如果面试时被问到“如何实现电商订单超时30分钟自动取消”,你会怎么回答?如果直接回答“写个定时任务每分钟扫描数据库”,可能会像这位求职者一样,在面试中陷入被动。面试官通常不会满足于此,他们会深入追问:面对千万级数据,每分钟全表扫描的数据库压力如何处理?如何保证取消动作的时效性?服务或任务宕机了怎么办?
实际上,这道题考察的是高并发场景下海量延迟任务的系统设计能力。核心思路并非轮询数据库,而是让超时的订单“主动通知”系统。下面我们来拆解从基础到高级的几种设计方案。
一、 为什么简单的“定时任务”方案不可行?
在低并发或内部系统中,使用 Spring @Scheduled 注解执行定时任务或许可行。但在大流量场景下,这种方案存在三个致命缺陷:
- 时效性差:轮询存在时间间隔,无法实现秒级精准的取消操作。
- 数据库压力大:将“事件驱动”变为“主动拉取”,频繁的全表扫描是数据库性能的主要瓶颈之一。
- 资源浪费:在多数没有超时订单的时间段,扫描任务仍在空转,消耗系统资源。
因此,高性能方案的核心是避免直接轮询数据库,转而利用高效的中间件来管理延迟任务。
二、 核心架构:三种主流设计方案
方案一:Redis 过期监听(需谨慎使用的“陷阱”)
一些候选人会想到利用 Redis 的 Key 过期事件(Expired Keys Notification)。将订单号存入 Redis 并设置30分钟的过期时间,通过监听过期事件来触发取消逻辑。
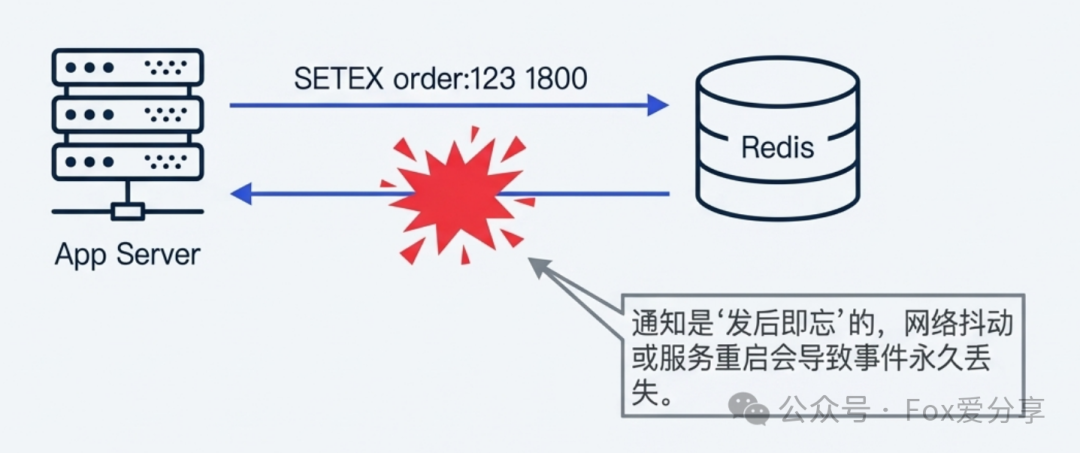
图1:Redis过期事件采用“发后即忘”模式,网络抖动或服务重启可能导致事件丢失。
但这通常是一个面试陷阱,不推荐作为主要方案。原因如下:
- 不可靠:Redis 的过期事件是“发后即忘”(Fire and Forget)的。如果消费者服务在事件触发时重启或发生网络抖动,该事件将永久丢失,导致订单无法取消。
- 延迟不确定:Redis 清理过期 Key 采用惰性删除与定期删除结合的策略,并不保证在 Key 过期的瞬间立即触发事件,可能会有分钟级的延迟。
方案二:Redis ZSet + 轮询(通用且可靠的解法)
这是最被广泛推荐的实践方案,利用 Redis 的有序集合(Sorted Set)来实现一个轻量级延迟队列。
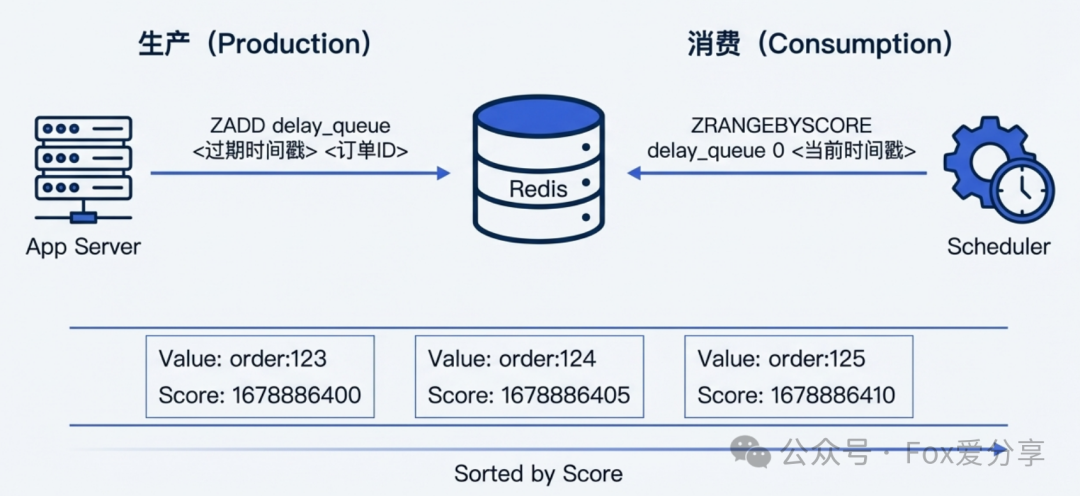
图2:使用Redis ZSet实现延迟队列,Score存储过期时间戳,Value存储订单ID。
- 原理:利用 ZSet 的
Score 来存储订单超时的具体时间戳,Value 存储订单ID。
- 生产消息(下单时):执行命令
ZADD delay_queue <30分钟后的时间戳> <OrderId>。
- 消费消息(后台线程):启动一个后台调度器,每秒执行一次查询。使用
ZRANGEBYSCORE delay_queue 0 <当前时间戳> LIMIT 0 10 获取所有已超时的订单。
- 优点:基于内存操作,性能极高;通过秒级轮询可以保证毫秒到秒级的处理延迟。
⚠️ 高阶防坑:如何保证可靠性?
面试官可能会追问:“如果从Redis取出订单后,业务服务在处理前宕机了,订单数据不就丢了吗?”
满分答案:需要引入 ACK确认机制。具体做法是,使用 Lua 脚本保证原子操作:不是直接删除(ZREM),而是将任务从 delay_queue 原子地移动到另一个 processing_queue(处理中队列)。业务逻辑处理成功后,再从 processing_queue 中删除该任务。同时,需要一个守护进程定期扫描 processing_queue 中滞留时间过长的任务,重新放入 delay_queue 进行重试。这保证了 至少一次(At Least Once) 的消费语义。
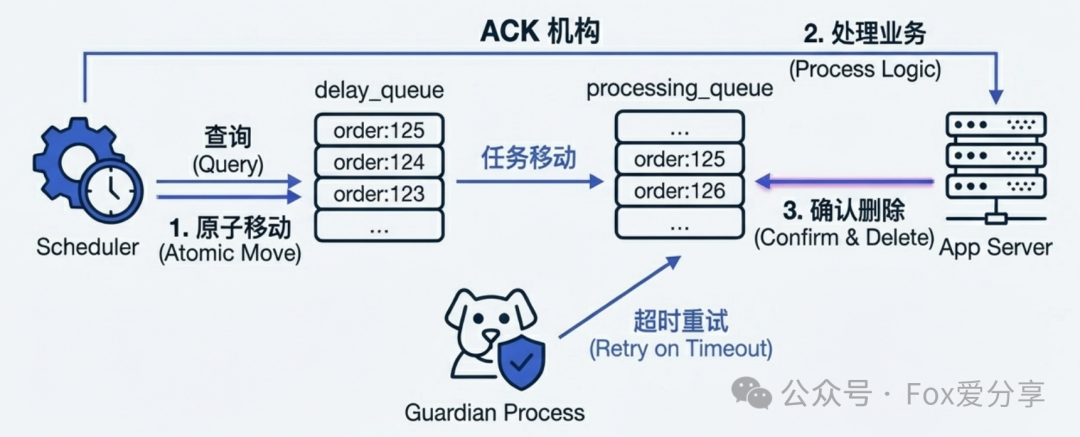
图3:通过ACK机制和待处理队列,确保任务不因处理过程失败而丢失。
对于复杂的分布式系统设计,这种对可靠性和一致性的深入考量至关重要。
方案三:消息队列与时间轮算法(应对亿级流量的架构)
当数据量达到亿级,单一的 Redis ZSet 可能成为大 Key,此时需要考虑更分布式的方案。
A. 消息队列的延迟消息
利用 RocketMQ、RabbitMQ 等消息中间件提供的延迟消息功能。
- RocketMQ:注意 4.x 版本只支持预设的延迟等级(如1s、5s、10s、30m等)。如果面试官问及“任意时长延迟”,需提及 RocketMQ 5.0 已支持任意时长延迟,或说明可用 Redis ZSet 作为补充方案。
- RabbitMQ:通过 TTL+死信队列实现延迟存在“队头阻塞”问题,推荐使用官方插件
rabbitmq_delayed_message_exchange。
B. 时间轮算法 (HashedWheelTimer)
这是 Netty、Kafka 等框架内部使用的高效定时器算法。
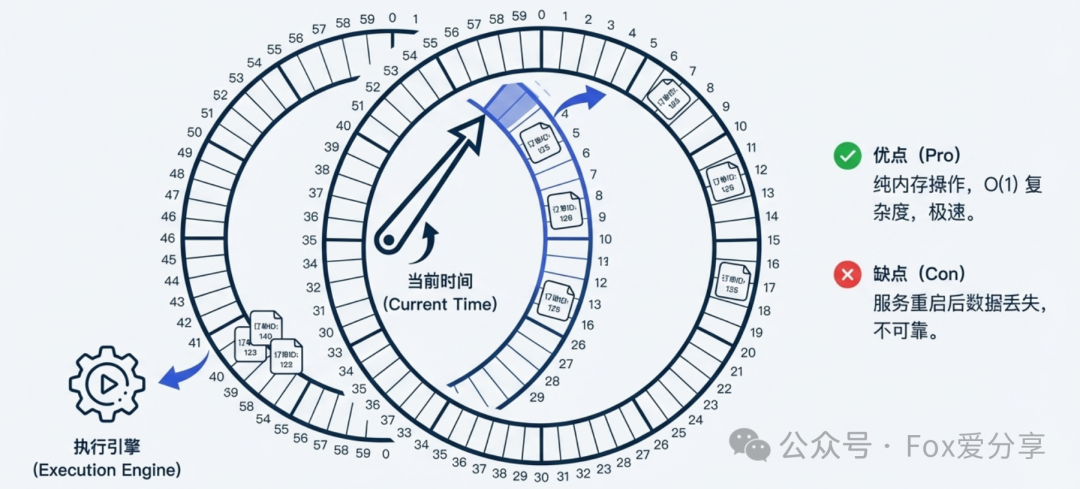
图4:时间轮算法通过一个循环数组模拟时钟,实现O(1)复杂度的任务调度。
- 逻辑:像一个拥有多个格子的钟表,指针按固定频率跳动。一个30分钟后执行的任务,会被放置在“当前指针位置 + 对应刻度”的格子中。
- 优势:纯粹的内存操作,性能极高(O(1)复杂度)。
- 短板:数据存储在内存中,服务重启会丢失。
- 大厂混合实践:通常采用 Redis ZSet 持久化存储 + 内存时间轮热加载。Redis 负责存储所有延迟任务,应用启动时,将近期(例如一小时内)要执行的任务加载到内存时间轮中执行。
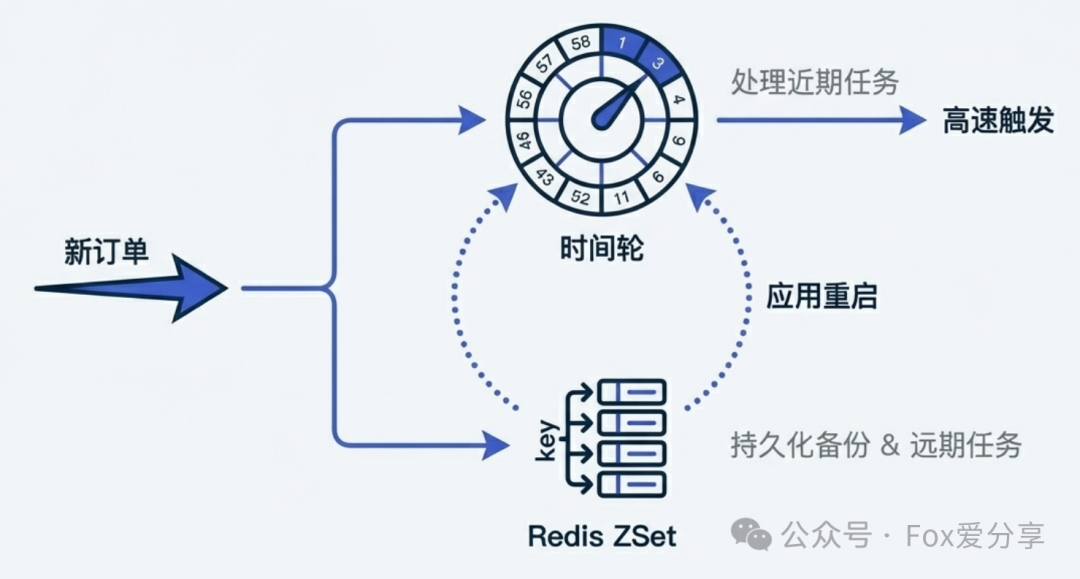
图5:混合架构利用时间轮处理近期高频任务,用Redis持久化远期任务,兼顾性能与可靠性。
三、 高频追问与应对策略
设计完主体架构,准备好应对以下深入提问能让你脱颖而出:
Q1:多节点服务同时轮询同一个ZSet,如何防止订单被重复取消?
答:首先,利用 Lua 脚本 将 ZRANGEBYSCORE(查询)和 ZREM(移除)封装成一个原子操作,确保一个任务只会被一个节点获取到。其次,业务层的订单取消接口必须实现幂等性,即基于订单状态机判断,只有处于“待支付”状态的订单才能被取消,无论接口被调用多少次,结果都一致。
Q2:如果订单量极大,Redis ZSet 形成大Key怎么办?
答:进行 数据分片(Sharding)。不把所有订单放在一个Key里,而是根据订单ID进行哈希取模,分散到多个ZSet中,例如 delay_queue_0 到 delay_queue_9。相应地,启动多个消费线程并行处理,吞吐量可线性提升。
Q3:如果所使用的中间件(如Redis)完全不可用了,如何兜底?
答:任何架构都需考虑兜底方案。可以保留一个低频的离线补偿任务,例如每天凌晨在数据库从库上执行一次扫描,清理那些状态异常(如超过24小时未支付)的订单。这确保了即使在极端情况下,系统也能通过离线手段达到最终一致性。
四、 面试回答模板
总结一下,当被问到此类问题时,可以遵循以下结构进行阐述:
“对于高并发下的订单超时等延迟任务,应避免对数据库进行轮询。我的设计思路是 ‘事件驱动,利用中间件解耦’。
- 架构选型:首选 Redis ZSet 实现延迟队列。下单时,以超时时间戳为Score,订单ID为Value存入ZSet。
- 核心流程:后台调度器每秒使用
ZRANGEBYSCORE 查询已超时的订单,并通过 Lua脚本 原子性地取出并处理。
- 可靠性保障:采用‘处理中队列’实现ACK机制,防止消息丢失;取消订单的业务接口严格保证幂等性,防止重复执行。
- 性能与扩展:数据量极大时,对 Redis ZSet 进行分片;也可评估使用 RocketMQ 5.0 的任意延迟消息功能。
- 兜底策略:设计一个离线的低频扫描任务作为最终保障,确保数据的最终一致性。”
这套组合拳不仅适用于订单超时,同样可以处理优惠券过期、预约提醒、红包退款等多种延迟任务场景。在云栈社区的技术论坛中,你还可以找到更多关于高并发架构和中间件实践的深度讨论。
 发表于 2025-12-31 07:49:14
|
查看: 308|
回复: 0
发表于 2025-12-31 07:49:14
|
查看: 308|
回复: 0
