本文将从YOLOv8与YOLOv5模型对比的角度,详细阐述两者在网络架构设计上的异同点,帮助大家对YOLOv8的模型结构建立起全面且深入的理解。
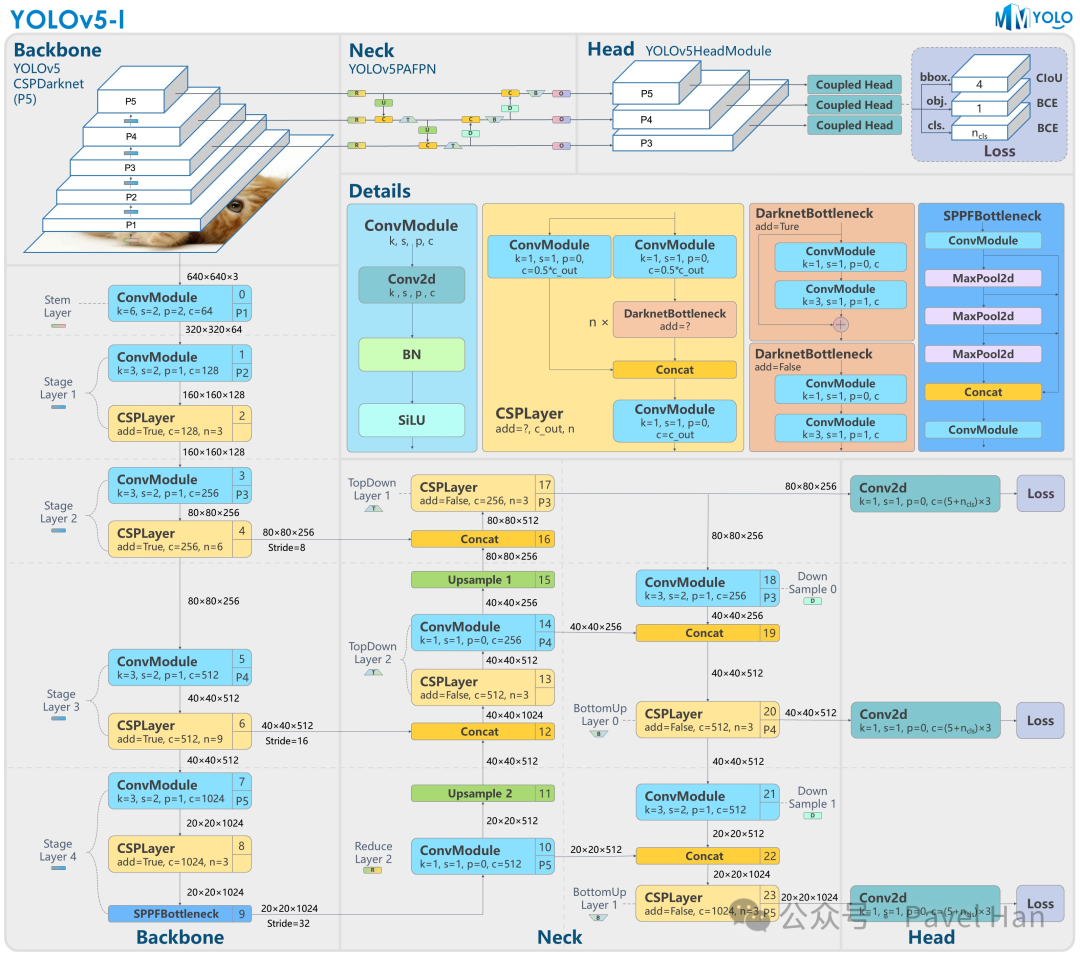
以下是YOLOv5模型的总体架构图:
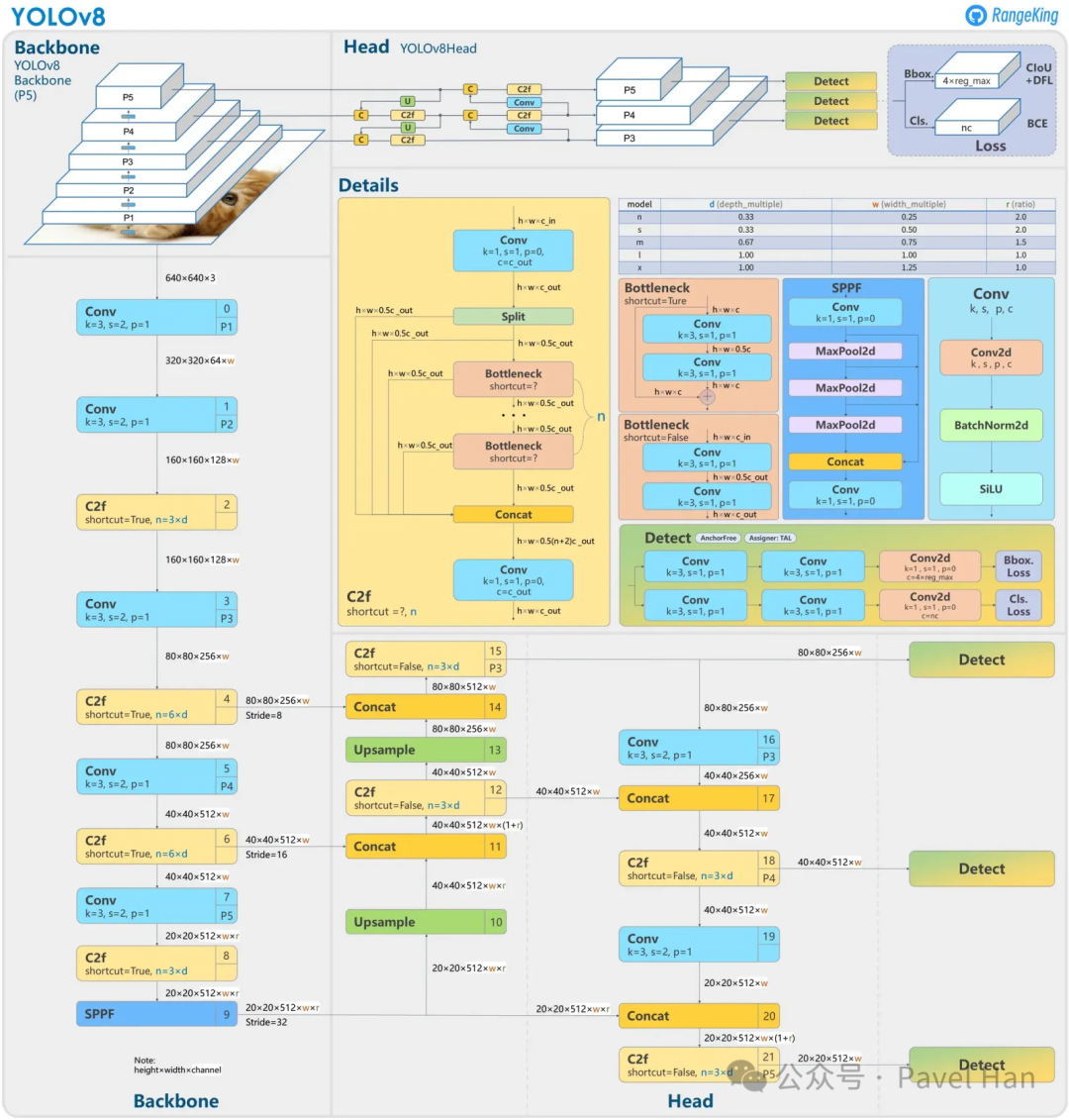
以下是YOLOv8模型的整体网络架构图:
主干网络
对比以上YOLOv5和YOLOv8架构图左侧的主干网络(BackBone)部分,可以直观地发现,YOLOv8与YOLOv5主干网络的整体骨架非常相似。它们的主要区别集中在以下两点:
- 在P1层:YOLOv5使用FOCUS模块(老版本)或一个6x6、步长为2的卷积层(新版本)来实现输入图像从640x640x3到320x320x64特征图的初始下采样;而YOLOv8则采用了与主干网络中其他降维模块一致的设计,使用一个3x3、步长为2的卷积层来完成分辨率降低,最终得到的同样是320x320x64的特征图。
- YOLOv8使用C2f模块替换了YOLOv5模型中的CSPLayer模块(即C3模块)。C2f模块是YOLOv8架构中的核心创新点之一。
C2f模块
如前所述,C2f模块是YOLOv8主干网络设计的最大亮点。首先,我们通过结构图对比YOLOv5的C3模块与YOLOv8的C2f模块:
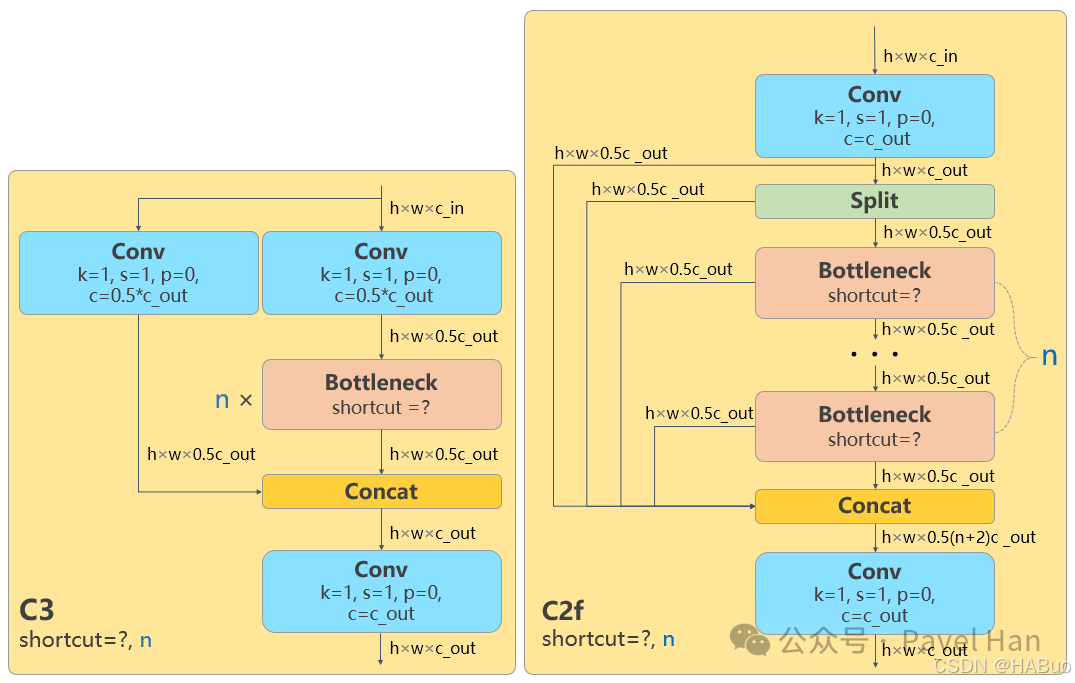
可以看到,C3模块采用的是双分支并行结构,它将输入的特征图分为两部分,分别交由主分支和旁路分支处理:
- 主分支:通过1×1卷积降维后,经过多个Bottleneck残差模块(残差模块数量可通过
depth_multiple参数设置)进行特征提取。
- 旁路分支:直接通过1×1卷积处理,以保留原始的特征信息。
- 特征融合:最后将两个分支的输出在通道维度直接拼接,再通过一个1×1卷积进行融合后输出。
而C2f模块则采用了多阶段串联结构,设计上更为精巧:
- 初始处理:输入的特征图首先统一通过一个1×1卷积,生成中间特征图。
- 特征拆分:将中间特征图拆分为两部分,一部分特征通过多个Bottleneck模块进行串联处理,另一部分则直接传递到末端。
- 多阶段处理:后续连续的多个Bottleneck残差模块,每个模块的输出都会被分成两部分:一部分继续流入下游的残差模块进行处理,另一部分则直接传递到末端等待合并。
- 多尺度融合:最后,将所有处理阶段的特征图(包括直接传递的部分)拼接在一起,再通过一个1×1卷积进行融合。
对比两者的结构,C2f相比C3最大的优势在于:它通过拼接内部残差模块输出的多阶段特征图,融合了包含中间处理阶段在内的、不同深度的特征信息,使得特征表达更为丰富。此外,更多的跨层连接形成了更丰富的梯度流路径,这有助于在训练过程中让梯度信息更有效地反向传播,缓解深层网络的梯度消失问题,从而提升训练稳定性和收敛速度。
需要强调的是,无论是C3模块还是C2f模块,其输入和输出特征图的维度都是相同的。
与YOLOv5模型类似,YOLOv8同样在8倍、16倍以及32倍下采样这三个尺度上,分别输出三路不同分辨率的特征信息给颈部网络,维度分别为80x80x256,40x40x512,20x20x512(作为对比,YOLOv5默认的最小分辨率特征输出维度为20x20x1024)。
颈部网络
在颈部网络(Neck)方面,两者的差异不大。YOLOv8在YOLOv5新版本的基础上做了一些简化,但整体结构基本一致:都采用了PANet的结构,通过自顶向下(Top-down)和自底向上(Bottom-up)的路径聚合,增强了主干网络输出的三种不同尺度特征之间的信息流动,最终将充分融合后的特征信息输出到检测头部分。
YOLOv8相比YOLOv5在颈部网络上的改进主要是:
- 简化了网络结构,去除了上采样(UpSample)路径中的两个卷积块。
- 与主干网络保持一致,在颈部网络中也使用C2f模块替换掉了C3模块。
经过颈部网络对三种尺度特征的多轮融合处理后,YOLOv8模型最终会输出三路特征给检测头部分,维度同样是:80x80x256,40x40x512,20x20x512。
检测头
相比于主干网络和颈部网络的渐进式改进,YOLOv8模型在检测头(Head)部分相比YOLOv5做出了更为革命性的改变,主要体现在解耦头(Decoupled Head) 和 Anchor-Free机制 这两个方面。
在YOLOv5的检测头设计中,采用了耦合头(Coupled Head) 结构,即针对目标分类的任务和针对边界框回归的任务共享同一组卷积层,仅在最后的输出通道上分离,分别预测类别和坐标。而YOLOv8则采用解耦头设计,将分类和回归任务完全分离为两个独立的网络分支:
- 分类分支:专门负责目标类别判断,使用独立的卷积层处理特征。
- 回归分支:专注于边界框位置预测,通过专门的卷积层输出坐标信息。
这种设计避免了两个任务在训练过程中因目标不同而产生的相互干扰。两者的对比如下:
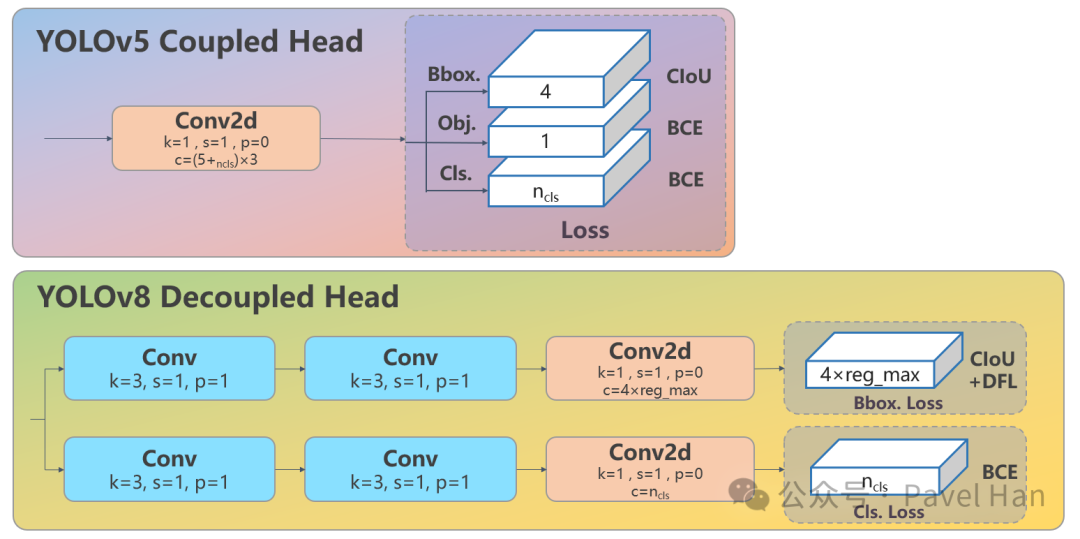
从上图可见,在YOLOv8的解耦检测头设计中,分类分支和回归分支各自包含两个独立的3x3、步长为1的卷积模块,最后再通过一个1x1卷积按各自所需的输出维度进行降维。
以COCO数据集为例,模型对单张图片进行推理时,检测头部分的最终输出数据维度为 [1, 8400, 144]。
- 1:表示batch size,处理单张图片时为1。
- 8400:表示从颈部网络送入检测头的三种不同尺度特征图上所有网格点的总和,即80x80 + 40x40 + 20x20 = 8400。每个网格点将输出一个一维张量,代表该处的检测结果。
- 144:可以拆分为两部分:
- 类别判断部分(80维):对应COCO数据集的80个类别。分数越高,表示该网格点检测到的物体属于该类别的可能性越大。
- 边界框位置部分(64维):这64维的长度与YOLOv8检测头的Anchor-Free机制紧密相关。
从YOLOv2开始,YOLO系列长期使用基于预定义锚框(Anchor)的预测机制。而YOLOv8转向了 Anchor-Free 的设计,不再依赖从数据集聚类得出的预设长宽比来辅助定位。这一转变的实现,核心依赖于 DFL(Distribution Focal Loss) 机制。
DFL机制可以这样理解:在预测框回归分支的输出中,每个网格点包含一个由该网格预测的物体边界框的坐标位置。以当前网格中心点在原图(640x640)中的坐标 (x, y) 为基准,目标框的位置由四个偏移量 l(左)、t(上)、r(右)、b(下)来计算。最终预测框的左上角坐标为 (x - l, y - t),右下角坐标为 (x + r, y + b)。l, t, r, b 这四个偏移量中的每一个,都用一个16维的向量来表示,四个偏移量合计就是64维——这正是回归分支为每个网格输出的数据。
例如,对于P3层(下采样步长stride=8)的特征输出,若某个锚点网格索引为 (10, 20),则该网格中心点在原图中的坐标即为 ((10+0.5)×8, (20+0.5)×8) = (84, 164)。P4和P5层的计算同理,只需将stride分别替换为16和32。
那么,这表示每个偏移量的16维向量具体如何用于计算呢? 这涉及两个关键参数:
reg_max:通常设置为16,表示将偏移量的可能距离范围(从0到最大距离)均匀划分为16个区间(或称“bins”)。stride:特征层的下采样步长(P3=8,P4=16,P5=32)。
以P3层(stride=8)为例解释计算逻辑。其能支持的最大偏移量为 16 × 8 = 128 像素。这128像素的范围被按8像素的间隔划分为16段:
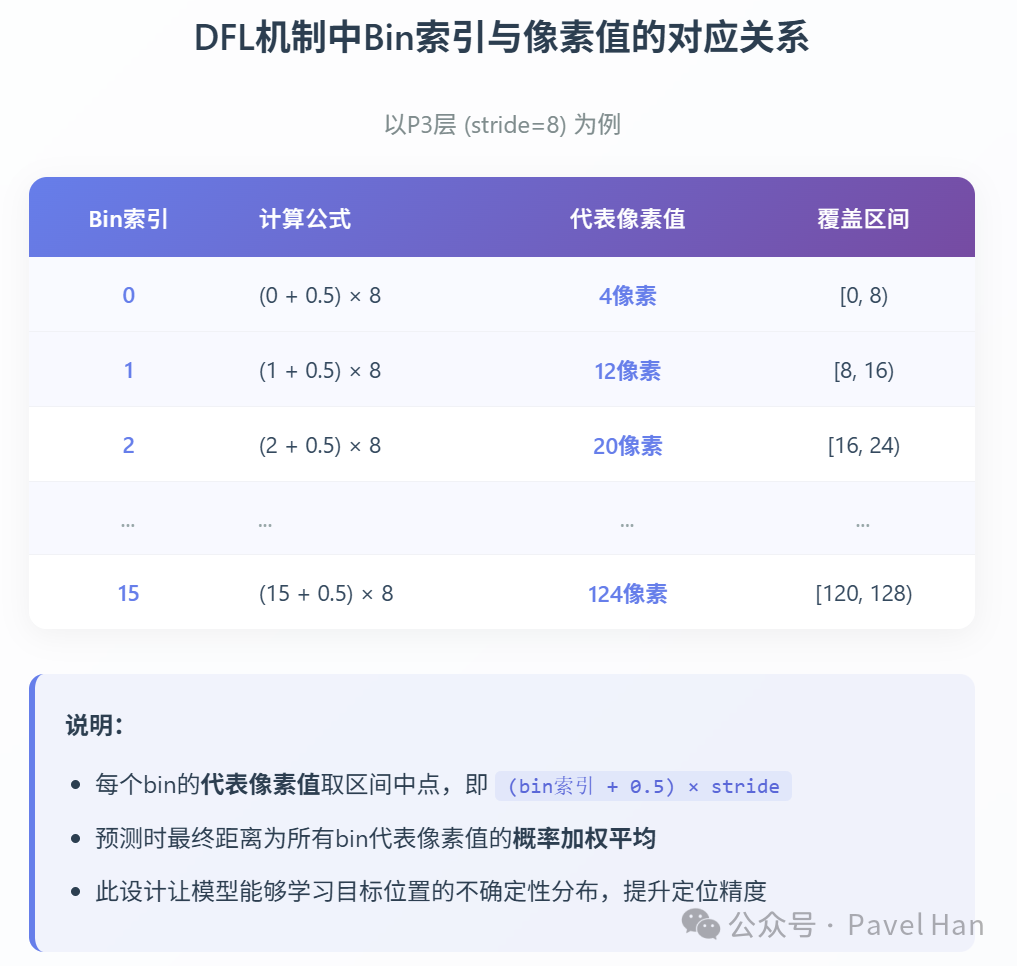
预测框回归分支为每个偏移量输出的16维向量,代表了实际偏移量落在这16个区间内每一个区间的概率。最终计算出的实际偏移量,并不是取概率最大的那个区间中心值,而是这16个概率值与16个区间中心点的加权平均值。以下是偏移量的计算逻辑流程:
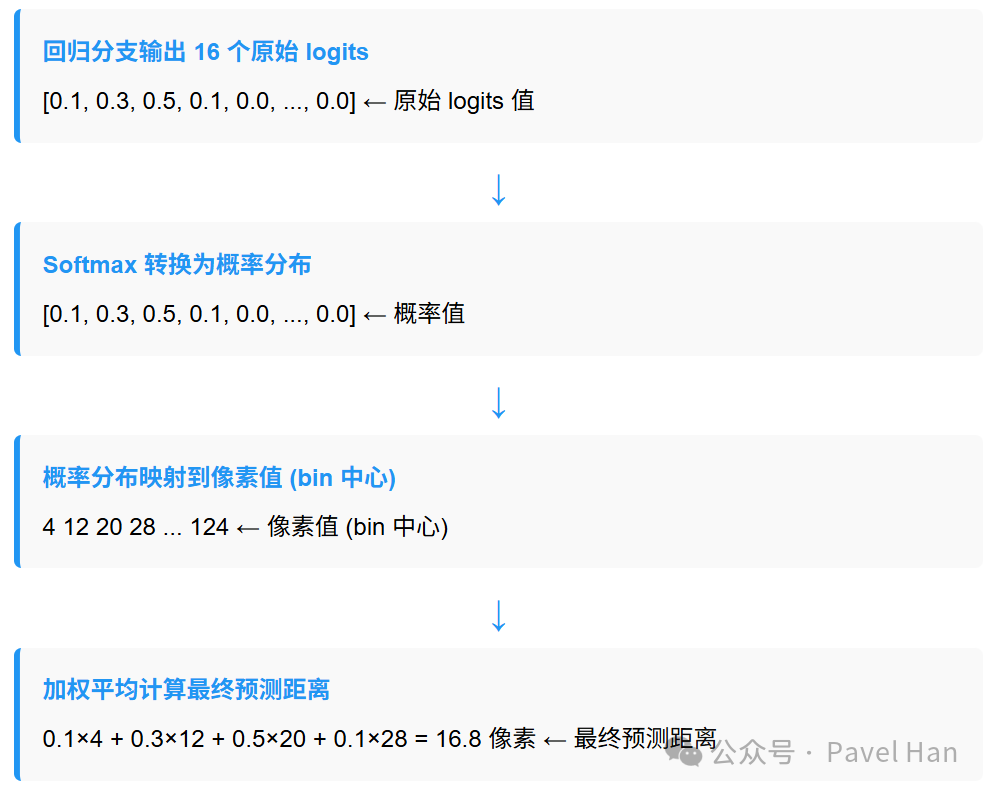
按照以上逻辑,即可计算出 l, t, r, b 四个精确的偏移量。结合锚点网格的中心坐标,就能得到该网格预测的物体边界框的精确坐标。
对于P4和P5层的特征输出,偏移量的概率输出与计算逻辑完全相同,唯一的区别是stride值分别变为16和32。
至此,YOLOv8模型从检测头部分输出了8400个预测框信息。这些预测框后续还需经过NMS(非极大值抑制)等后处理算法的过滤,才会作为模型的最终检测结果输出。
通过以上梳理,我们彻底搞清了YOLOv8检测头的解耦输出逻辑:对于P3、P4、P5三路不同尺度的特征,在检测头处解耦为分类和回归两个独立分支。针对COCO数据集,分类分支每个网格输出80维的类别概率;回归分支则用64维向量编码预测框的坐标。因此,每个网格的总输出维度是144。
还有一个关键问题:目标检测的置信度(Objectness Score)信息在哪里?
答案是,YOLOv8没有独立的置信度预测分支。它将目标存在的置信度信息隐含在了类别预测信息中。具体而言,每个网格锚点最终的目标检测置信度,就是其类别预测分支输出的80维张量中的最大值,即模型认为该处物体属于“可能性最大那个类别”的概率,直接作为该锚点存在目标的置信度。
参考资料
- 【YOLOv8】YOLOv8结构解读-腾讯云开发者社区-腾讯云
- What is YOLOv8? A Complete Guide
- YOLOv8 原理和实现全解析 — MMYOLO 0.6.0 文档
本文由云栈社区编辑整理,旨在深度解析前沿技术架构。
 发表于 2026-1-3 07:49:11
|
查看: 625|
回复: 0
发表于 2026-1-3 07:49:11
|
查看: 625|
回复: 0
