引言:为什么传统架构撑不起真正的AI规模化?
许多企业虽然部署了机器学习模型,却常常陷入困境。例如,特征数据分散在Hive、Kafka、MySQL等多个系统,训练时需要手动拼接,形成“特征孤岛”。离线训练用T+1数据,线上推理用实时流,特征分布不一致导致效果崩塌。每次模型更新需重跑ETL管道,周期长达数周。当问题出现时,谁用了哪些特征?模型依赖哪些表?也无从追溯。
这些挑战的根源,在于AI工作流与底层数据架构脱节。而湖仓一体(Lakehouse)的出现,恰好为AI规模化提供了一个统一、开放、高性能且可治理的数据基座。本文将深入解析AI与湖仓一体融合的逻辑、典型场景、设计步骤及实战案例。
一、核心概念:湖仓一体 ≠ 湖 + 仓,而是AI-ready的新范式
1. 什么是湖仓一体?
湖仓一体是一种在低成本对象存储(如S3、OSS)之上,通过开放表格式(Delta Lake、Apache Iceberg、Hudi)实现数据仓库级能力的架构。它兼具两方面的优势:
- 数据湖的灵活性:支持结构化、半结构化、非结构化数据,成本低廉。
- 数据仓库的可靠性:提供ACID事务、Schema管理、时间旅行(Time Travel)和高效查询能力。
其关键突破在于:一份数据,多种计算引擎共享(Spark、Flink、Trino、Pandas、PyTorch等)。
2. 为什么AI特别需要湖仓一体?
| AI需求 |
传统架构痛点 |
湖仓一体解法 |
| 高质量特征 |
特征分散、口径不一 |
统一特征层,集中管理 |
| 批流一致性 |
离线/在线特征逻辑不同 |
同一张表支持批写+流写 |
| 快速迭代 |
ETL耦合模型,改一次重跑全链路 |
特征即表,模型直接读取 |
| 可复现性 |
训练数据版本不可控 |
Time Travel回溯任意时刻快照 |
| 端到端治理 |
数据血缘断裂 |
元数据统一,追踪从原始日志到预测结果 |
湖仓一体不是“存更多数据”,而是“让AI更可信地用数据”。
二、五大典型使用场景:AI如何在湖仓上落地?
场景1:实时个性化推荐
- 需求:根据用户最近5分钟行为动态调整推荐内容。
- 湖仓作用:
- 实时行为流(Flink)写入Delta/Iceberg表;
- 推荐模型通过特征平台(如Feast)从同一张表读取特征;
- 从根本上避免了“训练用历史宽表,推理用Kafka”的线上线下不一致问题。
场景2:大模型RAG(检索增强生成)
- 需求:基于企业私有知识库进行问答,需高效检索相关文档。
- 湖仓作用:
- 原始PDF/Word → 向量化 → 存入开放格式表(包含text, embedding, metadata);
- 利用Z-Order等索引技术加速向量近邻搜索;
- 支持直接用SQL查询:
SELECT text FROM docs WHERE similarity(embedding, ?) > 0.8。
场景3:智能风控(反欺诈/信贷)
- 需求:毫秒级判断交易是否异常。
- 湖仓作用:
- 构建用户360°特征视图(历史交易、设备、地理位置);
- 批处理生成静态特征,流处理更新动态窗口统计;
- 所有特征统一存储,确保训练与推理的一致性。
场景4:AIOps(智能运维)
- 需求:从海量日志中自动识别故障根因。
- 湖仓作用:
- 原始日志(JSON)直接存入Iceberg表;
- 使用Spark NLP进行清洗、打标;
- 模型训练直接读取结构化的日志表,无需中间转换。
场景5:生成式BI(AI驱动的自动洞察)
- 需求:当用户提问“为什么GMV下降?”时,系统能自动生成归因报告。
- 湖仓作用:
- 聚合指标(DWS层)与明细数据(DWD层)统一存储;
- LLM通过SQL接口查询数据,结合语义层生成解释;
- 所有查询过程可审计、结果可复现。
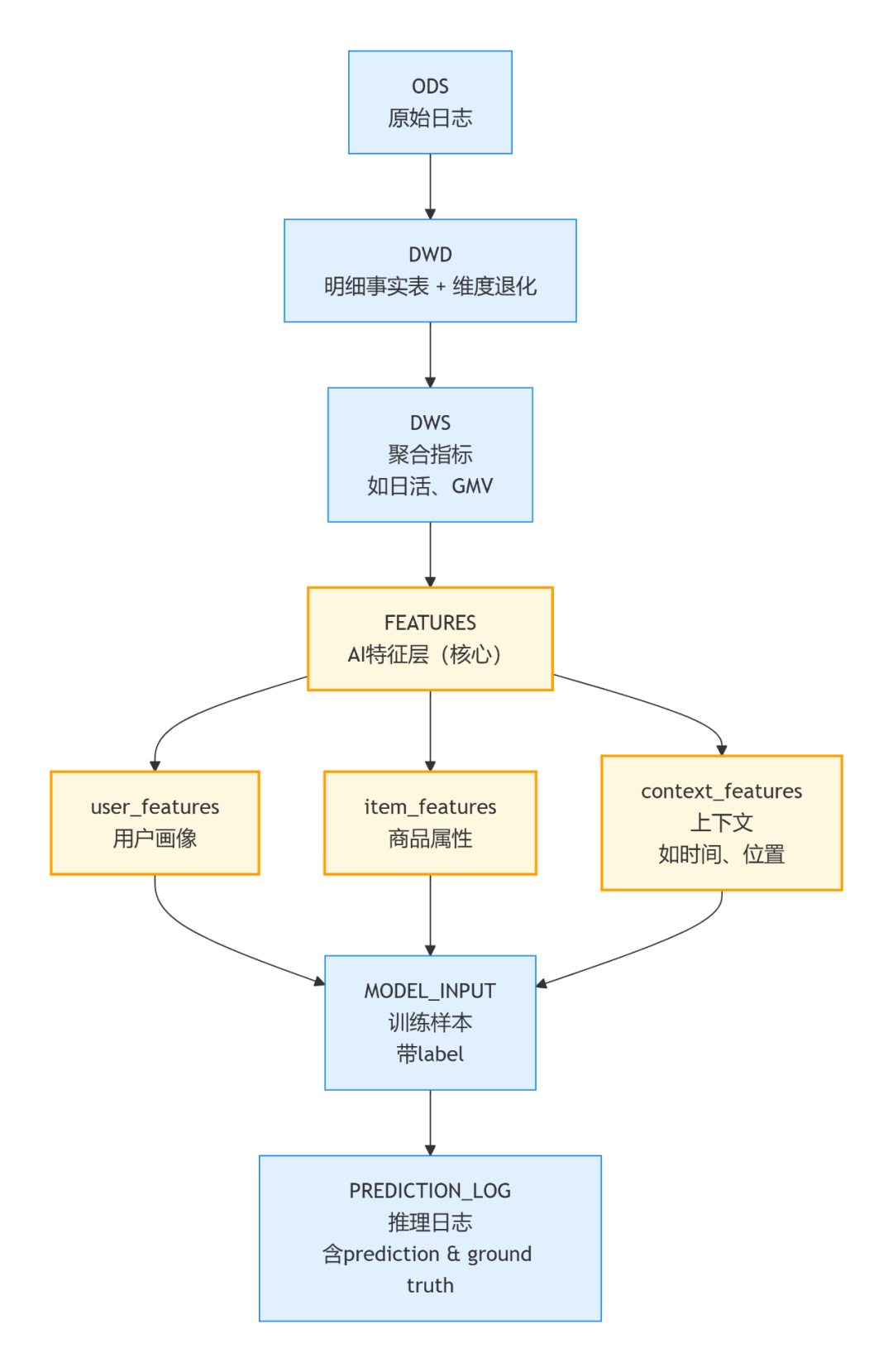
图:一个典型的AI导向的数据分层与特征工程流程
三、系统设计六步法:从0到1构建AI-Ready湖仓
步骤1:定义AI场景与SLA
- 明确是实时推理还是批量训练?
- 要求什么样的延迟?吞吐量?数据新鲜度?(例如:特征延迟 ≤ 1分钟)
- 示例:某出行平台“预估到达时间(ETA)”模型 → 需要每30秒更新路况特征。
步骤2:选择技术栈组合
| 层级 |
推荐方案 |
说明 |
| 存储 |
AWS S3 / 阿里云OSS |
对象存储,无限扩展 |
| 表格式 |
Delta Lake(Databricks生态)或 Apache Iceberg(开源中立) |
支持ACID、Time Travel、Schema Evolution |
| 批处理 |
Spark SQL / PySpark |
特征工程主力 |
| 流处理 |
Flink / Spark Streaming |
实时特征更新 |
| 特征服务 |
Feast / Tecton / 自研 |
提供低延迟特征API |
| AI框架 |
PyTorch / TensorFlow / LlamaIndex |
直接读取Delta/Iceberg表 |
建议:若已在用Databricks,选Delta;若追求开源中立与生态多样性,选Iceberg。
步骤3:设计分层数据模型(AI增强版)
关键在于构建独立的AI特征层。上图展示了一个典型流程:从原始日志(ODS)经过明细层(DWD)、汇总层(DWS),最终在特征层(FEATURES)形成服务于模型的用户画像、商品属性等特征。
特征层必须独立建模,避免在Notebook中进行临时、不可复现的数据拼接。
步骤4:实现批流一体特征管道
- 离线特征:每日凌晨用Spark生成,写入
user_features 表;
- 实时特征:Flink消费Kafka,通过
MERGE INTO 语句增量更新同一张表;
- 关键保障:
- 主键唯一(如
user_id + event_time);
- Schema严格校验;
- 依赖开放表格式的事务保证写入一致性。
步骤5:打通端到端AI工作流
- 训练:PySpark读取特征层中的
MODEL_INPUT 表,输出模型至MLflow等平台;
- 部署:模型服务启动时加载Feast等特征服务客户端;
- 推理:传入
user_id → 特征服务返回最新特征 → 模型预测;
- 日志:记录
request_id, features, prediction, timestamp 至日志表;
- 回流:真实标签(如用户是否点击)写回同一张日志表;
- 监控:对比预测值与真实值,监控数据漂移与模型衰减。
步骤6:嵌入治理与安全
- 元数据管理:用DataHub/Amundsen标注每个特征的业务含义、负责人;
- 血缘追踪:实现从原始日志 → 特征 → 模型输入 → 预测结果的完整链路追踪;
- 权限控制:对敏感特征(如身份证号)实施基于角色的精细化访问控制;
- 质量规则:设定监控规则,如特征空值率 > 5% 时自动触发告警。
四、实战案例:某头部电商平台的湖仓+AI实践
背景
原有架构:Hive做离线特征,Redis缓存实时特征。模型训练与推理使用的特征不一致,导致AB测试效果波动大,难以归因。
目标
构建统一特征平台,支撑推荐、搜索、广告三大核心AI场景。
解决方案
- 存储:阿里云OSS + Apache Iceberg;
- 计算:Spark(批处理) + Flink(流处理);
- 特征层:
user_profile_iceberg:性别、注册渠道、LTV等(每日更新);user_behavior_rt_iceberg:最近1小时点击/加购等行为(Flink每5分钟更新);
- 服务:自研高并发特征服务,提供gRPC API,P99延迟 < 20ms;
- 训练:PySpark直接读取Iceberg表生成训练集,告别导出CSV的中间环节。
成果
- 训练与推理的特征一致性达到100%;
- 模型迭代周期从平均2周缩短至2天;
- 推荐场景点击率提升12%。
五、深度思考:湖仓一体 × AI 的未来方向
-
向量与标量统一存储
未来的湖仓将原生支持向量数据类型,实现“文本+向量+元数据”的一体化管理,使其成为RAG(检索增强生成)应用的首选数据底座。
-
AI-Native SQL
数据库与查询引擎将内置AI函数,使得在SQL中进行AI推理和数据分析成为常态,例如:
SELECT ai_summarize(product_reviews), ai_sentiment(score) FROM reviews WHERE date = '2025-11-28'
图:在SQL中直接调用AI函数进行文本摘要和情感分析
-
自动特征工程
基于LLM理解业务语义,自动生成、评估候选特征,大幅降低特征工程的门槛和人力成本。
-
隐私计算集成
在湖仓层面集成联邦学习、同态加密等技术,实现“数据可用不可见”的AI训练,满足数据合规要求。
结语:不是所有湖仓都适合AI,但所有AI终将走向湖仓
湖仓一体的核心价值,并非简单替代Hadoop或传统数据仓库,而在于为AI提供一个可信、高效、可持续演进的数据操作系统。
未来的技术竞争,将不仅取决于算法的新颖性,更在于数据流动的顺畅度、特征管理的稳健性以及智能闭环的迭代速度。企业若想真正释放AI的业务潜力,必须从“以模型为中心”转向“数据与模型双轮驱动”——而湖仓一体,正是实现这一战略转型不可或缺的基石。
对于技术决策者和工程师而言,深入理解并实践这一架构,是构建下一代智能数据基础设施的关键一步。欢迎在 云栈社区 与更多同行探讨相关技术细节与落地经验。 |  发表于 2026-1-12 14:55:02
|
查看: 210|
回复: 0
发表于 2026-1-12 14:55:02
|
查看: 210|
回复: 0
