英特尔在人工智能与高性能计算领域持续推进芯片封装技术的极限。其早前打造的、包含47个芯片的Ponte Vecchio计算GPU曾创下多芯片设计数量的纪录,而如今,英特尔晶圆代工部门正规划一款更为极致的多芯片封装产品。
这款概念性封装设计旨在集成至少16个计算单元和24个HBM5内存堆栈,其整体尺寸可扩展至当前市场上最大AI芯片的12倍。这一设计超越了传统光罩尺寸的限制,为未来的计算机架构设计提供了全新的想象空间。
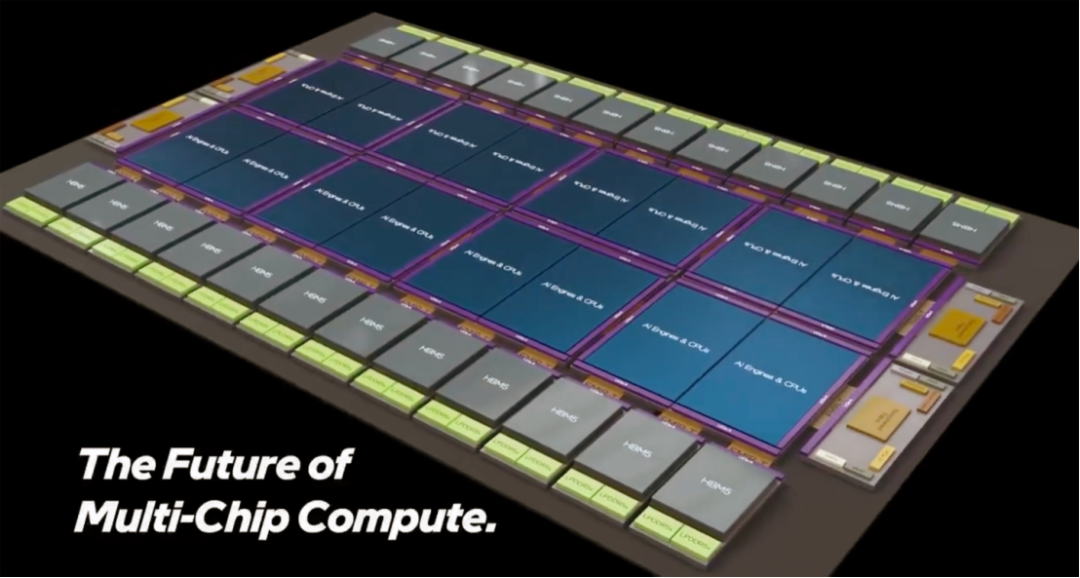
图1:英特尔展示的超大规模多芯片计算未来概念图
该封装的核心由16个大型计算单元构成,这些单元计划采用英特尔未来的14A或更先进的14A-E工艺节点制造。这些计算单元被放置在八个基础芯片之上,基础芯片则采用18A-PT工艺,并集成了硅通孔和背面供电技术,可以承担部分计算任务或为上层芯片提供大容量的SRAM缓存。
连接这些芯片的关键在于英特尔的先进互连技术。计算单元与基础芯片之间通过超高密度(10微米以下)的铜对铜混合键合技术连接,这为数据与功率传输提供了最大带宽。这项Foveros Direct 3D技术代表了英特尔目前在3D封装领域的最高水平。同时,基础芯片之间以及与I/O芯片的横向连接,则通过采用UCIe-A标准的EMIB-T技术实现,正是这套系统为多达24个HBM5内存堆栈提供了接入能力。

图2:英特尔提出的可扩展架构,旨在突破传统光罩尺寸限制
值得注意的是,英特尔在此次演示中提议使用基于UCIe-A的定制接口来连接HBM5模块,而非标准的JEDEC接口,这可能是为了追求更高的性能与容量定制化潜力。整个封装架构还具备高度的灵活性,未来可集成PCIe 7.0、光引擎、各类专用加速器乃至LPDDR5X内存,以满足不同场景的多样化需求。
根据英特尔展示的信息,这种“极端规模”的设计可能在本十年末实现。要实现这一目标,英特尔不仅需要完善其18A和14A制程节点,还需攻克Foveros Direct 3D封装技术的大规模量产难题。这其中包括确保超大尺寸芯片在主板上的机械稳定性,以及解决可能高达智能手机面积的处理器所带来的巨大散热挑战。
随着AI大模型对算力的需求持续爆炸式增长,业界面临的瓶颈已从单纯的处理器速度转向了“内存墙”——即数据在内存与计算单元之间传输的物理极限。先进的多芯片封装技术,正从制造流程的辅助环节,转变为突破性能瓶颈、驱动半导体创新的核心前沿。
对芯片封装、算力架构等前沿技术感兴趣的开发者,欢迎在云栈社区交流探讨。 |  发表于 2025-12-30 02:06:07
|
查看: 191|
回复: 0
发表于 2025-12-30 02:06:07
|
查看: 191|
回复: 0
