TL;DR
看到新闻中Groq被NVIDIA收购估值达200亿美元时,不少人误以为是模型参数规模。实际上这是对AI基础设施价值的一次重大重估。从Mellanox 60亿到如今Groq 200亿,背后反映的是推理市场正在经历结构性变革。本文将深入剖析Groq的技术架构、确定性设计哲学及其在AI计算中的独特优势,并探讨其对行业格局的影响。
1. Background
1.1 训推一体的故事变了么?
传统AI部署模式中,训练使用最新GPU,推理则采用前代产品,暗含训推比例接近1:1的假设。然而随着Blackwell发布,其推理性能显著提升,部分用户已直接用于推理场景。
同时,AWS Re:invent数据显示:
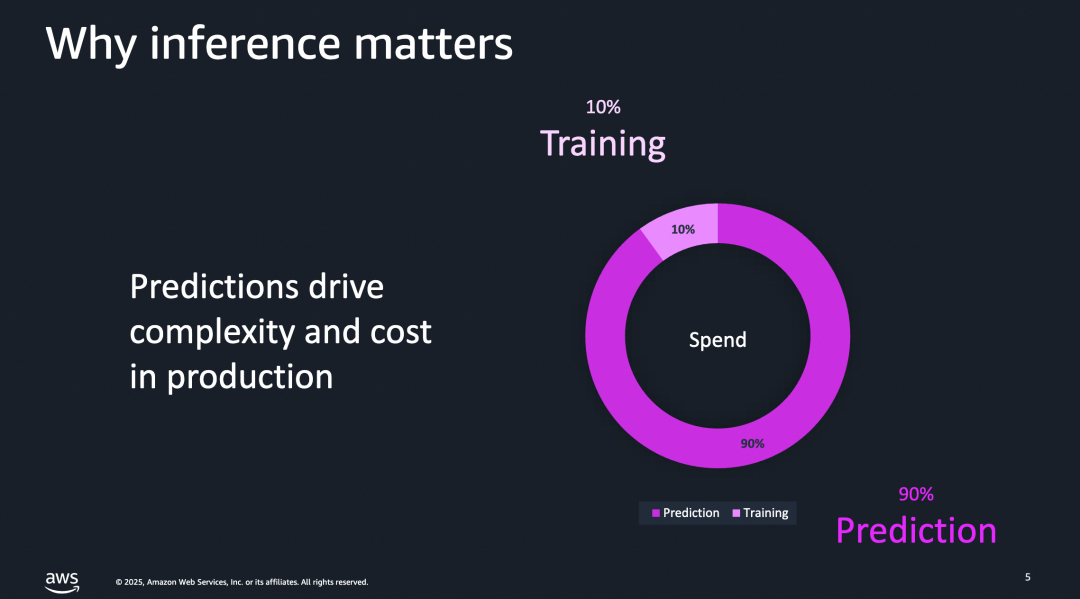
这引发了一个关键问题:NVIDIA收购Groq是否意味着技术路线将走向“训推分池”?即训练维持GPGPU架构,而推理平台转向异构化?Rubin CPX可能是第一步,Groq则是更深层次的战略布局。
1.2 从业务模式上分析
从AI可扩展性角度看,强化学习后训练、推理模型与智能代理(Agent)的发展正大幅拉高推理平台的需求占比。
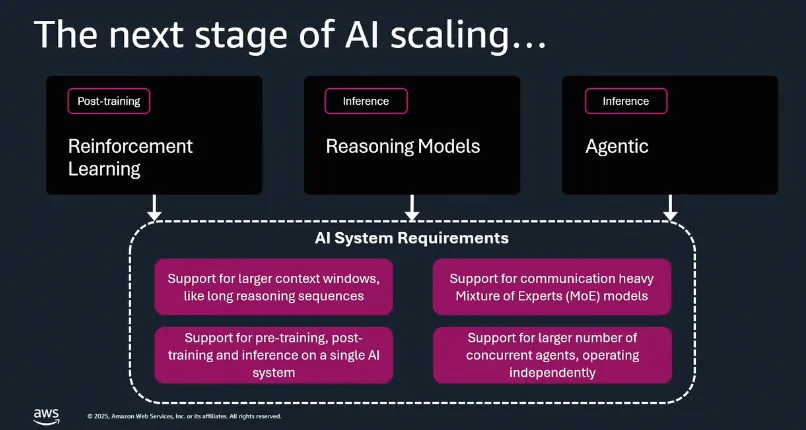
当训推比达到1:10以上时,独立部署专用推理集群变得经济可行,这也为Groq创造了市场机会。此外,来自Google TPU和AWS Trainium的竞争压力加剧,据称TPU ROI比Blackwell高出约30%,且AWS计划开源其编译器。
尽管NVIDIA拥有稳定的HBM供应,但竞争对手受限于产能。近期有消息称:“Google因HBM供应紧张解雇采购高管”,凸显了供应链的重要性。
1.3 从技术路线来看
当前体系结构优化主要集中在四个方向:
- 提高并行性
- 降低数值精度
- 改善数据局部性(Data Locality)
- 使用领域特定语言(DSL)
对于DSA(专用加速器)与GPGPU而言,核心差异在于数据局部性管理和内存子系统设计。DSA通常配备大容量SRAM,由编译器精细控制;而GPGPU依赖多级缓存层次结构,编程复杂度较高。
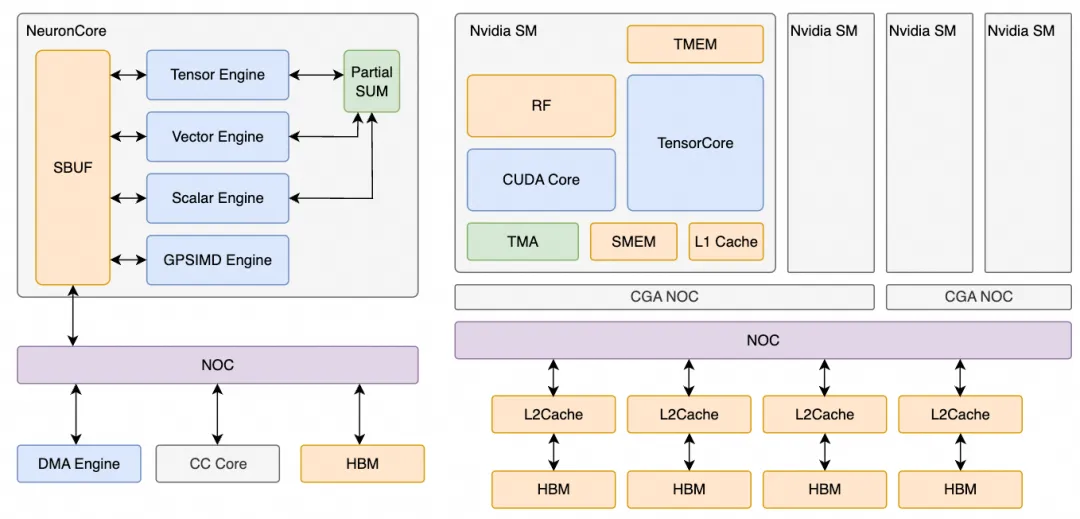
尽管Tile-Based DSL(如cutlass-dsl、cuda-tile)试图简化内存管理,但对于极致性能追求者来说,手动调优仍不可或缺。因此,内存系统的底层设计成为区分两类架构的关键。
2. Groq Arch Overview
Groq在ISCA 2022发表论文《A Software-defined Tensor Streaming Multiprocessor for Large-scale Machine Learning》[1],并在HotChips 34详细介绍了其架构设计理念。
2.1 什么是Software Defined?
Groq强调“软件定义张量流处理器”(Software-defined Tensor Streaming Processor)。这一概念并非简单软硬协同,而是重新划分软硬件边界。
问题背景与动机
- Strong Scaling:关注延迟,“更快解决问题”
- Weak Scaling:关注吞吐,“同时解决更多问题”
现代机器学习需兼顾两者,但传统架构存在不确定性(non-determinism),源于:
- 动态指令调度
- 缓存命中波动
- 网络拥塞导致延迟变化
- 内存仲裁竞争
这些因素使精确并行协调困难,只能通过昂贵同步机制等待,造成资源浪费。
解决方案:确定性扩展
Groq的核心思想是将单个TSP芯片的确定性扩展至数千节点系统,两大支柱:
- 软件调度Dragonfly网络:编译时规划通信路径与时序
- 运行时去偏斜(runtime deskew):校正时钟漂移,维持全局同步
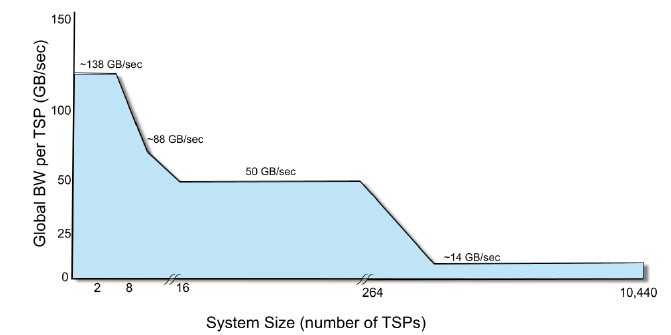
该图揭示了不同封装层级间的带宽衰减规律,指导编译器优先在本地完成高通信量任务。
软硬件接口重构
Groq提出两种关键接口:
-
静态-动态接口
将决策前移至编译时,运行时仅执行预设蓝图。
-
软硬件接口
向编译器暴露底层状态,使其能精确推理:
- 张量在SRAM中的物理地址
- 数据在功能单元间流动的路径与时间
- 每个FU的流水线延迟
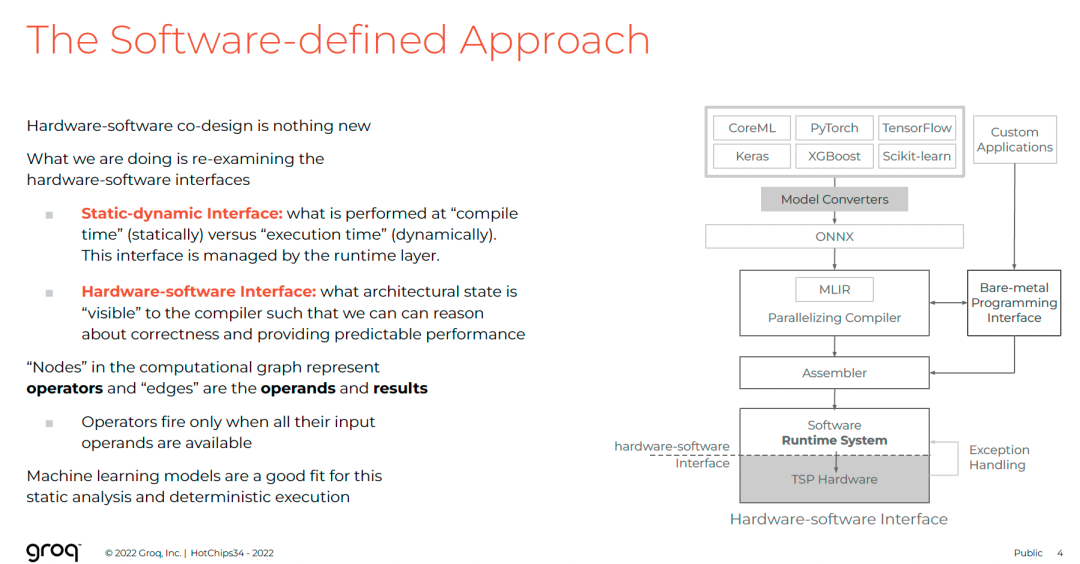
这种设计让编译器成为“全知全能”的调度者,确保“正确的时间遇到正确的数据”。
注:类似理念可见于《现代NVIDIA GPU架构》中Stall计数器与依赖掩码的设计,但Groq将其推向极致。
整个系统由大量TSP互联构成,全局内存逻辑共享、物理分布,每TSP贡献220 MiB,总容量可达2TB以上,端到端延迟低于3微秒。
2.2 确定性设计
Groq白皮书《Determinism and the Tensor Streaming Processor》[4]系统阐述了其确定性哲学。
定义与目标
确定性指性能完全可预测、可重复。工作负载执行时间在编译时即可精确知晓,无任何波动。
核心理念:移除反应式组件
传统架构依赖动态机制处理资源争用,引入不确定性。Groq移除以下组件:
- 硬件级控制流逻辑
- 硬件互锁(interlocks)
- 仲裁器(arbiters)
- 重放机制(replay mechanisms)
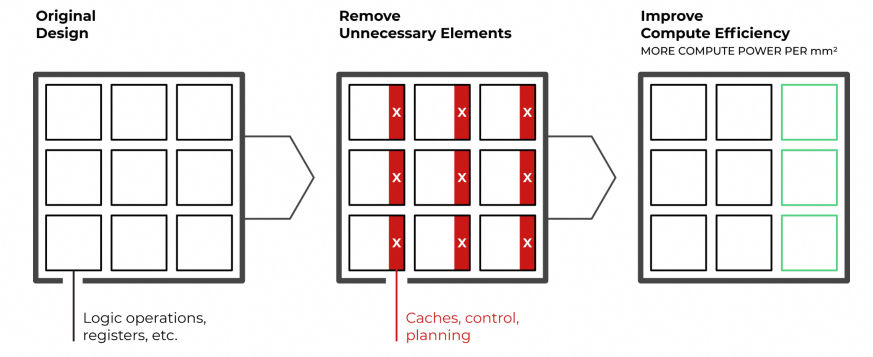
编译器在编译阶段完成所有操作规划,硬件变为纯粹执行者。
直接优势
- 简化硬件设计:释放面积用于更多计算单元
- 消除长尾延迟:无动态事件与资源争用
- 精确功耗预测:支持TCO优化
| 特性 |
Groq TSP |
传统架构 |
| 调度方式 |
静态调度(编译时规划) |
动态调度(运行时决定) |
| 核心组件 |
执行单元 + 内存,无动态控制 |
包含缓存、乱序引擎等反应式组件 |
| 性能可变性 |
零方差 |
高方差(受缓存、分支预测影响) |
| 长尾延迟 |
不存在 |
普遍存在 |
| 编译器角色 |
核心决策者(全周期规划) |
辅助角色(依赖硬件动态优化) |
| 调试分析 |
简单(编译时生成报告) |
复杂(需动态profiling) |
四大优势
-
易设计与调试
行为可重复,一次调试永久有效;无需担心“吵闹邻居”。
-
可预测性
控制权移交软件栈,启动即知完成时间。
-
服务质量(QoS)
延迟、吞吐、结果一致性均有保障,适用于集成模型或多输入系统。
-
总体拥有成本(TCO)
可控功耗,避免电源过度配置;减少开发猜测,加速上市。
思考:Groq本质是VLIW思想在AI加速器上的极致应用。但静态调度面临挑战:对动态模型(如MoE、变长序列)适应性差;编译耗时可能影响研发敏捷性;通用性弱于GPU。

“将硬件构建成高效的编译器目标”——这是Groq设计的核心信条。所有选择服从“为确定性而设计”的哲学:
- 清晰内存一致性模型(禁止重排序)
- 移除所有“反应式组件”
- 暴露架构状态给软件
编译器掌握每个张量的确切位置,通过生产者-消费者流编程模型实现精准编排。
2.2.1 芯片层面的确定性
传统CPU/GPU通过缓存隐藏DRAM访问延迟,但带来非确定性和能效问题。

Groq解决方案:
- 使用大容量单级暂存SRAM(Scratchpad),固定延迟
- 显式分配张量时空位置,解锁大规模内存并发
2.2.2 系统层面的确定性
超算与数据中心面临:
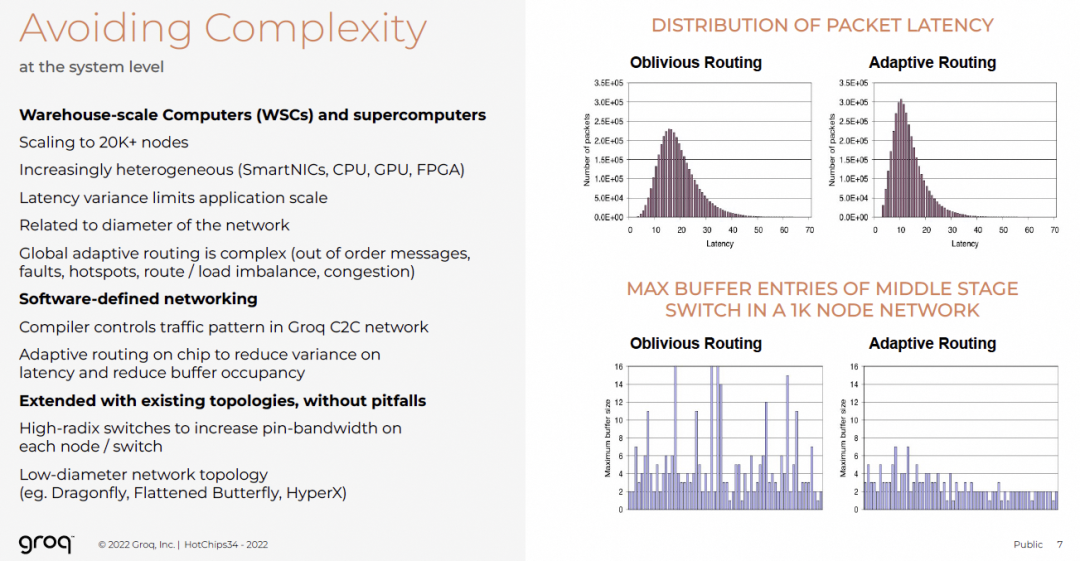
Groq采用软件定义网络(SDN):
- 编译器控制C2C网络流量模式
- 芯片内自适应路由降低延迟方差
- 高基数交换机+低直径拓扑(Dragonfly)
反思:Groq的绝对确定性是否走向极端?值得持续观察。
3. Groq TSP架构
3.1 TSP微架构
传统多核架构中,每个PE包含完整五级流水线与独立缓存。
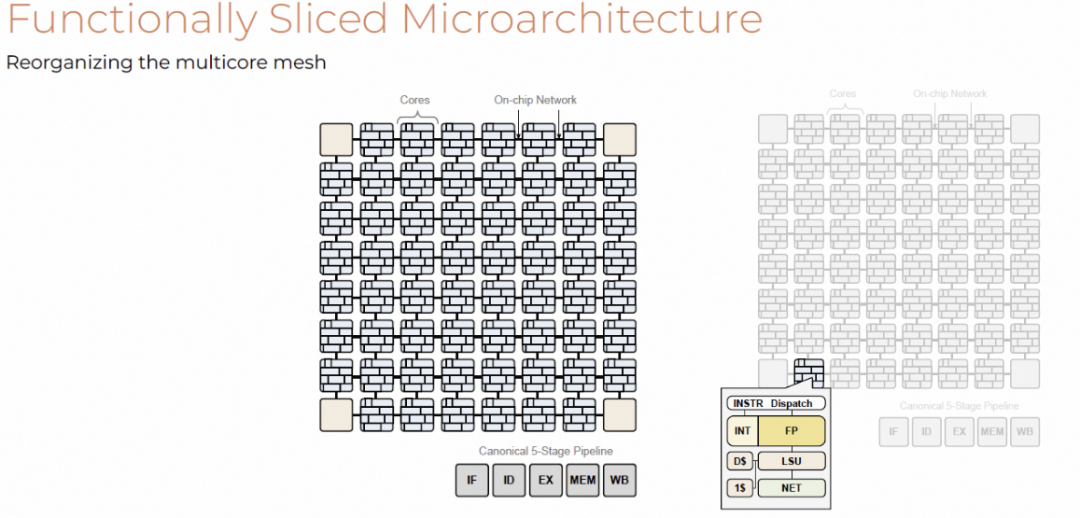
Groq重组为功能切片微架构:
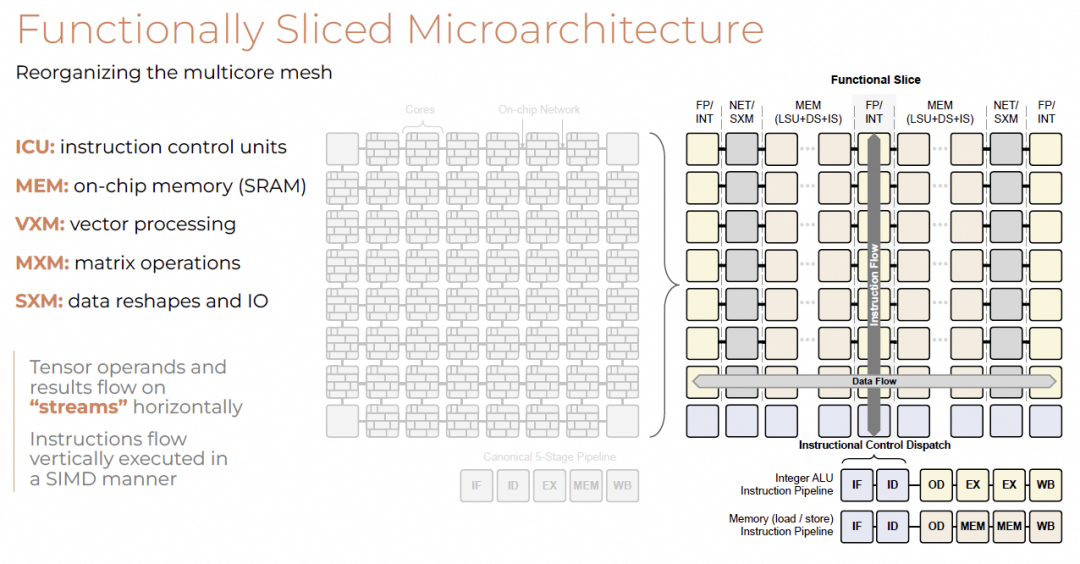
- 分离ICU(指令控制单元)与功能单元
- 功能切片包括FP/INT、NET/SXM、MEM等
- 指令垂直广播,数据水平流动
整体架构如下:

- SRAM:80 TB/s带宽,stride insensitive
- MXM:4×矩阵引擎,支持320×320点积
- VXM:5,120向量ALU
- 网络:480 GB/s带宽,支持多种拓扑
- 数据交换:支持shift、transpose、permute
- 指令控制:多队列支持指令并行
芯片布局呈双半球结构:

- 144个ICU,每列控制一个功能“列”
- SIMD基本单位为320元素向量

MXM为320×320,VXM/SXM/MEM均对齐320 lanes。

VXM每lane含16 PE,总计5,120 PE,支持高密度计算。
TSP设计实现 >1 TOPS/mm²,远超GPU能效密度。
3.2 软件抽象
Groq软件抽象 = SIMD + Spatial Arch + Streaming
SIMD
所有指令对齐320 lanes,lockstep执行。
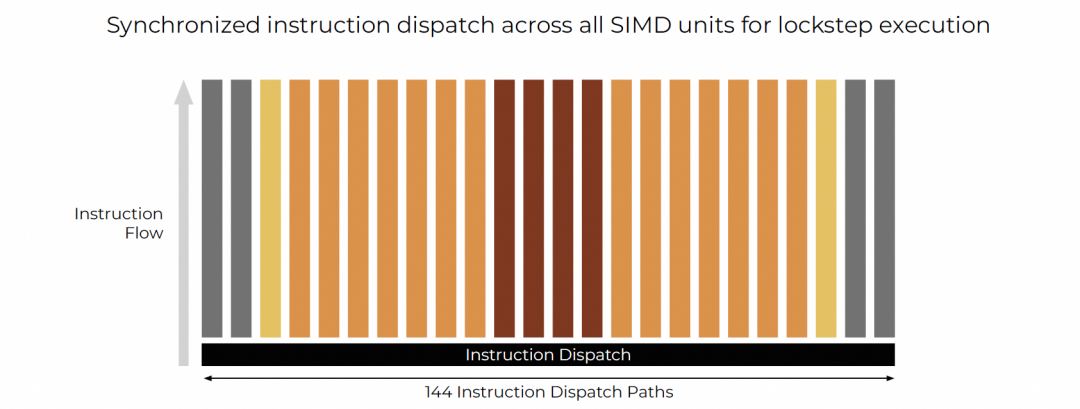
宏观上看,TSP相当于144路宽VLIW处理器,每周期发射144条子指令。
Streaming
数据作为“流”在FU间连续传递,形成生产者-消费者流水线。
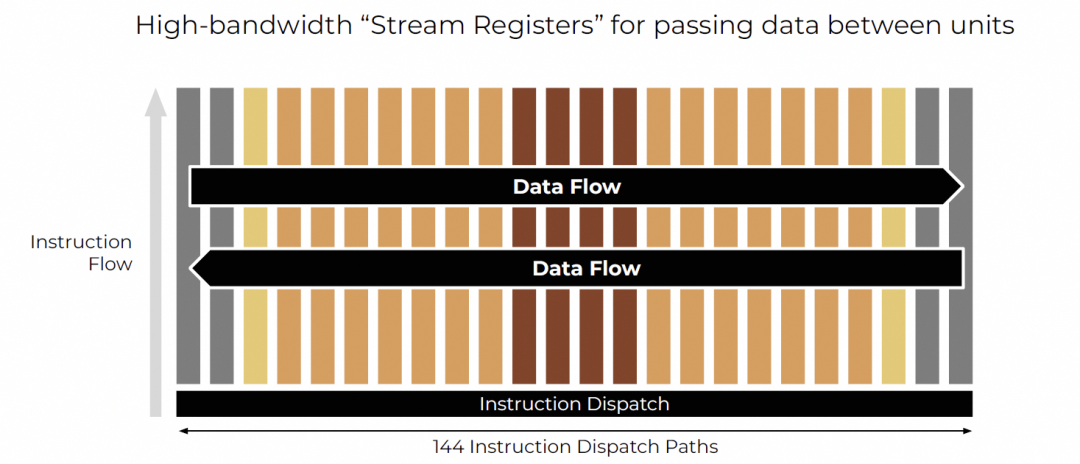
结合空间架构与SIMD,实现高效流水。
软件控制内存
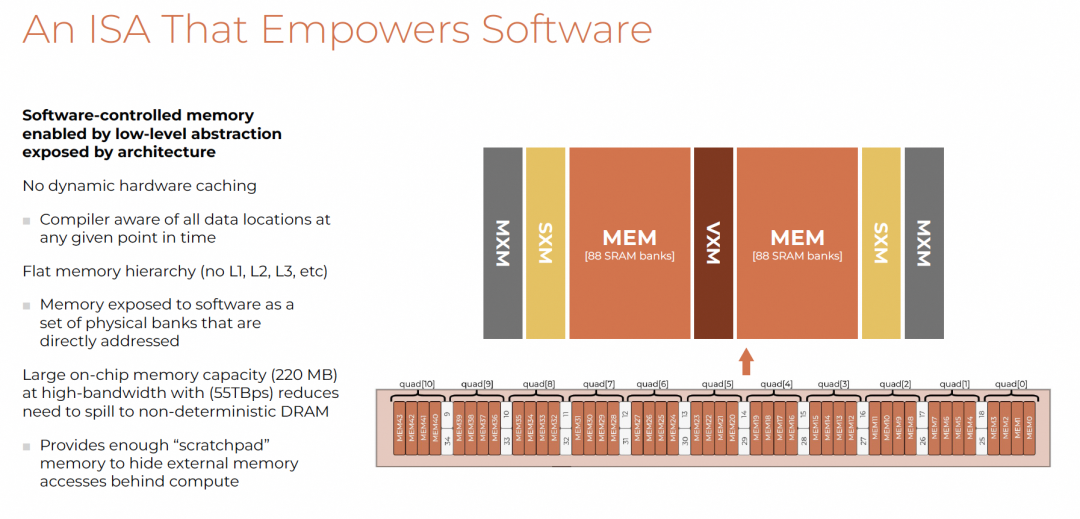
- 无动态缓存,扁平内存层次
- 220 MB片上SRAM,55 TBps带宽
- 直接寻址物理bank,暴露给软件
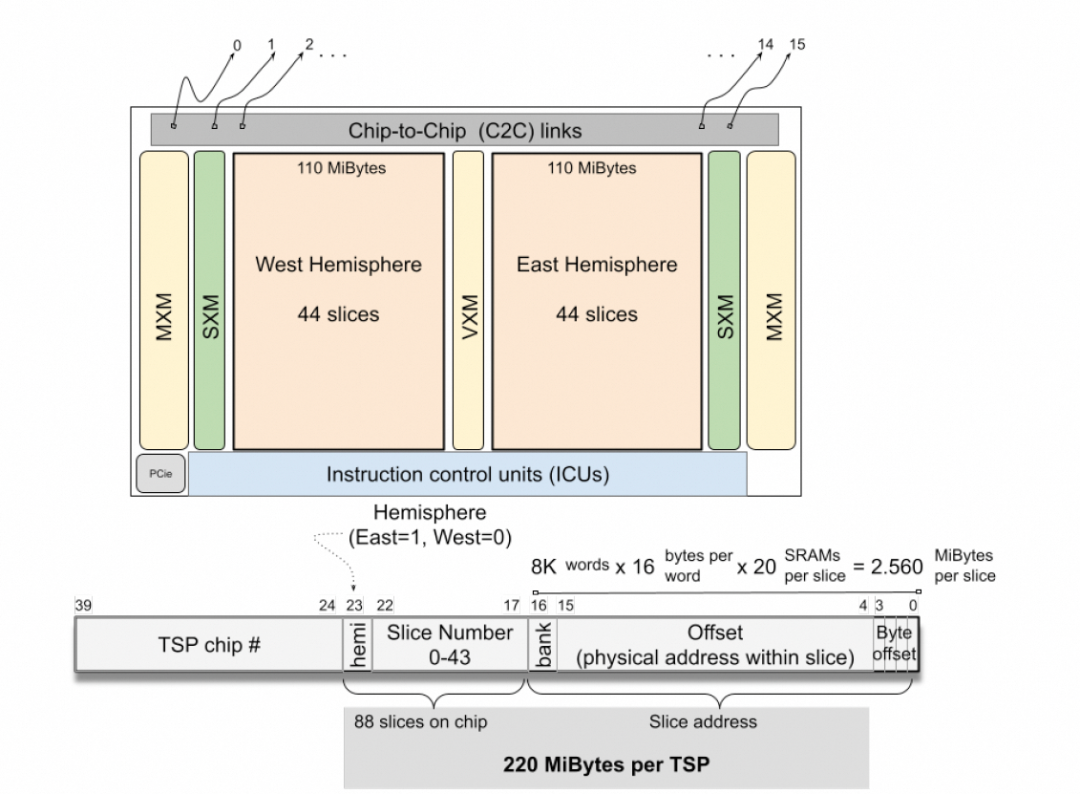
统一编址方式:
编译器具备cycle级调度能力,所有FU lockstep执行,144条分发路径每周期一指令。

硬件控制逻辑面积开销 <3%,>97%面积用于计算与存储。
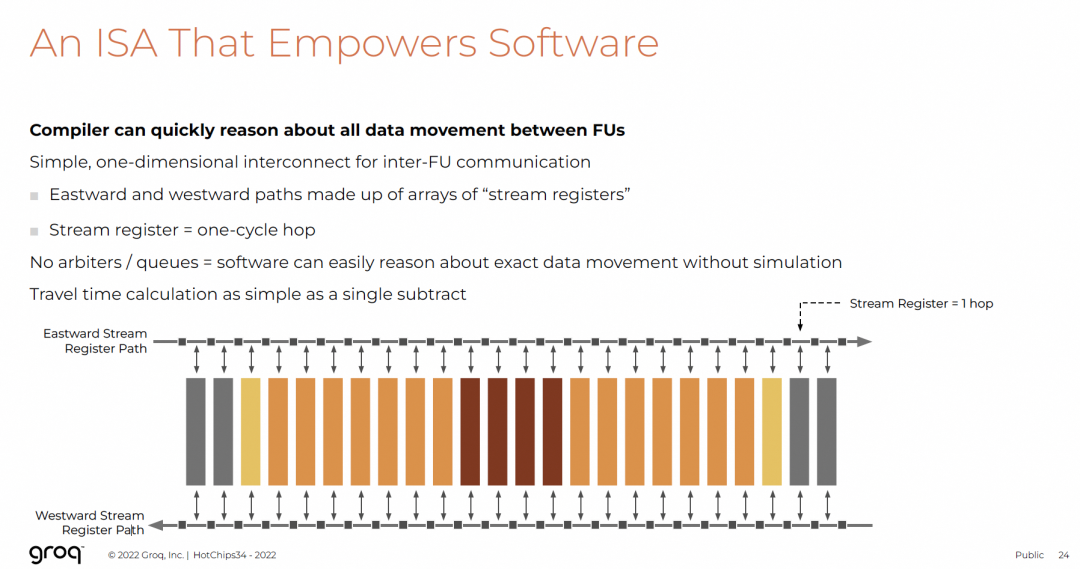
东西向流寄存器路径,延迟固定为1 cycle,无仲裁/队列,便于编译器推理。
3.3 ISA
指令集设计原则:显式、低级控制,320B位宽向量/矩阵操作。
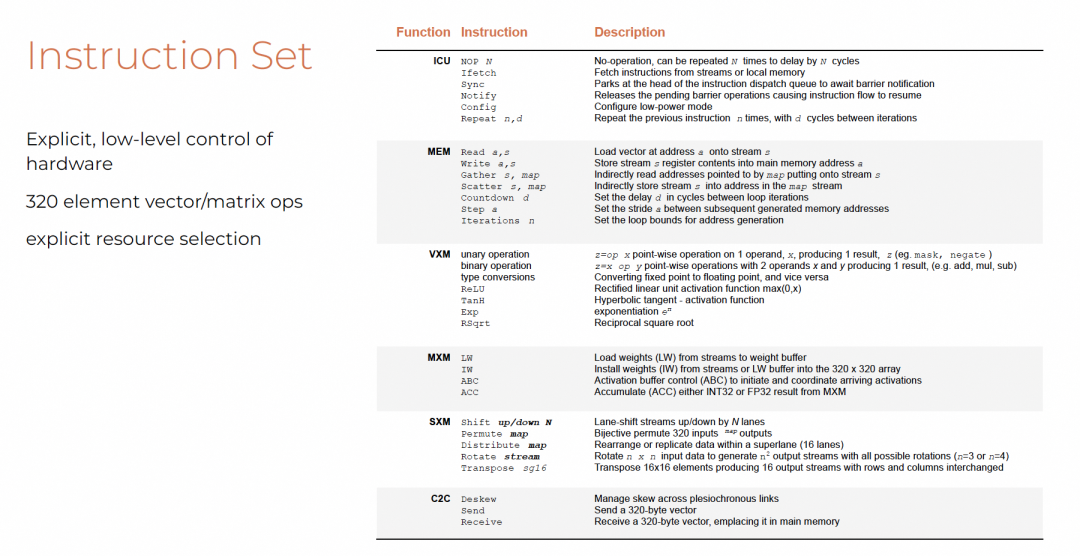
兼具RISC与CISC特点:
- RISC-like:多数指令功能单一、格式规整
- CISC-like:Repeat、Permute、Gather/Scatter等复合指令提升效率
无传统条件分支,因面向静态计算图。
每个FU有专属指令子集,但共享控制流指令:
IFETCH:取指开始执行NOP:填充空闲周期保持同步SYNC:屏障等待NOTIFY:唤醒等待线程
类似Hopper MBarrier机制,但更简洁。
各功能单元职责分离,类似NVIDIA Warp Specialization理念。
3.4 MXM
4个MXM分布于芯片东西两侧,位于VXM与SXM之间。

支持int8与float16输入,结果为int32或float32。
指令集:
LW:加载权重至缓冲区IW:部署权重至阵列ABC:激活值缓冲区控制ACC:累加控制
流程清晰:加载 → 部署 → 计算 → 累加。
3.5 VXM
提供灵活可编程计算能力。
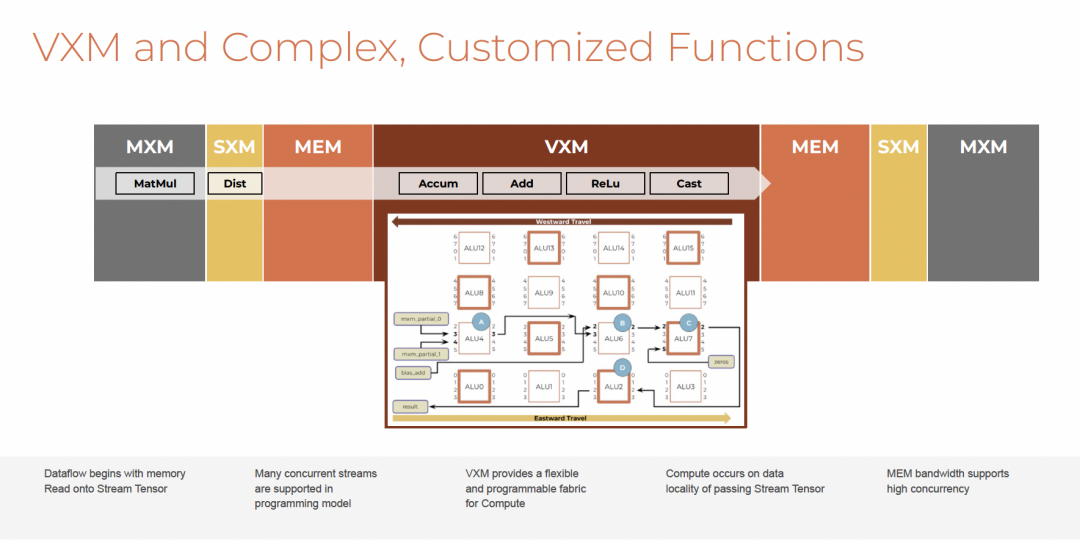
支持element-wise操作:
- 加减乘除、逻辑运算
- Exp/TanH/RSqrt等超越函数
- 类型转换(cast)、ReLU激活
- 基于mask的选择操作
3.6 SXM
SXM(Switch Execution Module)专司数据移动。
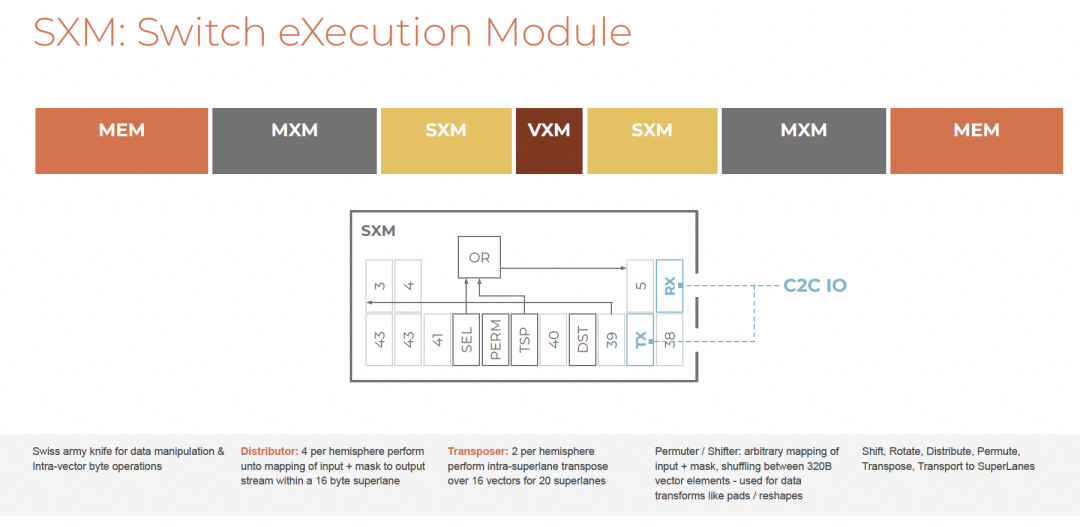
功能包括:
- Distributor:输入→输出流映射
- Transposer:superlane内转置
- Permuter/Shifter:任意元素重排
是数据重塑的“瑞士军刀”。
3.7 MEM
MEM由东西两半球组成,每半球44个独立bank,共88 slices。
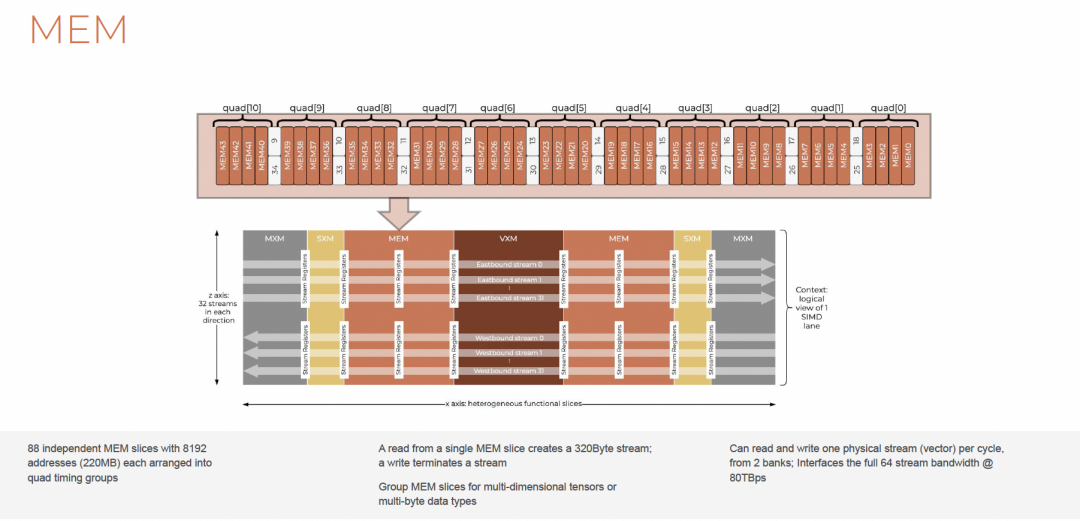
- Read:生产者,创建320B流
- Write:消费者,终止流生命周期
- 支持Gather/Scatter非连续访问
- 配合Countdown/Step/Iterations构成硬件地址生成器
4. 系统架构
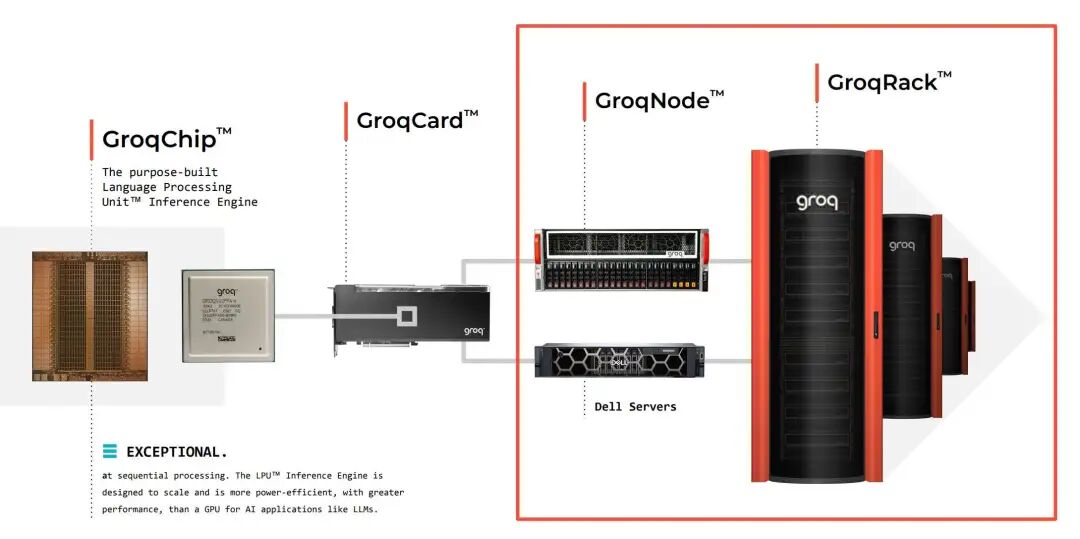
- 单卡:1 GroqChip
- 单节点:8 GroqCard
- 单机柜:9 GroqNode(72卡)
- 多机柜组成云服务
4.1 ScaleOut的拓扑选择
目标:
- 低网络直径
- 直接网络(无外部交换机)
- 层次化封装感知
采用Dragonfly拓扑,构建虚拟高基数路由器。
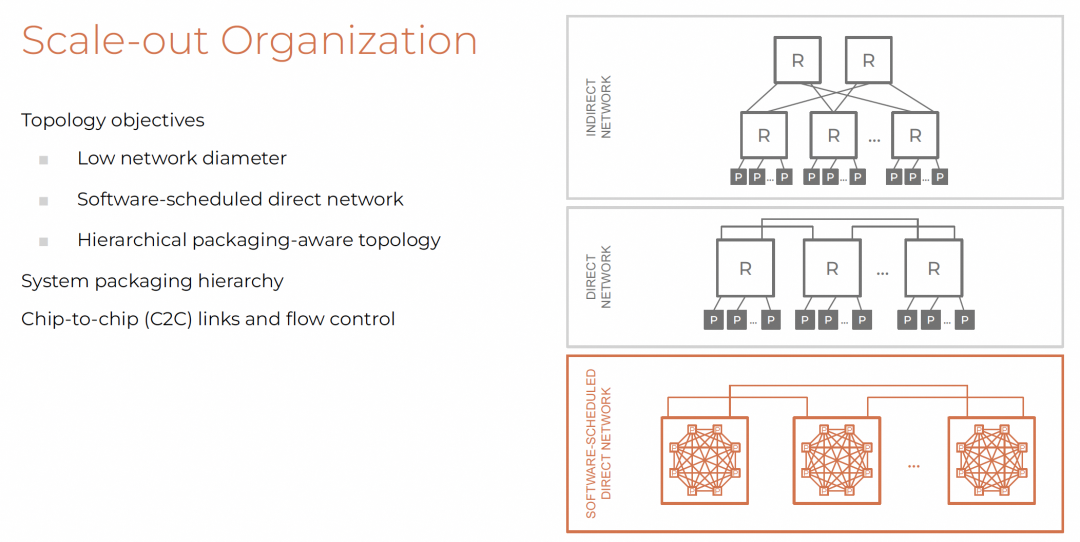
4.2 系统层次化封装
- 每TSP:7 Local Ports(节点内),4 Global Ports(跨节点)
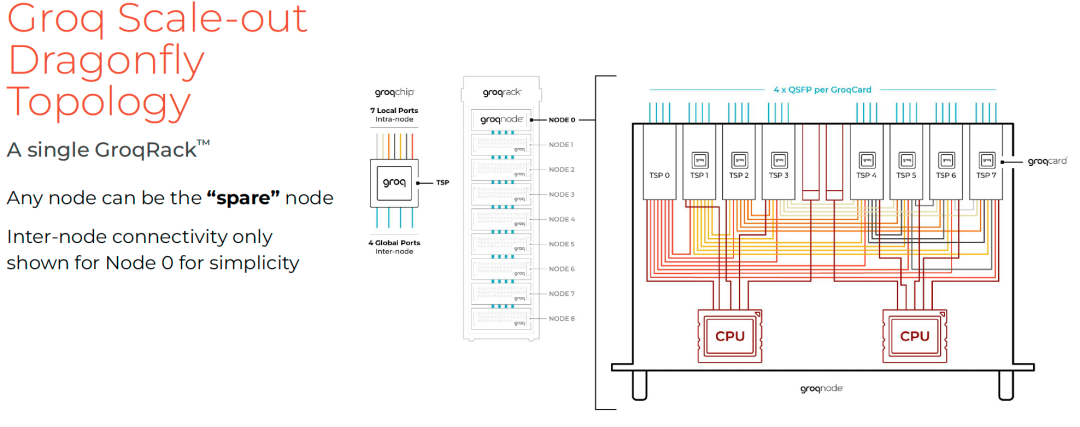
节点内全连接,背板线缆整齐布线:

跨节点通过QSFP连接,构成Dragonfly组。
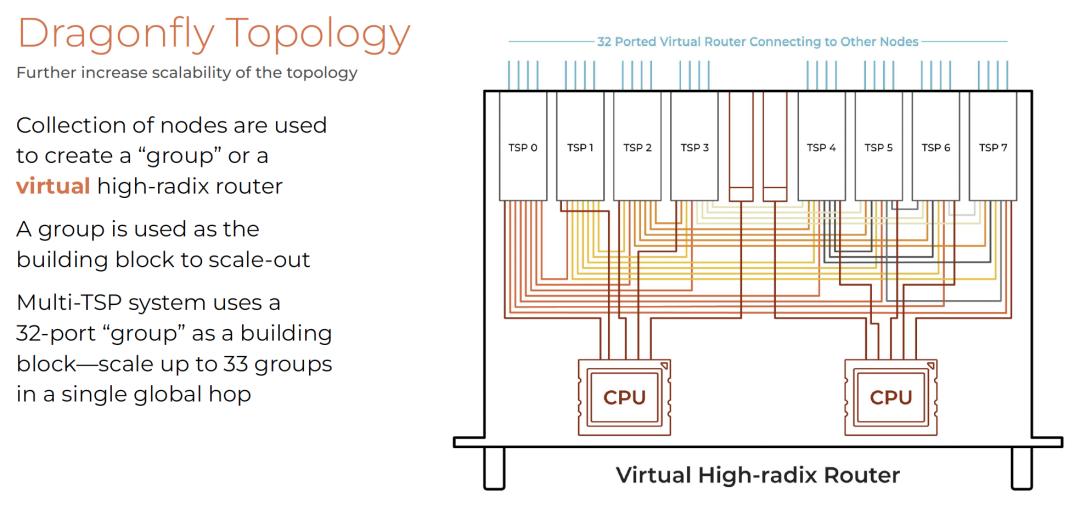
最大支持10,440 TSP,网络直径5跳。
4.3 芯片间的链路和流控
介质选择:
- 节点内:<0.75m,AWG-34细铜缆
- 机柜内:<2m,QSFP DAC
- 机柜间:AOC光缆
禁用反压机制以维持确定性。
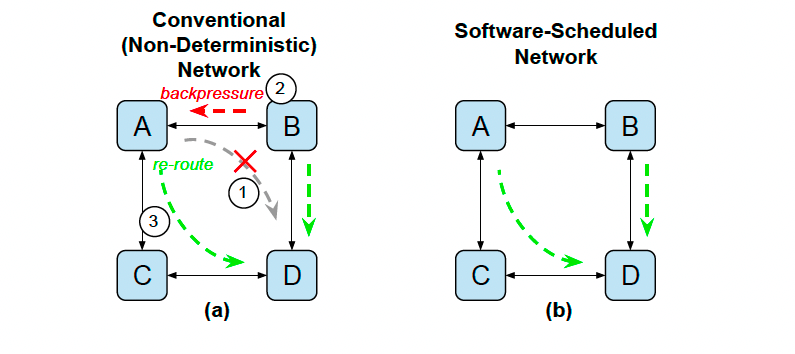
使用本地SRAM作为中间缓冲,配合Virtual Cut-Through转发,降低多跳延迟。
5. 在分布式系统中维持确定性
5.1 Overview
挑战:
需软硬件协同解决。

三大机制:
- HAC(硬件对齐计数器)
- 初始程序对齐
- 运行时去歪斜重同步
5.2 HAC
每个TSP维护自由运行的HAC(<256周期溢出)。
通过双向传输测量链路延迟:
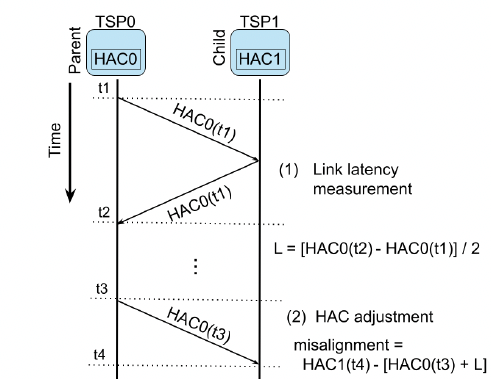
建立生成树传播参考时间。
5.3 初始程序对齐
利用DESKEW指令对齐HAC epoch边界,再通过TRANSMIT触发同步启动。
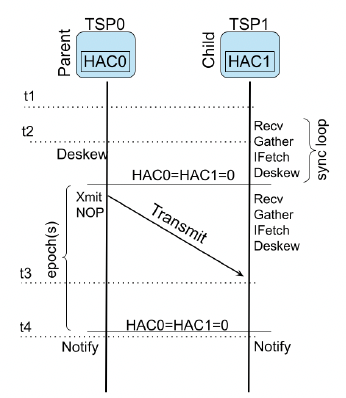
总开销为 $O(d \cdot h)$,仅发生在推理开始阶段。
5.4 运行时去歪斜以实现重同步
引入SAC(软件对齐计数器)跟踪本地与全局时间偏差。
RUNTIME_DESKEW t 指令暂停 $t \pm \Delta$ 周期,重新对齐。
期间其他ICU通过SYNC静默,待NOTIFY恢复。
6. 软件调度的网络(SSN)
6.1 流量模式先验已知
基于静态计算图,编译时已知通信模式。
支持模型/数据并行自动划分。
6.2 调度, 而非路由
传统路由依赖硬件查表,SSN由编译器显式调度逐跳路径。
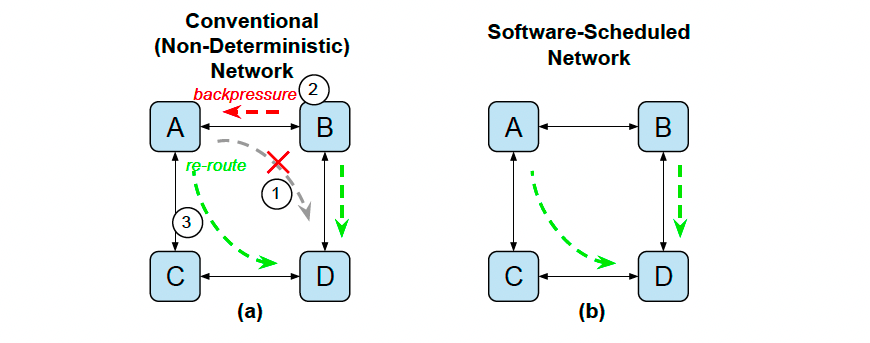
避免拥塞与反压,实现确定性通信。
还可消除请求-响应往返,直接推送数据。
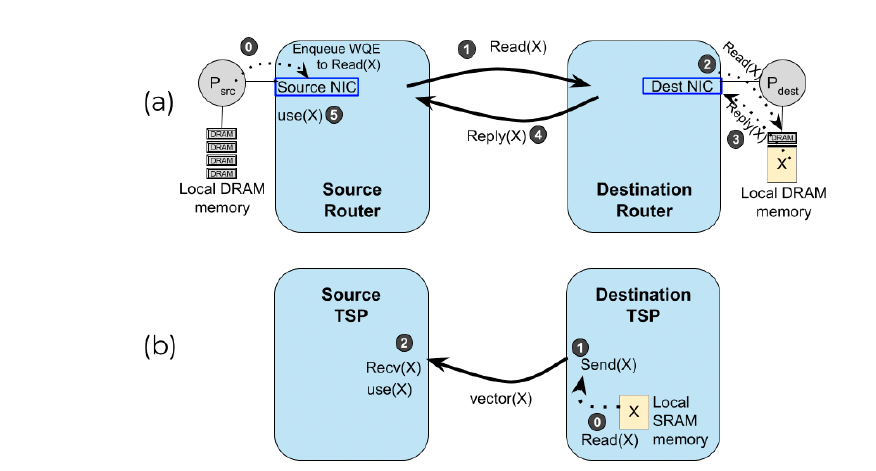
6.3 确定性负载均衡
Dragonfly高路径多样性需智能路由。
但自适应路由易引发幻象拥塞等问题。
Groq采用确定性分散流量至多条路径,实现负载均衡。
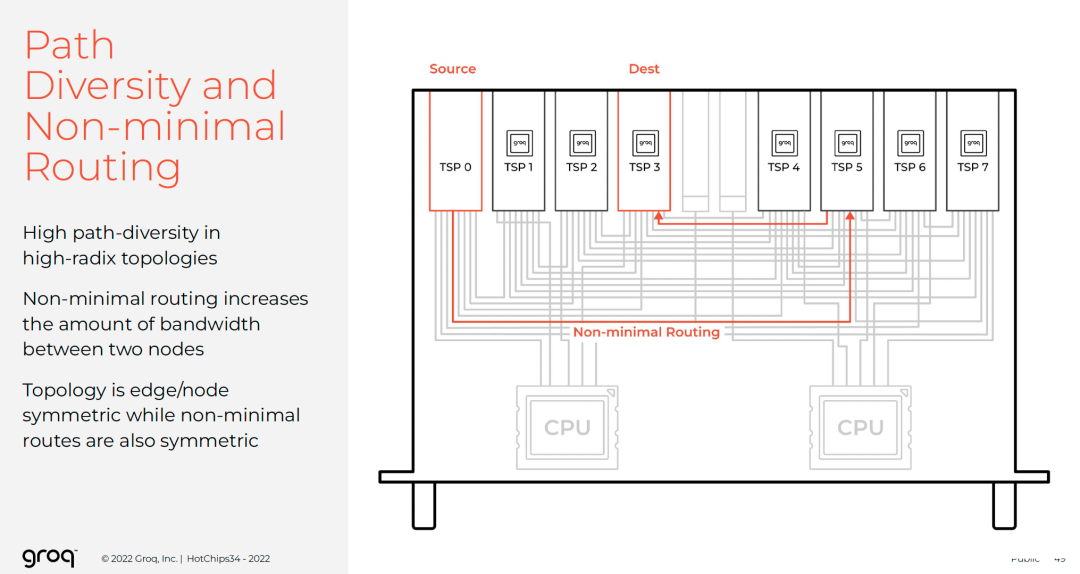
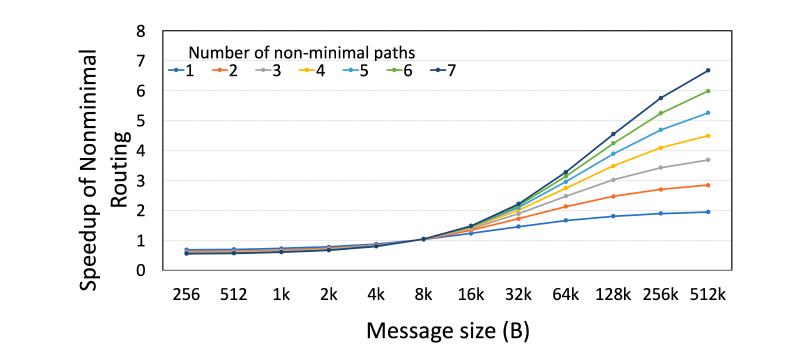
根据张量大小选择路径数,优化通信延迟。
6.4 Flow Control
禁用动态仲裁与深度队列。
无虚拟通道(VC),因调度提前避免死锁。
Packet格式仅2.5%开销:

7. RAS
确定性使软件定义RAS成为可能。
7.1 FEC和软件重放机制
使用FEC纠正传输错误,标记严重故障并触发软件重放。
避免链路层重传带来的不确定性。
NaN/Inf异常在编译时处理语义。
7.2 ECC
全芯片使用SECDED ECC保护SRF、指令队列等。
SXM仅用奇偶校验,权衡面积与可靠性。
8. Groq软件架构
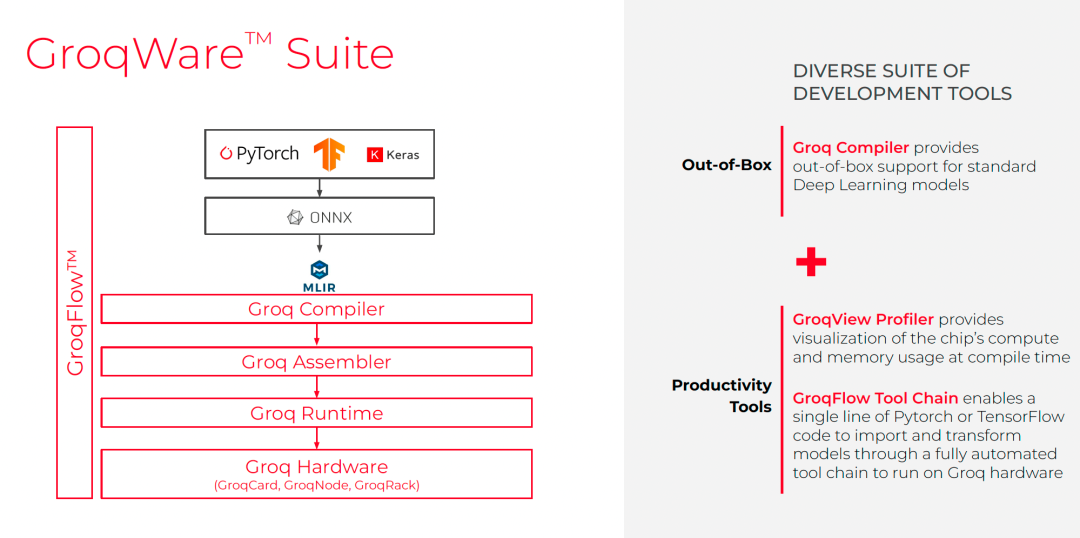
8.1 GroqIt
极简API接口:
gmodel = groqit(model, inputs)
output = gmodel(**inputs)
latency = gmodel.benchmark()
支持指定num_chips、build_name、rebuild策略。

8.2 Groq Compiler
前端支持PyTorch/ONNX → GTen ops → FU指令。
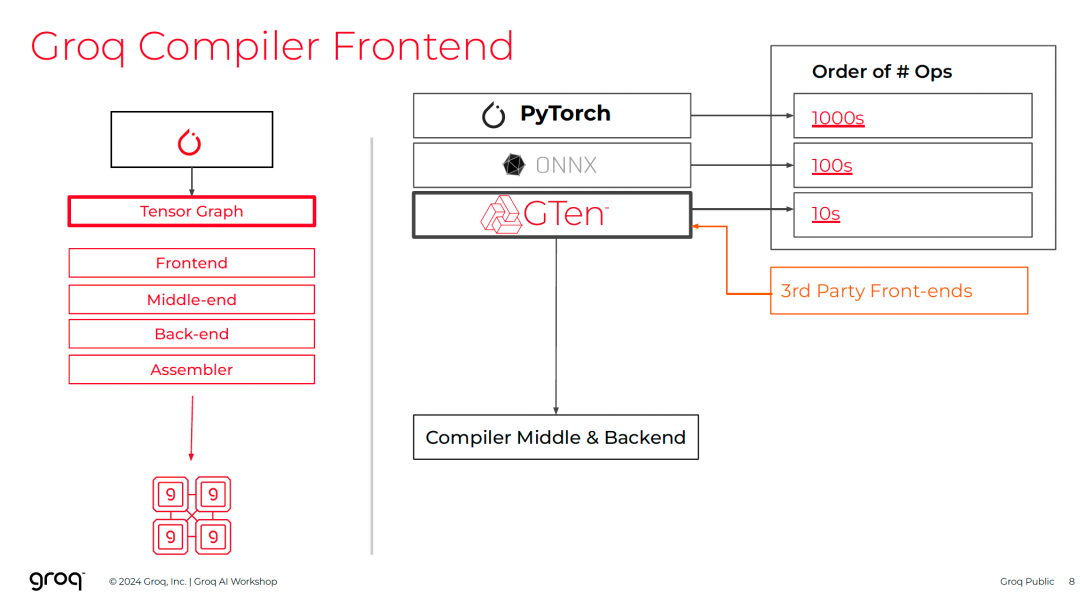
调度考虑:
- 哪个周期?
- 哪个功能单元?
- 哪些流?
- 哪些内存切片?
支持Vector vs Tensor调度:

多设备划分:流水线/模型并行。
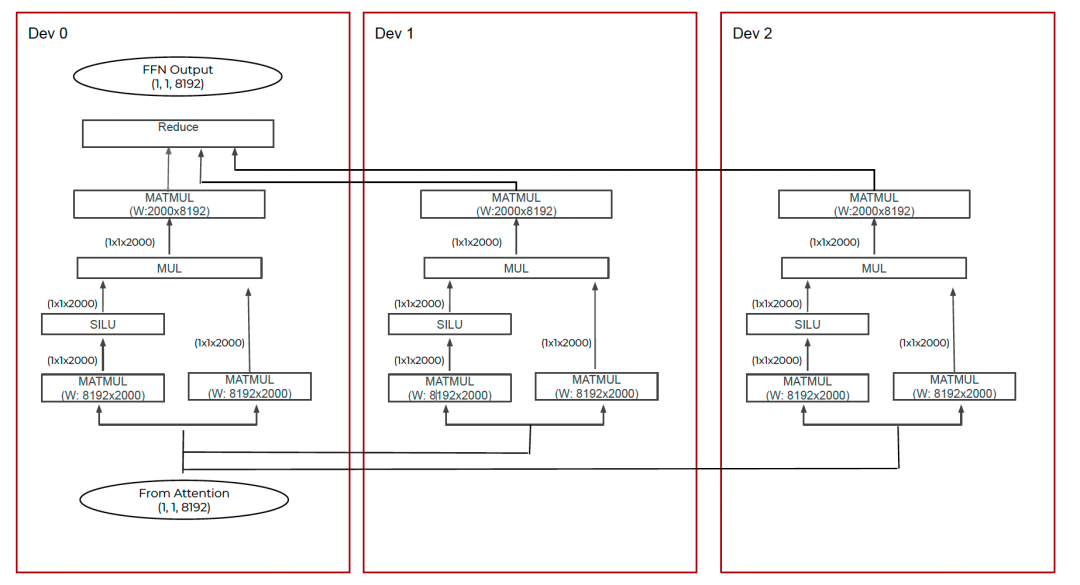
8.3 Groq Runtime
生成.iop文件,包含:
- 模型指令与权重
- SRAM加载指令
- I/O张量信息
- 调试元数据

驱动基于VFIO,实现高效DMA传输。
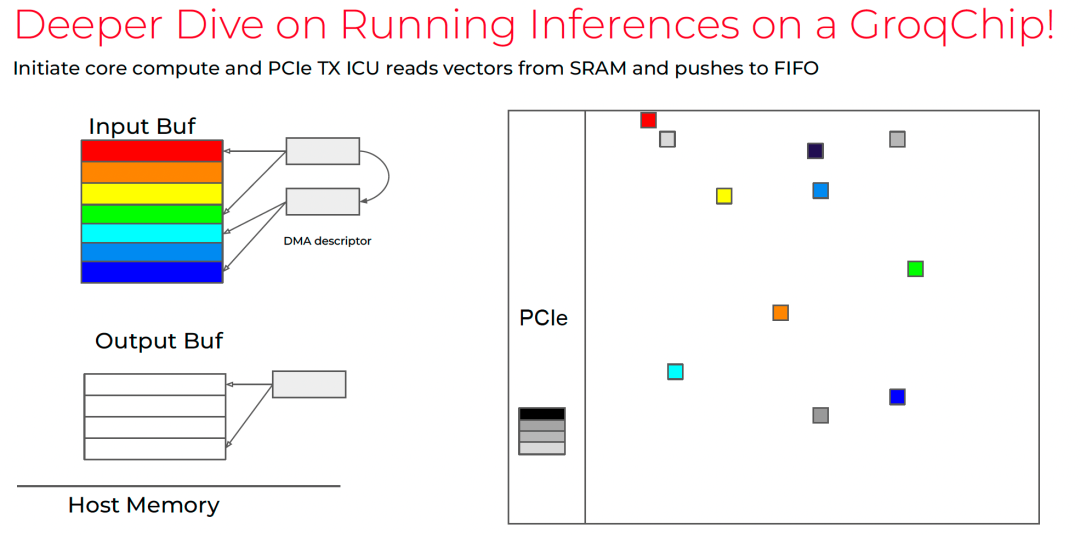
9. 未来的演进
9.1 对比GPGPU架构
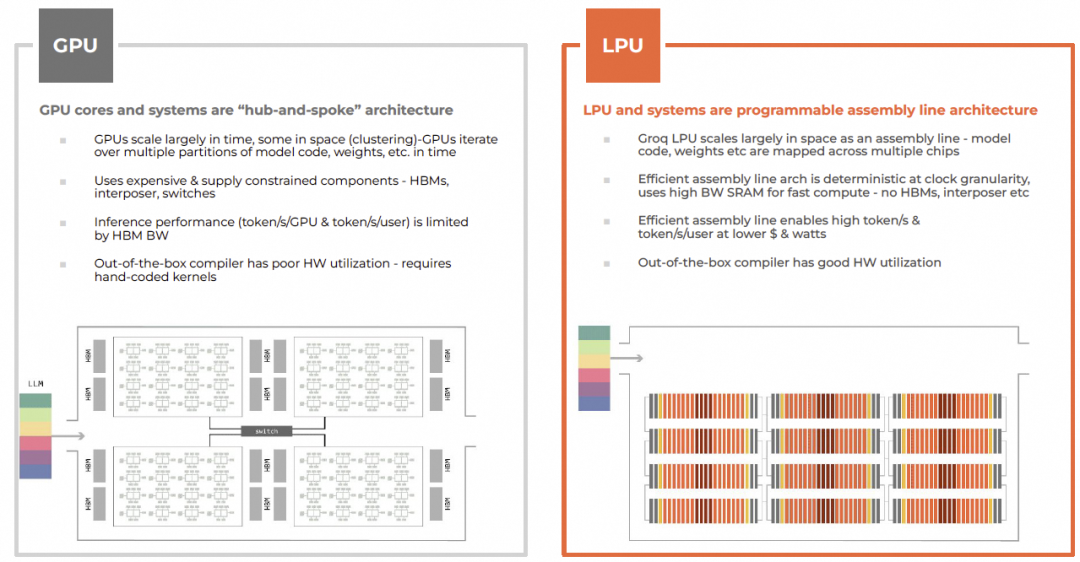
| 维度 |
GPU |
LPU |
| 架构 |
Hub-and-Spoke |
流水线装配线 |
| 内存 |
HBM,带宽低延迟高 |
SRAM,带宽高延迟低 |
| 扩展 |
时间为主,空间为辅 |
空间为主 |
| 成本 |
高(CoWoS、HBM) |
低(单芯片模块) |

9.2 Groq Roadmap
- 第二代LPU,四片合封
- 单节点32芯片,集群达68万片

编译器可评估功耗与散热,支持热优化。
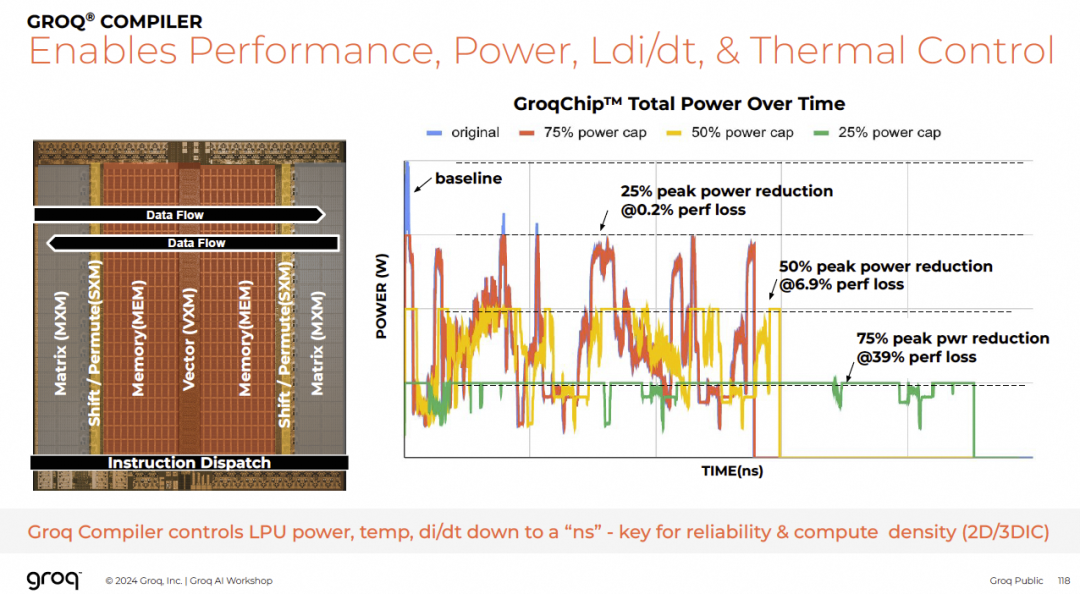
10. NV如何吸收Groq的技术
10.1 NV GPGPU的问题
Blackwell微架构瓶颈明显,尤其在跨Die延迟与通信效率方面。
10.2 是否真的需要确定性?
通信延迟仍是核心痛点。Groq的Streaming RF与确定性编译更具优势。
AWS Trn3虽未追求极致确定性,但也通过SRAM直拷与流量整形降低长尾。
10.3 CUDA Core的演进
Groq的320B向量化、Streaming RF、Virtual Cut-Through转发值得借鉴。
10.4 编译器视角
Tile-Based DSL(如cute-dsl)与静态图编译(如nncase[5])是未来方向。
10.5 3D架构
Groq通过编译器优化3D堆叠散热,极具启发性。
10.6 关于通信
NetDAM实验显示确定性延迟可达427ns:

Groq HAC延迟约217 cycles(~241ns @900MHz):
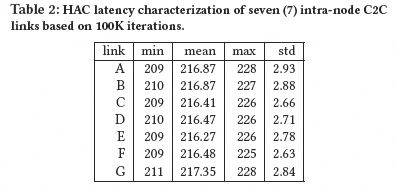
指令封装在FLIT中,支持自包含操作。
10.7 从稳定性的角度
DSA架构下热迁移只需拷贝SRAM并Replay流,远比GPU复杂内存体系迁移简单。
对称拓扑也利于N+1冗余部署。
参考资料
[1] A Software-defined Tensor Streaming Multiprocessor for Large-scale Machine Learning: https://cdn.sanity.io/files/chol0sk5/production/81d0c45ed70a10f1804bbd82f2d0076af1186ff0.pdf
[2] HC34-S4: Machine Learning: https://www.youtube.com/watch?v=MWQNjyEULDE
[3] The Groq Software-defined Scale-out Tensor Streaming Multiprocessor: https://hc34.hotchips.org/assets/program/conference/day2/Machine%20Learning/HotChips34%20-%20Groq%20-%20Abts%20-%20final.pdf
[4] Determinism and the Tensor Streaming Processor.: https://cdn.sanity.io/files/chol0sk5/production/6197cb897d1622ed3767cfafefecfcf417ab64b0.pdf
[5] nncase: An End-to-End Compiler for Efficient LLM Deployment on Heterogeneous Storage Architectures: https://www.arxiv.org/pdf/2512.21571
 发表于 2026-1-4 20:07:45
|
查看: 322|
回复: 0
发表于 2026-1-4 20:07:45
|
查看: 322|
回复: 0
