在AI算力赛道,英伟达凭借其Hopper、Blackwell及未来的Rubin等架构GPU,早已在AI模型训练领域构筑了坚固的技术与市场壁垒。然而,随着即时AI应用场景的爆发,传统GPU在处理低批处理量、高交互频率的推理任务时,其延迟短板正变得越来越突出。
为破解这一核心痛点,英伟达则采取了一次标志性行动:斥资200亿美元收购Groq的核心技术,意图在AI推理市场抢得先机。
这笔交易不仅是英伟达史上最大手笔,刷新了推理芯片领域的估值纪录,更清晰地表明了其从“算力霸主”向“推理之王”战略转型的决心。
紧随其后,据技术博主AGF进一步披露,英伟达计划于2028年推出新一代Feynman架构GPU。该架构将采用台积电A16(1.6nm)先进制程与SoIC 3D堆叠技术,其核心目标正是为了在GPU内部深度集成Groq专为推理加速而设计的LPU(语言处理单元)。这相当于为GPU加装了一个专门处理语言类推理任务的“专属引擎”,直指AI推理中长期存在的“带宽墙”与“延迟瓶颈”。
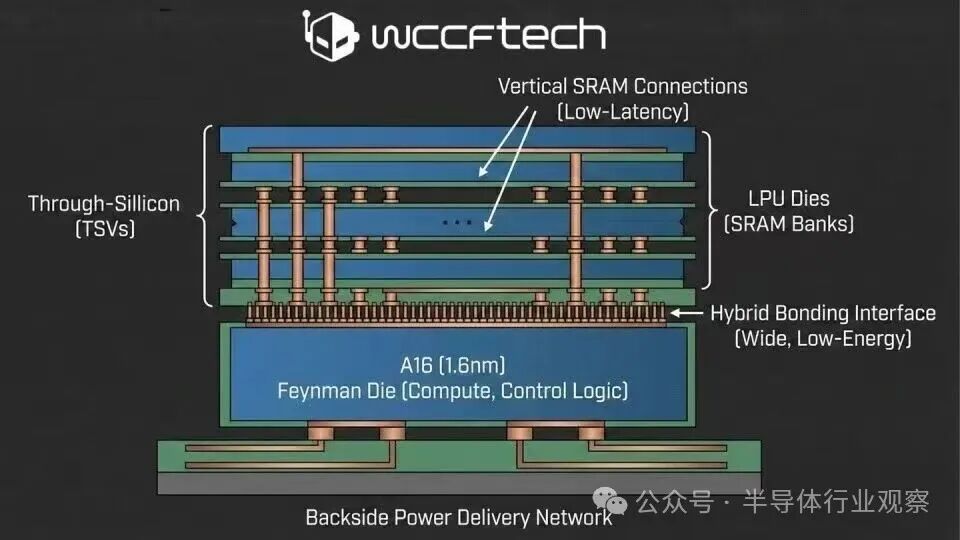
这一系列动作揭示了一个明确的行业趋势:AI行业的竞争正从单纯的算力(FLOPS)比拼,转向对单位面积带宽的极致追求。这与英伟达自身得出的“大模型推理中90%的延迟源于数据搬运,导致算力利用率常低于30%”的结论不谋而合。
无独有偶,AMD通过其3D V-Cache技术持续验证着“存储靠近计算”的效能逻辑;而d-Matrix、SambaNova等专注于AI推理的芯片公司,更是将流式执行与片上带宽构建作为核心竞争力,用产品印证了这一行业共识。
带宽战争打响,谁是“中国版Groq”?
回看中国市场,在AI浪潮的推动下,国产大模型实现多点突破,本土AI芯片企业也迎来爆发并密集冲击IPO,资本热度持续高涨。
然而,当英伟达选择通过Feynman架构来补齐其推理短板时,竞争的逻辑已然改变。谁能率先解决“带宽墙”问题,谁就握住了进入下一轮技术周期的关键入场券。
在此背景下,国内赛道已涌现出前瞻性的布局者。近日,一家源于北京大学物理学院的AI芯片公司——寒序科技(ICY Technology),宣布完成数千万元人民币的新一轮融资。这家以“超高带宽推理芯片”为核心产品的企业,被业内视为中国大陆少有的、在技术路线层面正面对标Groq的前沿团队。“中国版Groq”的轮廓,开始浮现。
实际上,寒序科技的技术披露并非偶然,而是源于其在内部保密原则下的长期深耕。早在2024年9月与2025年11月,该公司就已联合北京大学多个学院及澳门大学相关国家重点实验室,先后承担两项北京市科技计划项目。他们前瞻性地锁定了0.1TB/mm²/s超大带宽流式推理芯片的研发,并在项目任务书中全面对标了Groq的技术路线与带宽指标。
这意味着,当Groq因其LPU爆红而被视为“推理新范式”时,中国的科研与产业团队已在同步推进一条差异化的实现路径。
据了解,寒序科技采用“双线布局”构建其核心竞争力:一方面,已发布SpinPU-M系列磁概率计算芯片,推出1024比特全连接伊辛退火求解硬件,覆盖组合优化与量子启发式计算市场;另一方面,本轮融资的核心看点——SpinPU-E磁逻辑计算芯片系列,则直指大模型推理的解码(Decode)阶段加速。该系列以片上MRAM(磁性随机存储器)为核心介质,旨在构建超高带宽的磁性流式处理架构。

可以看到,寒序科技并未跟随主流GPU的片外DRAM/HBM方案,也未完全复制Groq的存算一体SRAM路线,而是选择了片上MRAM这条更底层、更具物理本征特性的技术路径。
当前主流的AI计算范式面临多重困境:采用HBM的GPU方案,带宽受限于昂贵且被海外垄断的2.5D/3D先进封装;采用SRAM的Groq方案,则因SRAM单元面积大、成本高,单芯片存储容量有限,难以规模部署千亿参数大模型。
面对这些行业共性难题,源自北大物理学院的寒序科技团队,从凝聚态物理的第一性原理出发进行思考。他们利用本征功耗更低、速度更快的“电子自旋翻转”,来代替传统的“电子电荷运动”进行信息存储与计算。
这种底层逻辑的革新,正是源于MRAM技术带来的核心优势。MRAM兼具SRAM的高速、DRAM的高密度与闪存的非易失性,其垂直结构的磁性隧道结(MTJ),通过微型化和与CMOS工艺的良好兼容性,能够大幅降低对复杂先进封装的依赖,在成本、功耗和可靠性上展现出显著潜力。
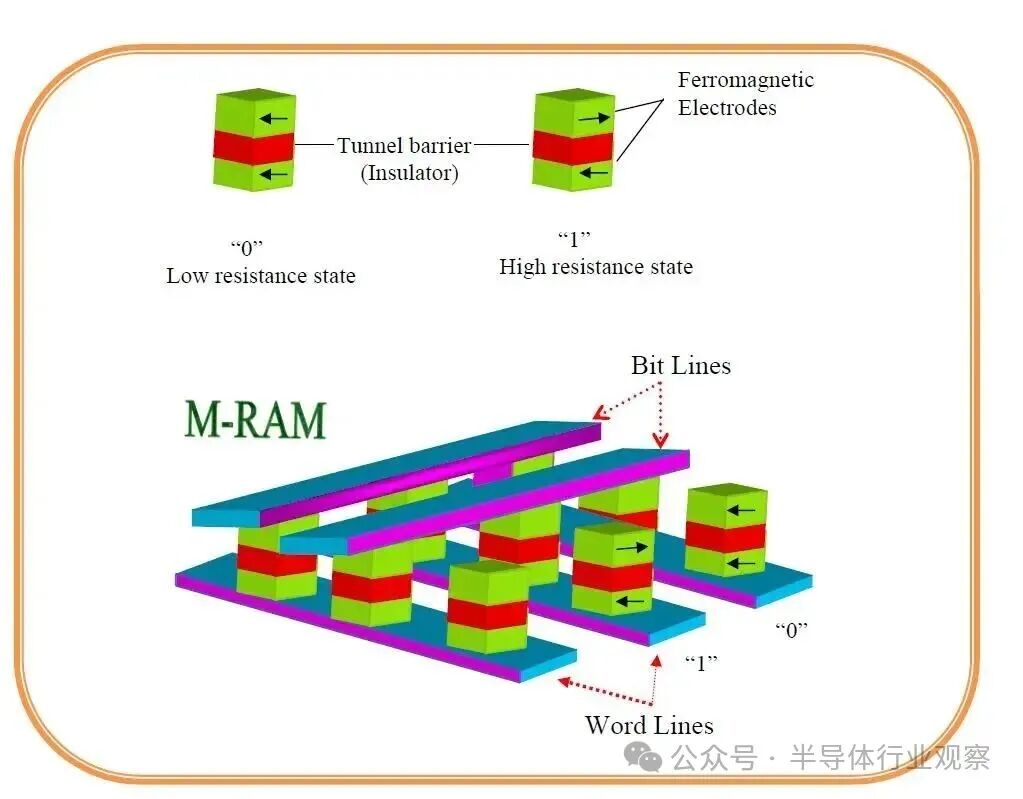
与SRAM方案相比,MRAM技术的差异化优势十分突出:
- 存储密度领先:片上SRAM正面临严峻的微缩困境。传统SRAM每个存储单元由6个晶体管(6T)组成,存储密度低,且在5nm以下节点尺寸几乎停止缩减;而MRAM采用1T1M(1个晶体管+1个磁隧道结)结构,单个MTJ可执行SRAM 6个晶体管的存储功能,同等芯片面积和工艺节点下,存储密度可达SRAM的5-6倍。
- 工艺成本更低:MRAM的物理结构优势,使其在采用相对成熟的本土工艺制程时,性能指标也能对标甚至超越采用更先进制程的SRAM方案。这意味着无需追逐极尖端制程,可大幅降低流片与量产成本,同时保障供应链的自主可控。
- 非易失性与高能效:MRAM断电后数据不丢失,无需像SRAM/DRAM那样持续刷新,待机功耗极低;同时避免了SRAM的漏电流问题,为边缘端和云端的大规模部署提供了优异的能效基础。
通过自研的磁性存算一体流式架构,寒序科技致力于将MRAM的器件优势转化为芯片级的系统性能。据悉,SpinPU-E芯片架构的目标是将访存带宽密度提升至0.1-0.3 TB/mm²·s,这不仅能够比肩以“快”著称的Groq LPU(约0.11 TB/mm²·s),更是英伟达H100(0.002-0.003 TB/mm²·s)的数十倍。

英伟达GPU的架构最初为大规模训练与图形渲染设计,强调峰值算力与吞吐能力。但在大模型推理的Decode阶段,其性能瓶颈主要来自对外部存储(HBM)和复杂内存层级的依赖。该过程呈现强序列性、小批量和带宽主导的特征,与GPU的设计初衷存在错配。在实际执行中,数据到达计算单元的时间不固定,不同计算单元之间需要反复协调,导致算力难以稳定发挥。
而寒序科技采用的是一种确定性的“磁性流式处理(MSA)架构”。该架构将大规模的MRAM存储单元紧邻计算单元部署,并围绕推理数据流构建多级流水执行路径,使权重和中间激活值在局部高带宽范围内按固定顺序流动。通过在硬件层面同时约束存储位置、访存带宽与执行节拍,该架构旨在显著降低延迟抖动与外部存储访问依赖,实现更稳定、更高速的推理性能。
值得关注的是,MSA架构并非简单的“存内计算”概念,而是围绕推理场景,对数据流组织、存储-计算耦合方式及执行节拍进行的系统性重新设计,在追求超高带宽的同时,也致力于降低对先进制程与复杂封装的依赖。
有业内人士指出,这一技术路线与英伟达在Feynman架构中释放的信号高度一致:未来推理性能的竞争核心,将不再是算力规模,而是单位面积带宽与执行效率。
走出北大实验室的秘密武器
SpinPU-E展现出的性能潜力,源于其核心团队跨学科的深厚积淀、全链条的技术把控与前瞻性的路线布局。
据报道,寒序科技是国内少数能跑通从物理材料、磁电器件、异质集成到芯片设计、人工智能算法全链条的交叉学科团队。其核心成员源自北京大学物理学院应用磁学中心,拥有深厚的磁学研究背景。团队历经多次流片验证,既保持了前沿技术探索的锐气,也具备了工程化落地的能力。
相比纯粹的架构创新,这种“材料-器件-芯片-系统-算法”的全栈视野与攻关能力,使得MRAM技术得以从底层原理到上层系统实现协同优化,而非仅停留在逻辑层面的修补。
回溯Groq的成长轨迹,其业务从LPU推理芯片起步,逐步延伸至加速卡、服务器系统,最终构建云服务平台,形成了“芯片-硬件-系统-云服务”的全栈布局。沿着这条被初步验证的商业逻辑推演,寒序科技或许也会以SpinPU-E磁逻辑芯片为起点,向上构建硬件产品矩阵,最终通过云服务触达更广泛的市场。
更为关键的是,这条路径是基于本土产业现状的创新破局。当行业苦于HBM成本高企、SRAM微缩放缓之时,寒序科技利用MRAM磁性计算新范式,尝试在成熟的本土供应链基础上,筑起一座对标全球顶尖推理性能的带宽高地。这种从底层物理原理出发的差异化竞争策略,或许正是其被视为“中国版Groq”的核心底气。
MRAM开启新型存储“黄金时代”
破局“带宽封锁”
寒序科技对MRAM技术的探索并非孤例,其背后是一场新型存储技术从“备选”走向“必选”的产业浪潮。尤其是在全球半导体产业演进与地缘政治激荡的背景下,为MRAM在内的新型存储铺就了一条通往AI算力核心的“黄金赛道”。
2024年12月,美国商务部工业与安全局(BIS)发布新出口管制规则,明确限制向中国出口内存带宽密度超过2GB/s/mm²的尖端存储器。这一封锁点,直指AI推理芯片的命门——带宽。
目前,国际巨头极度依赖HBM,而其产能被少数海外原厂垄断,且受制于复杂的先进封装。Groq代表的SRAM路线则成本极高,且在先进制程微缩上已近极限。
在此背景下,MRAM路线的战略价值陡增。它不仅具备跨代超越SRAM的物理潜力,更重要的是,它能基于国产28nm/22nm等成熟制程实现超高带宽,有望规避对尖端工艺和海外HBM供应链的依赖。这不仅是技术“备选”,更是中国半导体产业在算力领域实现差异化突围的“必选”路径之一。
全球共振,商业化拐点已至?
当前,产业界正在用实际行动表明,MRAM正从实验室走向产业化前台。台积电、三星、英特尔、格芯等晶圆代工龙头均在积极布局,将嵌入式MRAM(eMRAM)推进到22nm、16nm甚至更先进节点。
恩智浦与台积电合作推出16nm FinFET车规级eMRAM,应用于高端MCU;瑞萨电子推出了基于22nm工艺的STT-MRAM技术;格芯与Everspin合作将MRAM纳入工业级和车规级量产方案。这些头部厂商的集体行动,清晰印证着MRAM正从“备选技术”升级为“主流方案”,在汽车电子、边缘AI等领域的商业化落地进入加速期。
回看国内市场,本土半导体厂商同样敏锐地捕捉到了新型存储技术的发展机遇。在MRAM赛道,除了寒序科技,致真存储、驰拓科技、凌存科技、亘存科技等企业也已崭露头角,为国内MRAM产业的发展奠定了基础。
具体来看,本土MRAM厂商各有侧重:致真存储专注于磁性隧道结(MTJ)核心器件与制造工艺;驰拓科技专注于MRAM存储芯片的研发与制造,建有12英寸中试线;凌存科技则专注于存储模块开发与终端应用。而寒序科技的差异化定位在于,其以MRAM为核心介质构建计算芯片,开辟了“磁性计算”的全新赛道,致力于将MRAM的物理优势转化为算力与带宽优势。
生态共建:国产MRAM的“磁计算”革命
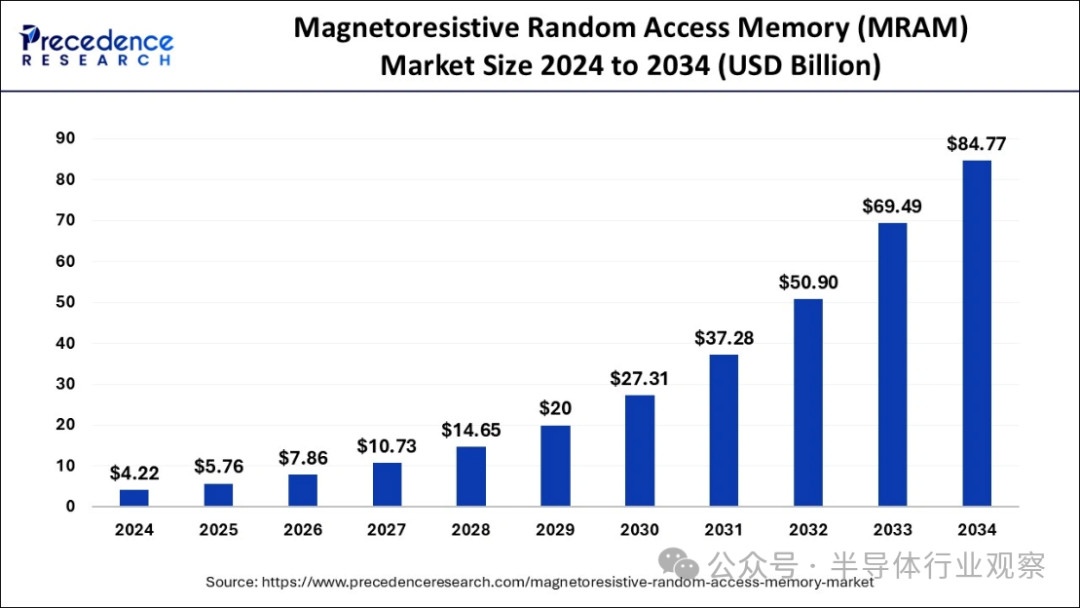
根据市场研究机构Precedence Research数据,2024年全球MRAM市场规模估计为42.2亿美元,预计到2034年将增长至约847.7亿美元,年复合增长率高达34.99%。
虽然前景广阔,但MRAM的大规模商业化落地仍需产业合力。借鉴国际经验,更深度的产业合作与资源倾斜是推动技术发展的关键。
例如,国内代工厂可加强对MRAM工艺的研发投入,与设计公司共同开展技术研发与工艺优化,争取尽早打通“设计-制造-封测”的本土化协同创新链路,降低流片成本与量产门槛。
此外,英伟达计划在Feynman架构中整合Groq LPU的案例,充分证明了“通用算力+专用引擎”的协同优势与行业趋势。这对国内AI芯片产业极具启示价值。在未来提升AI推理效率的共识下,国内厂商应加强与在新型介质与架构上具备底层创新能力的团队合作,探索打造兼具通用算力与专用推理性能的新技术路径,快速构建差异化竞争力。
产业界释放的信号已经清晰:以MRAM为代表的新型存储,已成为后摩尔时代的关键焦点之一。地缘政治的战略诉求、国际大厂的技术押注、国内产业链的长期积淀,再加上如寒序科技等企业的差异化突破,多重力量共振之下,MRAM正逐渐迈入产业化的“黄金时代”,有望成为中国AI芯片产业实现换道超车的关键抓手之一。
五年后,谁将主导下一代推理芯片?
当一批国产AI芯片公司接连叩响资本市场的大门,一个时代的答卷已然清晰。它们的密集上市,标志着中国在基于传统GPU架构的算力竞赛中,完成了从无到有的突围,进入了国产替代的收获期。
如果说上一代AI芯片的竞争是“算力竞赛”,那么下一代的分水岭将是“谁能率先跨过带宽墙”。
在这个关键转折点上,两条路径清晰呈现:一条是Groq选择的极致SRAM片上集成路径,用极高成本将带宽推向极限;另一条,则是以MRAM为代表的新型存储介质路线,为突破带宽瓶颈提供了一种更具根本性,也更符合长期成本与供应链安全需求的方案。
数年后,当AI推理进入“带宽决胜”的新时代,芯片市场的主导者或许将属于那些能够在这场“带宽战争”中率先构建起护城河的先行者。
正如Groq在硅谷用SRAM惊艳了世界,行业演进的逻辑暗示:“中国版Groq”的出现将不再是悬念。在这个征程中,寒序科技正依托MRAM磁性计算的新范式,给出了一条“中国版”的实现路径——并且,这条路,他们早在多年前,就已开始默默铺设。
 发表于 2026-1-16 02:28:10
|
查看: 320|
回复: 0
发表于 2026-1-16 02:28:10
|
查看: 320|
回复: 0
