
一、核心研究背景与问题提出
1. 现有 LLM 推理范式的局限
大语言模型(LLMs)的推理能力,通常依赖两类主流路径:
- 提示工程(Prompting):例如少样本思维链(Few-shot CoT)和零样本思维链(Zero-shot CoT)。它们需要人工设计示例或指令,引导模型输出推理步骤。但问题也很明显:任务特异性强、人工成本高,而且引入人类先验后,会干扰我们对模型“固有能力”的客观评估。
- 模型调优(Model Tuning):用大规模思维链数据做指令微调或蒸馏,往往能提升推理效果,但代价是需要海量标注数据与高算力投入,同时泛化能力也可能受到限制。
换句话说:现在很多推理提升手段,要么“靠人写提示”,要么“靠数据和算力堆微调”。那有没有第三条路?
2. 关键研究问题
Google DeepMind 团队提出一个直击本质的问题:
LLM 是否能在无需任何提示(Prompt-free)的情况下,自主展现有效的思维链推理能力?
这个问题背后,其实是在追问:推理到底是依赖外部引导的“模仿行为”,还是模型预训练后天然存在的“内在能力”?如果是后者,那为什么我们在常规使用中经常看不到它?
二、核心发现与创新方法
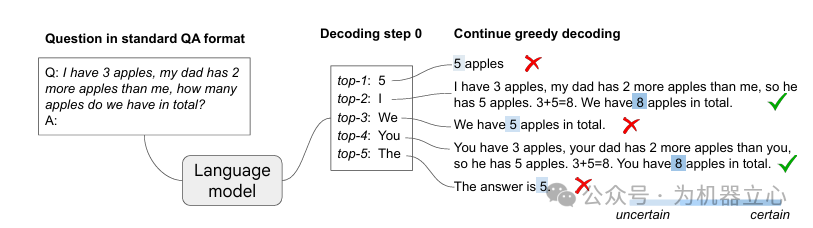
1. 突破性发现:推理路径藏于解码空间
传统解码通常采用 贪心解码(Greedy Decoding):每一步都选概率最高的下一个 token(top-1)。这种策略有个“副作用”:模型更倾向于直接给答案,而不是把推理过程写出来。
研究发现:
- LLM 的预训练已经让它具备一定的内在推理能力,这些能力以“思维链路径(CoT Paths)”的形式,隐藏在 top-k(k>1) 的候选 token 序列里。
- 当模型走“带思维链”的路径时,它对最终答案的置信度往往更高(例如图示中,包含 CoT 的路径对正确答案 “8” 的置信度显著高于错误答案 “5”)。
也就是说:问题可能不在模型“不懂推理”,而在于我们常用的解码方式把它的推理路径“压掉了”。
2. 创新方法:CoT-decoding(思维链解码)
基于上述发现,团队提出一种无需提示、完全无监督的解码策略。核心逻辑可以概括为:
在 top-k 候选路径中,挖掘能让模型对答案更“确定”的思维链路径。
如果你关注推理增强但不想重度依赖提示工程,这种思路也可以作为 人工智能 方向的工程参考。
(1)输入格式
采用极简的标准问答格式:
Q: [问题]
A:
目的只有一个:确保模型输出答案而不是继续编造问题内容,同时尽量避免任何“推理引导”的提示干扰。
(2)解码策略
- 第 1 步:在解码初始阶段(第 0 步),不只取 top-1 token,而是选择 top-k 个候选 token(默认 k=10)作为分支起点。
- 第 2 步:对每个分支起点,后续都采用贪心解码生成完整输出,从而得到 k 条候选路径。
(3)路径筛选:基于答案置信度的过滤
定义置信度指标 [\Delta],计算答案 token 序列中每个位置 top-1 与 top-2 的概率差,并取平均:
[
\Delta{k, answer }=\frac{1}{| answer| } \sum{x{t} \in answer } p\left(x{t}^{1} | x{<<t}\right)-p\left(x{t}^{2} | x_{<<t}\right)
]
- 核心直觉:包含思维链的路径,会让模型对最终答案更“确定”,因此 [\Delta] 往往更高。
- 筛选规则:选择 [\Delta] 最高的路径作为输出,或通过加权聚合融合多条高置信度路径。(原文此处括号内容未完整展示,保持不扩写。)
(4)关键特性
- 任务无关性:不需要为不同推理任务手写专属提示,也不需要切换模板。
- 无监督性:不依赖任何标注思维链数据,仅通过解码策略挖掘路径。
- 低成本:无需额外训练模型,只在解码阶段增加分支搜索与评估成本。
三、实验验证与核心结果
1. 实验设置
- 模型:PaLM-2(全尺度:XS/S/M/L)、Mistral-7B、Gemma-7B(含预训练与指令微调版本)。
- 数据集:数学推理(GSM8K、MultiArith)、常识推理(Year Parity)、符号推理(Big-Bench-Hard)。
- 基线方法:贪心解码、温度采样、Top-k 采样、核采样、束搜索、自一致性(Self-Consistency)等。
2. 核心实验结果
(1)CoT-decoding 显著超越传统解码
在 GSM8K 数据集上:
- Mistral-7B 的贪心解码准确率仅 9.9%,而 CoT-decoding(k=10)提升至 25.1%。
- PaLM-2 Large 从 34.8% 提升至 63.2%,并且是唯一能稳定提升推理性能的解码策略(其他采样方法准确率甚至低于贪心解码)。
这里的信号很强:并不是“采样多一点”就能变好,关键在于是否能稳定找到那条更可靠的推理路径。
(2)跨模型、跨任务的泛化性
- 模型泛化:在 PaLM-2、Mistral、Gemma 三大模型家族中,CoT-decoding 均实现 10%–30% 的绝对准确率提升,部分任务甚至性能翻倍(如图 3)。
- 任务泛化:对数学推理、常识推理、符号推理均有效。尤其在 Year Parity 任务中,PaLM-2 Large 的准确率从 57% 提升至 95%,接近满分。
(3)模型尺度与指令微调的影响
- 尺度效应:模型越大,CoT-decoding 的提升越显著(PaLM-2 Large 的增益远超 XS/S/M)。
- 与微调互补:预训练模型使用 CoT-decoding 后,性能接近同尺度指令微调模型(PaLM-2 Large 预训练 63.2% vs 指令微调 67.8%);而对指令微调模型,CoT-decoding 还能进一步提升,例如 Mistral-7B 指令微调模型在 GSM8K 上从 31.2% 提升至 38.2%。
这意味着:解码策略不是“替代微调”,更像是一个可叠加的增益模块。
(4)任务难度的边界
- 简单任务(1–2 步推理):CoT-decoding 能稳定挖掘正确思维链,准确率提升显著。
- 复杂任务(3 步以上推理或高度合成任务):正确思维链占比降低,但增大 k(如 k=20)可部分缓解;此时少样本 CoT 提示仍可能发挥“教学”作用,引导模型生成更规范的推理步骤。
3. 与提示工程的结合
CoT-decoding 也可以与零样本/少样本 CoT 提示叠加,进一步扩大增益:
- PaLM-2 Large 在 GSM8K 上,零样本 CoT 提示 + 自一致性准确率为 85.3%,叠加 CoT-decoding(聚合路径)后提升至 87.0%。
- Mistral-7B 的零样本 CoT 提示准确率为 39.4%,叠加 CoT-decoding 后提升至 48.4%。
这也回答了一个实用问题:如果你已经在用 CoT 提示,CoT-decoding 仍然可能“加一档”。
四、关键洞察与理论意义
1. 重新定义 LLM 推理能力的本质
研究挑战了“LLM 必须依赖提示才能推理”的常见认知:
推理更可能是 LLM 预训练后的内在能力,而不是提示工程赋予的“后天技能”。
传统推理表现差,很多时候是贪心解码把这些能力“掩盖”了,而非模型本身缺失推理能力。
2. 揭示提示工程的真实作用
少样本/零样本 CoT 提示的价值未必是“教会”模型推理,更像是改变了推理路径的可见性与可到达性:
- 对简单任务:把模型固有的思维链路径推到 top-1,使贪心解码也能走到。
- 对复杂任务:通过示例“引导”模型生成更规范的推理步骤(偏模仿机制)。
如果推理本来就存在,那我们是不是应该更多关注“如何让推理路径浮现”,而不是只讨论“怎么写提示词”?
3. 模型推理的固有缺陷暴露
CoT-decoding 的“无提示干扰”特性,还暴露了 LLM 推理的内在短板:
- 状态跟踪薄弱:在 Coin Flip、Web of Lies 等任务中,模型容易丢失中间状态(例如多次翻转后误判硬币朝向)。
- 计算顺序错误:在多步算术任务里,模型倾向于左到右计算,而不是遵循数学优先级(先乘除后加减)。
五、局限性与未来方向
1. 局限性
- 计算成本:需要生成 k 条路径并计算置信度,相比贪心解码有额外开销(但远低于模型调优的训练成本)。
- 开放答案适配:[\Delta] 指标依赖明确的答案 token(如数字、选项),对开放式答案的置信度评估精度较低。
- 分支点限制:当前仅在解码第 0 步分支;若在后续步骤也分支,可能进一步提升性能,但计算成本会指数级增长。
2. 未来研究方向
- 高效解码:结合投机解码(Speculative Decoding)等技术,降低 CoT-decoding 的额外开销。
- 动态分支:自适应选择解码过程中的分支点,而不是固定在第 0 步。
- 开放答案优化:设计更通用的置信度评估方法,适配非结构化答案场景。
- 缺陷修复:针对暴露出的状态跟踪、计算顺序等问题,定向优化预训练或微调策略。
六、总结
Google DeepMind 的这项研究通过对解码策略的微小调整,让 LLM 的推理能力在“无需提示”的前提下被激活。它的贡献不止是一种工程技巧,更在于提供了一个新的视角:模型潜力可能隐藏在标准解码未探索的空间里。
CoT-decoding 具备无需提示、泛化性强、成本相对低的特性,为推理能力的工程落地提供了新范式;同时也促使我们重新思考提示工程与模型内在机制的关系。未来如果能把解码优化与提示工程、模型调优的互补优势更好结合,LLM 推理能力的边界还可能继续被推开。
链接: https://arxiv.org/pdf/2402.10200
 发表于 2026-1-13 18:20:49
|
查看: 160|
回复: 0
发表于 2026-1-13 18:20:49
|
查看: 160|
回复: 0
