Redis作为高性能的内存数据库,支持多种数据结构,但原生并不提供类似SQL的条件查询与分页功能。在面对评论列表、信息流检索等需要结合分页、排序及多条件筛选的业务场景时,仅依赖Redis的基础功能会难以直接应对。
本文旨在探讨一种结合了分页与多条件模糊查询的Redis组合方案,分别从分页实现、模糊查询实现、两者组合以及性能优化四个方面,为你提供清晰的解决思路。
Redis的分页实现
在传统持久化数据库(如MySQL)中实现分页查询是常见操作,但在某些业务场景下,数据可能并未持久化,或出于性能考虑已将热点数据加载至如Redis的缓存数据库中,此时就需要在Redis层面实现分页。
Redis的分页功能可以基于其提供的ZSet(有序集合)数据结构来实现。ZSet的以下指令在分页中扮演关键角色:
- ZADD:
ZADD key score member [[score,member]…] 用于向有序集合添加元素,并为每个member绑定一个排序分数score。我们通常将数据的时间戳作为score以实现按时间排序,当然也可根据具体业务选择排序依据。
- ZREVRANGE:
ZREVRANGE key start stop 用于返回有序集合中指定排名区间内的成员,这正是实现分页查询的核心指令。
- ZREM:
ZREM key member 可根据key移除指定成员,适用于删除评论等场景。
因此,ZSet非常适合用于实现分页。下图演示了基于ZSet的分页查询过程,包括插入新记录后的查询变化:
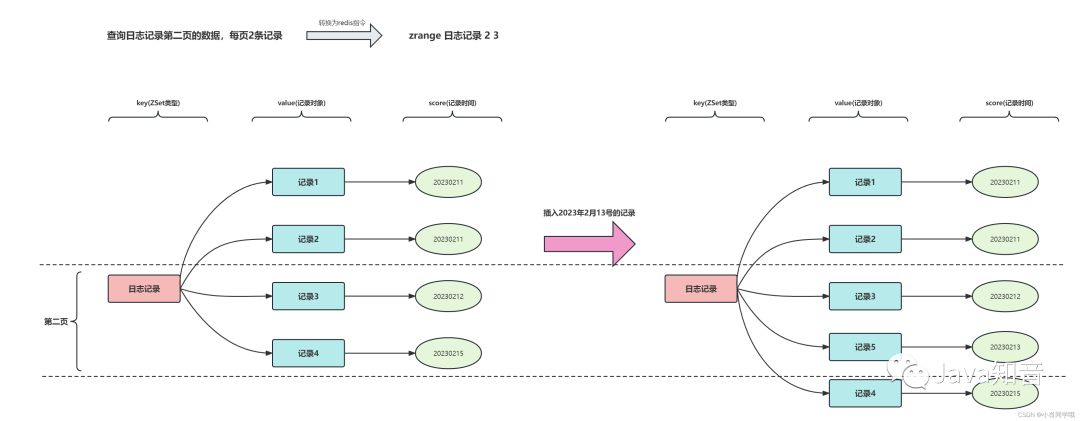
虽然Redis的List结构也能实现分页,但List无法自动排序,且ZSet还可以根据score范围筛选数据,灵活性更高。因此,在大多数需要排序和分页的场景下,ZSet是更优选择。当然,若业务需要存储重复数据,则需考虑使用List或其他方案。
Redis的多条件模糊查询实现
Redis是键值对数据库,通过Key直接取值虽然高效,却缺乏像关系型数据库那样灵活的条件查询支持。因此,我们需要借助Redis的其他结构自行实现模糊查询。
一种常见的实现方式是使用Hash结构。我们可以将数据的某些查询条件拼接作为Hash的field,而将数据详情(如JSON字符串)作为value存储。然后,利用HSCAN指令遍历所有field并进行模式匹配,筛选出符合条件的键。
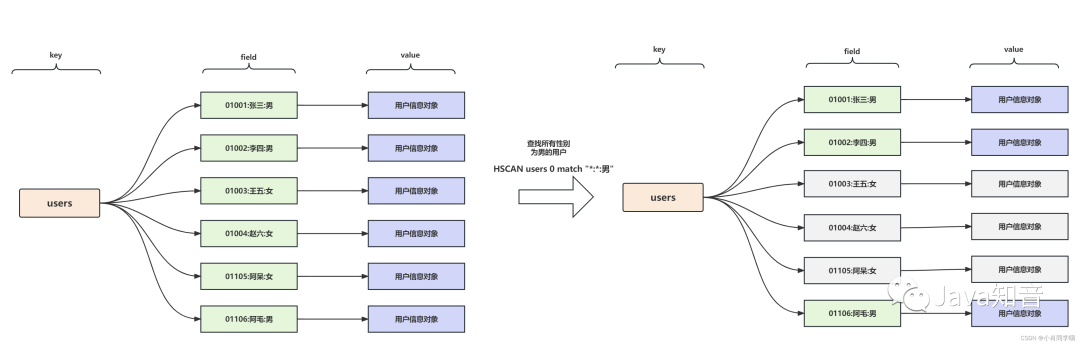
为便于后续操作,通常会将所有匹配到的field存入一个Set或List中。这样,我们就能根据这些field去获取完整的数据。以下为模糊查询的示例(假设field的命名规则为<id>:<姓名>:<性别>,value为用户详情的JSON串):
查询所有性别为女的用户
查询所有名字中姓“阿”的用户
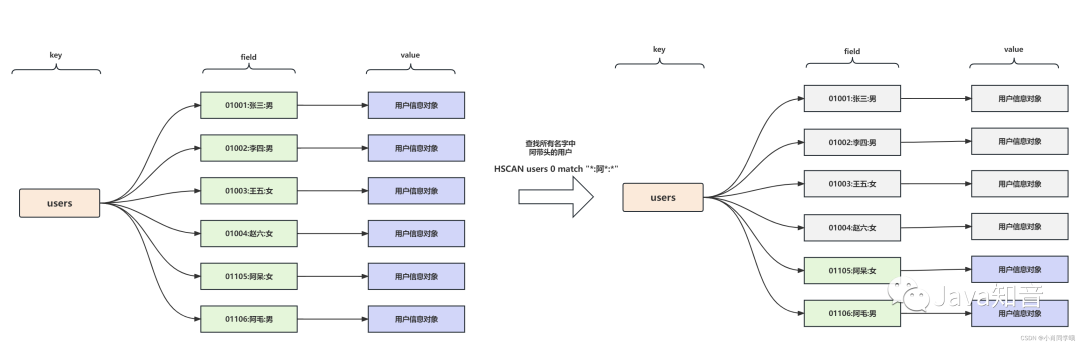
需要注意的是,HSCAN的模式匹配基于遍历实现,每次匹配都需要扫描所有键,在数据量大时效率较低。后续章节将讨论优化方案。
Redis的分页+多条件模糊查询组合实现
单独使用ZSet分页性能良好,但在实际应用中,分页往往需要结合动态的筛选条件。对此,通常有两种思路:
- 数据已持久化:在数据库(如MySQL)中完成条件查询和分页,再将结果集缓存至Redis。
- 完全在Redis中实现:在Redis内部完成多条件模糊查询并分页。
第一种方案简单直接,但如果数据为了追求高并发与响应速度,是先写入缓存,再异步持久化到数据库的,那么第一种方案就不适用了,必须采用第二种方案。
实现思路
首先,采用上文模糊查询的方案,将数据按约定格式(如<id>:<姓名>:<性别>)存入Hash。
当收到一个查询请求(例如匹配串为*:*:男,意为查询所有男性)时:
- 首先在Redis中查找是否存在以该匹配串为Key的ZSet。
- 如果不存在,则使用
HSCAN遍历Hash的所有field,将所有符合条件的field筛选出来,并将其作为一个新的有序集合(ZSet)存入Redis,此ZSet的Key即为该匹配串。
- 如果已存在对应的ZSet,则直接使用
ZREVRANGE等指令对该ZSet进行分页查询。
通过这种方式,我们实现了条件查询与分页的衔接。每次新的条件组合查询,在首次执行时会创建专属的ZSet用于分页,后续相同条件的查询则直接复用。
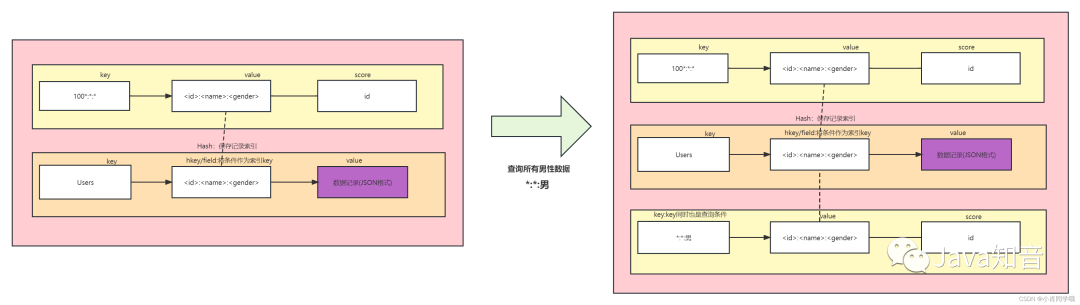
图示:未命中缓存时,根据匹配串生成新的ZSet集合用于分页。
性能优化方案
上述基础方案存在两个潜在问题:缓存无限增长和数据显示实时性。
1. 缓存集合管理
匹配串的组合可能非常多,无限制地创建ZSet会给缓存数据库带来巨大压力。解决方案是为每个动态生成的ZSet设置一个合理的过期时间(TTL)。基于时间局部性原理,长时间未被访问的查询结果其缓存会被自动清理。对于每次命中的缓存,则刷新其过期时间。
2. 数据实时性
缓存ZSet在创建时基于当时的Hash数据快照,后续新增或修改的Hash数据无法自动同步到已存在的ZSet中。有两种解决思路:
- 写时同步:在数据插入Hash时,同步将其
score和member插入到所有相关的ZSet中。这需要额外的元数据来标识数据与查询条件的关联关系,实现较复杂。
- 定时更新:为ZSet设置较短的过期时间,或定时重建缓存。这种方式实现简单,但无法保证数据的绝对实时性,适用于对实时性要求不苛刻的场景,在后端开发中需根据业务容忍度进行选择。
总结
本文系统性地阐述了在Redis中实现分页、多条件模糊查询以及两者组合应用的可行方案与优化思路。在实际开发中,需要根据数据规模、实时性要求和查询模式来灵活选择和调整这些方案,以期在性能与功能之间取得最佳平衡。
 发表于 2025-12-24 20:59:36
|
查看: 174|
回复: 0
发表于 2025-12-24 20:59:36
|
查看: 174|
回复: 0
