随着大模型参数规模突破万亿级别、训练数据集跨越万亿Tokens量级,单芯片算力增长已难以匹配指数级增长的模型复杂度。为突破内存墙、通信墙与计算墙的物理瓶颈,Google 采用了异构双平面的组网架构:
- ICI 后端网络(内存语义平面):不同于竞品通常采用的 InfiniBand 或 RoCEv2,Google 部署了轻量级的 G-ICI (Google Inter-Chip Interconnect) 专有协议。该协议摒弃了传统网络栈的帧开销,专注于张量并行(TP) 与 流水线并行(PP)的微秒级同步以及 Pod 内部的高频梯度同步(All-Reduce),实现了跨芯片的 HBM 内存空间全局寻址。
- Jupiter DCN 前端网络(存储与管控语义平面):与互联网上其他公开渠道常看到的2022年以前采用5层CLOS架构组网不同,本文特指2022年后引入 OCS 光交换核心层的 Jupiter Evolving 架构。除了常规的全局检查点(Checkpoint)读写和海量训练数据加载外,Jupiter DCN 的独特之处在于依托 Multislice 全栈技术,承担了跨 Pod 的数据并行(DP) 和 完全分片数据并行(FSDP)流量,实现了多租户环境下的全局资源调度与线性扩展。
Google ICI 后端网络架构演进回顾
在相关文章中已深度复盘 Google TPU 智算集群的网络架构演进,重点剖析了 3D Torus 拓扑与 OCS(光交换)技术的协同机制。文章从最小拓扑单元 4x4x4 Cube 出发,推演复盘了 TPUv4 4096 Pod标准3D Torus环面与 TPUv7 9216 Pod的Twisted 3D Torus环面组网拓扑背后的原理和数学实现,揭示了 Google 如何在万卡集群规模下实现确定性低延迟与极致 TCO(总拥有成本)优化。

图 1: Google TPU v7 Ironwood 9216 节点 ICI 后端网络连接示意图
Jupiter DCN 物理网络架构:光电融合拓扑深度解析
承接上文,接下来我们深度解析 Google 如何用一套物理与逻辑高度解耦、硬件与软件深度协同的 Jupiter DCN(数据中心网络) 支撑 147,456 颗 TPU v7 的超大规模 AI 集群。这套基于 Ethernet/Falcon 协议的 Jupiter DCN 前端网络与 TPU 内部基于 3D Torus/G-ICI 协议(9.6T/chip) 的 ICI 后端专网实现了彻底的物理隔离。Jupiter DCN 全网部署了 73,728 块 400G DCN IPU 网卡,4,608 台 12.8T ToR (TH3)、2,304 台 25.6T Leaf (TH4) 和 2,304 台 25.6T Spine (TH4) 交换机。接下来我们一起解构这庞大物理网络集群背后分层设计的奥秘。
3.1 拓扑层级视图:基于 Apollo OCS 的分层解构
Google Jupiter DCN 的核心变革在于引入光交换(OCS)重构了传统的数据中心网络拓扑。下图展示了从最底层的计算节点(Tray)到最顶层的光互联核心(OCS Core)的完整数据路径。
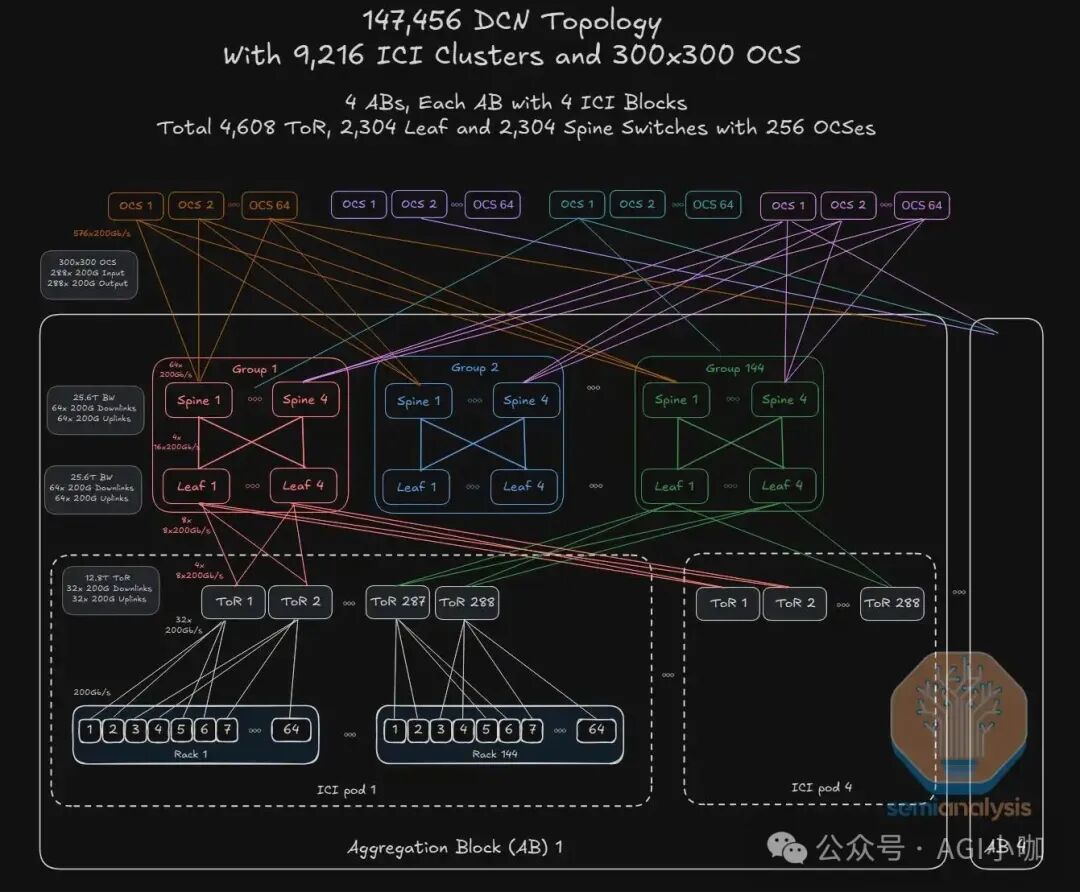
图 2: Google Jupiter DCN 物理组网拓扑全景
(一) 联合Intel定制IPU网卡
作为整个拓扑的最小原子接入单元,每个计算托盘(Tray)集成 4 颗 TPU v7 芯片与 1 颗 Host CPU(Google Axion 或 Intel Xeon),通过 PCIe 5.0 x16 链路(单向64GB/s)实现 CPU 与 TPU 无损通信互联。在网络接入方面,每个托盘配置了 2 张 Google Titanium IPU 网卡:这是 Google 与 Intel 联合研发和定制的、基于 Intel E2200(代号:Mount Morgan) ASIC 的单芯片,支持 400Gbps 吞吐与 PCIe Gen 5.0 x16 接口,每张网卡对外可提供 2*200Gbps 的上行链路接入到每个机柜的 TOR 交换机上。
(二) 联合 Broadcom 和 ODM 厂家自研电交换机
Google 采用液冷高密机柜的部署策略,每个机柜可以容纳 16 个托盘,合计 64 颗 TPUv7 芯片+16 颗 CPU,采用 双 ToR 冗余设计 接入 Jupiter DCN 网络中。依托交换芯片巨头 Broadcom Tomahawk 3(单芯片容量 12.8 Tbps) 和 ODM 厂家代工生产的自研交换机作为 TOR 层,严格遵循 32×200GE 下行 + 32×200GE 上行的 1:1收敛比,实现机柜内无拥塞、冗余网络,全网合计部署了 4,608 台 此类 ToR 交换机。
Google Jupiter 的 Leaf-spine 层同样采用与 Broadcom 和 ODM 厂家代工的自研电交换机。每 144 个机柜及其上行接入的 288 台 ToR 交换机组成一个 Pod 单元模块,Pod 与 Pod 之间的通信通过 Group 模块交换网络实现东西向流量通信。而每个 Group 内部由 4 台 Leaf + 4 台 Spine 组成,288 个 Group 电交换网络模块为 4 个 Pod 提供东西向流量交换以及向上的 OCS 连接。值得注意的是,Leaf 和 Spine 采用的是 Broadcom Tomahawk 4 ASIC(单芯片容量 25.6Tbps),而非更新的 51.2T Tomahawk 5 ASIC,全网共计部署了 2,304 台 Leaf 与 2,304 台 Spine。
(三) 基于 MEMS 的 Apollo OCS 全光交换矩阵
图 2 全景拓扑图最顶端的 4 组合计 256 台 Apollo OCS(内部代号 Palomar 演进版) 是前端网络设计的核心亮点,也是 Google Jupiter DCN 网络 从 2012 年 CLOS 架构全面转向以 Apollo OCS 为核心的 Direct Mesh 架构 的关键。它基于 3D MEMS 镜片阵列与高精度 2D 光纤准直器技术,配合环形器实现单光纤的双向传输,能够实现 300×300 端口的全光动态调度。256 台 OCS 组成的光交换矩阵,实现了 4 个超大 Aggregation Blocks 合计 36,864 CPU 计算节点和 9216 台交换机(TOR/Leaf/Spine) 的通信。
扁平化的光交换核心层不仅极大地简化了网络架构,还能实现极低的插入损耗与协议无关的透明传输。更为关键的是,其波长与端口速率无关的特性意味着,即使 Spine 层交换机从 400G 升级到 800G 乃至 1.6T,也无需更换核心 OCS 设备。
3.2 超大规模组网背后架构设计亮点揭秘
(一) 边缘计算单元:Titanium IPU 与 Host 协同
Google Cloud 与 Intel 在基础设施处理器(IPU)领域的合作,是“软件定义基础设施”在异构计算时代的成功实践。双方的战略合作始于 2022 年联合发布的 首款 ASIC 架构 IPU E2000(代号 Mount Evans)。而在 14 万 TPUv7 的 Jupiter DCN 前端网络中,采用的是基于 Intel E2200 (Mount Morgan) 定制的最新 Titanium IPU 网卡,解锁了 400Gbps 单芯片吞吐和双口 2*200Gbps 上行带宽接入能力。该网卡将 Google 私有 Falcon 协议内置于芯片,利用硬件级流控实现类 RDMA 的高性能与以太网的弹性,并集成线速加密引擎支持 PSP 安全协议,在不占用 Host CPU 算力的前提下构建零信任通信;同时内嵌 P4 可编程流水线,将虚拟交换数据平面下沉,让每一台 TPU 主机进化为具备边缘交换能力的高性能节点。

图 3: Intel E2200 Titanium IPU 架构逻辑图
(二) 交换网络:基于商用芯片的 TCO 优化策略
作为 Broadcom 最大的数据中心客户之一,Google 享有最新一代 Tomahawk 芯片的优先供应权与深度定制能力。但在 Jupiter DCN 网络的芯片选型上,Google 并未盲目追逐最新制程,而是基于 200GE 网络颗粒度的适配性与成本考量,务实选择工艺成熟的 TH3/TH4 芯片以获取“代差红利”。
与国内头部云厂商的底层网络构建逻辑类似,Google 采用定制设计 Broadcom Tomahawk ASIC 并交由 Celestica(天弘)、Quanta(广达)和 Edgecore(智邦) 等 ODM 厂商 代工的策略,彻底剔除品牌溢价并加速软硬协同迭代周期,确保了在万卡集群规模下的设备一致性与交付效率。
(三) 核心交换:OCS 光交换技术与架构重构
早期的 Jupiter 网络 (Jupiter Rising 阶段) 采用标准的 5 级 Clos 架构,依赖商用电子交换芯片构建分层网络。虽然解决了由 1G 向 10G/40G 的带宽扩展问题,但随着节点规模突破 10 万级,电子交换层级过多带来的 SerDes 功耗墙、光电转换(O-E-O)成本飙升以及布线复杂性逐渐成为瓶颈。
面对上述物理瓶颈,2022 年 Google 实施了数据中心 DCN 网络历史上最激进的一次重构,即从 CLOS 架构全面转向以 Apollo OCS 为核心的 Direct Mesh 架构。其核心在于,基于 MEMS 技术的全光交换矩阵替代了庞大的 Super-Spine 电交换层。得益于 MEMS OCS 对波长和速率的天然透明性,即使 Spine 层交换机从 400G 升级到 800G 乃至 1.6T,也无需更换核心 OCS 设备,从而克服了摩尔定律失效带来的硬件迭代压力。

图 4: Apollo OCS (Palomar) 光学核心原理示意图
OCS 的引入不仅是传输介质的物理变革,更赋予了网络架构无与伦比的动态重构能力与增量扩展弹性。在面对新旧 TPU v4 和 TPUv7 集群混合部署场景时,SDN 控制器和 OCS 协同调整微镜角度,即可在毫秒级时间内完成光路重组,无需任何人工介入插拔光纤,实现了对在运业务的无感扩容,同时支持从标准的 3D Torus 动态切换至 Twisted 3D Torus 拓扑。
从能效与成本维度考量,OCS 方案相比于同等带宽规模的 InfiniBand 组网方案,整体功耗降低了 30% 至 40%,且其在总系统拥有成本(TCO)中的占比不到 5%,功耗占比仅为 3%,构筑了极具竞争力的工程护城河。
面对光路切换带来的拓扑动态变化、数万条链路的拥塞控制以及微秒级的容错需求,接下来我们将深入解读 Google 如何通过 Jupiter DCN Overlay 层的 感知(CSIG)、传输 (Falcon)、接口(SAI)到调度(Orion) 的组合拳解决方案开启全局视野。
DCN Overlay 控制体系与全栈闭环
4.1 传输层 (Falcon):面向硬件卸载的协议设计
Falcon 是 Google 专门为配合 Titanium IPU 和 OCS 网络设计的传输协议,旨在彻底替代 TCP 和传统 RDMA,并提前集成到 ASIC 上提供硬件级传输卸载解决方案。
Falcon 原生支持细粒度的逐包级 多路径传输、数据包喷洒技术(Packet Spraying),彻底消除了传统 ECMP 哈希不均、长尾延迟的问题。为了解决逐包级多路径导致的乱序问题,Titanium 网卡内置了高性能的乱序重排引擎:Falcon 协议头中包含高精度序列号,接收端硬件能够以线速重组数据包。一旦发现丢包,Titanium 会立即主动触发微秒级的快速重传请求,而不是被动等待 TCP 超时。
4.2 感知层 (CSIG):高精度拥塞信号机制
标准 ECN (RFC 3168) 的拥塞控制机制只能通过一个比特(CE bit)告知发送端网络出现了拥塞,却无法准确定位拥塞点。为此,Google 引入了 CSIG (Congestion Signaling) 机制:创新性地在以太网头和 IP 头之间插入一个 L2.5 Shim Header。在 Jupiter DCN 网络沿途的 ToR/Leaf/Spine 交换机上,都会执行交换机端口当前指标(如队列深度的反压值、瞬时可用带宽)与 CSIG TAG 包头中的 Value 进行比较、按需重写和更新 Value 以及对应的 Locator Metadata(如 ToR ID)。
当数据包到达接收端 Titanium 网卡时,CSIG 信息被提取并通过 ACK 包带回发送端。这样,发送端 Titanium 网卡不仅知道网络拥塞状况,还能精确知道拥塞发生在哪个 ToR 的上行口。发送端的拥塞控制算法 (如 Swift 或 UEC 的 NSCC) 利用这些精确的数值(而不仅仅是 0/1 信号)计算发送窗口。例如,如果指标显示只有 50Gbps 可用带宽,发送端可以直接将速率调整至 50Gbps,而无需通过试探性增减来逼近极限。
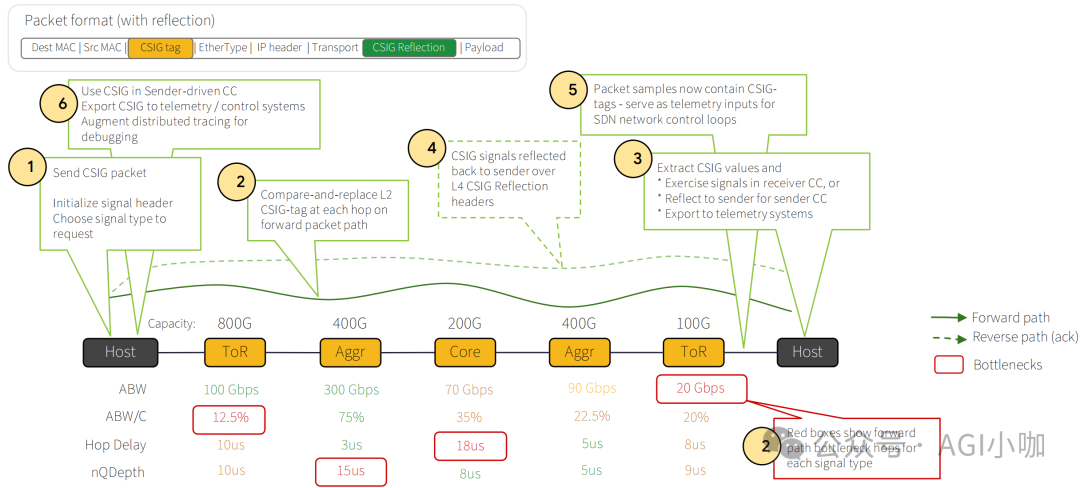
图 5: CSIG 端到端拥塞感知流程与数据包格式
4.3 调度与接口层 (Orion & SAI):全域 SDN 控制平面
为了屏蔽底层 ASIC(Broadcom TH3/TH4)的差异,Google 深度参与了 OCP SAI (Switch Abstraction Interface) 标准定义。所有控制指令都通过标准化的 SAI 接口下发,使得上层 Orion 控制器可以无缝管理底层来自不同厂商的交换机芯片,实现了真正的可编程确定性网络和网络自动化。
Orion 作为 Google 的 第二代 SDN 控制器,分布式部署于集群之上。它通过二分图匹配算法进行全局资源调度,实现了“光电交换”层面的深度协同。一方面,Orion 通过专有控制通道向 OCS 下发微镜偏转指令,在物理层面重构 Aggregation Block 间的互联拓扑以动态分配带宽;另一方面,Orion 同步通知 Falcon 协议栈更新路由表,以实时适配新的网络架构。
针对 AI 训练流量“长周期、高可预测”的特性,Orion 采用了 Rail-Aligned 路由策略,将同一训练任务的流量静态绑定至特定物理路径,大幅减少动态冲突;同时结合 Hedging(对冲)算法智能规避哈希冲突,确保全网高达 13 Pb/s 的对分带宽得到高效利用。
依托对 L2.5 层 Shim Header 中 CSIG 遥测数据的深度解析,Orion 实现了纳秒级的全网负载感知,并将网络抖动精准压制在微秒级。在运维场景中,系统利用 OCS 的光电路交换能力,将指定区域流量无损迁移至备用路径,达成了业务零感知的在线热维护。Orion 深度统筹了主机侧 Falcon 的拥塞控制、交换侧 Shared Buffer 的动态分配以及核心层 OCS 的光路重构,成功构建起一套端到端协同的流量治理闭环。
展望
本文系统剖析了 Google Jupiter DCN 的演进逻辑,阐述了其如何以 OCS 光交换矩阵取代传统 CLOS 架构中的 Super-Spine 层,并协同 Titanium IPU 实现 Falcon 协议的硬件级卸载,融合 CSIG 的纳秒级拥塞感知机制,从而成功构建了一套物理拓扑与逻辑控制高度解耦、却在调度层面(Orion)深度协同的智算网络。这一架构变革不仅从根本上突破了超大规模集群面临的布线复杂度与散热瓶颈,更为 AI 基础设施确立了一套从芯片互联到数据中心架构的工程范本。
在产业生态层面,Google TPU 产能正处于指数级爬坡期。近期 Meta 与 Google 确立了基于 TPU 的 “先租后买” 混合部署战略,并联合启动了 TorchTPU 项目,致力于通过 PyTorch/XLA 在 TPU 上的深度优化,为全球开发者提供更灵活的算力选择。
面向未来 百万卡 超大规模集群互联挑战,Jupiter DCN 的 OCS 光交换架构展现了极具前瞻性的技术韧性。面对下一代 TPU v8/v9 对 I/O 带宽的爆发式需求,尽管边缘侧的交换层势必向 Broadcom Tomahawk 5 (51.2T) 乃至 Tomahawk 6 迭代演进,但核心层凭借 MEMS OCS 对波长与速率的天然透明性,无需物理更替即可实现无感升级。
在探索极限互联解决方案的道路上,各家技术路线竞相绽放。更多关于前沿网络架构与云原生技术的深度讨论,欢迎在 云栈社区 与广大开发者继续交流。
 发表于 2025-12-30 06:04:31
|
查看: 516|
回复: 0
发表于 2025-12-30 06:04:31
|
查看: 516|
回复: 0
