本文面向已了解强化学习中策略梯度、优势函数、重要性采样等概念的读者,重点对大模型强化学习主流算法做一条线的梳理与比较。
强化学习已成为大模型后训练必不可少的环节。本篇将介绍 PPO,GRPO,DAPO,GSPO,SAPO 等大模型主流强化学习算法。
在此之前,我先简短回答几个问题,让大家对强化学习在大模型训练中有更直观、全面的认识:
- 一般情况下,强化学习训练前为何要先进行监督微调?
- 为什么强化学习训练在大模型领域是重要的?
首先,大模型在前期会使用大量文本进行自监督预训练(自回归语言建模),这个阶段决定了模型能力的上限,模型在过程中掌握了大量知识,但缺乏指令遵循能力。
此时,直接进行 RL 训练会导致大部分采样样本没有奖励信号,训练效率低下。为提高训练效率,SFT 训练能快速提升模型指令遵循的能力,相当于为 RL 阶段做热身。那么大家可能会好奇,既然 SFT 能提升指令遵循能力,为什么不直接使用 SFT,非要加入 RL 训练呢?
原因在于,SFT 训练大模型容易导致过拟合。以数学推理任务为例,SFT 会直接强迫模型输出分布与标准解题过程一致,这可能导致模型仅学会了 “模仿” 解题过程的输出风格,但没有学会真正的数学解题能力。
另一方面,SFT 训练并非渐进式的。训练初期,若样本中包含难度较高的数学问答样本,模型因推理能力有限,会倾向去“背题”而非“理解题目”,这类样本产生的梯度会严重损害模型泛化能力。
反观 RL 训练,它采用渐进学习策略,训练样本通过模型自身采样生成,这能保证训练样本与模型当前能力分布间的差距不大。模型能够理解当前能力所及的题目,而不是去“背题”。
形象地说,SFT 更像是老师给学生“灌输”知识,学生能在短时间内学会一套解题套路,但模型尚未将这些知识完全内化成能力。而 RL 则更像是学生在老师布置的题库上不断做题、订正和反思:解题方法是模型自己采样出来的,分布始终贴着模型当前能力,从而在“做题—反馈—调整”的循环中,逐步把知识沉淀为真正的能力。
下面我将按照技术发展脉络,依序介绍大模型主流强化学习方法。从最早的 PPO 出发,依次经过 GRPO、DAPO、GSPO,再到最新的 SAPO,每一个方法都在前一代技术的基础上改进与演化。
PPO:旧策略采样与 Clip 约束的新策略更新
PPO 是经典的强化学习算法,它通过旧策略采样轨迹来估计新策略的梯度。这种方法必须保证新、旧策略分布差距不大,否则估计的梯度会失准。PPO 使用 hard-clipping 技巧来避免新、旧策略分布差距过大。
PPO 公式如下:

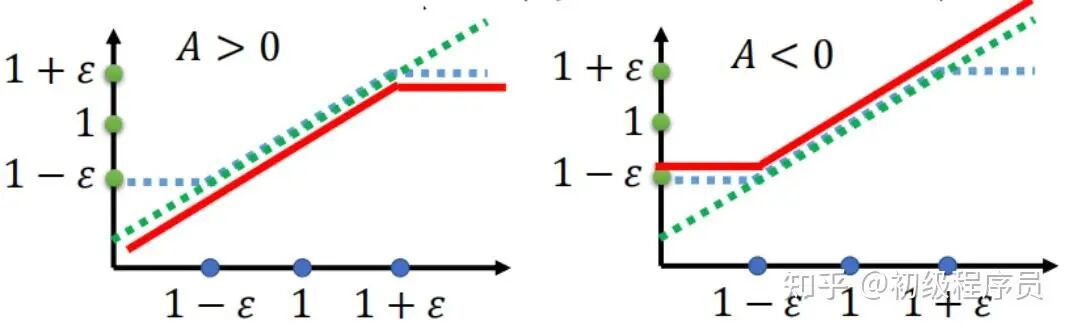
PPO 的训练流程如下:
- 采样轨迹:通过策略模型生成当前批次 prompt 的 response。
- 奖励计算:对生成的 response 进行序列级别的奖励计算(可通过奖励模型预测或基于规则计算)。
- 计算价值估计:价值模型估计每个 response token 的价值,即截止到当前 token,未来生成完整个 response 的期望奖励回报。
- 计算 token 级别优势:通过广义优势估计将优势分配给每个 token,形成 token-level 的监督信号。
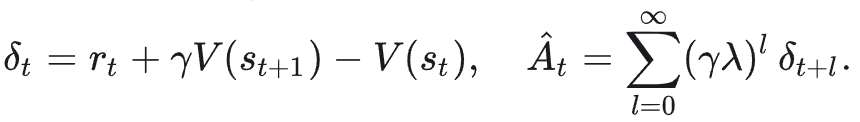
- 更新价值模型的梯度。
- 更新策略模型的梯度。
GRPO:舍弃价值模型,通过分组采样估计优势
GRPO 的核心思想是舍弃价值模型,通过采样同一 prompt 下的多组样本来估计经验优势,从而降低资源开销。
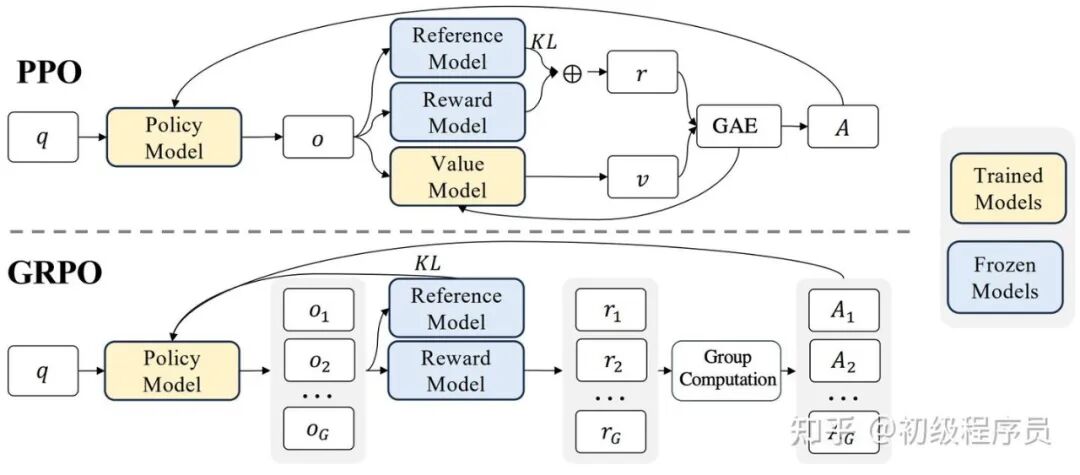
PPO 存在以下几点缺点:需要同时训练价值模型,造成额外计算开销;优势估计依赖价值模型的预测,其训练质量直接影响策略训练的稳定性。一旦价值模型估计不稳定,整个策略训练就会变得高度不稳定。
GRPO 巧妙地避开了价值模型的估计,其核心想法是通过多次轨迹采样来估计优势。给定一条 prompt,GRPO算法会采样该条 prompt 的 G 条轨迹,并计算对应的奖励,然后直接使用经验优势。

GRPO 保留了 KL 散度项,以避免模型因过度追求奖励而导致模型崩塌。
DAPO:GRPO 的改进,提升训练效率与稳定性
DAPO 在 GRPO 的框架上,通过不对称裁剪、动态采样、token 级别损失等技巧缓解训练效率和稳定性问题。它主要包含以下几个方面的改进:
1. 更高裁剪上界:GRPO 存在熵塌陷问题,即训练早期模型输出分布的熵快速下降,这会抑制模型探索能力,导致经验优势计算为 0,降低训练效率。熵塌陷源于 GRPO 的裁剪设计。

2. 动态采样:GRPO 训练效率低的另一个原因是,模型可能会看到太简单(全对)或太难(全错)的样本,导致采样出来的轨迹优势全为 0,没有策略梯度。因此,DAPO 通过约束条件过滤掉全对或全错的样本。

3. Token-Level 策略梯度损失:GRPO 会将序列级别的优势平均分配给每个 response token。这导致长推理序列中,每个 token 分配到的优势非常少,策略梯度强度很弱。因此,DAPO 提出 Token-Level Policy Gradient Loss,让同个 mini-batch 内,每个 response token 的 advantage 权重相同。
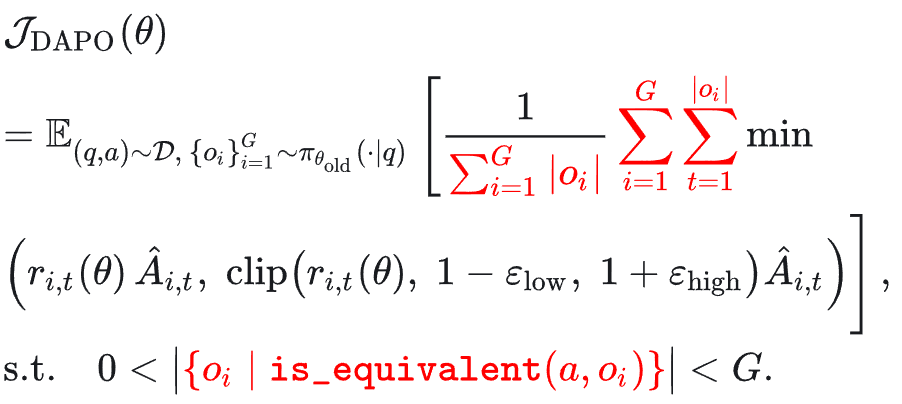
4. 过长奖励重塑:传统方法会将过长的 response 截断,这些被截断的样本也会参与到奖励计算中,造成奖励噪声,导致训练不稳定。通过超长过滤策略,对被截断的样本进行损失屏蔽,可以提高训练稳定性。此外,为避免模型生成过长的 response,会在原有奖励基础上加入长度感知惩罚。
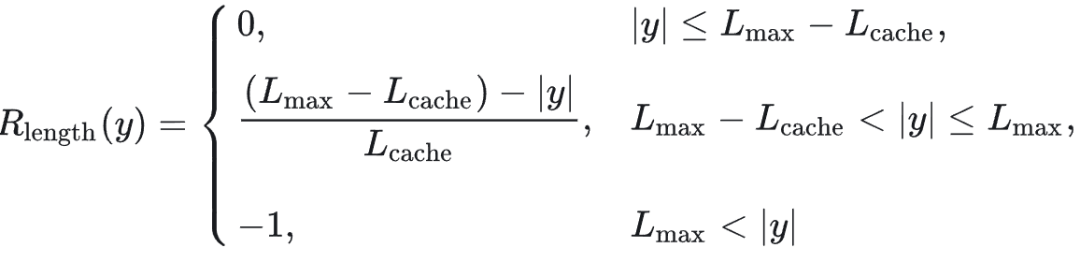
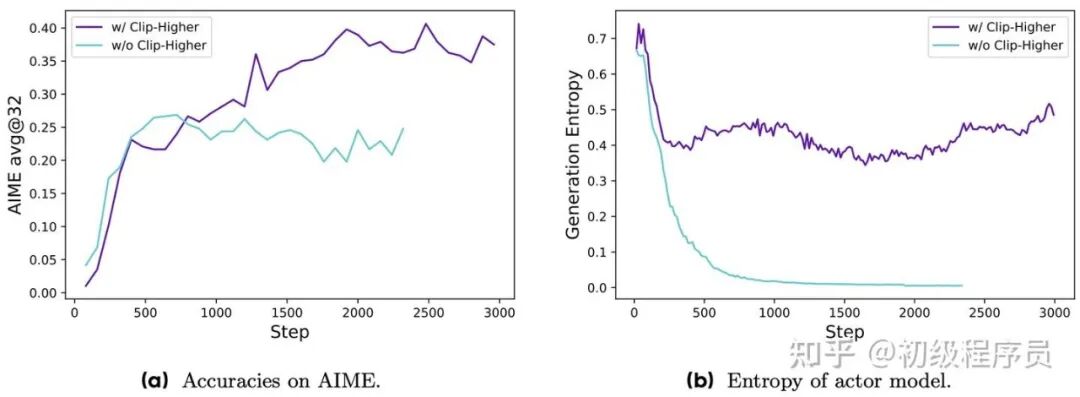
Qwen2.5-32B 模型微调后在 AIME 测试集上准确率,以及在 RL 训练过程中【采用/未采用】Clip-Higher 策略时,模型生成概率的熵变化。
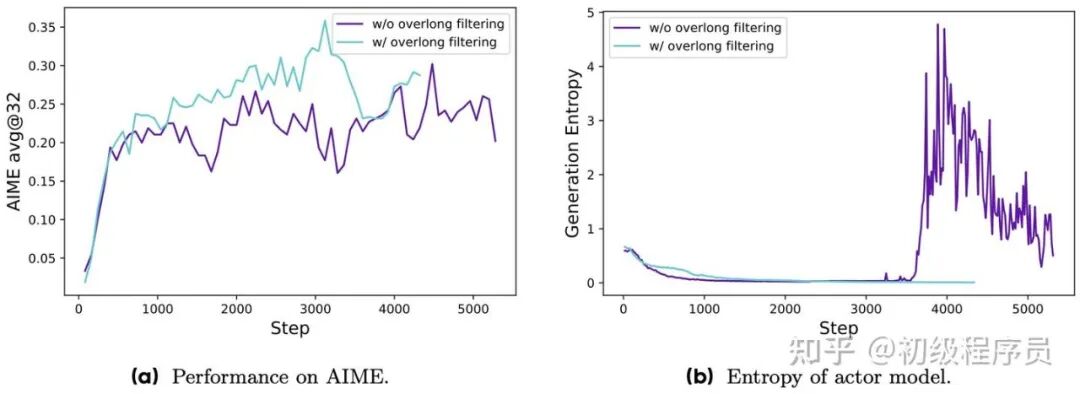
Qwen2.5-32B 模型微调后在 AIME 测试集上准确率,以及其生成概率的熵变化,对比【采用/未采用】Overlong Reward Shaping 策略的情况。
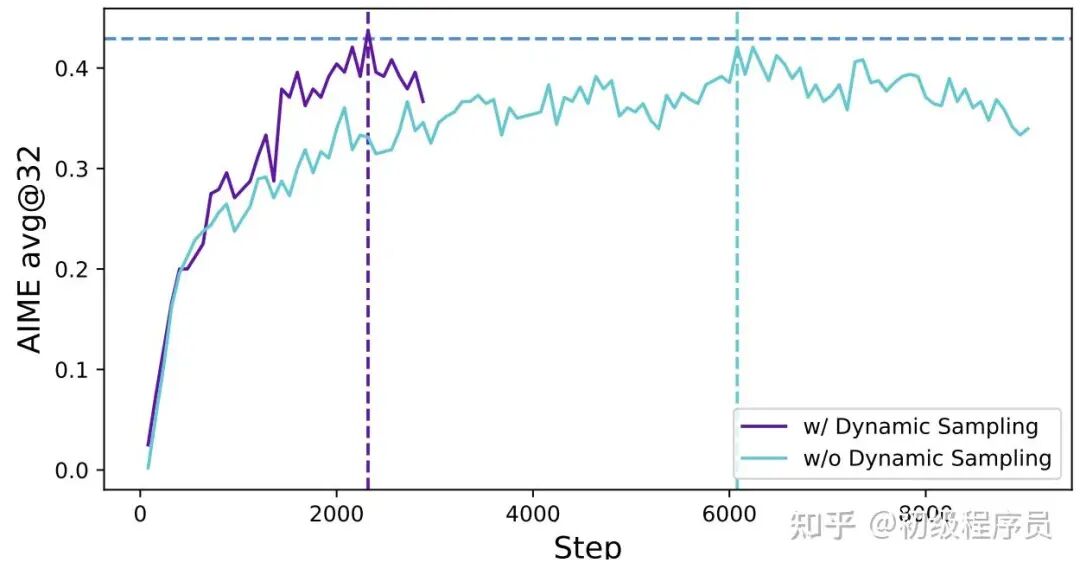
【采用/未采用】Dynamic Sampling 策略的对比。
GSPO:序列级别重要性比率,提升MoE模型训练稳定性
GSPO 是阿里巴巴提出的方法,旨在改善 GRPO 训练不稳定且效率低的问题。GSPO 将 token 级别的优势与重要性比率改为序列级别。
在 GSPO 中,序列级别的重要性比率定义为:
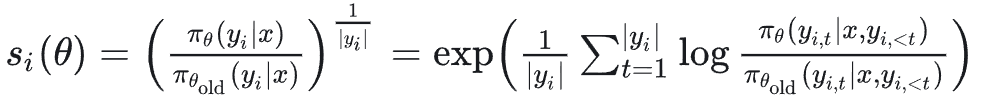
其目标函数为:
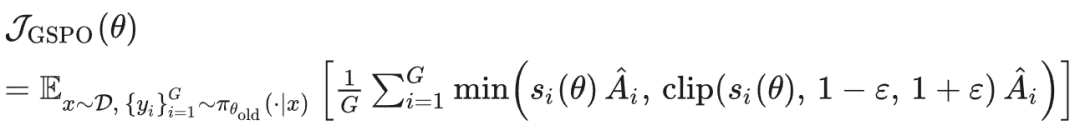
下面简短说明 GSPO 为什么比 GRPO 更有优势:
1. 梯度更稳定:对比 GRPO 与 GSPO 的策略梯度公式可以发现,GRPO 的策略梯度方向受到了重要性比率的扭曲,这会影响更新的稳定性与效率。而 GSPO 每个 token 的策略梯度权重相等,重要性比率仅决定梯度的强弱,不决定方向。
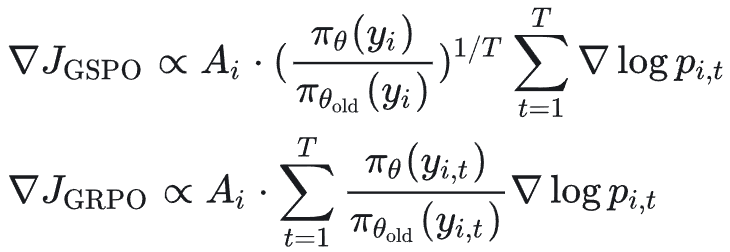
2. MoE 训练更稳定:混合专家模型训练难度大,每次策略梯度更新都可能改变激活的专家,从而导致同个序列的 token-level 重要性比率出现剧烈震荡,阻碍模型有效收敛。论文以微调 Qwen3-30B-A3B-Base 为例,每次更新平均会激活约 10% 的新专家。GSPO 通过约束 sequence-level 的重要性比率,在 MoE 训练中更具优势,因为即使 token-level 比率波动剧烈,整体的 sequence-level 比率仍能保持相对稳定。
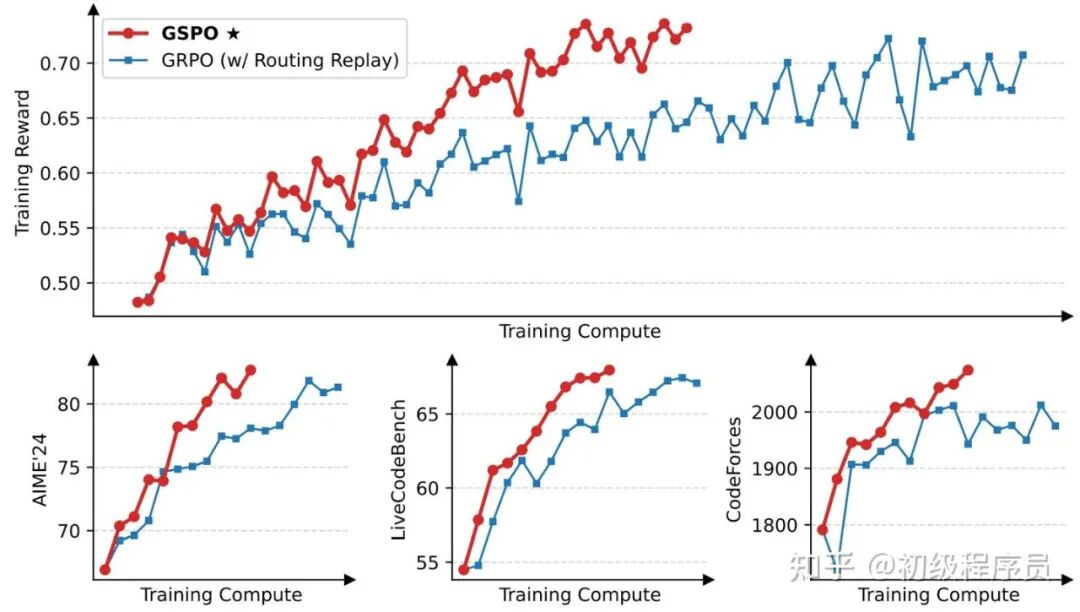
由 Qwen3-30B-A3B-Base 冷启动微调所得模型的训练曲线。GSPO 的训练效率明显高于 GRPO。
SAPO:软门控替代硬裁剪,实现连续平滑过渡
SAPO 对 GSPO 做了进一步优化。GSPO 使用序列级别的硬裁剪机制,这导致部分序列因重要性比率过大而被完全裁剪,以致整条序列的策略梯度为 0,影响训练效率。
SAPO 将硬裁剪改为软门控函数,避免了策略梯度为 0 的问题。
SAPO 目标函数为:
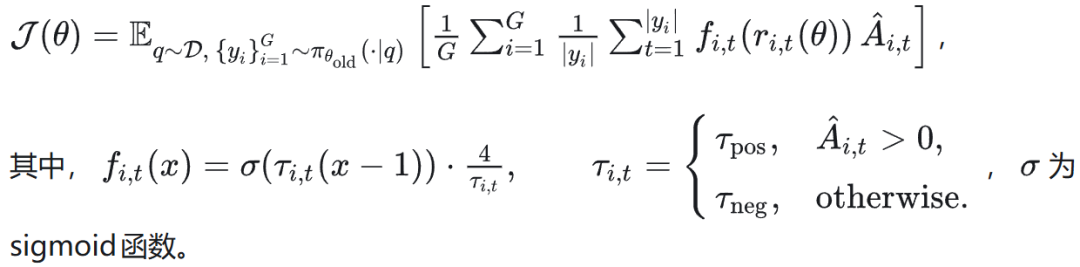
SAPO 的策略梯度为:

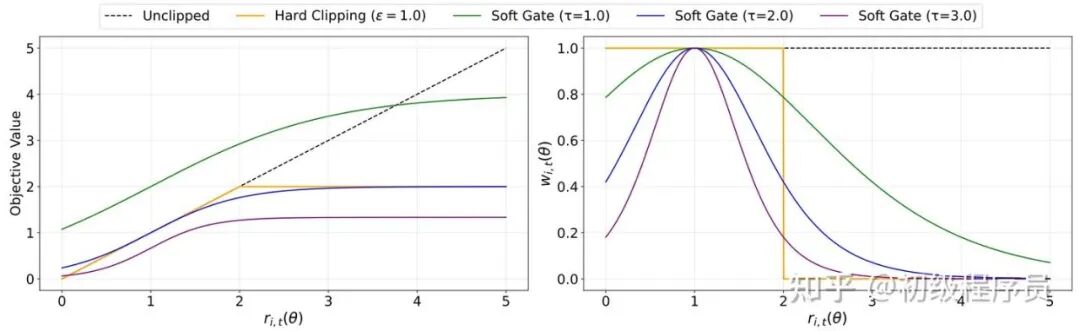
advantage>0 情况下的比较。左图展示目标函数随 importance ratio 的变化曲线;右图展示对应的梯度权重随 importance ratio 变化的曲线。
总结来说,SAPO 有两个主要创新点:
1. 软门控取代硬裁剪:提高了训练稳定性与效率。
2. 正负 token 非对称温度:由于负优势 token 倾向于提高所有非当前 token 类别的概率,可能引发训练不稳定,因此设定 τ_neg > τ_pos 旨在降低负优势 token 的影响。

因此,SAPO 同时具有序列级别与 token 级别的特性。在特定条件满足时,其目标函数与 GSPO 相近;而在条件不满足时,其行为退化为 GRPO。同时,SAPO 通过软门控在 on-policy 与 off-policy 策略间进行连续化的权重调整,以避免硬式切换造成的非平滑策略梯度,从而增强整个优化过程的稳定性。
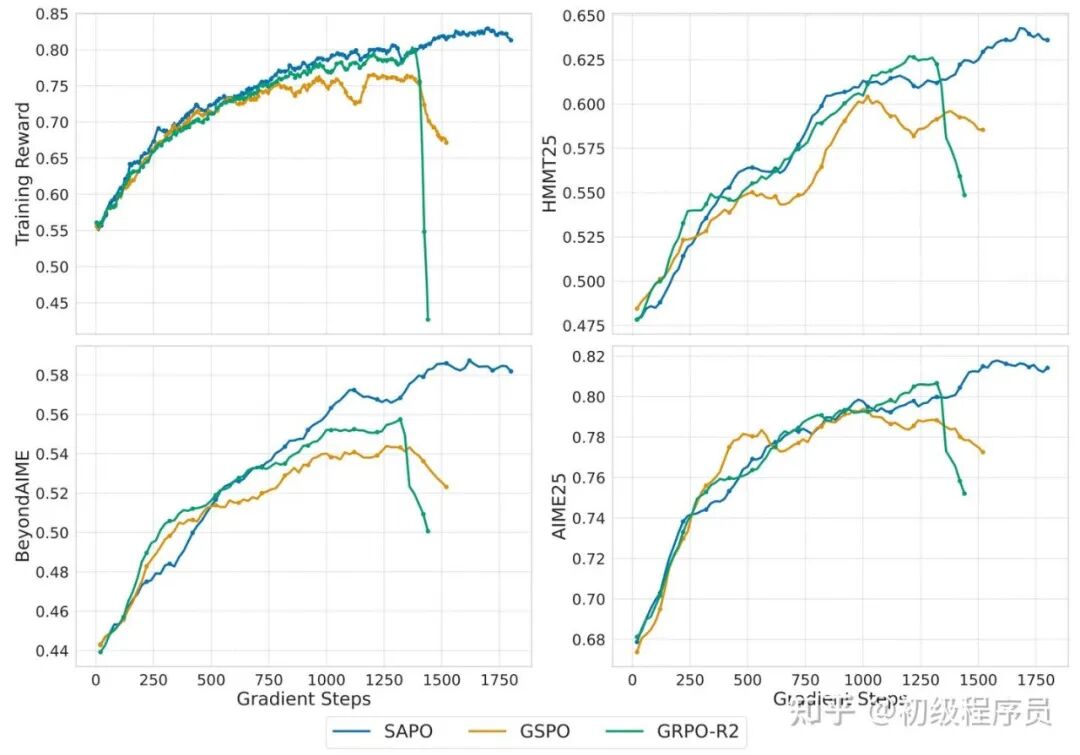
对 Qwen3-30B-A3B-Base 模型进行不同 RL 方法下的训练与验证表现。SAPO 的学习过程始终稳定,最终性能也更高。
总结
PPO,GRPO,DAPO,GSPO,SAPO 可以视作一条面向大模型强化学习微调的算法演进链:
- PPO 作为经典强化学习算法,在旧策略采样、clip 约束小步更新的框架下,让大模型可以稳定地进行策略梯度更新。
- GRPO 通过同一 prompt 下的样本组来估计经验优势,省去了价值模型的训练开销。
- DAPO 在 GRPO 的基础上加入不对称裁剪、动态采样、token-level 策略损失与长度奖励等技术,显著提升长推理序列的训练效率与稳定性。
- GSPO 将重要性比率与优势提升到序列级别,缓解了 MoE 等大模型训练中 token-level 重要性比率剧烈波动带来的不稳定性。
- SAPO 以软门控取代硬裁剪,并通过正负优势不同温度,在 sequence-level 与 token-level、on-policy 与 off-policy 之间实现自适应折中,兼顾了训练稳定性与效率。
来源:https://zhuanlan.zhihu.com/p/1978480903136245222
 发表于 2026-1-10 22:58:37
|
查看: 290|
回复: 0
发表于 2026-1-10 22:58:37
|
查看: 290|
回复: 0
