IB 业务卖给 Intel,使 Mellanox 成为 IB 事实上的唯一供应商。后期 Intel 推出 OmniPath 等竞争技术也很快败下阵来。
与此同时,Mellanox 深耕 HPC:针对 Barrier、Allreduce 等集合通信瓶颈开发 SHARP 等在网能力,进一步降低集合通信延迟。
在这段市场变化中,业务相对简单使得 ASIC 数据路径能显著降低静态时延;再通过交换机协同(如 SHARP)降低通信量与动态传输延迟,这是 Mellanox 在 HPC 胜出的关键。
2.4 Ethernet 的低延迟之争
随着 10GbE 普及与 IB 成本偏高,Mellanox 也转向在以太网上支持 RDMA。RoCEv1 延续 IB 的低时延诉求,仅使用以太网头,依赖 DCB/PFC 构建二层无损以太网承载业务,但在数据中心内部署困难,最终效果不佳。

工业界开始做妥协:增加消息头、支持三层路由以降低部署复杂度。2014 年 RoCEv2 诞生,增加 IP/UDP 头、抛弃 IB GRH 头,报文格式如下:

但受 Mellanox ASIC 架构限制,早期仍延续无损以太网部署方式与 Go-Back-N 重传逻辑,拥塞控制也沿用既有思路。同期 Cisco usNIC 借助主 CPU 算力实现滑动窗口,但受业务与产品线变化影响后续未持续推进。
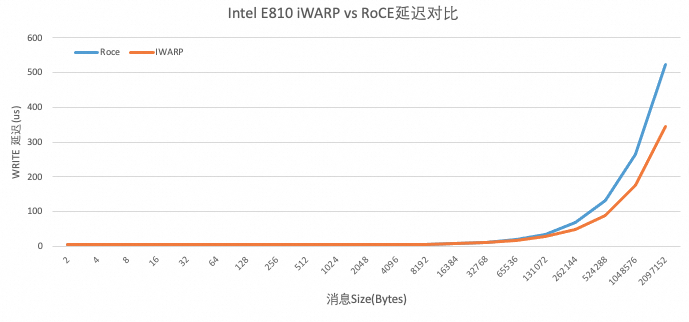
同时期不少公司采用 NP 微码架构,例如 Chelsio 通过微码实现 iWARP。需要强调的是:很多“协议差异”在落地时往往更像“微架构差异”。例如使用 Intel E810 测试 RoCEv2 与 iWARP,小于 64Bytes 的延迟均约 4.5us(具体随环境而变)。
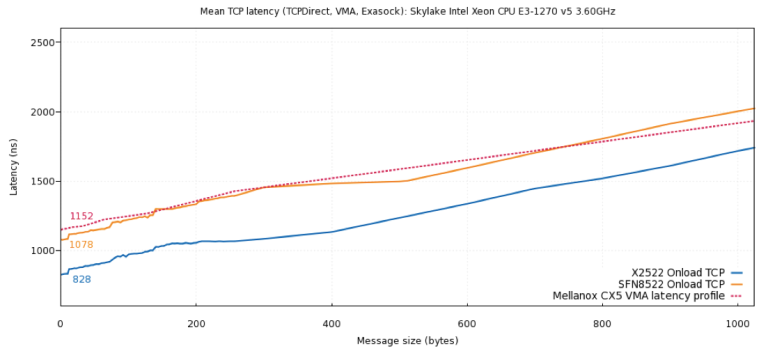
另一个侧面证据来自高频交易:行业尝试构建低延迟 TCP/UDP 转发,例如 SolarFlare OpenOnload、以及硬件实现的 TCP Offload Engine。在部分测试中,硬件 ASIC 平台的延迟甚至低于 Mellanox CX5。
极致低时延场景还会通过专用处理逻辑避免数据穿越 PCIe,例如面向高频交易的 Exablaze 网卡,最低 Tick-to-Trade latency 可到 34ns。
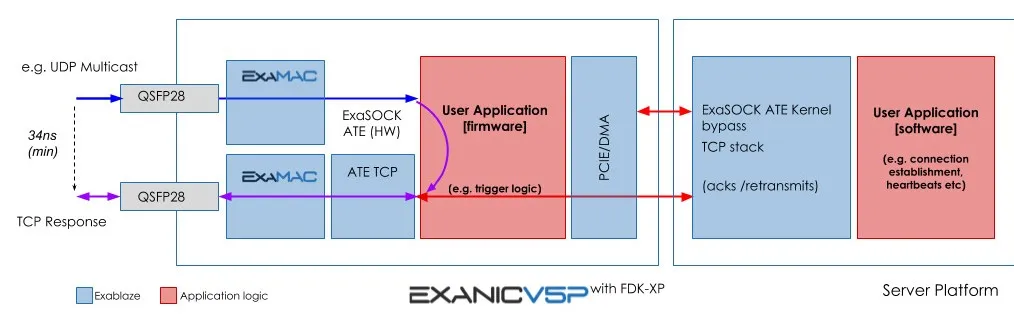
网卡微架构对端到端时延影响巨大。基于 ASIC 的 Mellanox 系列网卡通常显著低于基于 NP 微码的平台。但 ASIC 在功能复杂化时会面临可编程性挑战;而这种“架构约束 + RoCE 追求低时延的设计取向”在后续几年会引发一系列问题。下一章讨论复杂业务推动的智能网卡架构转型。
3. 复杂业务带来的架构转型
随着 100G 以太网到来,以及对主 CPU offload 的需求增长,网卡功能越来越复杂,工业界逐渐转向 SmartNIC/DPU/SuperNIC 等融合网卡形态。
3.1 SmartNIC 时代
从 ConnectX-3 开始,以太网速率逐渐跟上 PCIe 总线演进;与此同时 CPU 处理能力成为瓶颈。伴随 CPU 核数增长与虚拟化普及,工业界对网卡提出更多需求:例如 ConnectX-4 将 OVS Offload 到网卡,同时期也出现大量基于 CX4+FPGA、以及其他 FPGA/NP/ManyCore 的可编程方案。

需求变化带来网卡微架构“百花齐放”,但很多架构难以兼顾各种 offload 任务:例如某些可编程方案有编程便利性,却在 RDMA 低时延路径上表现不佳;可编程性也未必能覆盖足够广的业务面。一个常被忽略的原则是:ASIC 加速经常性路径,异常路径用通用处理器兜底。
在这一阶段,Mellanox 的策略值得关注:一方面通过 CX4/CX5+FPGA 形成 Innova 产品线覆盖部分需求;另一方面在 2016 年收购 EzChip,补齐网络处理器技术,并继承 EzChip 于 2014 年收购 Tilera 的 ARM 多核片上网络技术,由此基本完成 DPU 能力拼图。同期 Pensando、Fungible 等也相继成立。
3.2 成也 ASIC,败也 ASIC
Mellanox 的 ASIC 流控机制长期偏 Rate-based,这也推动了业界大量围绕交换机 buffer 的“精细化调参”。ConnectX-6 引入的可编程拥塞控制机制如下:
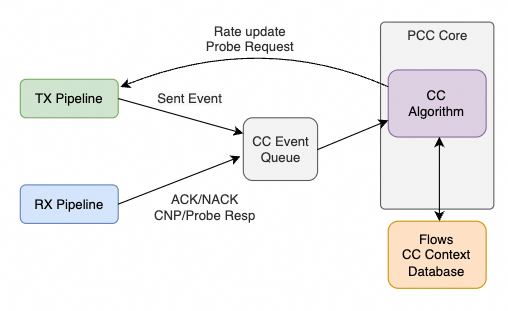
该机制中,拥塞控制算法主要通过控制发包速率生效:支持 ECN 的交换机标记拥塞,接收方回传信息给发送方,发送方降低注入速率;在无拥塞期再逐步加速。由于 ECN 只有二值标记,缺少细粒度信号,往往需要多次 RTT 才能收敛到合适速率。它可以把交换机队列维持在较浅水平,但对大模型 bursty 集合通信、All-to-All 的 Incast 场景、以及 IOPS 密集型场景并不理想。

相对而言,Window-based CC 如果能结合远端处理能力与 Packet Spray 等机制(可视为 pacing 的一种)来做,往往能更有效降低交换机 buffer 占用——这恰恰是关键所在。
丢包重传方面,Go-Back-N 机制简单,其隐含前提是 IB 的 credit-based 无损网络中丢包概率低,丢包更多来自误码。但在以太网与多路径/乱序场景下,Go-Back-N 的问题会被放大:不支持多路径或无序传输对 AI 训练集群是致命缺口,因此本质上需要更强的 SACK/Selective Repeat 等机制。由于硬件限制,在 IRN 中 Mellanox 做了简化版 Selective Repeat 来支持 Lossy RoCEv2。
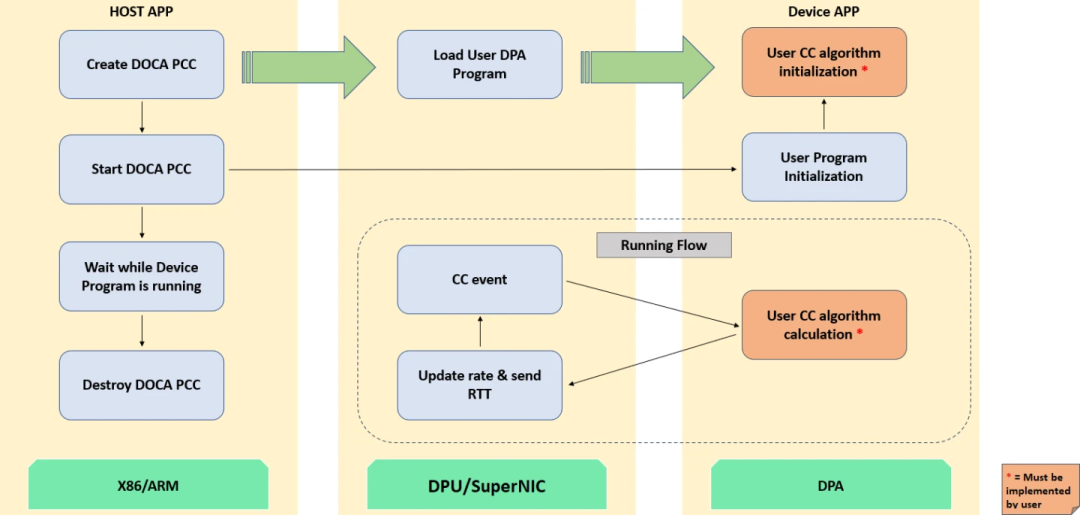
3.3 DPA 算力置换
为解决多业务 offload,Mellanox 早期在 CX6 中增加可编程 CC 引擎。直到 BF3 引入 Data-Path Accelerator(DPA),通过算力置换拥塞控制问题才得到一定缓解。

从 BF3 硬件看,它沿用 CX7 的 ASIC 快速转发路径;DPA 子系统旁挂在 ASIC FastPath 旁,并采用 RTOS 提供实时拥塞控制反馈。
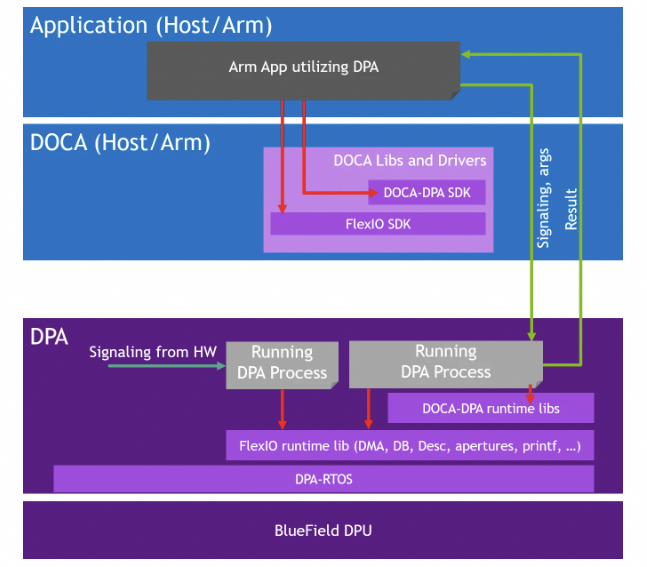
DOCA DPA 包含 16 个 Core、累计 256 个 Thread:
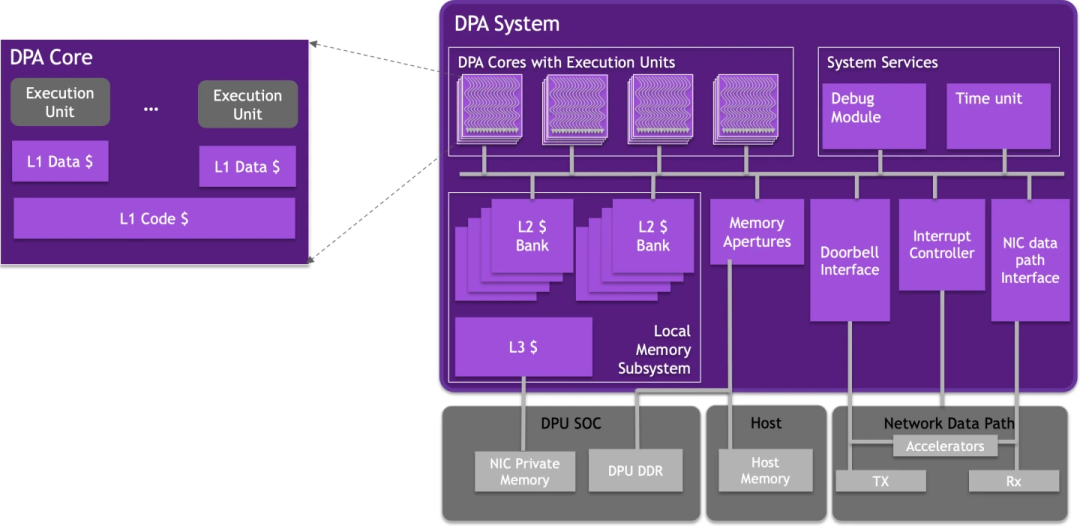
但遗憾的是,DOCA PCC 仍以 Rate-based 为主;Window-based 才更贴近“压低 buffer 占用”的核心目标。
3.4 自适应路由与多路径转发
AI 训练对大带宽的需求推动 Mellanox 从 ConnectX-5 开始支持 Adaptive Routing(AR),并支持 Out-of-Order delivery。其收益 Mellanox 自身也有清晰阐述:

但 AR 在以太网上会遇到连锁难题:ReOrder 如何实现?丢包重传逻辑如何与乱序共存?收到 CNP 后是降速还是切换路径?这些都容易陷入两难,最终 Mellanox 又回到了 Lossless 路线。
多路径拥塞控制会推翻很多单路径直觉:例如随机 Packet Spray 在统计意义上可能降低 burst 影响;Incast 也可能更易通过 Window-based 机制抑制。与此同时,降速还是选路本身就很难;如果用 Dynamic WRR 做多路径,又会遇到大权重流对某条链路形成 burst、链路故障时如何快速恢复且避免新拥塞等难题。另一个现实矛盾是:追求路径确定性时又希望使用交换机 hash 来决定转发路径,如何解耦同样困难。
3.5 RDMA 现代化
随着 RDMA 部署到存储等场景,硬件架构遇到新挑战:例如典型问题是 QP 数量上来后性能下降。
因此一些厂商做了“现代化改造”。两个代表性例子:
- AWS SRD:目标是多路径提高带宽利用率、降低长尾;同时缓解 HPC 应用 QP 爆炸的问题,因此选择支持 Reliable Datagram(RD)。
- 阿里云 Solar RDMA:面向 Block Server 接收多计算节点请求的模型,这些请求在与 Chunk Server 相连的 QP 上相互独立,不需要 RC 语义的严格保序,因此 RD 更贴合业务。
QP 爆炸的根因之一是片上 QP Context 缓存较小,Cache miss 后需要通过 PCIe 从主机侧拉取导致开销;后期 Mellanox 网卡已有明显改善,并在 ConnectX-4 开始支持 DCT(Dynamically Connected Transport)能力来缓解此问题。
3.6 UEC:另一个 Converged Ethernet 的故事
对互联技术 Ethernet / NVLINK / InfiniBand,英伟达在叙事上更像构造了三张网络,加上存储 backend 一共四张网络:
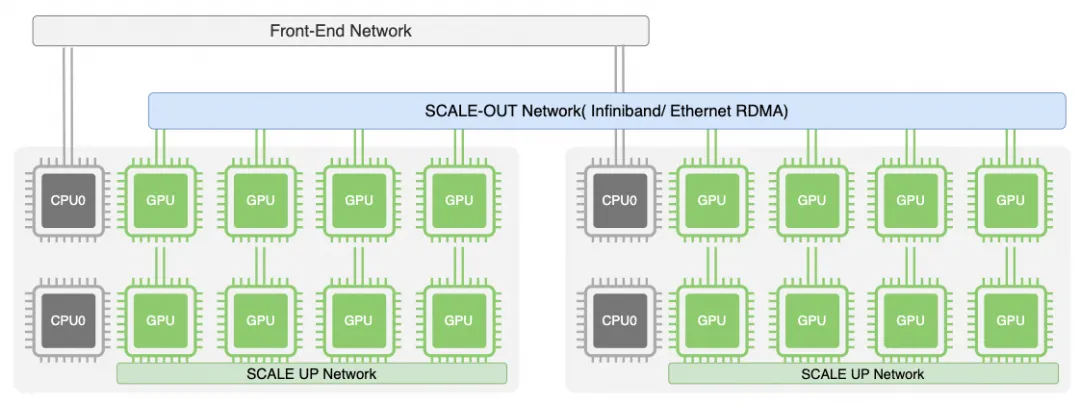
一方面认为东西向流量需要单独的 ScaleOut 网络,另一方面又强调南北向用以太网接存储;同时通过 GPUDirect-Async 又可细粒度访问存储网络:
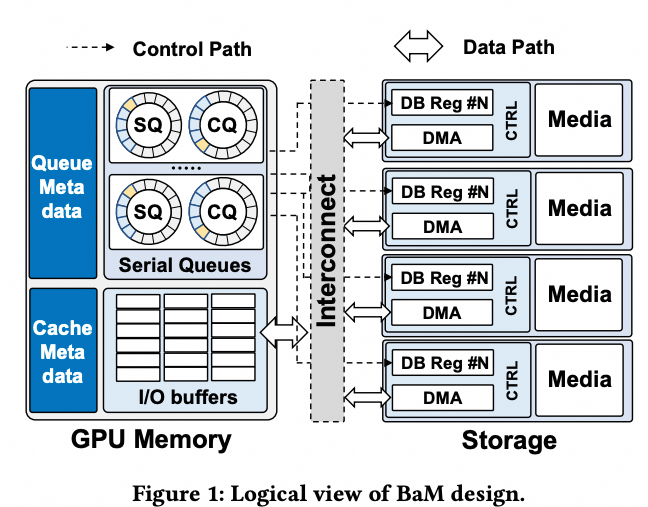
与此同时,工业界也出现新一轮 Converged Ethernet 思路:AWS 通过 Nitro EFA/SRD、Google 通过 IPU Falcon 把 FrontEnd 与 ScaleOut 进行整合;UEC 的出现试图用一套以太网技术统一多张网络。HPE-Cray 基于以太网的 Slingshot interconnect 也在 UEC 中被讨论,但 UEC 仍没有很好回答关键问题:拥塞控制仍有大量工作要做;ScaleUp 的内存语义与 ScaleOut/FrontEnd 的消息语义如何平衡也是难题——距离与拥塞都会引入延迟。
4. 历史的重复,架构的选择
RFC1925 有一句非常贴切:
One size never fits all.(没有一个方案适用于所有场景。)
业务驱动芯片架构变化,历史不断重复。RFC1925 也点出这一点:
Every old idea will be proposed again with a different name and a different presentation, regardless of whether it works.
RDMA 也会“再走一遍”:从早期基于处理器编程的 Myrinet,可编程网卡雏形;到基于 ASIC 的普通网卡;再到基于微码网络处理器的智能网卡;到 DPU 出现;今天又新增 SuperNIC 概念。本质上都在回答同一个问题:不同应用下芯片架构怎么选。
路由器的历史也高度类似:从通用处理器软件转发,到 ASIC 时代卷处理能力,再到微码流水线处理器,随后因业务复杂引入 NP,最终走向 ASIC Fastpath + 通用处理器的 Network Service Processor。BlueField 系列背后的两次收购路径(Tilera → EzChip → Mellanox → NVIDIA)其实非常清晰,正是这一演进逻辑在 NIC 领域的复刻。
4.1 网络处理器与网卡处理器的异同
本质上,路由器与网卡的定位非常相近:早期解决协议转换与高性能 I/O;后期不断叠加 QoS 隔离、安全、多业务等能力。到 DPU 时代业务更复杂,功能边界进一步扩张。
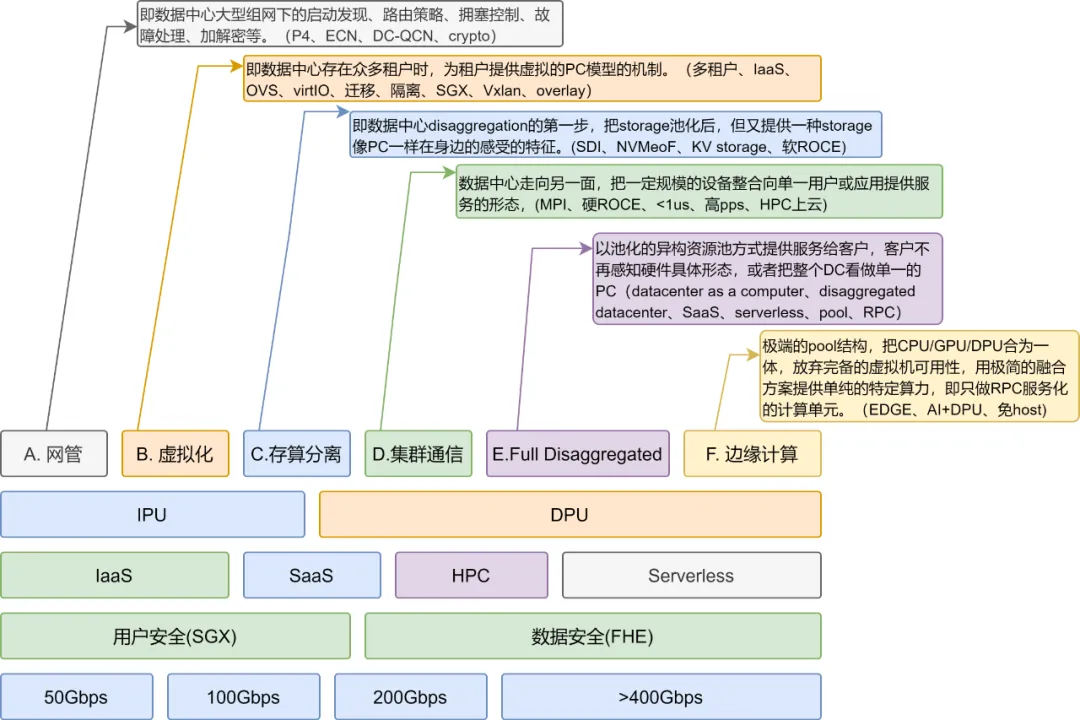
从产业角度看,很多 DPU 厂商背后都有网络处理器相关团队的影子。针对 I/O 密集且 latency-bound 的应用,体系结构的取舍也高度一致,大体经历几个阶段:
- 纯软件转发:早期通用处理器为主;早期 Myrinet 也通过固件/处理器方式优化集合通信
- ASIC 专用架构:为满足处理性能,转向硬件化 fastpath;类似 Mellanox ConnectX 系列纯 ASIC 数据面
- 微码 NP 架构:随着业务增多,采用流水线处理与微码可编程(如 IXP/EzChip 等);网卡侧也有厂商走类似路线
- 多核通用计算 + NOC:当业务变为带状态复杂处理(防火墙/DPI/IPS/IPSec 等),传统微码可编程性吃力,转向以大量通用核承载服务面;DPU 的 ARM 子系统、NOC 互联等与之呼应
5. 总结
本文从应用需求与芯片架构两个维度回看 RDMA 十年演进。核心结论是:理解应用、围绕应用定制架构,比“单指标最优”更重要。
(再次给出粗粒度对比)
| 场景 |
极低延迟 |
高带宽 |
INCAST |
QP 数 |
| HPC |
Y |
N |
N |
Y |
| 分布式 DB |
Y |
N |
N |
N |
| 分布式存储 |
Y |
N |
Y |
Y |
| AI 大模型 |
N |
Y |
Y |
Y |
架构争议的本质,往往是 On-Path Processing 与 Off-Path Processing 的取舍:
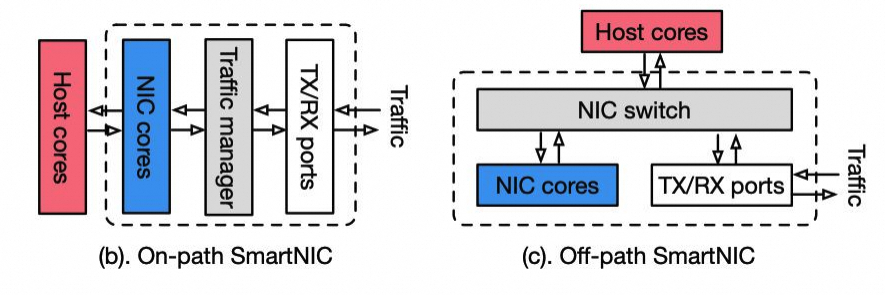
On-Path 无论是基于微码还是基于 P4,虽然增加了数据路径的可编程灵活性,但都面临延迟难以满足存储与 HPC 的挑战。因此无论是博通 TrueFlow 还是 Mellanox ASAP,最终更常见的落点都是:ASIC FastPath 处理经常性路径 + 通用计算核处理异常路径。这类“多业务融合网卡”的落地,在云基础设施与 Kubernetes/Docker 等云原生场景 也会不断被验证与重塑。
Mellanox 在 RoCEv2 上从 Lossless 到 Lossy 再回到 Lossless,很大程度上也受硬件架构约束:协议栈早期过度围绕低时延的 HPC/存储优化,而在 AI 大带宽、突发与多路径的场景中暴露缺陷。随着其演进到 BlueField-3 的 SuperNIC/DPU Mode 及后续架构,这些问题会逐步得到缓解,但拥塞控制、多路径与可编程性之间的权衡仍将长期存在。
参考资料
[1] 最佳实践-使用 SMC 和 ERI 透明加速 Redis 应用:https://openanolis.cn/sig/high-perf-network/doc/735934915657042794
[2] From Luna to Solar: The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud:https://rmiao.github.io/assets/pdf/solar-sigcomm22.pdf
[3] Empowering Azure Storage with RDMA:https://www.usenix.org/system/files/nsdi23-bai.pdf
[4] Datacenter Ethernet and RDMA: Issues at Hyperscale:https://arxiv.org/abs/2302.03337
[5] High Performance Ethernet for Computing and Storage Systems:https://www.ieee802.org/3/ad_hoc/ngrates/public/calls/22_0622_HPE/zhuang_nea_01_220622.pdf
[6] RoCE vs. iWARP Competitive Analysis:https://network.nvidia.com/pdf/whitepapers/WP_RoCE_vs_iWARP.pdf
A. 附录:RDMA 应用分析
A.1 分布式数据库
主要特征:极低延迟,单边操作
分布式数据库广泛使用 RDMA,主要用于分布式一致性处理。这里简述几个代表性工作。这类应用主要特征是:
- 分布式事务一致性需要降低延迟与长尾抖动
- 通常使用 RDMA OneSide 单边操作语义构建 RPC,在关键路径避免远端 CPU 参与执行
A.1.1 Oracle RAC
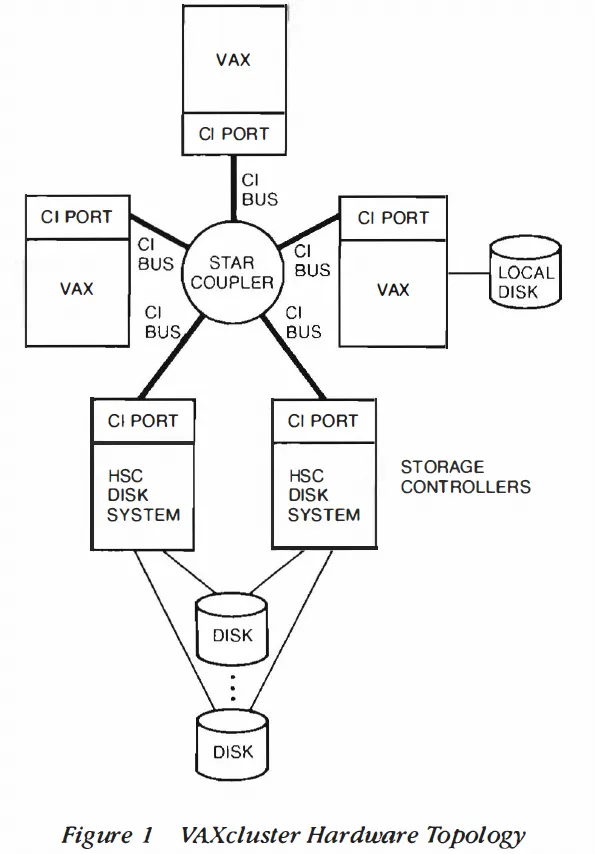
讨论 Oracle RAC 前,需要先了解其早期产品基于 DEC VAXCluster 集群技术实现。VAX 集群的定义中强调了通信与协同的重要性:

Oracle RAC 的 CacheFusion 分布式锁架构也在设计理念上与 DEC VAXCluster 的分布式锁架构高度一致。
在 VAXCluster 硬件中最重要的是一个基于消息(Message-Oriented)的高速互连总线 CI Bus,连接其上的网络设备称为 CI Port。
CI Port 负责仲裁/选路/数据传输,也可以让 VAX 主机通过网络引导无盘启动并共享后端存储。CI Port 的设计初衷主要有两点:
- 尽可能多地 offload 分布式节点通信开销
- 提供标准的基于消息的软件接口,用于处理器间通信与设备访问
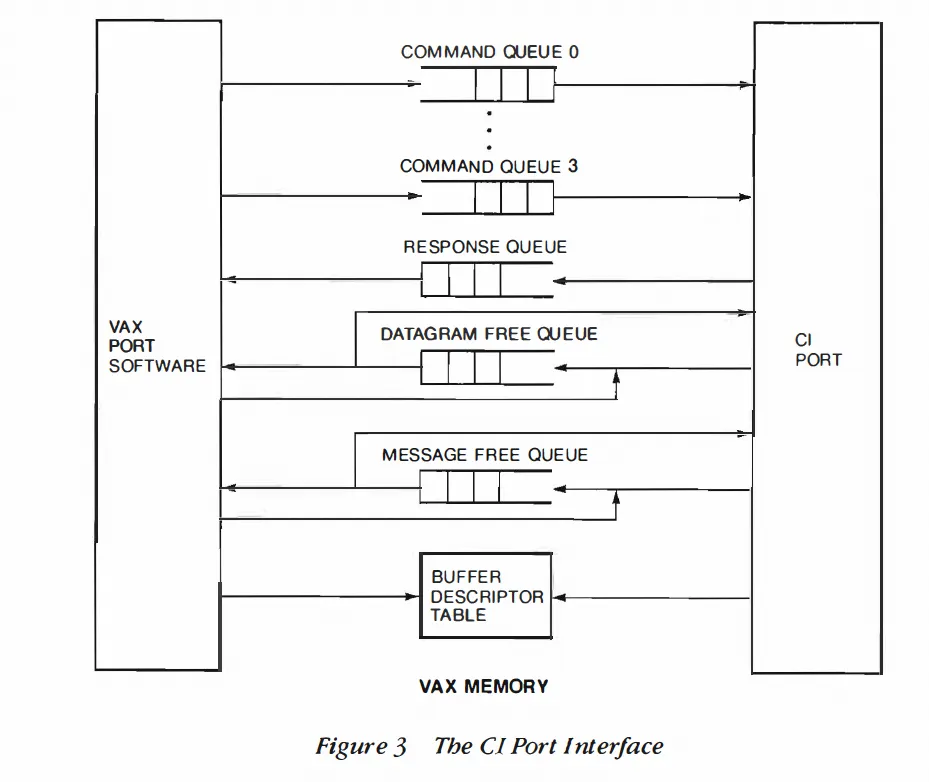
CI Port 上层软件系统称为 VMS System Communications Architecture(SCA)。SCA 提供三类通信服务:Datagram / Message / block data transfer。
- Datagram 类似 RDMA UD(Unreliable Datagram)
- Message 类似 RDMA RC 下的 SEND/RECV
- block data transfer 类似 RDMA 单边 READ/WRITE:直接把内存页按 block size 转移到其他节点并保证可靠传输
CI Port 队列定义与 RDMA 也高度相似:Command Q / Response Q / Message Free Q 与 RDMA 的 SQ / RQ / CQ 在抽象上接近。
分布式锁服务存在大量条件执行与复杂顺序依赖以维持一致性,处理延迟与长尾抖动直接影响数据库吞吐。Oracle RAC 后期大量采用 RDMA,并通过 RDMA OneSide 降低延迟,其动机与此高度一致。
A.1.2 IBM DB2 PureScale
DB2 PureScale 依赖 IBM 大型机中的 Coupling Facility(CF)协调事务处理:实现分布式锁/Cache/List 等结构协调多个处理器上的应用。CF 是专用物理处理器,具备数十 GB 内存与特殊通道(CF-Link),并运行耦合设施控制代码(CFCC)。
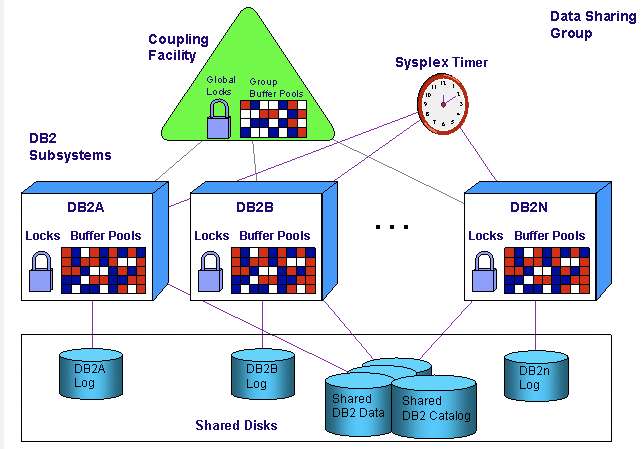
工业界也存在利用 X86 + RDMA 实现类似 Coupling Facility 的工作思路。
A.1.3 Microsoft FaRM
FaRM 是微软基于 RDMA 的分布式一致性系统,并在 Bing 搜索中部署。项目从 2014 年至今有多篇论文:
- 《FaRMv1: Fast Remote Memory》:两阶段提交 + OCC;用 RDMA 单边写消息与环形缓冲区实现低延迟消息原语,以及无锁读算法
- 《No compromises: distributed transactions with consistency, availability, and performance》:在高性能前提下提供严格可串行化/持久性与高可用
- 《FaRMv2: Fast General Distributed Transactions with Opacity》:用 RDMA 单边操作协调全局时钟并按时间戳排序事务
- 基于 FaRM 架构实现分布式内存图数据库《A1: A Distributed In-Memory Graph Database》并落地
其使用 RDMA_WRITE 实现消息传递:
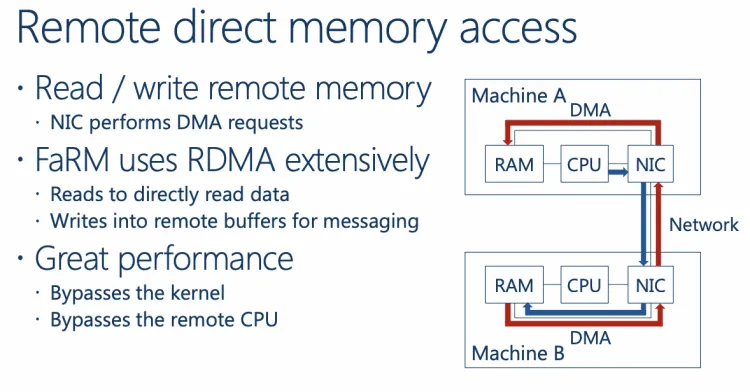
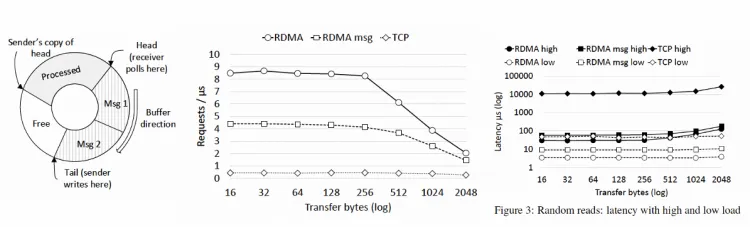
通过构造内存环形队列与特定数据结构实现单边操作 RPC,显著降低延迟:
A.1.4 PolarDB 严格一致性读及 Serverless 架构
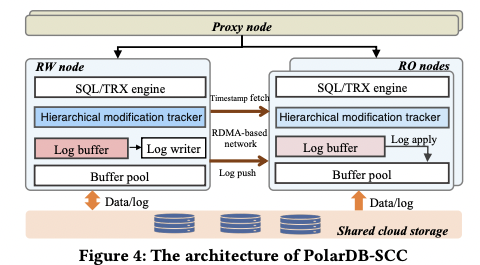
PolarDB 也使用 RDMA 优化性能,通过 RDMA 降低读写延迟并实现严格一致性。论文可参考《PolarDB-SCC: A Cloud-Native Database Ensuring Low Latency for Strongly Consistent Reads》。
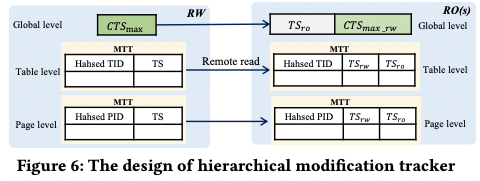
针对云上 Serverless 架构,也可参考《PolarDB Serverless: A Cloud Native Database for Disaggregated Data Centers》。
参考资料:
[1] https://www.vldb.org/pvldb/vol16/p3754-chen.pdf
[2] https://users.cs.utah.edu/~lifeifei/papers/polardbserverless-sigmod21.pdf
[3] 转自公众号作者:zartbot
 发表于 2025-12-24 17:35:24
|
查看: 193|
回复: 0
发表于 2025-12-24 17:35:24
|
查看: 193|
回复: 0
