在使用大型语言模型处理长篇非结构化文本时,你是否也遇到过这些挑战?
- 让模型总结一份临床报告,结果最关键的治疗记录却被遗漏;
- 要求模型从合同中提取所有时间节点,返回的结果却无法追溯到原始出处,并且模型偶尔还会“凭空捏造”不存在的信息,让提取结果的可信度大打折扣;
- 面对上百份技术文档,人工核对提取结果所耗费的时间,甚至超过了直接阅读原文。
在信息爆炸的时代,如何从海量非结构化文本中高效、准确地提取结构化信息,已成为自然语言处理领域的核心需求。为此,谷歌开源了一款名为 LangExtract 的 Python 库,它不仅是一个工具,更是一套面向真实场景的信息抽取解决方案。它无需微调模型,仅需根据用户定义的指令和示例,即可在复杂文档中稳定提取所需信息,并确保每一条结果都能回溯到原文位置。该项目在 GitHub 已收获 19.8K Star。

01 项目介绍
LangExtract 是一个 Python 库,旨在使用大型语言模型从非结构化文本文档中提取结构化信息。它能够处理临床记录、报告等材料,准确识别并整理关键细节,同时确保提取数据与原文严格对应。其核心特性包括:
- 精准的原文定位:每一次提取结果都能映射到原文中的确切位置。
- 可靠的结构化输出:基于用户提供的少量示例,强制执行一致的输出格式。
- 长文档优化:通过优化的文本分块、并行处理和多轮提取,显著提升信息召回率。
- 交互式可视化:生成独立的交互式 HTML 报告,可在原始上下文中可视化审阅数千条已提取的实体信息,便于追溯与验证。
- 兼容多种LLM:既支持云端模型(如 Google Gemini 系列),也支持通过内置 Ollama 接口调用本地开源模型。
- 跨领域适应性强:仅需少量示例即可定义任意领域的提取任务,无需模型微调。
02 使用方法
LangExtract 提供多种安装方式,以适应不同的开发环境和使用场景。
(1) 通过 PyPI 安装
pip install langextract
对于隔离环境,建议使用虚拟环境:
python -m venv langextract_env
source langextract_env/bin/activate # Windows系统:langextract_env\Scripts\activate
pip install langextract
(2)开发环境安装
LangExtract 采用基于 pyproject.toml 的现代 Python 依赖管理方案。使用 -e 参数安装可将包置于开发模式,便于代码修改而无需重新安装。
git clone https://github.com/google/langextract.git
cd langextract
# 基础安装:
pip install -e .
# 开发环境(包含代码检查工具):
pip install -e ".[dev]"
# 测试环境 (包含pytest):
pip install -e ".[test]"
(3)Docker 安装
docker build -t langextract .
docker run --rm -e LANGEXTRACT_API_KEY="your-api-key" langextract python your_script.py
核心使用流程
LangExtract 仅需几行代码即可提取结构化信息。
1. 定义提取任务
首先,创建一个清晰描述提取需求的提示。随后,提供高质量的示例引导模型行为。
import langextract as lx
import textwrap
# 1. 定义提示词和提取规则
prompt = textwrap.dedent("""
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
# 2. 提供一个高质量的示例来指导模型
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"}
),
]
)
]
2. 执行提取
将输入文本和提示材料提供给 lx.extract 函数。
# 待处理的输入文本
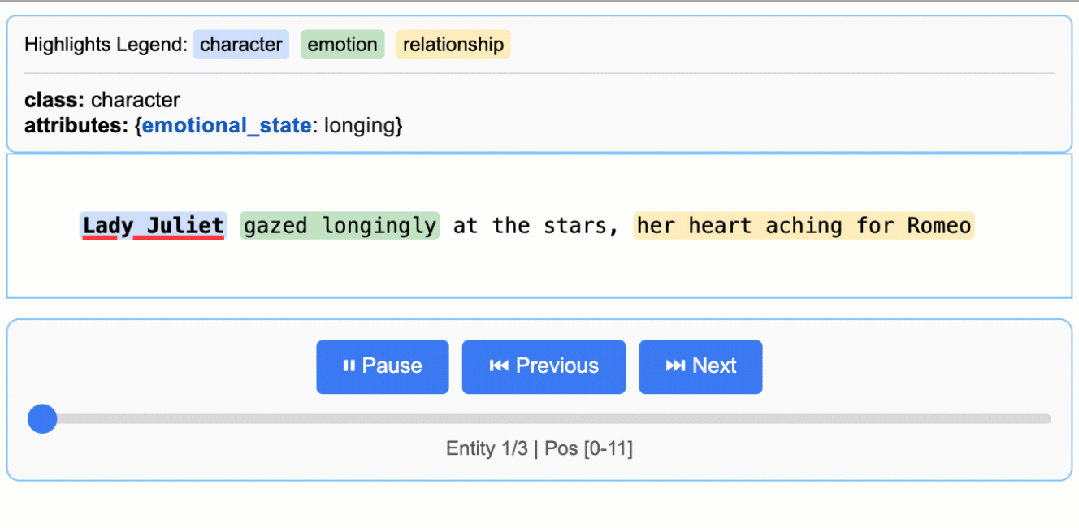
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# 运行提取
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
API密钥配置
使用 LangExtract 调用云端托管模型(如 Gemini 或 OpenAI)时,需配置 API Key。设备端本地模型则无需 API Key。配置方式如下:
选项 1:环境变量
export LANGEXTRACT_API_KEY="your-api-key-here"
选项 2:.env 文件(推荐)
# 将API Key添加到 .env 文件
cat >> .env << 'EOF'
LANGEXTRACT_API_KEY=your-api-key-here
EOF
# 保护API Key安全
echo '.env' >> .gitignore
在 Python 代码中使用时,会自动读取环境变量中的 LANGEXTRACT_API_KEY。
选项 3:直接在代码中传入 API Key(不推荐用于生产环境)
result = lx.extract(
text_or_documents=input_text,
prompt_description="Extract information...",
examples=[...],
model_id="gemini-2.5-flash",
api_key="your-api-key-here" # 仅用于测试/开发
)
支持多种模型后端
使用 OpenAI 模型(需安装可选依赖:pip install langextract[openai]):
import os
import langextract as lx
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o",
api_key=os.environ.get('OPENAI_API_KEY'),
fence_output=True,
use_schema_constraints=False
)
使用 Ollama 进行本地推理,无需 API Key:
import langextract as lx
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemma2:2b",
model_url="http://localhost:11434",
fence_output=False,
use_schema_constraints=False
)
3. 可视化结果
提取结果可保存为 .jsonl 文件。LangExtract 随后可基于该文件生成交互式 HTML 可视化报告,方便在上下文中审阅实体。
# 将结果保存至JSONL文件
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")
# 从文件生成可视化报告
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
if hasattr(html_content, 'data'):
f.write(html_content.data) # 适用于 Jupyter/Colab
else:
f.write(html_content)
此操作将生成一个动态交互式 HTML 文件,可在原始文本中高亮并审阅提取的实体及其属性。
处理长文档与网页内容
对于长文档可直接输入 URL,系统将自动并行处理并提升信息捕捉的灵敏度。
# 直接从 Project Gutenberg 处理《罗密欧与朱丽叶》
result = lx.extract(
text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3, # 通过多轮处理提升召回率
max_workers=20, # 并行处理以加速
max_char_buffer=1000 # 更小的上下文窗口提升准确性
)
这种方法可以在保持高准确率的情况下,从完整小说中提取数百个实体。
03 总结
在处理长篇非结构化文本时,LLMs 常面临关键信息遗漏、结果难以溯源、大模型幻觉导致提取信息与原文不符以及人工核验成本高等核心痛点。针对这些问题,谷歌开源的 Python 工具库 LangExtract 提供了一站式的信息抽取解决方案。
LangExtract 无需微调模型,仅需用户通过自然语言指令和少量示例,即可从临床报告、合同、技术文档等复杂文本中精准提取结构化信息。其对缓解大模型幻觉问题的核心价值尤为突出:一方面,每一条抽取结果都能精确映射回原文的具体位置,强制要求提取内容与原文严格对应,从底层逻辑上杜绝了模型凭空生成无依据信息;另一方面,通过文本分块、多轮提取的优化策略,以及交互式可视化核验功能,进一步校验提取结果的真实性,大幅降低幻觉内容的留存概率,真正实现了“提取有依据、结果可验证”。
探索更多 AI 与数据处理领域的精彩内容与开源项目,欢迎访问 云栈社区 。
 发表于 2026-1-3 04:30:29
|
查看: 293|
回复: 0
发表于 2026-1-3 04:30:29
|
查看: 293|
回复: 0
