在理解了Redis主从复制的原理后,我们实现了一主多从的读写分离架构,这初步提升了系统的并发处理能力和数据冗余度。然而,这种架构存在一个致命缺陷:当主节点(Master)意外宕机时,整个集群将无法处理写入请求,从节点(Slave)也失去了数据同步的来源,服务陷入瘫痪。
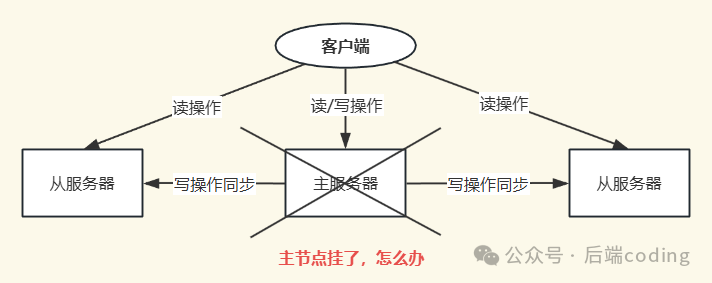
此时若想恢复服务,运维人员必须手动介入:从存活的从节点中选出一个升级为主节点,并重新配置其他从节点复制新的主节点,最后还得通知所有客户端更新连接地址。这套手动流程不仅效率低下,在紧急情况下还极易出错,完全不符合生产环境对高可用的要求。
为了从根本上解决这个问题,Redis自2.8版本起引入了哨兵机制(Redis Sentinel)。它就像一个智能的集群管家,能够自动完成节点监控、故障判定、主从切换和客户端通知等一系列操作,让Redis主从架构真正具备了自动故障恢复的能力。本文将深入解析Redis哨兵机制的核心工作逻辑。
哨兵机制是什么?
首先需要明确,哨兵并非一个独立于Redis之外的组件。哨兵本质上是一个运行在特殊模式下的Redis服务进程。它使用和Redis相同可执行文件,只是启动时加载的配置和执行的命令逻辑不同。
从其名称“哨兵”就能看出它的两大核心职责:监控者与决策者。它需要持续监控集群中所有节点的健康状态,并在主节点发生故障时,主动执行故障转移(Failover),将集群恢复到正常工作状态。
具体来说,一个哨兵节点的核心工作可以概括为以下三件事:

- 监控:持续检查主节点、从节点以及其他哨兵节点是否处于正常工作状态。
- 选主:当主节点被判定为故障时,从可用的从节点中选举出最合适的一个,将其升级为新的主节点。
- 通知:将主从切换的结果告知客户端(让其连接新主节点)以及其他从节点(让其复制新主节点)。
核心工作逻辑:从故障检测到集群恢复
哨兵机制实现高可用的完整流程,可以拆解为五个环环相扣的步骤:故障检测 → 故障确认 → 选举哨兵Leader → 主从切换 → 集群恢复。
第一步:故障检测(主观下线)
哨兵通过心跳机制来探测节点的存活性。每个哨兵会以每秒一次的频率,向所有被监控的主节点、从节点以及其他哨兵节点发送PING命令。
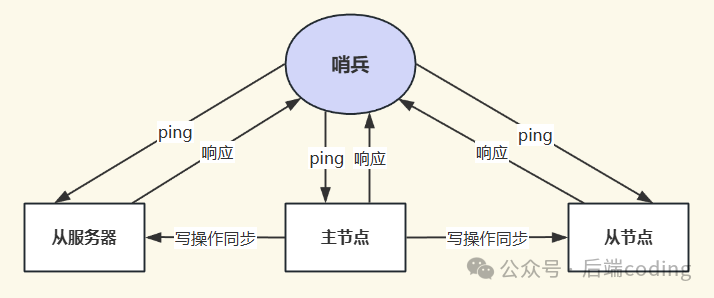
如果在配置项 down-after-milliseconds 指定的时间内(例如3000毫秒),哨兵没有收到来自某个节点的有效PONG回复,那么该哨兵就会将这个节点标记为主观下线(Subjectively Down,简称SDOWN)。
这里有两点需要注意:
- 主观下线是单个哨兵的“一面之词”。它可能因为网络瞬时抖动、节点压力大等原因产生误判。
- 主观下线适用于所有节点类型。但后续更严格的判断(客观下线)通常只针对主节点,因为从节点或哨兵节点故障对集群核心服务(写操作)影响相对较小。
第二步:故障确认(客观下线)
为了避免单点误判,高可用架构的哨兵必须以集群方式部署(至少3个,推荐奇数个)。当某个哨兵(假设为哨兵B)将主节点标记为主观下线后,它会发起一个“投票”请求,征询其他哨兵的意见。
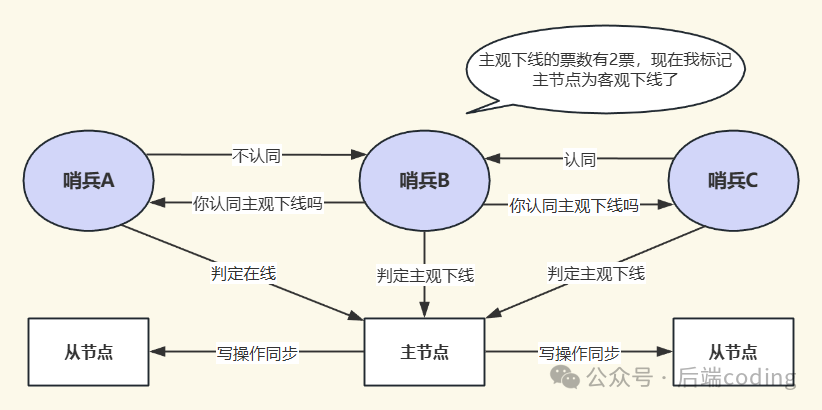
具体流程如下:
- 哨兵B向哨兵集群中的其他所有哨兵发送
SENTINEL is-master-down-by-addr 命令,询问它们是否也认为该主节点已下线。
- 其他哨兵根据自己与主节点的连接状态回复“赞成”或“反对”。
- 当哨兵B收到的“赞成票”数量达到配置文件中的
quorum 值时,它就会将主节点标记为客观下线(Objectively Down,简称ODOWN)。
quorum 值通常建议设置为 哨兵总数 / 2 + 1(例如3个哨兵时设为2)。这遵循了“少数服从多数”的原则,能有效防止因部分哨兵节点异常而导致的误判。只有主节点被标记为客观下线,才会触发后续的故障转移流程。
第三步:选举哨兵Leader
故障转移是一个关键操作,必须由唯一的“负责人”来执行,以防多个哨兵同时操作造成混乱。因此,在确认主节点客观下线后,哨兵集群会先通过选举产生一个哨兵Leader。
选举基于Raft分布式共识算法,规则清晰:
- 成为候选者:任何将主节点判定为客观下线的哨兵,都会立即宣布自己为Leader候选者。
- 投票规则:每个哨兵在每一轮选举中只有一张票,且必须投给最先向自己发送投票请求的候选者。
- 当选条件:候选者必须获得超过半数的选票(
> N/2),并且票数至少达到 quorum 值,才能成功当选Leader。
由于网络消息有先后,最终总会有一个候选者率先获得足够票数,从而避免选举僵局。
第四步:主从切换
选举出的哨兵Leader将主导整个故障转移流程,主要包括以下四个子步骤。
1. 筛选并选举新主节点
哨兵Leader不会随意挑选从节点,而是通过一套严格的筛选规则,找出状态最优的从节点。筛选流程是一个多级漏斗:
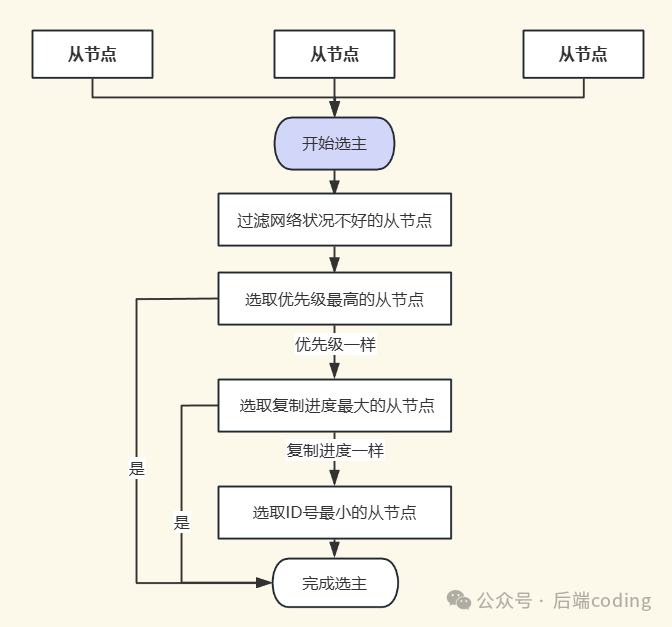
- 第一轮:过滤无效节点。排除已下线的从节点,以及网络状况不稳定的从节点(例如在指定时间内与主节点频繁断连)。
- 第二轮:优先级排序。在剩余节点中,按照以下三个维度依次比较:
- 优先级最高者胜出:每个从节点可通过
slave-priority 配置优先级(值越小优先级越高)。优先级最高的直接当选。
- 复制进度最靠前者胜出:若优先级相同,则比较复制偏移量(
slave_repl_offset),最接近原主节点偏移量的从节点数据最完整,优先当选。
- ID最小者胜出:若复制偏移量也相同,则比较节点的运行ID(
runid),ID号最小的当选。
选定目标从节点后,哨兵Leader会向其发送 SLAVEOF no one 命令,使其脱离从属关系,升级为新的主节点。
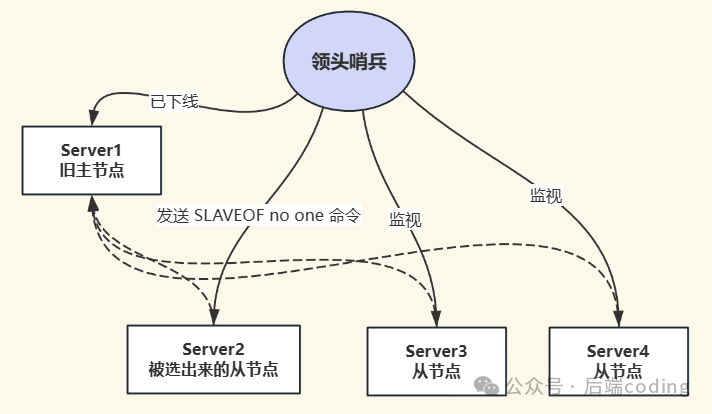
2. 让其他从节点复制新主节点
新主节点确立后,哨兵Leader会向其他所有从节点发送 SLAVEOF <new_master_ip> <new_master_port> 命令,让它们转而从新的主节点同步数据。
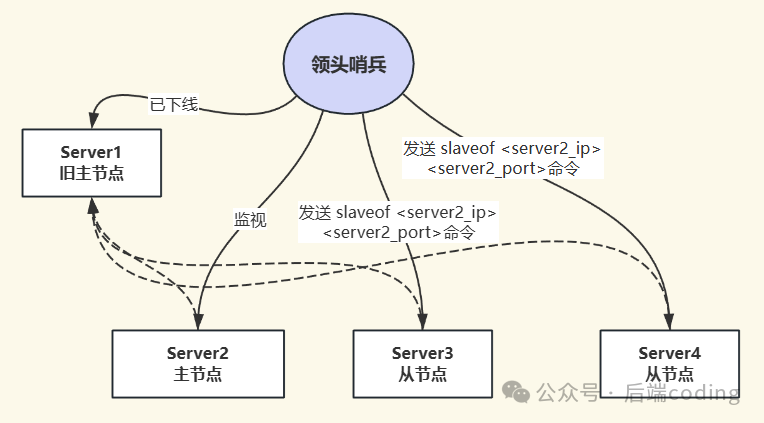
3. 通知客户端主节点已变更
客户端如何感知到主节点切换了呢?这依赖于Redis强大的发布/订阅机制。
- 客户端可以连接到任意哨兵节点,并订阅特定的频道(如
__sentinel__:hello)。
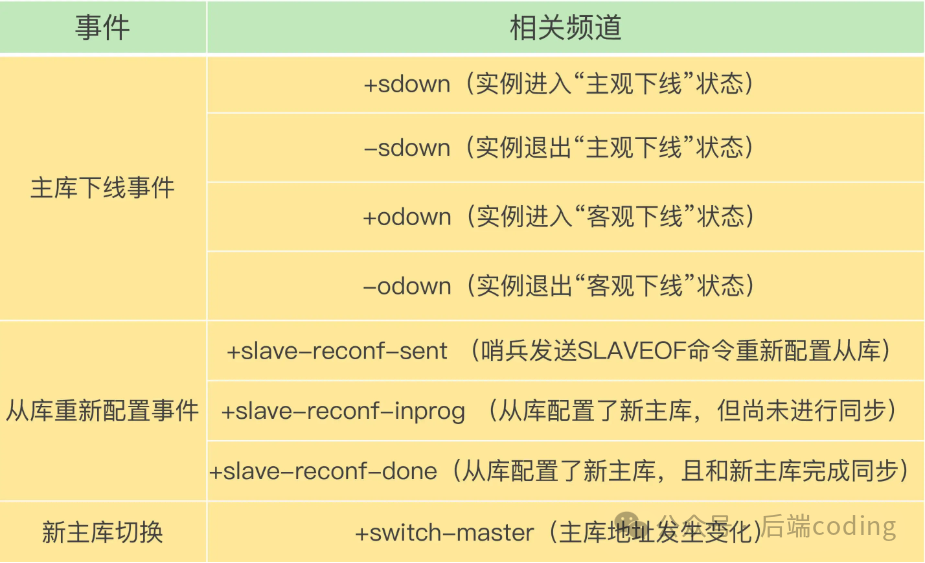
- 当主从切换完成后,哨兵会向
+switch-master 频道发布一条消息,内容包含新主节点的IP和端口。
- 订阅了该频道的客户端收到消息后,会自动更新其连接配置,将后续请求发往新的主节点。
除了 +switch-master,哨兵还提供了 +sdown(主观下线)、+odown(客观下线)等多个事件频道,方便客户端监控集群状态。
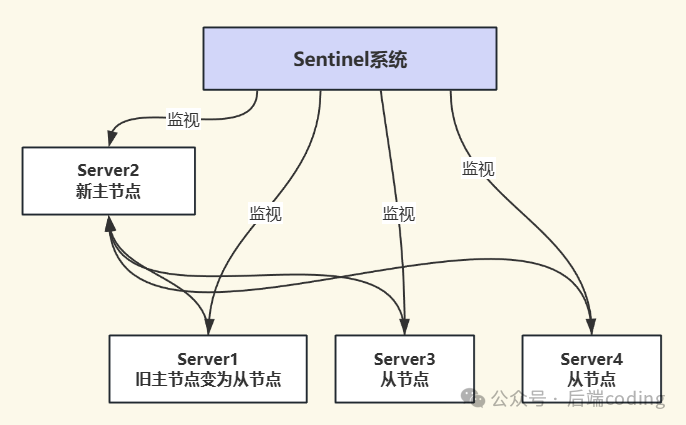
4. 将旧主节点降级为从节点
故障转移的最后一步是处理旧主节点。当旧主节点恢复上线后,哨兵会向它发送 SLAVEOF 命令,使其成为新主节点的从节点,从而完整地融入新的集群结构中。
哨兵集群如何自动组建?
一个常见的疑问是:我们只配置了哨兵监控哪个主节点,并没有配置哨兵之间的互相发现,它们是如何自动组成集群的?答案依然是 发布/订阅机制。
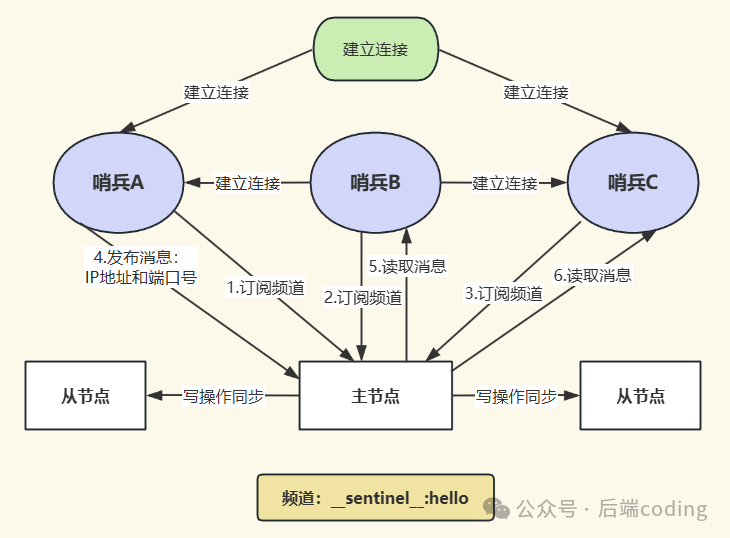
- 所有哨兵启动后,都会与配置文件中指定的主节点建立连接。
- 每个哨兵会以每2秒一次的频率,向主节点的
__sentinel__:hello 频道发布自己的信息(如IP、端口、运行ID)。
- 同时,每个哨兵也会订阅这个
__sentinel__:hello 频道。因此,每个哨兵都能通过该频道收到其他哨兵发布的信息。
- 根据收到的信息,哨兵之间会相互建立命令连接,从而自动形成一个逻辑上的集群网络。
那么哨兵如何知道主节点下有哪些从节点呢?很简单,哨兵会定期(默认10秒一次)向主节点发送 INFO 命令。主节点的 INFO 命令回复中包含了其下所有从节点的连接信息,哨兵借此便能发现并监控所有从节点。
核心流程总结
为了清晰把握,我们将主节点故障后哨兵机制的完整处理链路总结如下:
- 主观下线:某个哨兵通过PING检测,判定主节点无响应,将其标记为“主观下线”。
- 客观下线:该哨兵发起投票,当赞成票数达到
quorum 值时,主节点被标记为“客观下线”。
- 选举Leader:哨兵集群通过Raft算法选举出一个哨兵Leader来负责故障转移。
- 故障转移:哨兵Leader筛选最优从节点升级为新主节点,并让其他从节点复制它。
- 通知与恢复:通过发布/订阅机制通知客户端,并将恢复上线的旧主节点设置为新主节点的从节点。
关键配置参数
理解原理后,正确配置至关重要。以下是几个影响哨兵行为的核心参数:
-
sentinel monitor <master-name> <ip> <port> <quorum>
- 核心配置,定义要监控的主节点以及判定客观下线的法定票数(
quorum)。
-
sentinel down-after-milliseconds <master-name> <ms>
- 定义主观下线的超时时间。例如设为
3000,表示3秒内无响应则标记为主观下线。需根据网络状况调整。
-
sentinel slave-priority <master-name> <priority>
- 设置从节点的优先级(默认100),数值越小优先级越高,在选举新主节点时优先考虑。设为0表示该从节点不参与选举。
-
sentinel parallel-syncs <master-name> <num>
- 故障转移后,允许同时向新主节点发起全量同步的从节点数量(默认1)。增大此值可加速从节点数据同步,但会增加新主节点的负载。
总结
Redis哨兵机制通过引入分布式监控与自动化决策,完美弥补了主从复制架构在高可用方面的短板。其核心思想在于:通过“主观下线+客观下线”的二级判断避免误判;通过Raft共识算法选举唯一领导者来保证操作一致性;通过多维度的从节点筛选策略确保新主节点的最优性;最后借助发布/订阅机制实现集群信息的自动同步。
掌握哨兵的工作原理,不仅能让你在部署和运维Redis集群时更有把握,也能在出现故障时快速定位问题根源。技术深度决定了运维的高度。希望这篇深入解析能帮助你彻底理解Redis Sentinel,构建更稳固的缓存与存储服务。更多技术讨论,欢迎访问云栈社区进行交流。
 发表于 2026-1-12 04:08:02
|
查看: 227|
回复: 0
发表于 2026-1-12 04:08:02
|
查看: 227|
回复: 0
